ebaz4205部署Yolo(三)—— HLS加速神经网络策略
1、LUT:查找表,来实现组合逻辑电路的功能2、FF 触发器3、BRAM:block ram 嵌入fpga内部。BRAM可以用来实现多种不同位宽和深度的RAM/ROM/FIFO。相比于DRAM这种分布式的ram,Bram只存了1 bit也要占用一个BRAM。4、DSP:高位加法和乘法主要是由DSP数字信号处理器承担。
部署方案
我们选择yolo v3 Tiny,这是一个轻量级的网络(仅13层),先前已有在7z020上部署了yolo v3 Tiny的整个网络的开源案例[1]。但7020逻辑资源数量是7010的将近1倍,所以要在7010上部署就不得不把一些层放在arm核上计算,在FPGA部分实例化更多计算密集层的单元。
前提
参数量化
参数的量化是必须的,PL部分逻辑资源受限,高精度的浮点计算消耗资源太多,所以把参数量化成了16位(一位符号位、7位整数和8位小数)。在内存中存储的参数为short类型(16位),但只是以short类型存储,实际值为有符号浮点数。Short类型的值传入PL端卷积模块会以有符号浮点数计算,输出的值依然是16位有符号浮点数。
ap_fixed<16,8>部署
原则上,实例化单元越多,并行计算加速越多,资源消耗也会越大。反之,资源消耗也就少。由于片上逻辑资源受限,我们并不能使用HLS进行最大限度的实例化。要合理的实例化数据结构和计算单元,保证片上逻辑资源得到充分使用。
此外,尽可能提高PL的使用效率是重要的:资源有限的情况下,不一定把更多的层放在PL获得的效益最高。把使用频繁的层和计算密集的层放在PL侧并将内容进行最大的实例化,使用次数较少的层放在arm侧,收益最高。
结果
测试多种部署方案:卷积+池化、深度可分离卷积?。最优结果是在PL部署卷积计算,并利用了片上资源对其进行了最大限度的加速优化(见下文)。
HLS数据结构
// AXI_HP 接口数据结构
typedef struct quad_fp_pack{ //四个16位并行传输,共64位
fp_data_type sub_data_0;
fp_data_type sub_data_1;
fp_data_type sub_data_2;
fp_data_type sub_data_3;
}quad_fp_pack;
template<int D,int U,int TI,int TD> // 数据传输信号
struct ap_axi_fp{
quad_fp_pack data; // 数据
ap_uint<(D+7)/8> keep;
ap_uint<(D+7)/8> strb;
ap_uint<U> user;
ap_uint<1> last;
ap_uint<TI> id;
ap_uint<TD> dest;
};
typedef ap_axi_fp<64,2,5,6> quad_fp_side_channel;
typedef hls::stream<quad_fp_side_channel> yolo_quad_stream; //接口,FIFO实现
// 计算数据结构
typedef hls::Window<3,3,fp_data_type> window_type; //感受野
typedef hls::LineBuffer<3,MAX_LINE_BUFF_WIDTH,fp_data_type> line_buff_type; //三行特征图缓存
typedef struct local_weight_type // 卷积核
{
fp_weight_type data[3*3];
}local_weight_type;HLS资源优化策略和协调仿真验证
下文一次计算最大in/out通道为16,经过测试不行。尝试8也不行,改为了4。最终运行在200Mhz。
数据结构
资源受限,一次计算输入输出最大通道数为16。
卷积核缓存local_mem_group第三维complete卷积核的9个值都有单独的输入输出接口。
卷积核缓存local_mem_group第一维16个卷积核组被分为4个block,4个卷积核组存一起,每个能单独输入输出。
特征图缓存line_buff_group[4]实例化四个,每个存四个通道(每四个有一个输入输出接口)
#define MAX_KERNEL_NUM 16 定义conv ip进行一次计算最大输入/输出通道数
line_buff_type line_buff_group_0[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_1[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_2[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_3[MAX_KERNEL_NUM/4];
local_weight_type local_mem_group[MAX_KERNEL_NUM][MAX_INPUT_CH];
#pragma HLS ARRAY_PARTITION variable=local_mem_group block factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=local_mem_group complete dim=3
函数和循环
pipline后,先9个并行读入卷积核数据,4个并行读入特征图数据
macc卷积计算模块实例化4个,slide_window实例化了2个
暂时未验证计算瓶颈,待学习透视图分析
基于MAX_KERNEL_NUM = 32的分析
权重读入
weight [MAX_KERNEL_NUM][MAX_INPUT_CH][9] 被例化成72个部分
第三个维度是complete block ,每个block有独立的读写接口,能够被并行处理(pipline后,实现并行读入),而且每个都被单独存放!
第二个维度只能串行读取,循环嵌套方式(内层第二维度,外层第一维度)导致pipline无法展开一二层循环(第一维虽然有8个接口,也只能串行读取)。但是第一维被分为8个block,所以每四个可以进行单独存储(4个卷积核组存一起)。
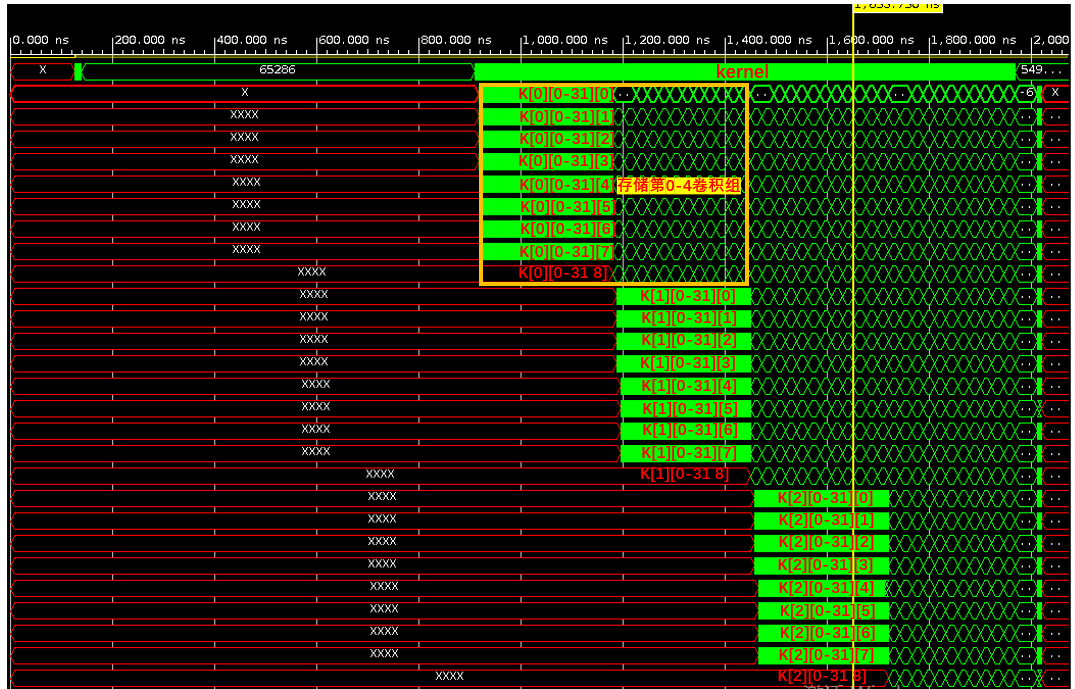
// 读取并存放权重,数据结构为 32 * 32 个 3*3 的卷积核。
local_weight_type local_mem_group[MAX_KERNEL_NUM][MAX_INPUT_CH];
#pragma HLS ARRAY_PARTITION variable=local_mem_group block factor=8 dim=1 // 卷积核分8组,每组四个
#pragma HLS ARRAY_PARTITION variable=local_mem_group complete dim=3 // 每个kernel的9个值独立,可以被并行处理
for(int k=0; k<output_ch; k++) //卷积核个数(最大32)= 输出通道数
{
for(int i=0;i<input_ch;i++) //每个kernel的depth(最大32)= 输入通道数
{
for(int j=0; j<fold_win_area; j++) //文件中以4*3存储kernel,读取3*3
{
#pragma HLS PIPELINE
curr_input = inStream.read();
local_mem_group[k][i].data[4*j] = curr_input.data.sub_data_0;
if(j!=(MAX_KERNEL_DIM*MAX_KERNEL_DIM+3)/4-1)
{
local_mem_group[k][i].data[4*j+1] = curr_input.data.sub_data_1;
local_mem_group[k][i].data[4*j+2] = curr_input.data.sub_data_2;
local_mem_group[k][i].data[4*j+3] = curr_input.data.sub_data_3;
}
}
}
}特征图读入
数据在内存中的存储方式 是CHW,这是能进行四通道并行读入的前提!!!
4个line_buf每个有独立接口(读入被例化四次),pipline后4个buf并行读入 418 * 3 个数据(每行也是并行读入,且每行单独存储)。下图表示3通道图片输入读取的过程(第四通道为0),如果是32通道输入则四个四个通道依次读取。
数据持续读入第三行第三列(能够进行一次计算),之后每次读入一个数,抛弃一个数。之所以数组元素为8是要在输入为32通道时记录每个通道的输入数据,以便计算每个通道。
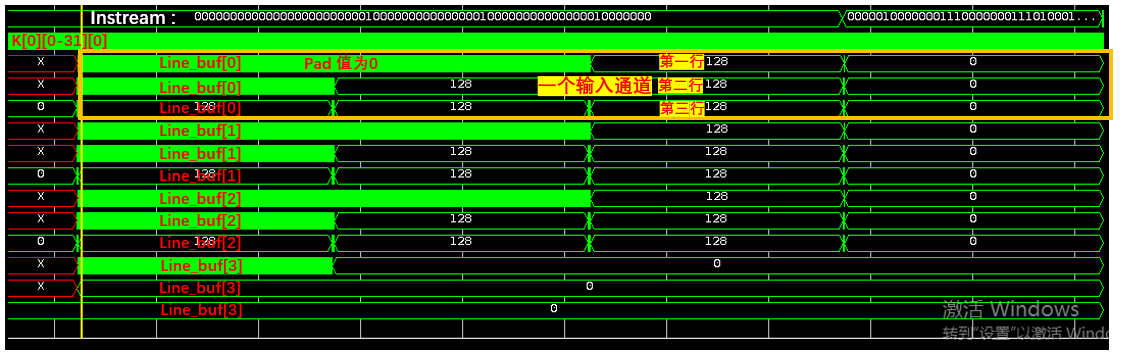
// 缓存感受野(被卷积的window):数据结构为 3 行宽度为 418 的缓冲区。
// 加速计算是进行四个一组的并行计算,所以定义的四个。最大32个输出对应8个并行计算组。
line_buff_type line_buff_group_0[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_1[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_2[MAX_KERNEL_NUM/4];
line_buff_type line_buff_group_3[MAX_KERNEL_NUM/4];
for(int row_idx=0;row_idx<input_h+1;row_idx++) //extra one row to send rest data
{
for(int col_idx=0;col_idx<input_w;col_idx++)
{
for(int input_ch_idx=0;input_ch_idx<fold_input_ch;input_ch_idx++)
{ //四个输入一组的并行计算,input_ch_idx是计算组的index
#pragma HLS PIPELINE
/*--------------------------------------------------------------------------------------------------------------------*/
if(row_idx != input_h)
{
if(((row_idx == 0)|| (row_idx == real_input_h-1)||
(col_idx == 0)|| (col_idx == input_w-1)))
{ // 原本是416*416 进行首尾行列的pading得到418*418
curr_input.data.sub_data_0 = 0;
curr_input.data.sub_data_1 = 0;
curr_input.data.sub_data_2 = 0;
curr_input.data.sub_data_3 = 0;
}
else curr_input = inStream.read();
/*--------------------------------------------------------------------------------------------------------------------*/
// 每个输入通道的三行数据缓存到每个输入通道的buf中
yolo_line_buffer(curr_input.data.sub_data_0,&line_buff_group_0[input_ch_idx],col_idx);
yolo_line_buffer(curr_input.data.sub_data_1,&line_buff_group_1[input_ch_idx],col_idx);
yolo_line_buffer(curr_input.data.sub_data_2,&line_buff_group_2[input_ch_idx],col_idx);
yolo_line_buffer(curr_input.data.sub_data_3,&line_buff_group_3[input_ch_idx],col_idx);
// 从 linebuf 中取一个 window
kernel_window_0 = slide_window(conv_col_count,&line_buff_group_0[input_ch_idx]);
kernel_window_1 = slide_window(conv_col_count,&line_buff_group_1[input_ch_idx]);
kernel_window_2 = slide_window(conv_col_count,&line_buff_group_2[input_ch_idx]);
kernel_window_3 = slide_window(conv_col_count,&line_buff_group_3[input_ch_idx]);计算
四个输入通道可以并行计算,先循环计算kernel0-32(可以被pipline并行,取决于kernel接口的个数) ,再循环计算输入通道组(串行)。
卷积模块被例化了16次,后处理4次(被pipline展开,kernel_idx :0,1,2,3又进行了并行计算)
row_idx == 2 col_idx == 2 时进行第一次conv计算(416*416)
row_idx == 2 col_idx == 3 时进行第一次输出
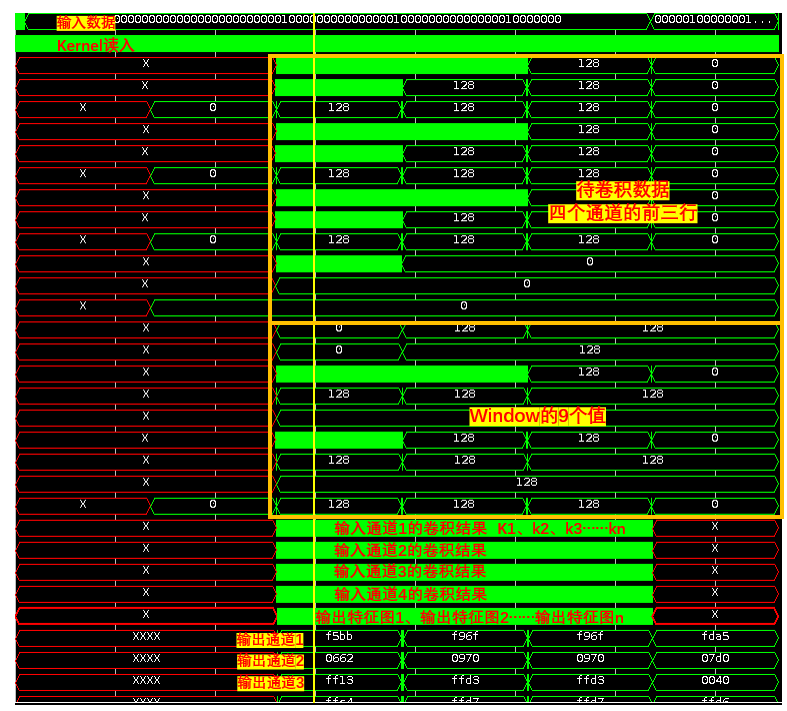
void yolo_conv_top(yolo_quad_stream &inStream, yolo_quad_stream &outStream 。。。)
{
// 输出FIFO,每个卷积核会有一个输出,网络单层最多32个输出,所以定义了32个用于输出FIFO的数组 。
yolo_inter_stream out_stream_group[MAX_KERNEL_NUM];
#pragma HLS ARRAY_PARTITION variable=out_stream_group complete dim=1 // complete:元素独立,因此每个输出通道(每个元素)可以单独进行输入输出。
#pragma HLS STREAM variable=out_stream_group depth=2 dim=1 // fifo深度为2
fp_mid_type val_output[MAX_KERNEL_NUM]; //用来暂存输出
#pragma HLS ARRAY_PARTITION variable=val_output complete dim=1
/*-------------------------------------------------------------------------------------*/
for(int row_idx=0;row_idx<input_h+1;row_idx++) //extra one row to send rest data
{
for(int col_idx=0;col_idx<input_w;col_idx++)
{
for(int input_ch_idx=0;input_ch_idx<fold_input_ch;input_ch_idx++)
{ //四个输入一组的并行计算,input_ch_idx是计算组的index
#pragma HLS PIPELINE
int conv_row_count=0,conv_col_count=0;
if((row_idx>MAX_KERNEL_DIM-2)&&(col_idx>MAX_KERNEL_DIM-2))
{ conv_row_count = row_idx - (MAX_KERNEL_DIM-1);
conv_col_count = col_idx - (MAX_KERNEL_DIM-1);}
else
{conv_row_count = 0;conv_col_count = 0;}
//条件判断使得linebuffer中先填充3行,才能开始计算
if((row_idx>MAX_KERNEL_DIM-2)&&(col_idx>MAX_KERNEL_DIM-2))
{
// kernel_idx 输出的索引值。每个输出 = Σ( 所有输入*输入通道对应的卷积核 )
//进行所有输出通道一个计算组的计算
for(int kernel_idx=0; kernel_idx<MAX_KERNEL_NUM; kernel_idx++)
{
//window_macc :卷积计算
sub0_val_output = window_macc(kernel_window_0,local_mem_group[kernel_idx][4*input_ch_idx]);
sub1_val_output = window_macc(kernel_window_1,local_mem_group[kernel_idx][4*input_ch_idx+1]);
sub2_val_output = window_macc(kernel_window_2,local_mem_group[kernel_idx][4*input_ch_idx+2]);
if(input_ch==3)
sub3_val_output = 0;
else
sub3_val_output = window_macc(kernel_window_3,local_mem_group[kernel_idx][4*input_ch_idx+3]);
// 累加操作
val_output[kernel_idx]=post_process(sub0_val_output,sub1_val_output,sub2_val_output,sub3_val_output,input_ch_idx,val_output[kernel_idx]);
//完成所有的计算组,最终结果接入输出流fifo
if(input_ch_idx == fold_input_ch-1)
{
if(kernel_idx<output_ch)
{
ap_fixed<16,8,AP_RND_CONV,AP_SAT> output_rec = val_output[kernel_idx];
if(!(out_stream_group[kernel_idx].full()))
write_output(output_rec,out_stream_group[kernel_idx]);
}
}
}
}
if(!((conv_row_count == 0)&&(conv_col_count ==0)))
{
if((row_idx==input_h)&&(input_ch_idx==fold_input_ch-1))
last = 1;
else
last = 0;
// input_ch_idx 值为0、1时才能输出。
out_stream_merge(out_stream_group,outStream,input_ch_idx,curr_input,last,output_ch,fold_output_ch);
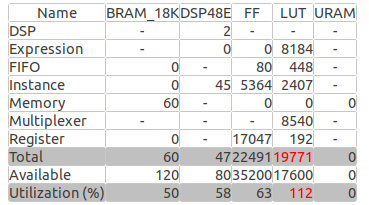
}HLS资源占用
仿真结果频率达到100Mhz
Tips--使用方法
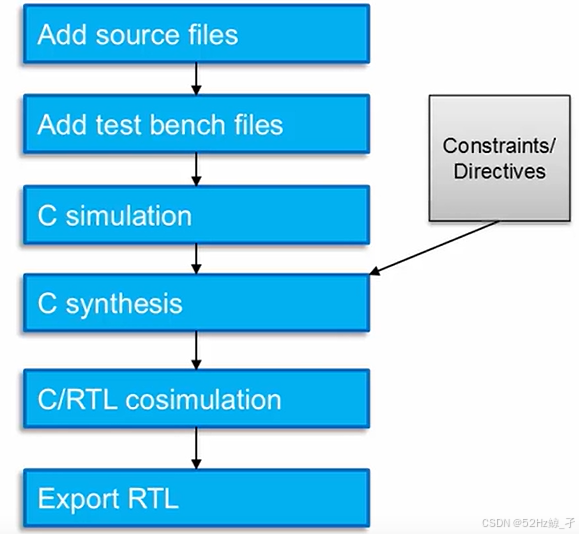
新建工程:定义top函数、定义tb文件(包含测试向量)、设置器件型号、定义端口输入时钟、定义输出配置(默认:导出IP、语言verilog)
模拟仿真
第一步:C simulation 软件层面,对代码功能进行逻辑验证(需要使用tb和测试向量)
主要检查功能是否符合预期,不考虑硬件实现的时序、资源等因素。
第二步:C synthsis (hls会自动优化资源占用空间)
目的:高级语言综合成RTL 、计算 FPGA 资源使用情况、生成时序信息
结果示例:


第三步 Co-simulation协同仿真
目的:检查 RTL 代码是否与原始 C 代码的功能匹配
使用dunp trace 选项可以得到波形图(可以使用仿真工具vivado 、modelsim打开)
可以在仿真工具中查看时序情况、并行情况、函数实例化个数
第四步:导出IP
Solution --->Export RTL
Ref
[1] Yu, Z., Bouganis, CS. (2020). A Parameterisable FPGA-Tailored Architecture for YOLOv3-Tiny. In: Rincón, F., Barba, J., So, H., Diniz, P., Caba, J. (eds) Applied Reconfigurable Computing. Architectures, Tools, and Applications. ARC 2020. Lecture Notes in Computer Science(), vol 12083. Springer, Cham. https://doi.org/10.1007/978-3-030-44534-8_25

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)