Quantlab3.4代码发布 | lightGBM排序轮动 | 29个行业机器学习合成因子轮动策略(代码+数据+模型下载)
拟在走通策略模型,明显出现了过拟合的情况,这个下周我们继续来做超参数优化,如何避免过拟合等,如果挖掘到更好的因子。rank需要特殊处理,它是groupby('date'),就是某一天截面数据的排序分位点。咱们的函数基本都是时序的,比如 log, std,或者常见的均线,macd,布林带等。代码在engine/models下,一个分类模型,一个排序模型。在轮动之前,新增了SelectByModel算
原创文章第444篇,专注“AI量化投资、个人成长与财富自由"。
按咱们星球的惯例,今天发布代码:Quantlab3.4。
quantlab 3.4重要更新:
1、支持截面rank函数写因子。
2、alpha158因子集。
3、lightgbm分类和排序模型。
4、基于模型的多因子轮动策略模板。
5、29个主要行业指数的机器模型轮动策略。

1、截面rank函数。
咱们的函数基本都是时序的,比如 log, std,或者常见的均线,macd,布林带等。
rank需要特殊处理,它是groupby('date'),就是某一天截面数据的排序分位点。
def rank(se: pd.Series):
ret = se.groupby(level=1).rank(pct=True)
return ret
2、本期咱们是机器学习合成因子,因此需要因子集:
代码在工程的如下位置:
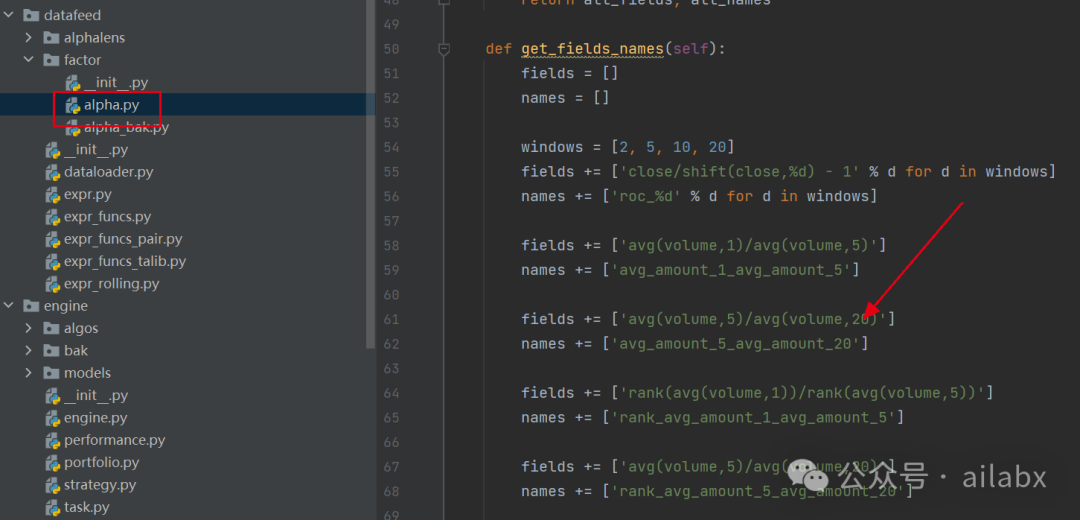
考虑到性能,我只选了十几个,这个大家可以添加自己的因子进来即可。
windows = [2, 5, 10, 20] fields += ['close/shift(close,%d) - 1' % d for d in windows] names += ['roc_%d' % d for d in windows] fields += ['avg(volume,1)/avg(volume,5)'] names += ['avg_amount_1_avg_amount_5'] fields += ['avg(volume,5)/avg(volume,20)'] names += ['avg_amount_5_avg_amount_20'] fields += ['rank(avg(volume,1))/rank(avg(volume,5))'] names += ['rank_avg_amount_1_avg_amount_5'] fields += ['avg(volume,5)/avg(volume,20)'] names += ['rank_avg_amount_5_avg_amount_20']
3、机器学习模型,lightGBM是所有学习算法里,效率兼性能最高的。
代码在engine/models下,一个分类模型,一个排序模型。大家重点关注排序模型。
模型训练的模块在ModelTrainer里:
from config import DATA_DIR
from datafeed import CSVDataloader
from datafeed.factor.alpha import AlphaBase, AlphaLit
class ModelTrainer:
def __init__(self, symbols, model_name='model.pkl', split_date='20200101'):
self.model_name = DATA_DIR.joinpath('models').joinpath(model_name).resolve()
self.split_date = split_date
self.model_path = DATA_DIR.joinpath('models').joinpath(self.model_name)
self.alpha = AlphaLit()
self.symbols = symbols
self._load_data()
def _load_data(self):
loader = CSVDataloader(path=DATA_DIR.joinpath('indexes'), symbols=self.symbols)
features, feature_names = self.alpha.get_fields_names()
fields, names = self.alpha.get_all_features_names()
df = loader.load(fields=fields, names=names)
df.dropna(inplace=True)
self.df = df
def train(self, train_func):
df = self.df
split_date = self.split_date
df_train = df.loc[:split_date]
df_val = df.loc[split_date:]
fields,names = self.alpha.get_fields_names()
train_func(df_train, df_val, feature_cols=names, model_save_path=self.model_path)
if __name__ == '__main__':
etfs_indexes = {
'159870.SZ': '000813.CSI',
'512400.SH': '000819.SH',
'515220.SH': '399998.SZ',
'515210.SH': '930606.CSI',
'516950.SH': '930608.CSI',
'562800.SH': '930632.CSI',
'515170.SH': '000815.CSI',
'512690.SH': '399987.SZ',
'159996.SZ': '930697.CSI',
'159865.SZ': '930707.CSI',
'159766.SZ': '930633.CSI',
'515950.SH': '931140.CSI',
'159992.SZ': '931152.CSI',
'159839.SZ': '399441.SZ',
'512170.SH': '399989.SZ',
'159883.SZ': 'h30217.CSI',
'512980.SH': '399971.CSI',
'159869.SZ': '930901.CSI',
'515050.SH': '931079.CSI',
'515000.SH': '931087.CSI',
'515880.SH': '931160.CSI',
'512480.SH': 'h30184.CSI',
'515230.SH': 'h30202.CSI',
'512670.SH': '399973.SZ',
'515790.SH': '931151.CSI',
'159757.SZ': '980032.CNI',
'516110.SH': 'h30015.CSI',
'512800.SH': '399986.SZ',
'512200.SH': '931775.CSI',
}
symbols = etfs_indexes.values()
m = ModelTrainer(symbols=symbols)
from engine.models.lightGBM_stockranker import train
m.train(train_func=train)
训练好的模型保存在如下位置data/models:
多因子轮动策略模板:
在轮动之前,新增了SelectByModel算子,选择机器模型,并对数据进行预测计算。
@dataclass
class TaskRolling_Model(Task): # 轮动策略模板
def get_algos(self):
return [
RunAlways(),
SelectBySignal(rules_buy=self.rules_buy,
buy_at_least_count=self.at_least_buy,
rules_sell=self.rules_sell,
sell_at_least_count=self.at_least_sell
),
SelectByModel(model_name=self.model_name,feature_names=self.feature_names),
SelectTopK(factor_name=self.order_by, K=self.topK, drop_top_n=self.dropN,
b_ascending=self.b_ascending),
self._parse_weights(),
Rebalance()
]
29个行业,基于机器学习模型的轮动策略:
def Rolling_ranker():
task = TaskRolling_Model()
task.name = '轮动策略-29个行业指数-StockRanker'
task.benchmark = '510300.SH'
task.start_date = '20100101'
task.symbols = list(etfs_indexes.values())
task.data_path = 'indexes'
task.model_name = 'ranker.pkl'
alpha = AlphaLit()
features, feature_names = alpha.get_fields_names()
# fields, names = alpha.get_all_features_names()
task.features = features
task.feature_names = feature_names
# task.rules_buy = ['roc_20>0.02']
# task.rules_sell = ["roc_20<-0.02"]
task.topK = 2
return task
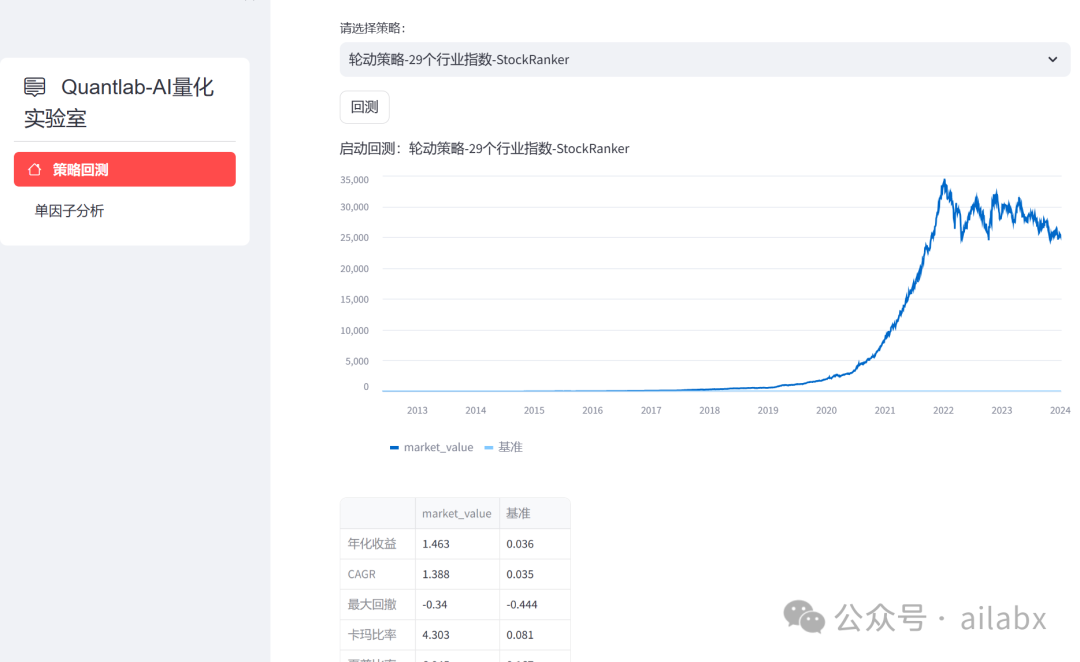
拟在走通策略模型,明显出现了过拟合的情况,这个下周我们继续来做超参数优化,如何避免过拟合等,如果挖掘到更好的因子。
历史文章:
Quantlab3.3代码发布:全新引擎 | 静待花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
创业板指布林带突破策略:年化12.8%,回撤20%+| Alphalens+streamlit单因子分析框架(代码+数据)
去掉底层回测引擎,完全自研,增加超参数优化,因子自动挖掘,机器模型交易。
飞狐量化——AI驱动的量化。(持续给大家写代码的,交付最前沿AI量化技术和策略的星球)AI量化实验室——2024量化投资的星辰大海
关于我:CFA,北大光华金融硕士,十年量化投资实战。 / CTO,全栈技术,AI大模型 。——应该是金融圈最懂技术的男人

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)