神经网络与深度学习学习报告(二)
在传统全连接神经网络中,每个神经元与相邻层的所有神经元相连,导致参数量爆炸式增长。以1000×1000像素输入图像为例,若隐含层包含100万个节点,则输入层到隐含层的连接参数达到1×10¹²量级。这种结构存在三大核心问题:(1)计算效率低下,训练速度缓慢;(2)极易陷入局部极小值和过拟合;(3)特征提取层次不足,难以捕捉图像的空间关联性。神经科学研究(如Hubel和Wiesel的视觉皮层研究)表明
一、深度学习与卷积神经网络的必要性
1.1 全连接网络的局限性
在传统全连接神经网络中,每个神经元与相邻层的所有神经元相连,导致参数量爆炸式增长。以1000×1000像素输入图像为例,若隐含层包含100万个节点,则输入层到隐含层的连接参数达到1×10¹²量级。这种结构存在三大核心问题:
(1)计算效率低下,训练速度缓慢;
(2)极易陷入局部极小值和过拟合;
(3)特征提取层次不足,难以捕捉图像的空间关联性。
神经科学研究(如Hubel和Wiesel的视觉皮层研究)表明,生物视觉系统通过局部感知和分层特征提取处理信息,这直接启发了卷积神经网络(CNN)的设计。
1.2 卷积神经网络的核心创新
CNN通过以下机制突破全连接网络的限制:
局部连接:每个神经元仅连接输入区域的局部感受野(如5×5窗口)
权值共享:使用相同卷积核扫描整个图像,参数量减少90%以上
空间下采样:通过池化操作逐步降低分辨率,保留主要特征
数学表达式展示了卷积操作的本质: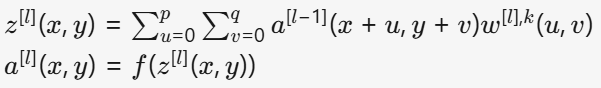
其中f(⋅)为激活函数,实现非线性变换。
二、经典网络结构演进
2.1 LeNet-5:开山之作

Yann LeCun于1998年提出的LeNet-5网络开创了CNN的基本范式:
- 交替卷积与池化:C1层(5×5卷积)→S2层(2×2平均池化)→C3层(5×5卷积)→S4层(池化)
- 全连接分类:C5层(120维特征)→F6层(84维)→高斯连接输出
- 参数特性:总参数量约6万,远小于同规模全连接网络
技术特点对比:①无填充操作(padding),特征图尺寸逐步缩减②使用sigmoid激活函数而非ReLU③平均池化替代现代常用的最大池化
2.2 AlexNet:深度网络突破
2012年ImageNet竞赛冠军AlexNet标志着深度学习时代的到来:
- 架构创新:5卷积层+3全连接层,参数量达6000万
- 关键技术:
- ReLU激活函数解决梯度消失
- Dropout正则化(p=0.5)抑制过拟合
- 双GPU并行训练策略
- 数据增强(随机裁剪、翻转、光照调整)
第一层卷积核可视化显示,网络自动学习到边缘、纹理等基础特征,验证了CNN的特征学习能力。
2.3 VGG-16:标准化深度模型
牛津大学提出的VGG网络确立了深度CNN的设计规范:
- 模块化结构:连续2-3个3×3卷积+ReLU后接2×2最大池化
- 深度拓展:16层结构(13卷积+3全连接)
- 感受野理论:堆叠3×3卷积等效于单个7×7卷积,但参数量减少33%
参数量分布呈现典型金字塔结构:输入层→64→128→256→512通道,最后展开为4096维全连接。
2.4 残差网络:突破深度极限
针对深层网络梯度消失问题,何恺明团队提出残差学习:
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
def forward(self, x):
residual = x
x = F.relu(self.conv1(x))
x = self.conv2(x)
return F.relu(x + residual)残差块通过跳跃连接(skip connection)建立直连通路,使得:
H(x)=F(x)+x
即使深层权重F(x)→0,仍能保持有效梯度传播。ResNet-152在ImageNet上将top-5错误率降至3.57%,证明了极深网络的有效性。
三、关键组件与技术
3.1 卷积操作进阶
- 空洞卷积:通过dilation参数扩大感受野
- 可变形卷积:自适应调整采样网格
- 分组卷积:降低计算量(如ResNeXt)
3.2 注意力机制
通道注意力(SENet)和空间注意力(CBAM)模块的引入,使网络能动态调整特征重要性:![]()
其中gap表示全局平均池化,W1、W2为全连接层。
四、数据集全景
| 数据集 | 规模 | 特点 | 适用任务 |
|---|---|---|---|
| MNIST | 7万 | 手写数字,28×28灰度 | 分类入门 |
| CIFAR-10 | 6万 | 10类物体,32×32彩色 | 小图像分类 |
| PASCAL VOC | 1.1万 | 20类,边界框标注 | 目标检测/分割 |
| MS COCO | 33万 | 80类,密集实例标注 | 实例分割 |
| ImageNet | 1400万 | 2.1万类别,层次化结构 | 大规模分类 |
五、未来发展方向
- 轻量化网络:MobileNet的深度可分离卷积(参数量减少90%)
- 神经架构搜索:AutoML自动生成高效网络结构
- 视觉Transformer:ViT模型在ImageNet上达到87.76%准确率
- 多模态学习:CLIP等模型实现图文跨模态理解

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)