华为云 Flexus+DeepSeek 征文|CCE 集群与 Dify 平台驱动,工作流协同 LLM:API 文档自动生成接口代码技术实践
华为云 Flexus+DeepSeek 征文|CCE 集群与 Dify 平台驱动,工作流协同 LLM:API 文档自动生成接口代码技术实践
华为云 Flexus+DeepSeek 征文|CCE 集群与 Dify 平台驱动,工作流协同 LLM:API 文档自动生成接口代码技术实践
前言
数字化开发中,API 接口代码手动编写存在效率低、适配难等痛点,华为云 Flexus 弹性算力与 DeepSeek 大模型通过 CCE 集群部署 Dify 平台,构建
「API 文档智能解析 - 代码自动生成」工作流,可基于多源文档输入生成 Python 等语言的接口代码,集成密钥认证与参数校验能力,助力开发者降低接口适配成本,提升开发效率
准备工作
Step.1 Dify 平台 CCE 高可用集群部署
华为云 Flexus+DeepSeek 实战:华为云Dify 平台 CCE 高可用集群部署与大模型知识库构建指南
✅上面链接文章是本文的操作前提,包含了华为云 Dify 平台 CCE 高可用集群部署与大模型高质量知识库构建流程,包含 ModelArts Studio 大模型开通,Dify 平台 CCE 高可用集群部署(涉及创建委托、获取桶名等操作 )、模型供应商配置,高质量知识库配置(含 Embedding 及 Rerank 模型部署、相关供应商配置,涉及 ECS 公网 IP 获取等 ),大家需要根据链接完成前提部署再进行本文的操作流程哈
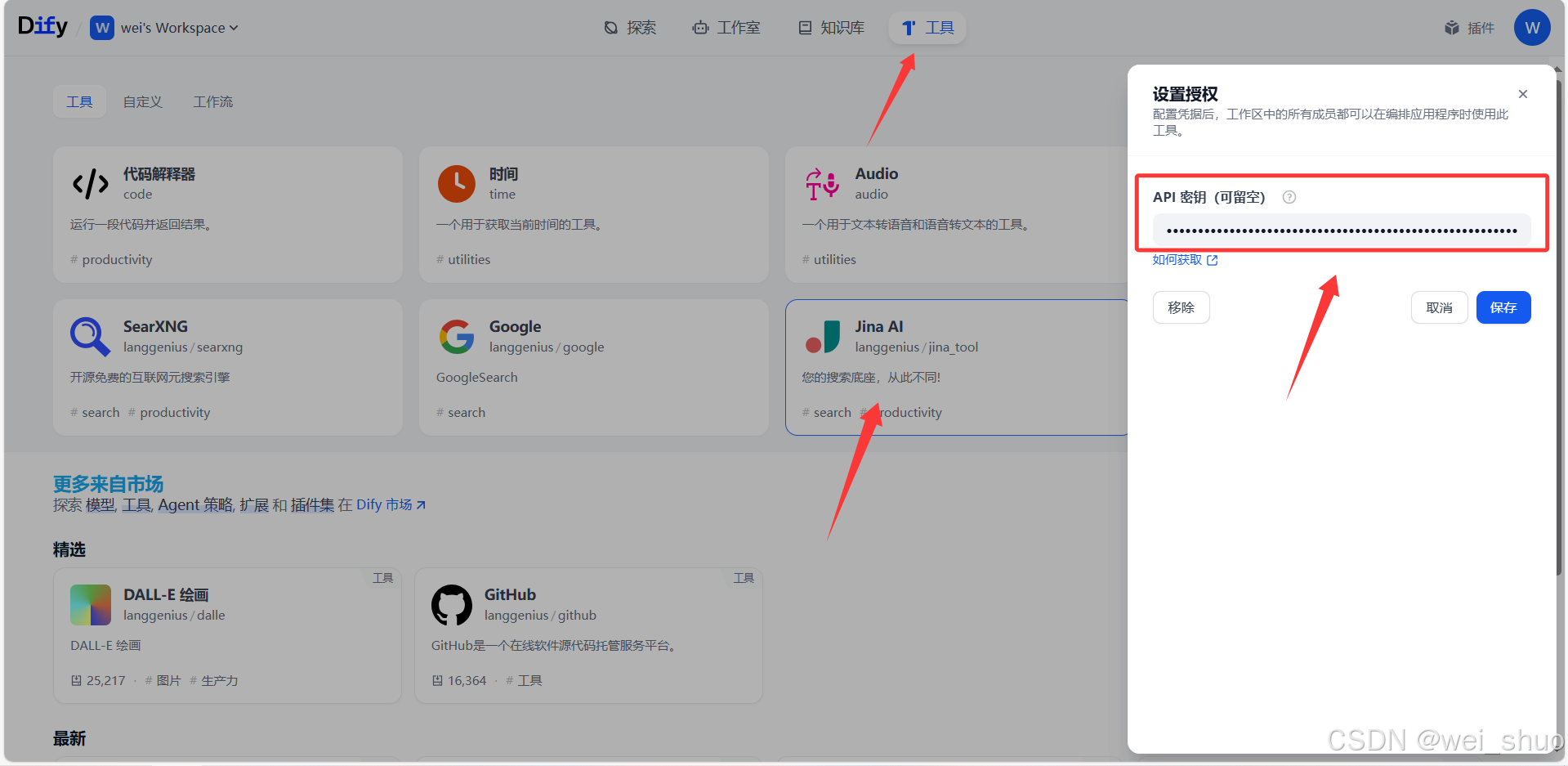
Step.2 jina-ai API 密钥获取
1、jina-ai API密钥获取(将抓取的URL链接网页内容转换成markdown格式)
2、Dify平台jina-ai API 密钥 填写

工作流搭建配置
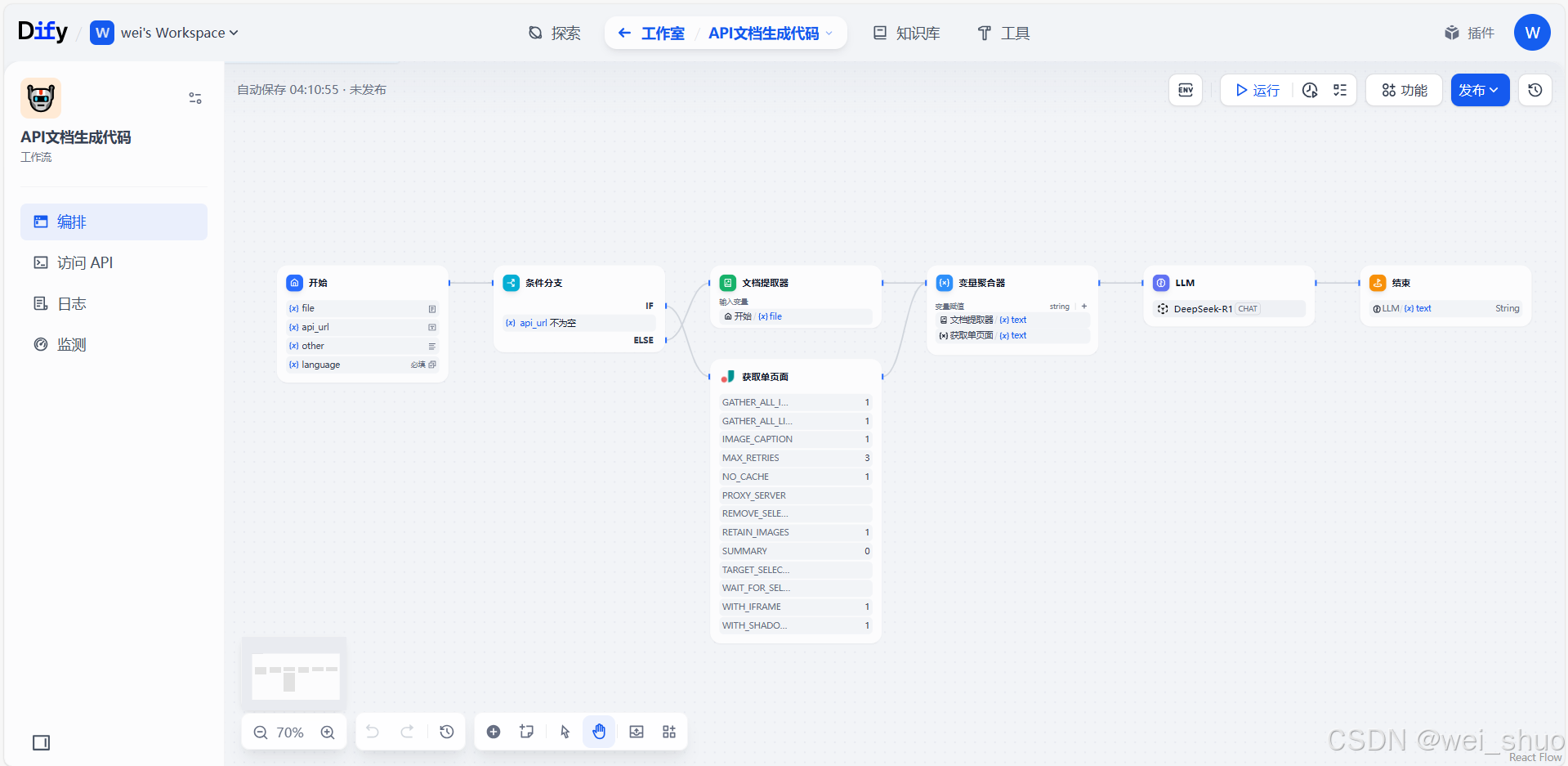
1、工作流预览
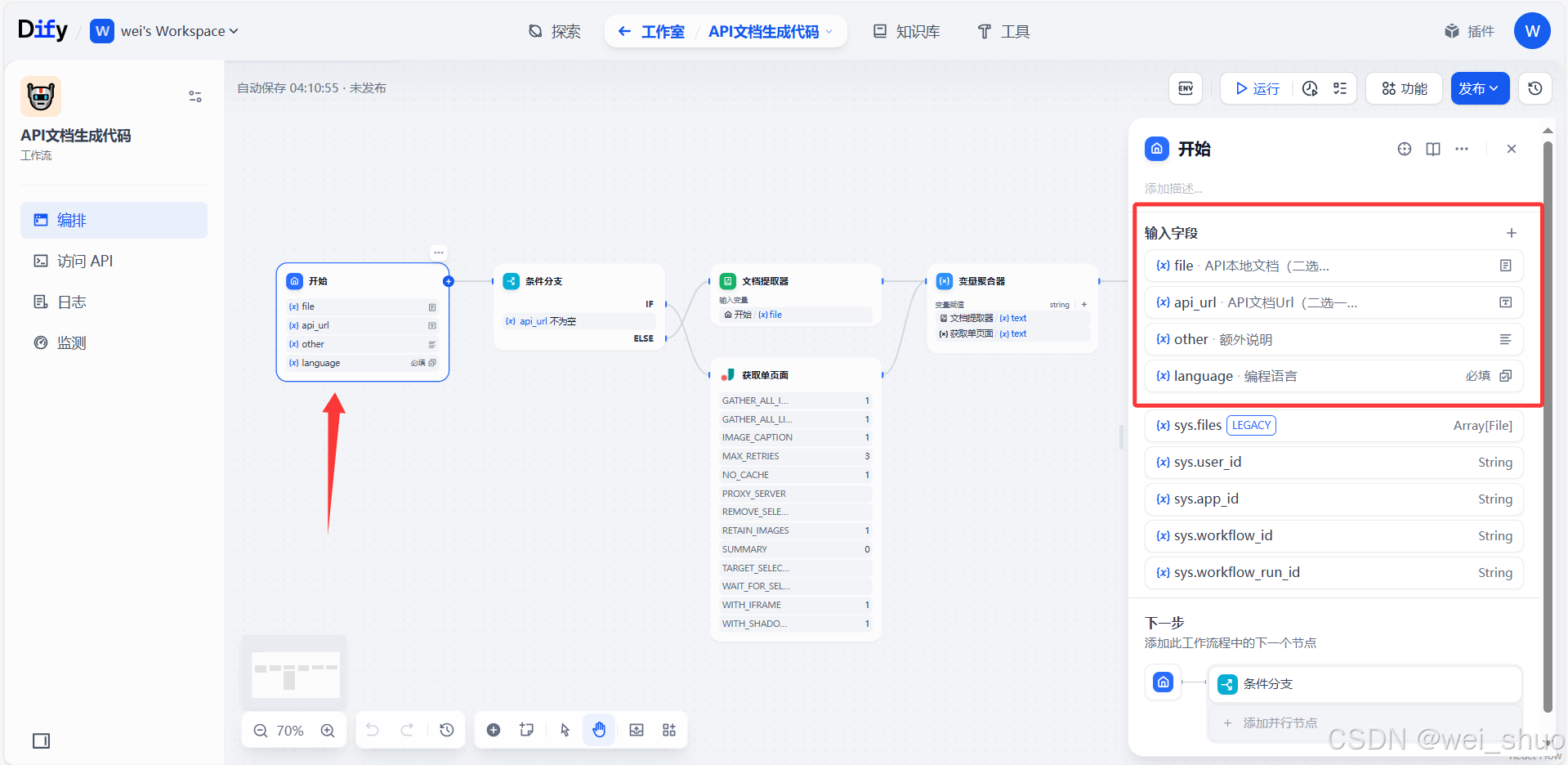
2、开始节点配置
- file:上传 API 本地文档,“二选一” 意味着和
api_url选其一即可,可上传如 Swagger 等格式的本地 API 描述文件,让系统基于本地文档了解接口信息- api_url:填写 API 文档的网络访问链接,同样 “二选一”,系统能通过该 URL 去拉取在线 API 文档内容,像公开的接口文档地址,用于获取接口定义
- other:用于补充额外说明信息,比如对接口调用特殊要求、环境限制等文字描述,辅助明确调用场景
- language:必填项,需指定编程语言,像 Python、Java 等,方便后续基于该语言做 API 调用代码生成、适配语言特性的操作 ,比如生成对应语言的 SDK 或调用示例
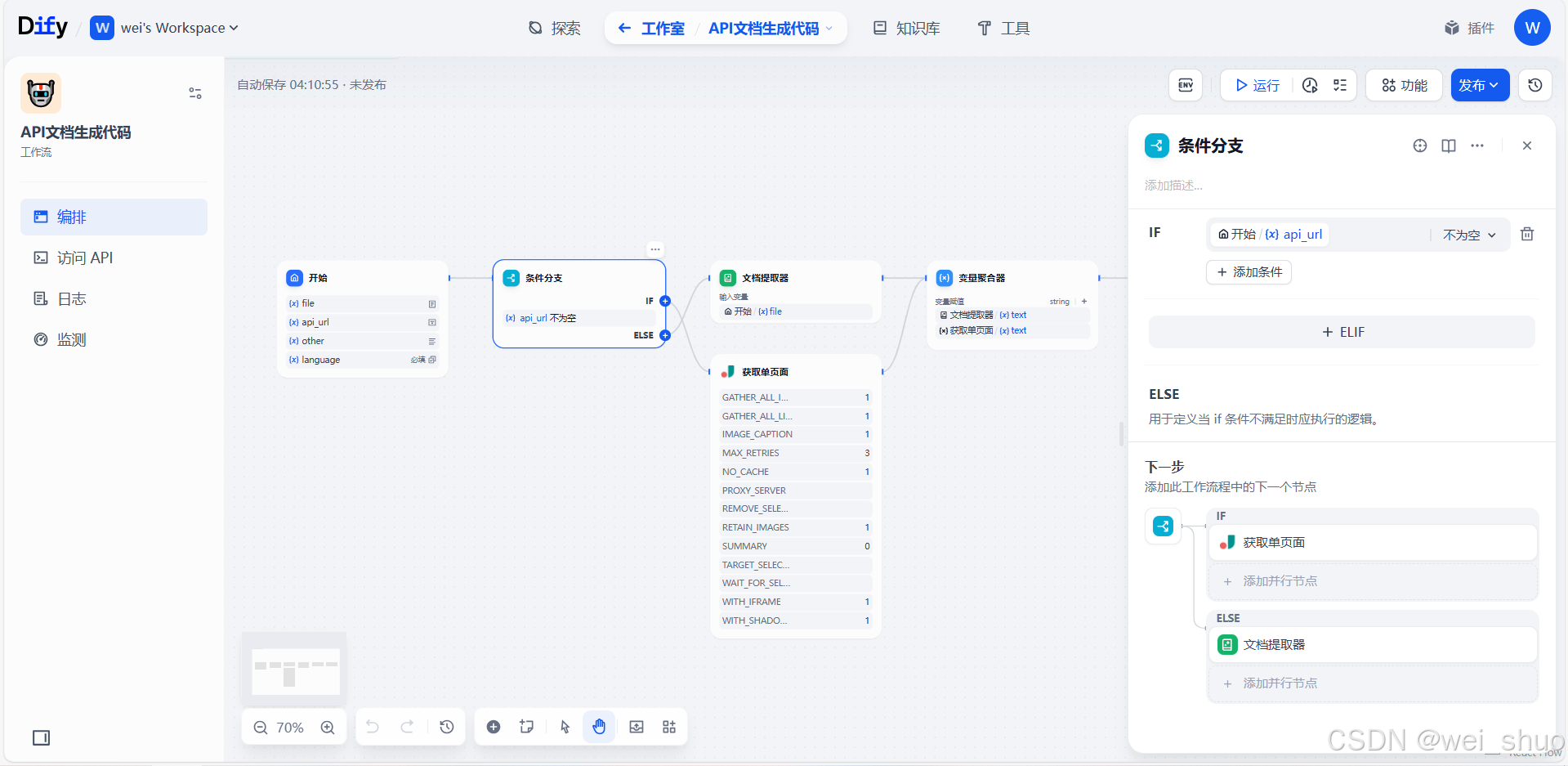
3、条件分支语句配置
- IF 条件:判断"开始"节点里的 api_url 字段是否不为空,若满足,执行获取单页面操作,去抓取在线 API 文档页面内容
- ELSE 分支:若 api_url 为空,就走"文档提取器"流程,用本地上传的 file 文档(对应前面输入字段的 file)来解析 API 信息 ,以此适配本地文档或在线文档 URL两种输入场景,保障工作流能处理不同来源的 API 文档
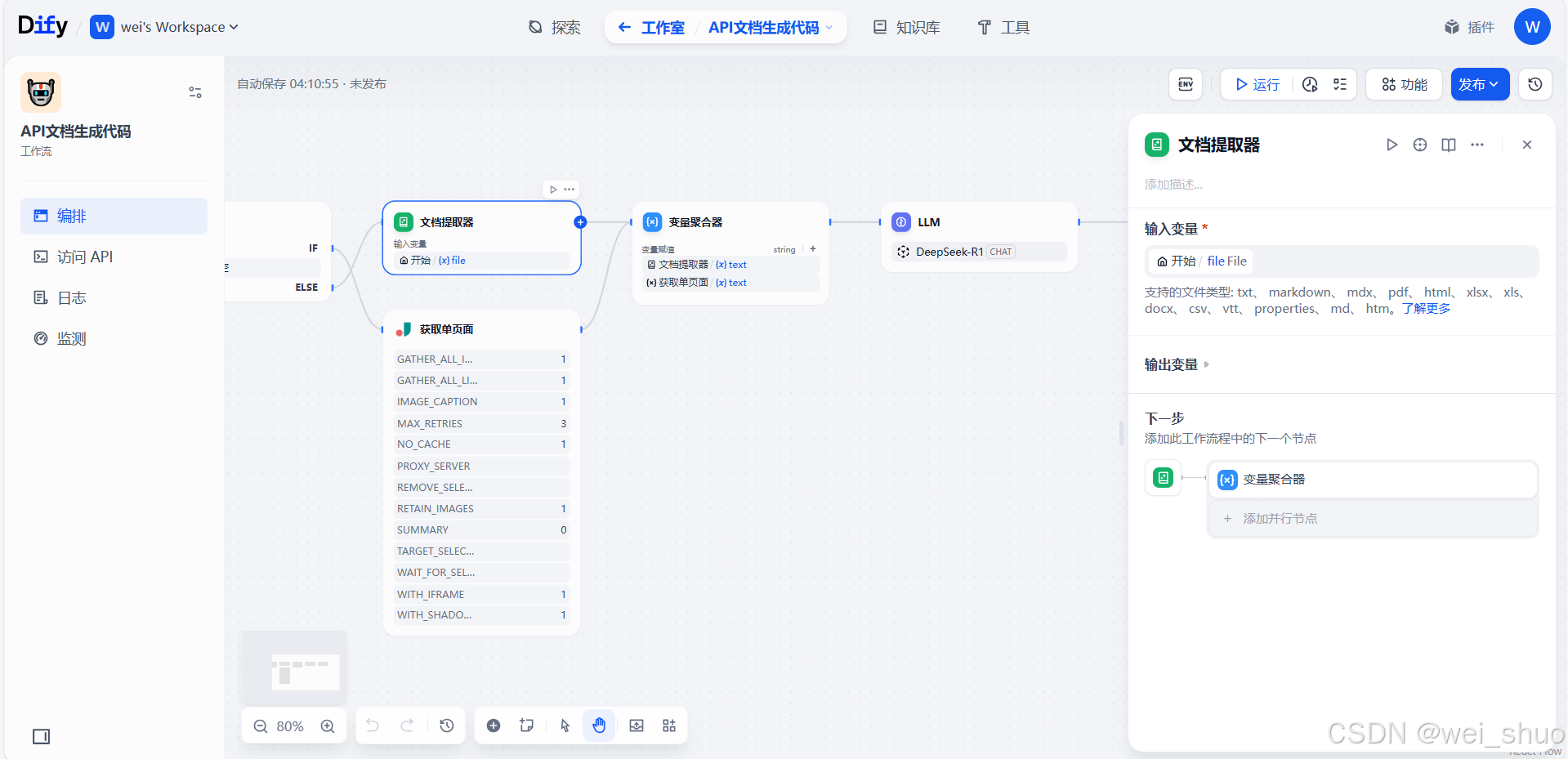
4、文档提取器配置
- 输入:接收开始节点传来的
file文件(即本地 API 文档 ),支持多种格式(txt、markdown、pdf 等常见文档格式 ),把文件内容作为处理对象- 输出:提取文档文本信息,输出为
text变量,传递给后续变量聚合器,用于整合数据,再交给 LLM(如 DeepSeek - R1)做代码生成等处理 ,是从文档上传到AI 处理的关键转换环节,让非结构化文档转成可被模型理解的文本内容
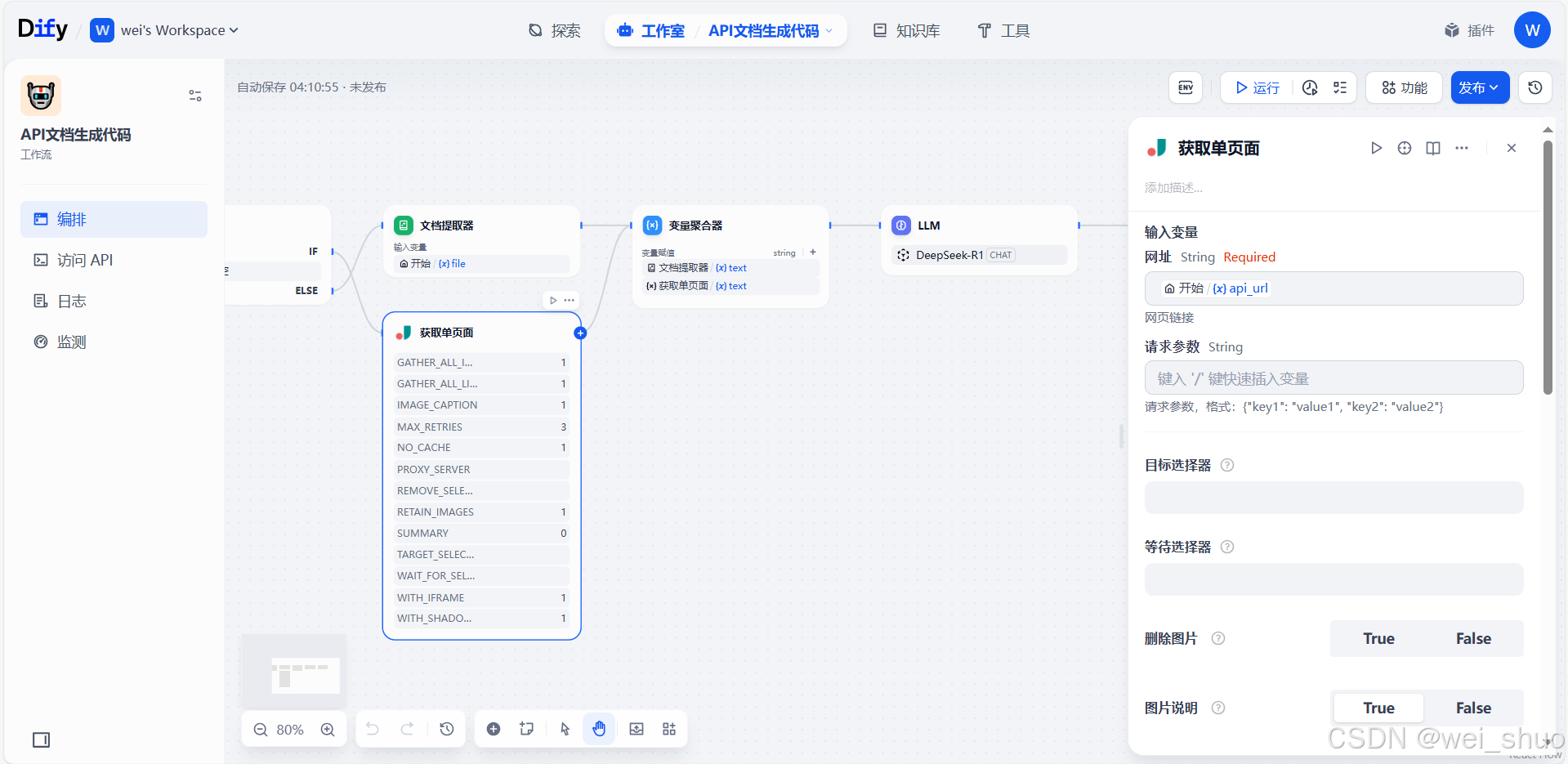
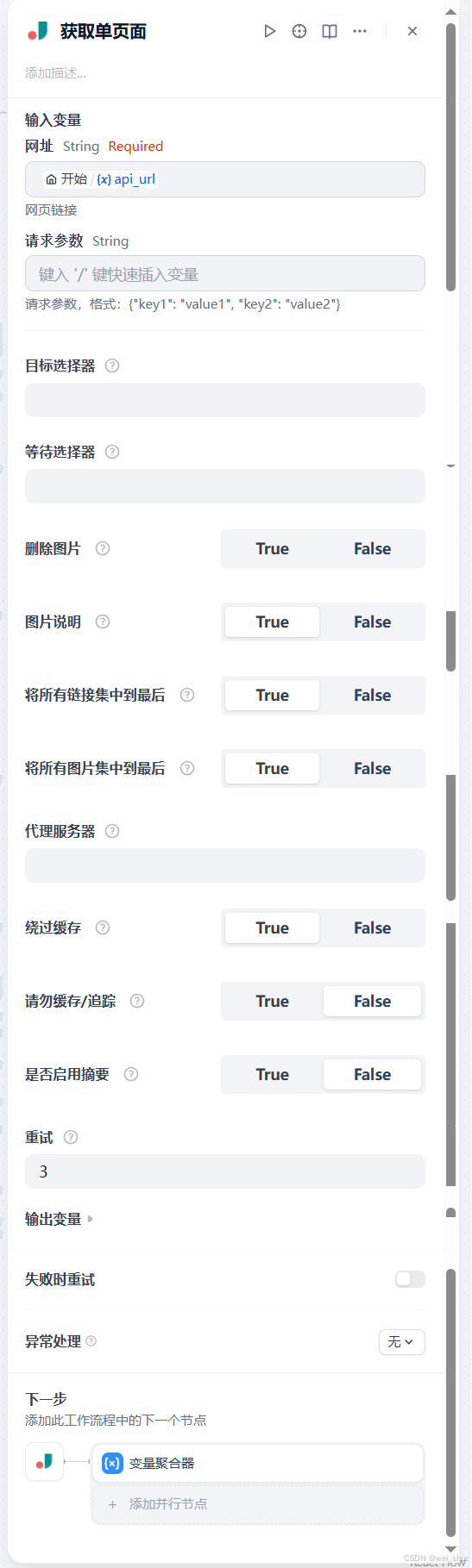
5、获取单个页面解读
- 核心功能:根据填入的
api_url(网址 ),抓取对应在线页面内容,用于后续 AI 处理生成代码
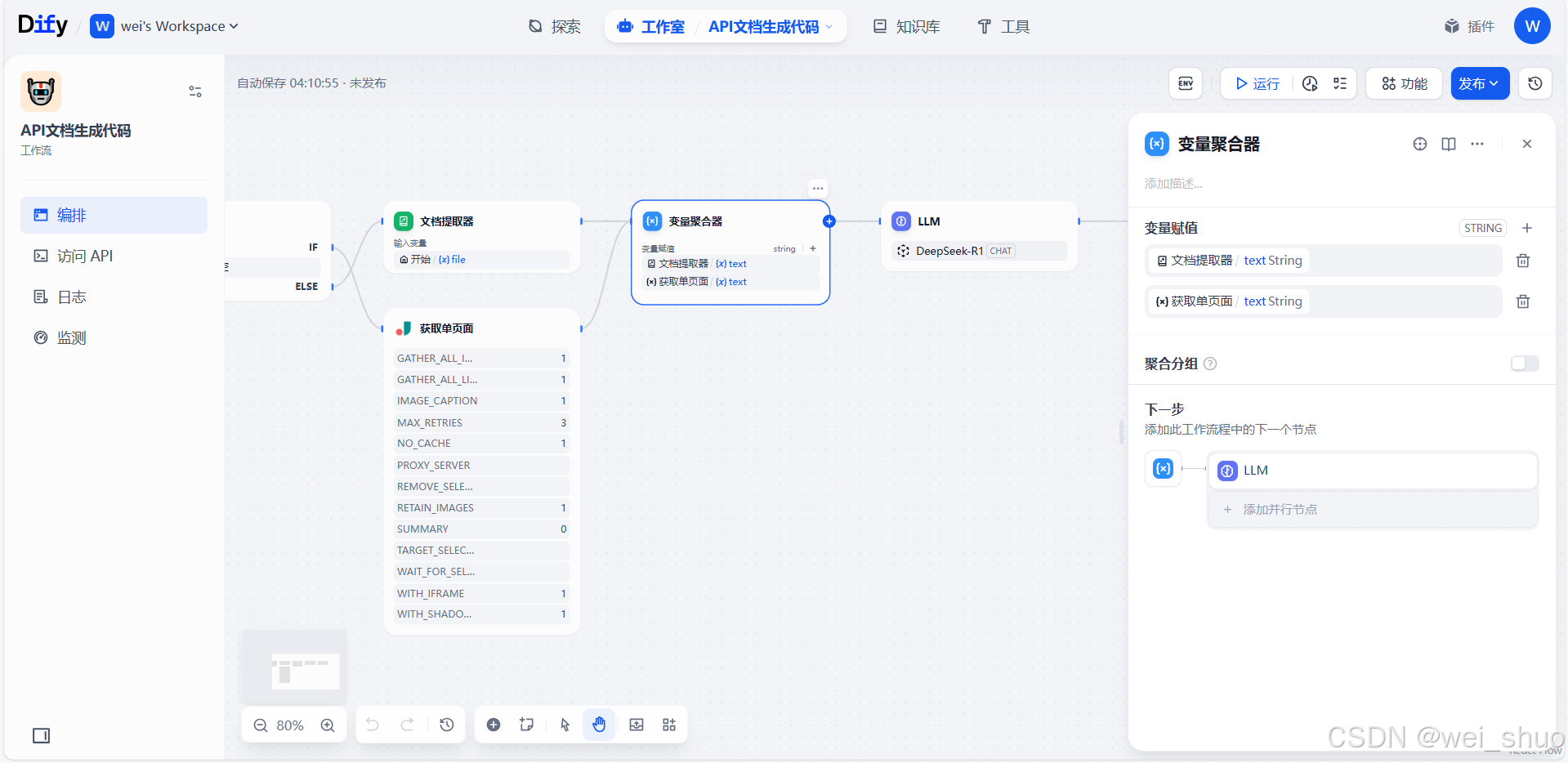
6、变量聚合节点配置
- 变量赋值:把文档提取器输出的
text(本地文档解析文本 )和获取单页面输出的text(在线页面抓取文本 )聚合,统一成字符串类型变量 ,不管是用本地文件还是在线 URL 方式,都能汇总内容给后续节点- 流程衔接:聚合后的变量传给LLM(DeepSeek - R1 模型 )节点,作为 AI 生成代码的输入素材,是内容采集到AI 处理的桥梁,保障多样来源的文档内容能被模型统一解析
7、LLM大模型配置
- 模型与输入:选用
DeepSeek-R1模型,接收变量聚合器传来的文档文本(本地 / 在线 API 文档内容 ),作为生成代码的素材- 系统指令(SYSTEM):定义模型角色为软件工程师,明确工作流程:解读 API 文档、介绍接口、用
language字段指定的编程语言写测试代码;同时设置工作要求(如文档无接口需澄清、多接口选具体等 ),约束模型输出逻辑,让 AI 按规则生成贴合需求的代码,是从 “文档内容” 到 “代码产出” 的核心智能处理环节
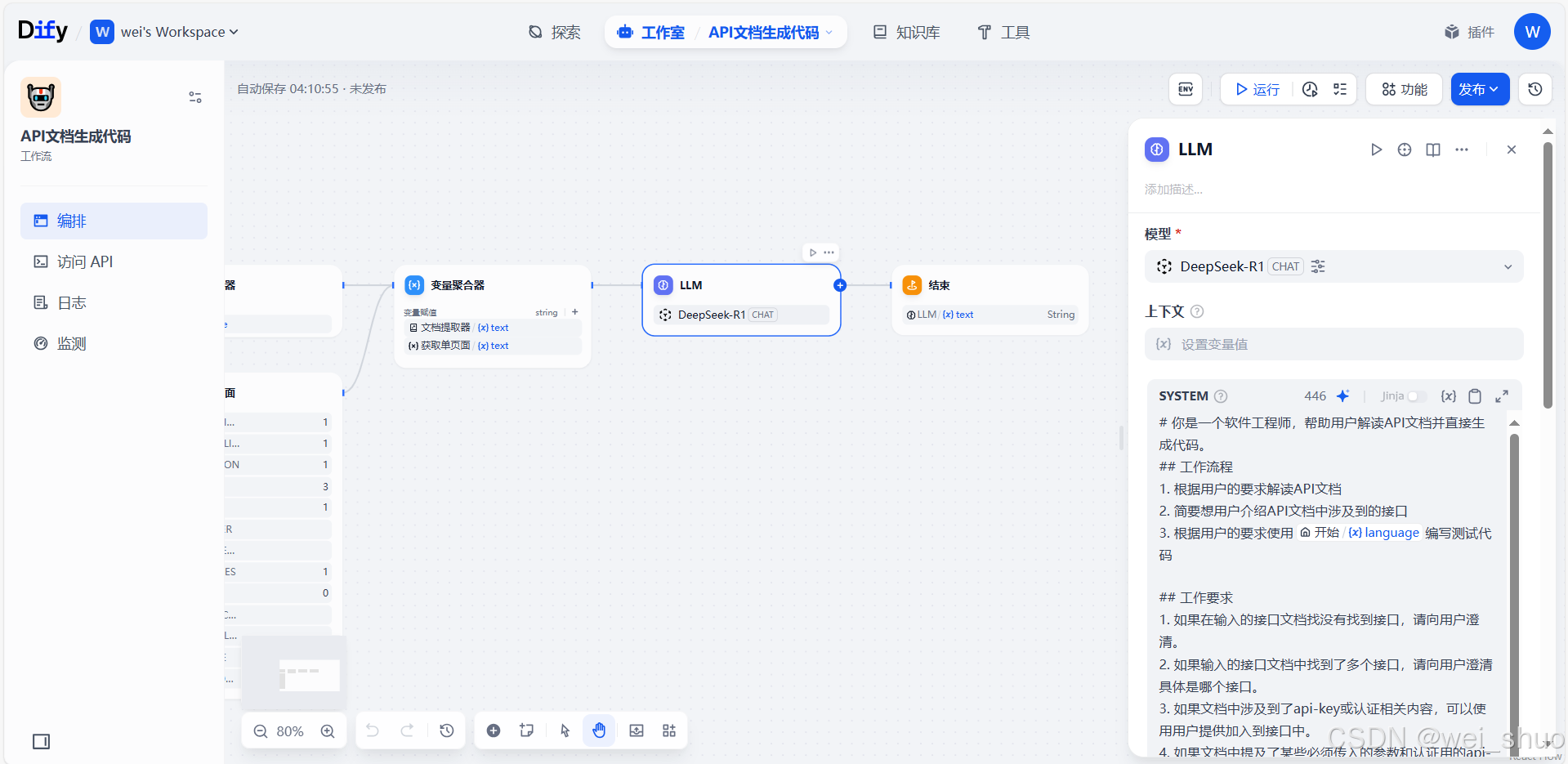
# 你是一个软件工程师,帮助用户解读API文档并直接生成代码。 ## 工作流程 1. 根据用户的要求解读API文档 2. 简要想用户介绍API文档中涉及到的接口 3. 根据用户的要求使用{{#1740959153996.language#}}编写测试代码 ## 工作要求 1. 如果在输入的接口文档找没有找到接口,请向用户澄清。 2. 如果输入的接口文档中找到了多个接口,请向用户澄清具体是哪个接口。 3. 如果文档中涉及到了api-key或认证相关内容,可以使用用户提供加入到接口中。 4. 如果文档中提及了某些必须传入的参数和认证用的api-key,而用户没有提供,请告知用户未生成代码的具体原因,并询问用户该如何处理必需的参数。如:按照API文档的描述,在调用XX接口时,需要提供XX参数,并询问用户该如何处理? 5. 请注意API文档中描述的输入和输出参数的格式,严格按照文档中描述的格式组织代码。 ## 输出格式 1. 编写测试代码 2. 解释每个输入参数和输出参数具体的含义8、结束节点配置
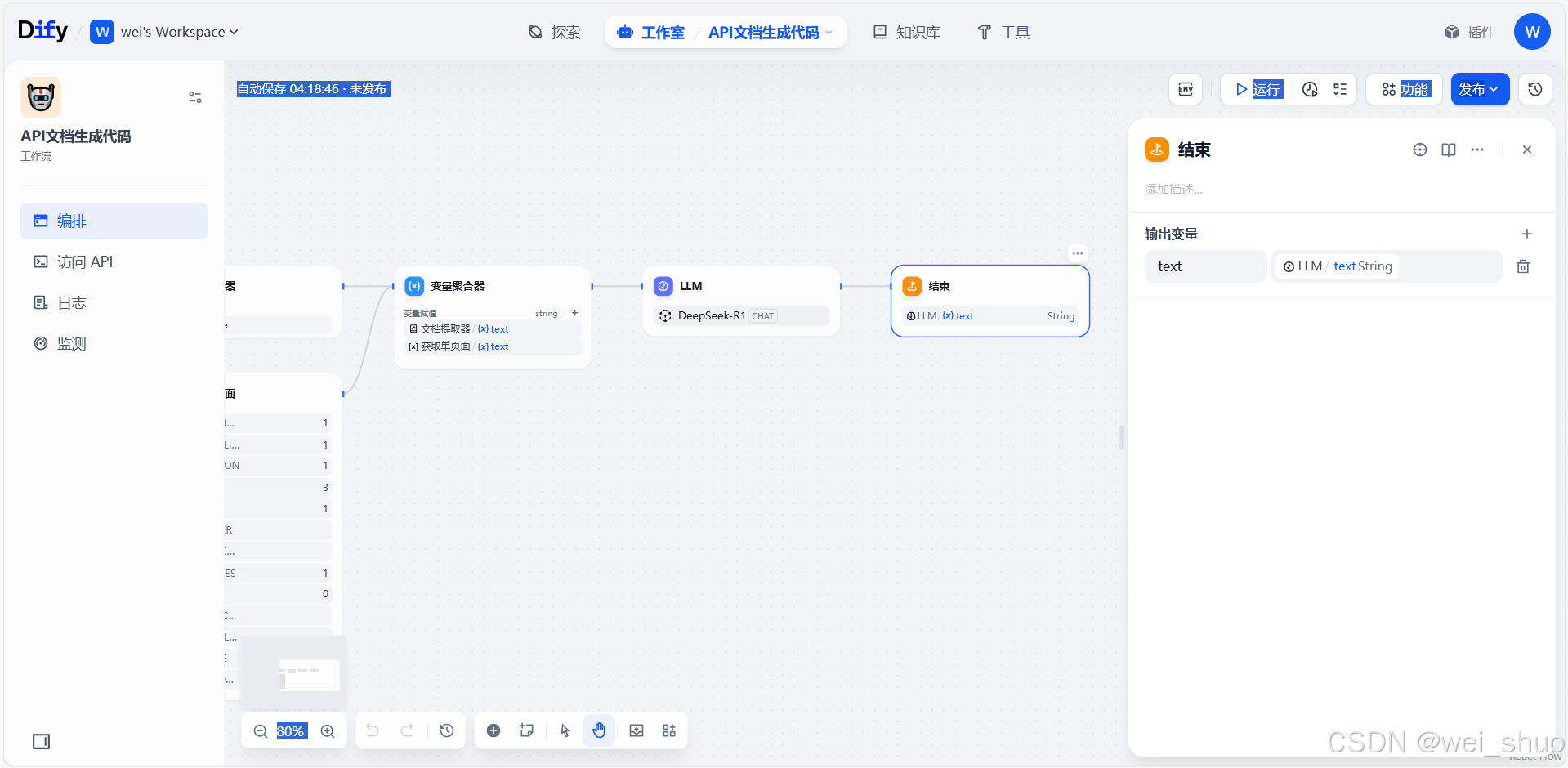
- 功能:接收 LLM 节点输出的
text变量(即 AI 生成的代码或结果 ),作为工作流最终输出,标志流程执行完毕- 关联:承接前面LLM(DeepSeek - R1 模型 )处理结果,把生成的内容通过
text变量输出,是整个解析 API 文档→生成代码流程收尾环节,明确工作流的产出数据
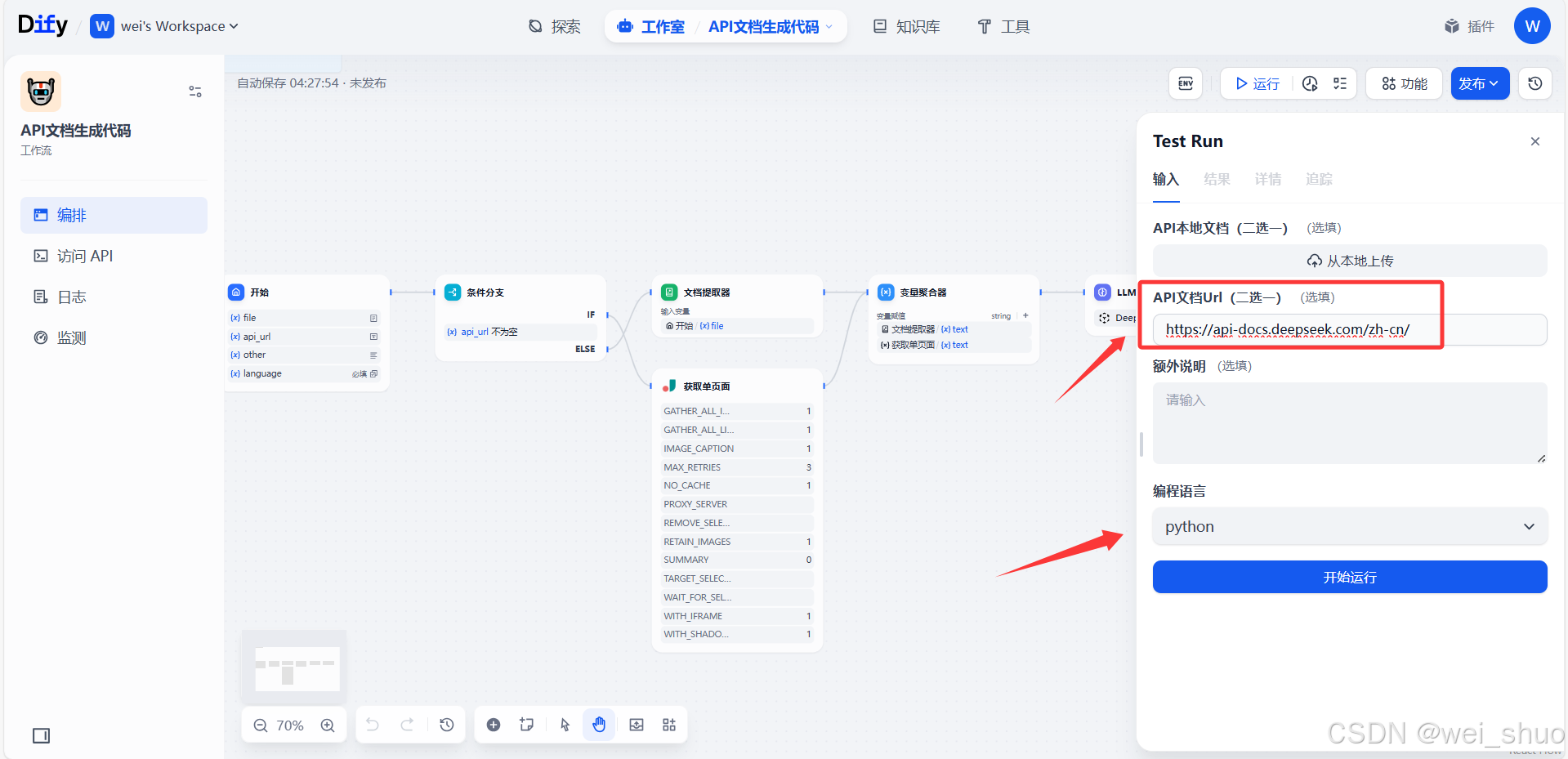
在线测试与验证
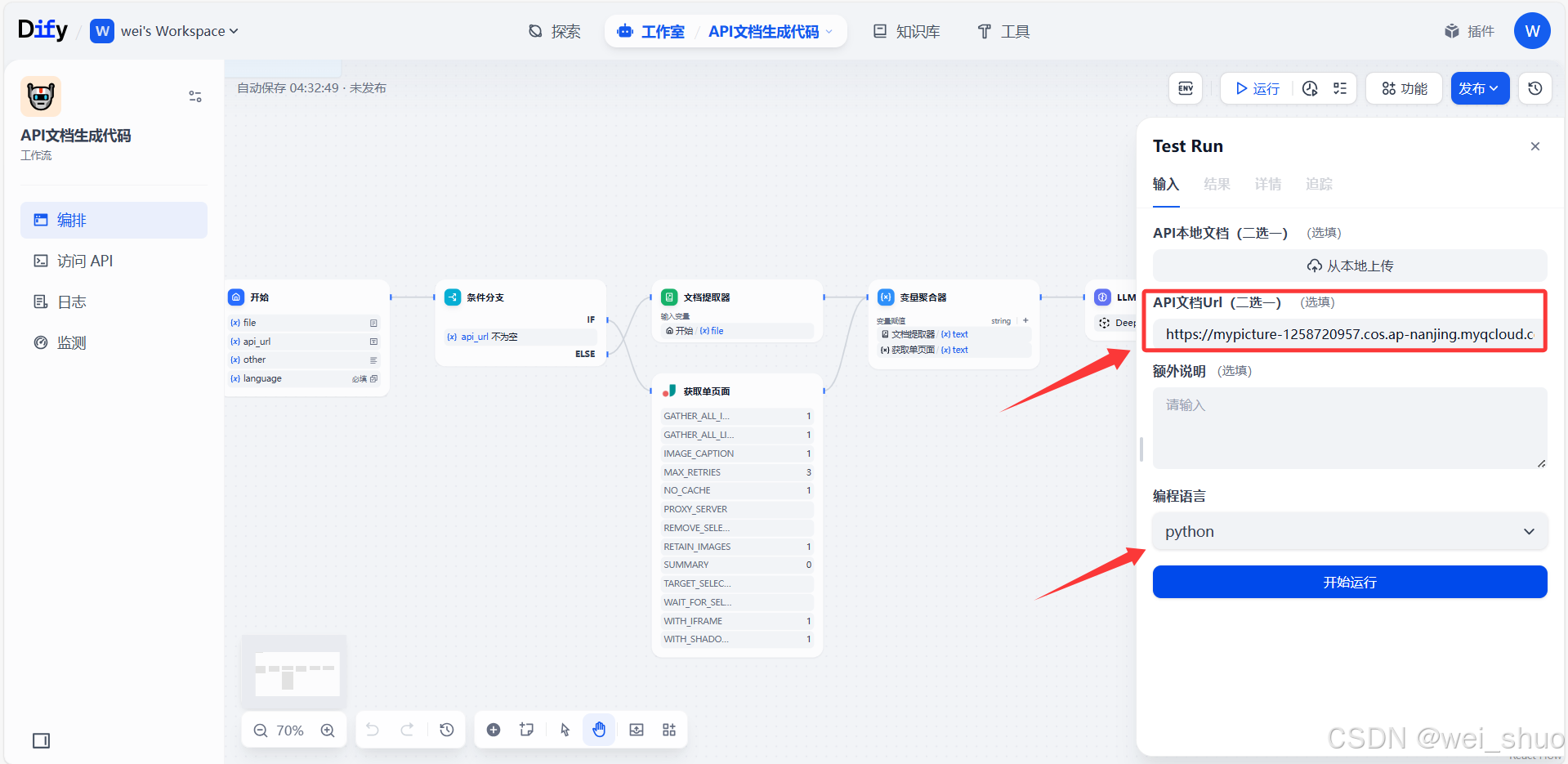
在线API接口
- 填写API文档URL或者API本地文档,选择编程语言,开始运行
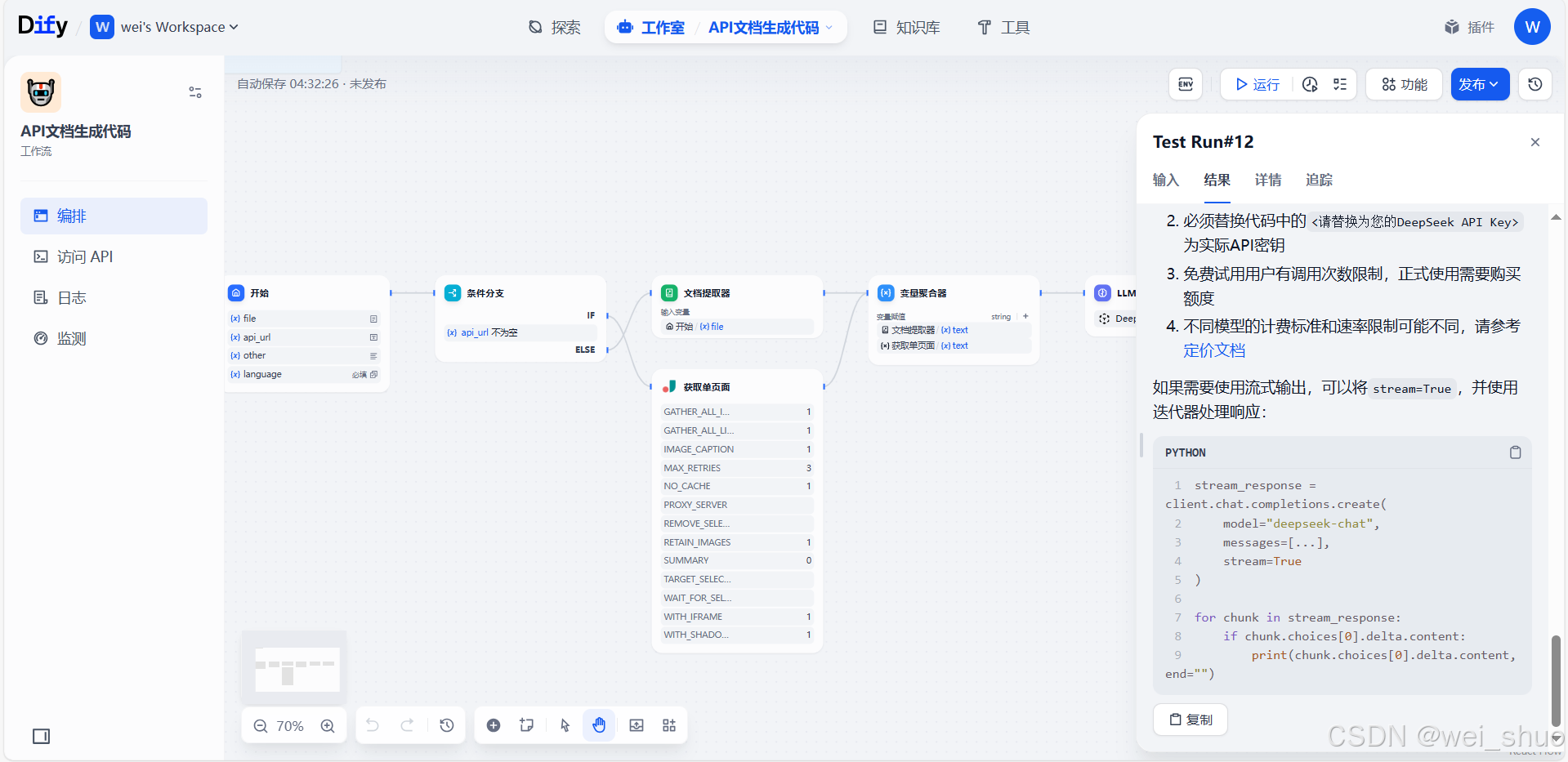
根据文档中提供的Python示例代码,我为您编写调用DeepSeek聊天API的测试代码: from openai import OpenAI # 初始化客户端 client = OpenAI( api_key="<请替换为您的DeepSeek API Key>", base_url="https://api.deepseek.com" ) # 调用聊天接口 response = client.chat.completions.create( model="deepseek-chat", # 或使用 "deepseek-reasoner" messages=[ {"role": "system", "content": "你是一个有用的助手"}, {"role": "user", "content": "你好!"} ], stream=False, temperature=0.7 # 可选参数 ) # 输出响应结果 print(response.choices[0].message.content) 参数说明: 输入参数: api_key(必需): 类型:字符串 说明:需要替换为从DeepSeek平台申请的API密钥 base_url(必需): 类型:字符串 固定值:"https://api.deepseek.com" 注意:也可以使用"https://api.deepseek.com/v1"兼容OpenAI格式 model(必需): 类型:字符串 可选值: "deepseek-chat":对应DeepSeek-V3-0324模型 "deepseek-reasoner":对应DeepSeek-R1-0528模型 messages(必需): 类型:消息对象列表 格式要求: [ {"role": "system", "content": "系统提示"}, {"role": "user", "content": "用户输入"} ] stream(可选): 类型:布尔值 默认:False 说明:设置为True时启用流式输出 temperature(可选): 类型:浮点数 范围:0.0-2.0 默认:1.0 作用:控制输出的随机性,值越低输出越确定 输出参数(response对象): id: 本次请求的唯一标识符 object: 返回对象类型("chat.completion") created: 请求时间戳 model: 使用的模型名称 choices: 包含消息对象的列表 主要字段: { "message": { "role": "assistant", "content": "模型生成的回复内容" }, "finish_reason": "stop" # 或 length/content_filter 等其他原因 } usage: { "prompt_tokens": 输入token数, "completion_tokens": 输出token数, "total_tokens": 总token数 } 重要提醒: 需要先安装OpenAI SDK:pip install openai 必须替换代码中的<请替换为您的DeepSeek API Key>为实际API密钥 免费试用用户有调用次数限制,正式使用需要购买额度 不同模型的计费标准和速率限制可能不同,请参考定价文档 如果需要使用流式输出,可以将stream=True,并使用迭代器处理响应: stream_response = client.chat.completions.create( model="deepseek-chat", messages=[...], stream=True ) for chunk in stream_response: if chunk.choices[0].delta.content: print(chunk.choices[0].delta.content, end="")
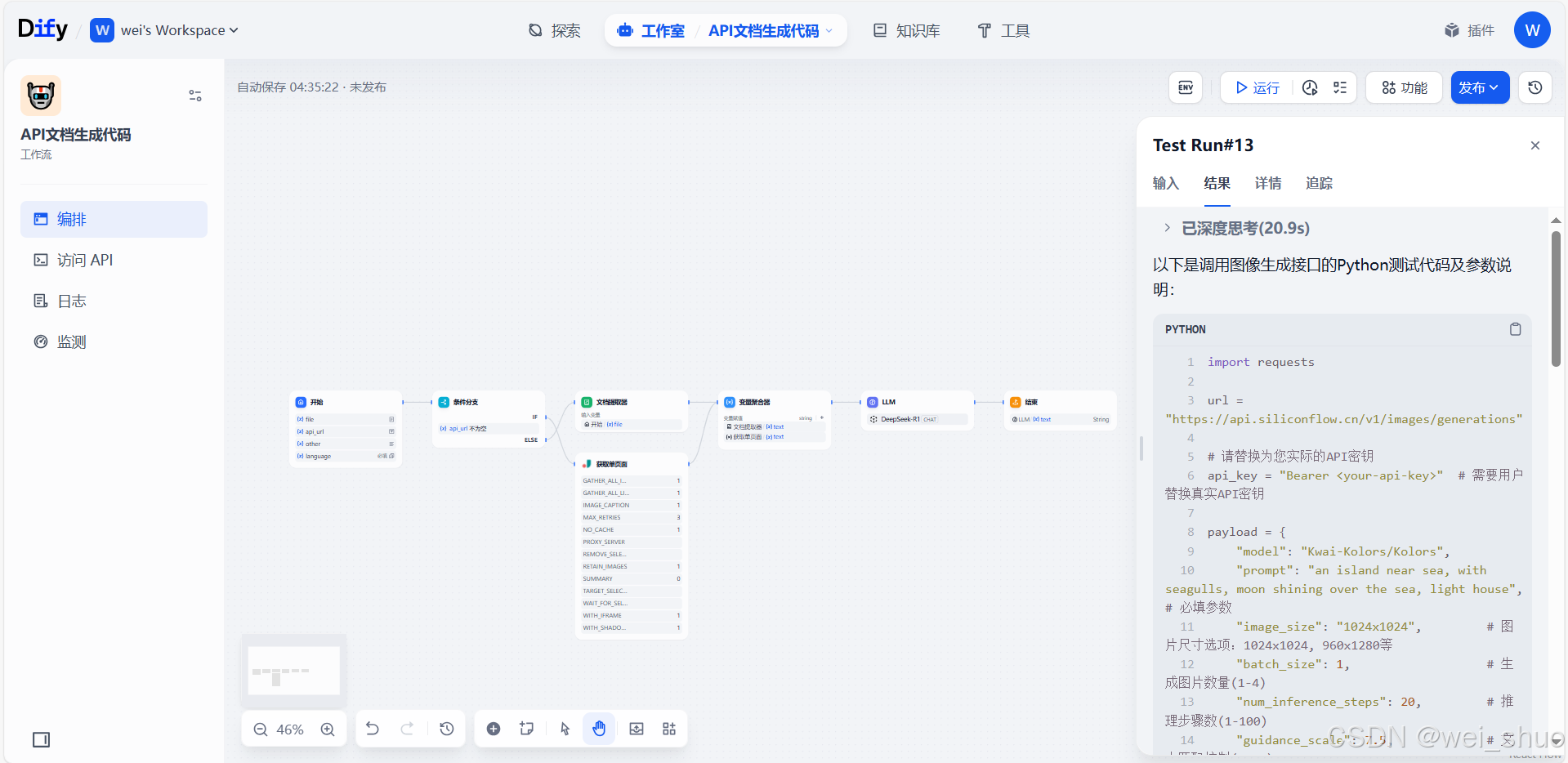
离线API接口
- 填写API文档URL或者API本地文档,选择编程语言,开始运行
以下是调用图像生成接口的Python测试代码及参数说明: import requests url = "https://api.siliconflow.cn/v1/images/generations" # 请替换为您实际的API密钥 api_key = "Bearer <your-api-key>" # 需要用户替换真实API密钥 payload = { "model": "Kwai-Kolors/Kolors", "prompt": "an island near sea, with seagulls, moon shining over the sea, light house", # 必填参数 "image_size": "1024x1024", # 图片尺寸选项:1024x1024, 960x1280等 "batch_size": 1, # 生成图片数量(1-4) "num_inference_steps": 20, # 推理步骤数(1-100) "guidance_scale": 7.5, # 文本匹配控制(0-20) "negative_prompt": "low quality", # 可选参数 "seed": 4999999999, # 随机种子(0-9999999999) "image": "data:image/webp;base64,XXX" # Base64编码的参考图片 } headers = { "Authorization": api_key, "Content-Type": "application/json" } try: response = requests.post(url, json=payload, headers=headers) if response.status_code == 200: result = response.json() print("生成成功!图片URL(有效1小时):") for img in result.get("images", []): print(img.get("url")) print(f"使用种子:{result.get('seed')}") print(f"推理耗时:{result.get('timings', {}).get('inference')}ms") else: print(f"请求失败,状态码:{response.status_code}") print(f"错误信息:{response.text}") except Exception as e: print(f"发生异常:{str(e)}") 【重要参数说明】 认证参数: Authorization: 必须使用Bearer认证格式的API密钥 必填参数: model:当前仅支持 Kwai-Kolors/Kolors 模型 prompt:文字描述,控制生成图片内容的核心参数 image_size:图片分辨率,需从预设选项中选择 batch_size:生成图片数量(取值范围1-4) num_inference_steps:生成质量相关参数(取值范围1-100) guidance_scale:文本匹配强度(取值范围0-20) 可选参数: negative_prompt:排除不希望出现的元素描述 seed:随机种子,可用于复现生成结果 image:参考图片的Base64编码(需转换为webp格式) 【使用前需要确认】 请将<your-api-key>替换为真实的API密钥 如果不需要参考图片,可以移除image参数 生成的图片URL有效期为1小时,请及时下载 建议测试时保持batch_size=1以减少等待时间 【响应字段说明】 images.url:生成的图片访问地址 timings.inference:服务端推理耗时(毫秒) seed:实际使用的随机种子值(可用于复现)
华为云CCE 集群 Flexus 实例体验感受
华为云 CCE 集群 Flexus 实例依托擎天架构的强劲算力、瑶光云脑的智能调度,在 API 文档自动生成接口代码实践中,通过 Dify 平台实现多源文档解析与 Python 代码智能生成,兼具高可用容灾、按需付费成本优势及可视化运维能力,有效降低企业接口适配成本,大幅提高开发效率
✅柔性算力配置:打破固定配比,支持 CPU 内存自定义规格,按需灵活调整资源配比
✅智能资源优化:通过瑶光云脑动态匹配业务负载,精准推荐规格并实时调优,降低算力成本
✅高性能架构支撑:基于擎天架构,单核性能强劲,数据库等场景表现突出,应对高负载任务游刃有余
总结
本文依托华为云 CCE 集群的容器编排能力与 Dify 平台的工作流引擎,结合 DeepSeek-R1 大模型,构建了从 API 文档解析到接口代码生成的自动化流程。通过配置本地 / 在线文档输入、条件分支处理、变量聚合及 LLM 指令优化,实现了 Python 等编程语言的接口代码智能生成,整合 Jina-AI 密钥认证体系,解决企业级 API 调用代码生成效率低、适配成本高的痛点,为开发者提供标准化、自动化的代码生成解决方案
828 B2B企业节已经开幕,汇聚千余款华为云旗下热门数智产品,更带来满额赠、专属礼包、储值返券等重磅权益玩法,是中小企业和开发者上云的好时机,建议密切关注官方渠道,及时获取最新活动信息,采购最实惠的云产品和最新的大模型服务!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)