神经网络如何入门,神经网络训练流程
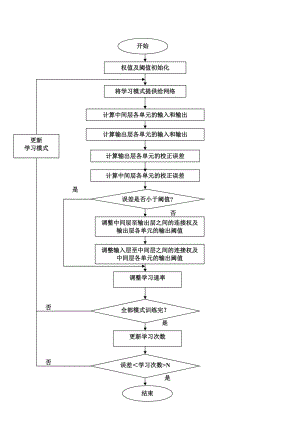
神经网络的学习,也就是训练过程,指的是输入层神经元接收输入信息,传递给中间层神经元,最后传递到输出层神经元,由输出层输出信息处理结果的过程。在这个过程中,神经网络通过不断调整网络的权值和阈值,达到学习、训练的目的,当网络输出的误差减少到可以接受的程度,或者预先设定的学习次数后,学习就可以停止了。...
(1)BP算法的学习过程中有两个过程是什么?(2)写出BP神经网络的数学模型,并以20
bp(backpropagation)网络是1986年由rumelhart和mccelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
bp网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
bp神经网络模型拓扑结构包括输入层(input)、隐层(hidelayer)和输出层(outputlayer)。人工神经网络就是模拟人思维的第二种方式。
这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的行为却是极其丰富多彩的。
人工神经网络首先要以一定的学习准则进行学习,然后才能工作。现以人工神经网络对手写“a”、“b”两个字母的识别为例进行说明,规定当“a”输入网络时,应该输出“1”,而当输入为“b”时,输出为“0”。
所以网络学习的准则应该是:如果网络作出错误的的判决,则通过网络的学习,应使得网络减少下次犯同样错误的可能性。
首先,给网络的各连接权值赋予(0,1)区间内的随机值,将“a”所对应的图象模式输入给网络,网络将输入模式加权求和、与门限比较、再进行非线性运算,得到网络的输出。
在此情况下,网络输出为“1”和“0”的概率各为50%,也就是说是完全随机的。这时如果输出为“1”(结果正确),则使连接权值增大,以便使网络再次遇到“a”模式输入时,仍然能作出正确的判断。
如果输出为“0”(即结果错误),则把网络连接权值朝着减小综合输入加权值的方向调整,其目的在于使网络下次再遇到“a”模式输入时,减小犯同样错误的可能性。
如此操作调整,当给网络轮番输入若干个手写字母“a”、“b”后,经过网络按以上学习方法进行若干次学习后,网络判断的正确率将大大提高。
这说明网络对这两个模式的学习已经获得了成功,它已将这两个模式分布地记忆在网络的各个连接权值上。当网络再次遇到其中任何一个模式时,能够作出迅速、准确的判断和识别。
一般说来,网络中所含的神经元个数越多,则它能记忆、识别的模式也就越多。如图所示拓扑结构的单隐层前馈网络,一般称为三层前馈网或三层感知器,即:输入层、中间层(也称隐层)和输出层。
它的特点是:各层神经元仅与相邻层神经元之间相互全连接,同层内神经元之间无连接,各层神经元之间无反馈连接,构成具有层次结构的前馈型神经网络系统。
单计算层前馈神经网络只能求解线性可分问题,能够求解非线性问题的网络必须是具有隐层的多层神经网络。神经网络的研究内容相当广泛,反映了多学科交叉技术领域的特点。
主要的研究工作集中在以下几个方面:(1)生物原型研究。从生理学、心理学、解剖学、脑科学、病理学等生物科学方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。(2)建立理论模型。
根据生物原型的研究,建立神经元、神经网络的理论模型。其中包括概念模型、知识模型、物理化学模型、数学模型等。(3)网络模型与算法研究。
在理论模型研究的基础上构作具体的神经网络模型,以实现计算机模拟或准备制作硬件,包括网络学习算法的研究。这方面的工作也称为技术模型研究。(4)人工神经网络应用系统。
在网络模型与算法研究的基础上,利用人工神经网络组成实际的应用系统,例如,完成某种信号处理或模式识别的功能、构作专家系统、制成机器人等等。
纵观当代新兴科学技术的发展历史,人类在征服宇宙空间、基本粒子,生命起源等科学技术领域的进程中历经了崎岖不平的道路。我们也会看到,探索人脑功能和神经网络的研究将伴随着重重困难的克服而日新月异。
神经网络可以用作分类、聚类、预测等。神经网络需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。
在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。虽然bp网络得到了广泛的应用,但自身也存在一些缺陷和不足,主要包括以下几个方面的问题。
首先,由于学习速率是固定的,因此网络的收敛速度慢,需要较长的训练时间。
对于一些复杂问题,bp算法需要的训练时间可能非常长,这主要是由于学习速率太小造成的,可采用变化的学习速率或自适应的学习速率加以改进。
其次,bp算法可以使权值收敛到某个值,但并不保证其为误差平面的全局最小值,这是因为采用梯度下降法可能产生一个局部最小值。对于这个问题,可以采用附加动量法来解决。
再次,网络隐含层的层数和单元数的选择尚无理论上的指导,一般是根据经验或者通过反复实验确定。因此,网络往往存在很大的冗余性,在一定程度上也增加了网络学习的负担。最后,网络的学习和记忆具有不稳定性。
也就是说,如果增加了学习样本,训练好的网络就需要从头开始训练,对于以前的权值和阈值是没有记忆的。但是可以将预测、分类或聚类做的比较好的权值保存。
谷歌人工智能写作项目:小发猫

深度神经网络具体的工作流程是什么样的?
第一,深度神经网络不是黑盒,个人电脑开机直到神经网络运行在内存中的每一比特的变化都是可以很细微的观察的AI爱发猫。没有任何神秘力量,没有超出科学解释的现象发生。
第二,深度神经网络的工作方式是基于传统的电脑架构之上的,就是数据+算法。但人们确实从中窥探到了一种全新的电子大脑方式。所以目前有研究提炼一些常用神经网络算法加速硬件。微软等巨头则在开发量子计算。
第三,深度神经网络是一个很初级的特征自动提取器。说初级因为简单粗暴。以前为了节约算力特征关键模型都是人工亲自设定。而现在这部分工作随着算力的提高可以自动化。
所以从某种意义上来说深度神经网络也是一种自动编程机,但和人们相比,一点点小小的自动化都需要很多很多的计算力支持,这一点也不重要,重要的是,它能工作(手动英文)。那么深度神经网络究竟是什么呢?
它是一个能迭代更新自己的特征提取算法。现在这个算法可是像全自动高级工厂,数据往里一丢,不得了!整个工厂里面所有机器都动了起来。没见过的小伙伴当场就被吓呆瓜了,用流行的话说叫懵住。
几千只机械手把数据搬来搬去,拿出魔方一样的盒子装来装去又倒出来。整个场面就叫一个震撼。算法运行规模也更大了。
什么是神经网络学习呢
神经网络的学习,也就是训练过程,指的是输入层神经元接收输入信息,传递给中间层神经元,最后传递到输出层神经元,由输出层输出信息处理结果的过程。
在这个过程中,神经网络通过不断调整网络的权值和阈值,达到学习、训练的目的,当网络输出的误差减少到可以接受的程度,或者预先设定的学习次数后,学习就可以停止了。
什么神经网络训练学习?学习有哪几种方式?
想要学习人工神经网络,需要什么样的基础知识?
人工神经网络理论百度网盘下载:链接: 提取码:rxlc简介:本书是人工神经网络理论的入门书籍。全书共分十章。
第一章主要阐述人工神经网络理论的产生及发展历史、理论特点和研究方向;第二章至第九章介绍人工神经网络理论中比较成熟且常用的几种主要网络结构、算法和应用途径;第十章用较多篇幅介绍了人工神经网络理论在各个领域的应用实例。
。
神经网络应用分几个具体步骤?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)