Deep Learning:Foundations and Concepts - 第1章 深度学习的变革 (学习笔记)
本文是Christopher M. Bishop与Hugh Bishop新书《Deep Learning: Foundations and Concepts》的读书笔记,主要探讨深度学习的基础理论与核心概念。书中首先介绍了深度学习在医学诊断、蛋白质结构预测、图像生成和大语言模型等领域的重大影响。通过正弦函数拟合示例,引出机器学习的关键概念如模型复杂度、正则化和模型选择问题。作者梳理了深度学习的发展
本文是Christopher M.Bishop & Hugh Bishop的新书Deep Learning:Foundations and Concepts英文版读书笔记, 而本书作者的前作则是大名鼎鼎的机器学习"圣经"——PRML(Pattern Recognization and Machine Learning)随着如今深度学习大语言模型的发展,时隔近二十年后,作者也与时俱进,出版了这本关于深度学习的书籍。
文本内容取自官方在线阅读网站https://issuu.com/cmb321/docs/deep_learning_ebook
一、内容概览: 1-深度学习的变革
这个部分是对原书内容的一个简要的介绍
1.1 深度学习带来的影响
这一小节主要讲述了如今人工智能/机器学习的主流方向: 深度学习Deep Learning是如何带来影响的, 在哪些领域有着重要的实践. 主要举了四个比较典型的例子, 分别是
- 医学(影像)诊断 Medical Diagnosis
- 蛋白质结构预测 Protein Structure
- 图像合成/生成 Image Synthesis
- 大语言模型 Large Language Models
1.2 一个教学示例
这个小节则是通过一个简单的例子, 由正弦函数+随机误差生成的数据, 使用线性函数-多项式函数去尝试拟合这些数据。作为引子, 引出了很多机器学习比较深刻的概念, 包括线性模型(多项式模型)、误差函数、以及由之引出的欠拟合/过拟合问题, 它与模型的复杂度有关, 而为了解决这个问题, 我们引入了正则化, 和模型复杂度(阶数)这些作为超参数, 并讨论了这些超参数的选择, 即模型选择的问题。
具体章节安排如下:
- 数据合成
- 线性模型
- 误差函数
- 模型复杂度
- 正则化
- 模型选择
1.3 深度学习简史
这个小节实际上叫"A Brief History of Machine Learning", 但我更想称其为深度学习的简史. 因为机器学习有很多的分支, 而作者也提到这些分支实际上大多都没落了, 如今深度学习是这些分支中走的最远的一个, 因此选择深度学习的发展历史作为机器学习简史.
如今发展的如火如荼的深度学习领域, 其发展阶段可以分为三个, 分别是
- 早期感知机阶段
- 多层感知机/全连接神经网络
- 深度神经网络
二、正文批注/思考
(1)关于本书的内容安排
“For example, large language models have been evolving very rapidly at the time of writing, yet the underlying transformer architecture and attention mechanism have remained largely unchanged for the last five years, while many core principles of machine learning have been known for decades.” (Bishop 和 Bishop, 2024, p. v) (pdf)
这个部分揭示了为什么作者认为即使是大语言模型出现的今天, 我们仍然需要学习这些基础的深度学习理论, 因为近五年以内的LLM其底层架构仍然是Transformer和注意力机制, 机器学习的核心原则仍然适用于这些模型
(2)本书与前作PRML的区别
“For example, Bishop (2006) discusses Bayesian methods in some depth, whereas this book is almost entirely non-Bayesian.” (Bishop 和 Bishop, 2024, p. vii) (pdf)
好吧, 这本书和PRML确实不一样, PRML着眼于使用贝叶斯方法/思想去理解机器学习; 而这本书是没有使用这个思想的.
(3)本书的写作方式
“In the spirit of focusing on core ideas, we make no attempt to provide a comprehensive literature review, which in any case would be impossible given the scale and pace of change of the field. We do, however, provide references to some of the key research papers as well as review articles and other sources of further reading. In many cases, these also provide important implementation details that we gloss over in the text in order not to distract the reader from the central concepts being discussed.” (Bishop 和 Bishop, 2024, p. vii) (pdf)
这个片段里作者讲述了为什么他们不提到过多的参考文献, 因为这样会让人分心,走神…他们不是想写文献综述, 而是专注于介绍理论本身.
(4)迁移学习的概念

(Bishop 和 Bishop, 2024, p. 3) 这里作者谈到的是迁移学习, 也就是先用超大型数据集先与训练出一个模型, 这个模型本身就具有一定的通用识别能力, 然后再根据少量的业务数据集进行训练微调参数, 使这个模型更加地Specialized.
我们比较熟悉的YOLO模型是否是用来做迁移学习的呢?
(5)关于蛋白质结构预测的这一应用
“Protein structure prediction is therefore another example of supervised learning. Once the system is trained it can take a new amino acid sequence as input and can predict the associated 3D structure (Jumper et al., 2021).” (Bishop 和 Bishop, 2024, p. 4) (pdf)
前面提到的AlphaFold正是2024年诺贝尔化学奖的获奖者, 根据作者在这一段的简单描述, 我们能得知这个神经网络的输入是氨基酸的序列/肽链, 而输出则是它最有可能的蛋白质三维折叠结构; 结合上面的图像Figure1.2 来看,其吻合度是相当高的.
(6)LLM的基本原理

(Bishop 和 Bishop, 2024, p. 5) 这个地方主要是讲了一些关于LLM的基本原理, 它是根据前面的文字然后将后面的一个一个字"吐"出来再接成一句话的. 其实就像是之前看关于大模型的介绍视频说的那样, LLM就像是一个牙牙学语的鹦鹉.
(7)统计学习背后的理论依据
(Bishop 和 Bishop, 2024, p. 8) 这里提到了预测本身存在不确定性, 因为随机变量的干扰, 但作者也提到了概率论与决策论为我们进行合理的预测提供了理论支撑.
尤其是说到后面的决策论, 在学习统计学习的各种模型时, 我们常用的步骤都是:
- 选定输入(特征)-输出变量(因变量)
- 根据实际需求选择一个准则, 并依据改准则构建出一个指标函数/误差函数/目标函数
- 以模型参数为自变量, 对这个目标函数进行优化, 转化为一个求最值的问题, 找到能使目标函数达到最值的的模型参数;
这个步骤在各种统计学习的模型中常常出现, 现在看来这背后是决策论的思想.
(8)关于多项式函数, 其高阶与低阶的关系
“This may seem paradoxical because a polynomial of a given order contains all lower-order polynomials as special cases. The M = 9 polynomial is therefore capable of generating results at least as good as the M = 3 polynomial. Furthermore, we might suppose that the best predictor of new data would be the function sin(2πx) from which the data was generated (and we will see later that this is indeed the case). We know that a power series expansion of the function sin(2πx) contains terms of all orders, so we might expect that results should improve monotonically as we increase M.” (Bishop 和 Bishop, 2024, p. 11) (pdf)
有点意思, 高阶模型是低阶模型的扩展, 低阶模型是高阶模型的特例. 那按理来说我们不应该越高阶越好吗
并且, 根据Taylor公式, 产生这这些数据的"内在规律"是正弦函数, 它是包含了所有阶的多项式;
(9)为什么这里高阶模型的拟合失效了?因为数据量不够, 数据带有噪声
“Intuitively, what is happening is that the more flexible polynomials with larger values of M are increasingly tuned to the random noise on the target values. Further insight into this phenomenon can be gained by examining the behaviour of the learned model as the size of the data set is varied, as shown in Figure 1.8.” (Bishop 和 Bishop, 2024, p. 11) (pdf)
确实, 因为有噪声的存在, 这就导致了即使是使用标准的"规律", 也会有误差存在. 但过于复杂的模型可能会导致模型朝着噪声拟合了…诶, 朝着零散的, 带有噪声的少数点拟合, 为什么会导致权重过于吓人呢?结合下面的来看, 为什么数据量增大可以缓解过拟合现象呢?
(10)关于正则化的一些思考
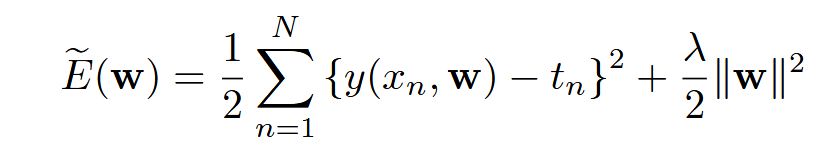
(Bishop 和 Bishop, 2024, p. 13) 本质上就是引入不同的约束条件, L1正则化引入的是绝对值约束, 可以理解为曼哈顿距离?; L2正则化引入的是模长/欧几里得距离约束
“We cannot simply determine the value of λ by minimizing the error function jointly with respect to w and λ since this will lead to λ → 0 and an over-fitted model with small or zero training error.” (Bishop 和 Bishop, 2024, p. 14) (pdf)
开始反思, 这里的部分提醒了我不能单纯的把它视为一般的条件优化问题
(12)关于第二节的总结
“This simple example of fitting a polynomial to a synthetic data set generated from a sinusoidal function has illustrated many key ideas from machine learning, and we will make further use of this example in future chapters.” (Bishop 和 Bishop, 2024, p. 15) (pdf)
确实如此, 这个例子很简单, 但又可以作为引子引出很多机器学习的深刻概念, 包括像模型选择, 欠/过拟合, 正则化, 超参数选取以及交叉验证等等.
(13)神经网络的第一次低谷
“An important change was to replace the step function (1.7) with continuous differentiable activation functions having a non-zero gradient. Another key modification was to introduce differentiable error functions that define how well a given choice of parameter values predicts the target variables in the training set.” (Bishop 和 Bishop, 2024, p. 18) (pdf)
这背后可能隐藏着曾经桎梏MLP的原因, 即缺失的有效优化算法
(14)数据预处理问题
“To achieve reasonable performance on many applications, it was necessary to use hand-crafted pre-processing to transform the input variables into some new space where, it was hoped, the machine learning problem would be easier to solve.” (Bishop 和 Bishop, 2024, p. 20) (pdf)
一些传统数字图像处理的用武之地?
三、一些收获
(1) 一个有趣的统计学经验
经典统计学中有时提倡的一种粗略的启发式方法是,数据点的数量应不少于模型中可学习参数数量的倍数(比如 5 或 10)。
(Bishop 和 Bishop, 2024, p. 12)
这是一个有趣的经验结论, 不知道这个准则在统计学里叫什么名字?
四、未解决的疑问
Q1: 关于自监督学习与无监督学习的区别
“self-supervised learning” (Bishop 和 Bishop, 2024, p. 5) (pdf) 这个自监督和监督学习的区别说的是挺清晰的, 但是这个不用人工标记数据集的训练就是自监督吗? 不能是无监督吗?
Q2: 误差函数表达式是否准确?
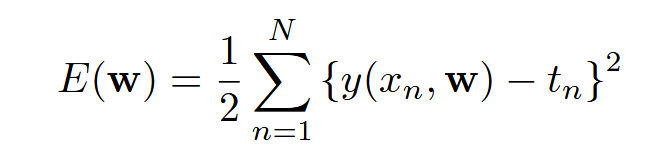
(Bishop 和 Bishop, 2024, p. 9) 这个表达式准确吗? 这个就是期望本身而不是估计量?
Q3: 二次函数的误差函数, 其导数为线性函数能导出只有唯一解吗?
“a unique solution,” (Bishop 和 Bishop, 2024, p. 9) (pdf) 如何确定就是唯一解? 线性方程组也会出现无穷个解的对吗?
Q4: 关于过拟合的产生原因…
“Intuitively, what is happening is that the more flexible polynomials with larger values of M are increasingly tuned to the random noise on the target values. Further insight into this phenomenon can be gained by examining the behaviour of the learned model as the size of the data set is varied, as shown in Figure 1.8.” (Bishop 和 Bishop, 2024, p. 11) (pdf)
为什么会导致权重过于吓人呢?结合下面的来看, 为什么数据量增大可以缓解过拟合现象呢?
Q5: 这个图像坐标轴是否存在问题?
(Bishop 和 Bishop, 2024, p. 14) 为什么底下的M是负的呢?
Q6: 感知机的缺陷, 什么是只有一层能学习?
“A typical perceptron configuration had multiple layers of processing, but only one of those layers was learnable from data, and so the perceptron is considered to be a ‘single-layer’ neural network.” (Bishop 和 Bishop, 2024, p. 18) (pdf)
只有一层能学习?这是什么意思?
Q7: 感知机的局限究竟是什么呢?
“The properties of perceptrons were analysed by Minsky and Papert (1969), who gave formal proofs of the limited capabilities of single-layer networks. Unfortunately, they also speculated that similar limitations would extend to networks having multiple layers of learnable parameters.” (Bishop 和 Bishop, 2024, p. 18) (pdf)
啥意思呢? 明斯基他们是怎么证明的? 所以说他们的推论是错误的吗?
Q8: 原文表述略带术语, 没看明白
“One key insight is that learning from data involves background assumptions, sometimes called prior knowledge or inductive biases. These might be incorporated explicitly,” (Bishop 和 Bishop, 2024, p. 19) (pdf)
没看明白, 里面提到了很多术语…
Q9: 为什么说NN只有最后两层有效参数?
“However, it was also observed that in networks with many layers, it was only weights in the final two layers that would learn useful values.” (Bishop 和 Bishop, 2024, p. 20) (pdf)
什么意思? 原书并没有讲述清楚这里的细节.
Q10: NN在第二阶段没落的真正原因有哪些?
“A series of developments allowed neural networks with many layers of weights to be trained effectively, thereby removing previous limitations on the capabilities of these techniques.” (Bishop 和 Bishop, 2024, p. 20) (pdf)
这个地方还是没讲清楚, 以前的NN问题是在哪呢? 是和前面的只有两层有效相关吗? 还是训练的问题?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)