自然语言处理-命名实体识别实验(CRF条件随机场实现)
一、概念命名实体识别(Named Entity Recognition,NER)中的“命名实体”一般是指文本中具有特别意义或者指代性非常强的实体,可分为三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)。命名实体识别的任务就是识别出文本中的命名实体,通常分为两个过程:实体边界识别和实体类别的确定。二、问题转化中文命名实体识别的本质就是序列标注。设定3种命名实体
一、概念
命名实体识别(Named Entity Recognition,NER)中的“命名实体”一般是指文本中具有特别意义或者指代性非常强的实体,可分为三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)。
命名实体识别的任务就是识别出文本中的命名实体,通常分为两个过程:实体边界识别和实体类别的确定。
二、问题转化
中文命名实体识别的本质就是序列标注。
设定3种命名实体标注符号PER、LOC、ORG分别代表人名、地名、机构名;3种命名实体标注符号B、I、O分别代表实体开始、实体中间、其它。
这样就有7种标记L={B-PER,I-PER,B-LOC,I-LOC,B-ORG,I-ORG,O},这样就把命名实体识别转换成了每个字的分类问题。例如:
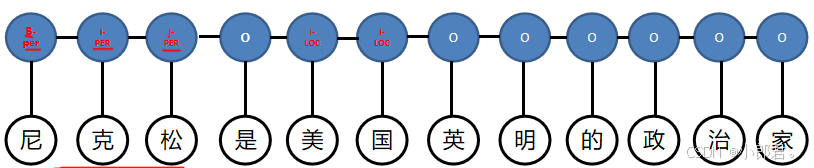
尼克松是一个人名吧,那就把开始的一个字‘尼’标注为 实体开始 ,即B-PER,其他的字标注为实体中间,即I-PER,依次类推标注其他命名实体。
这样就可以用分类模型去做了吧,但要注意以下几点:
- 中文词灵活多变:有些词语在不同语境下可能是不同的实体类型,辽宁有个市叫“沈阳”,也有一些人名叫“沈阳”。有些取名叫“高富帅”,但“高富帅” 是一个现代流行的形容词。
- 中文词的嵌套情况复杂:一些中文的命名实体中常常嵌套另外一个命名实体,如“北京大学附属中学”
- 中文词存在简化表达现象:通常对一些较长的命名实体词进行简化表达,如“北京大学”通常简化为“北大”,“北京大学附属中学”通常简化为“北大附中”
所以也并不是一个简单的分类,要把这些问题都考虑进模型中。
三、方法
主要有三大类方法
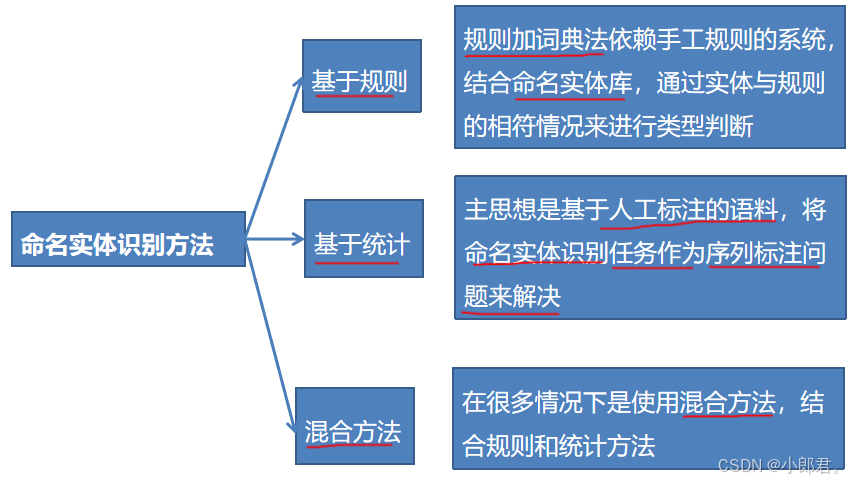
有了方法,那就构建模型呗,下面是基于统计的模型
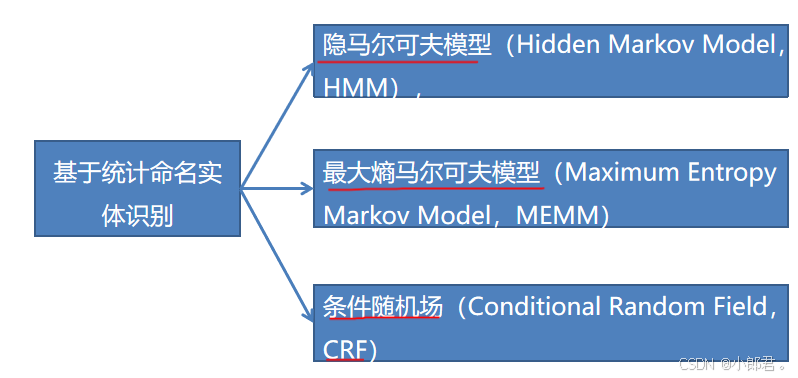
四、CRF模型
这里简单介绍一下CRF模型,
**条件随机场(Conditional Random Fields, CRF)**是一种用于序列标注的概率图模型,广泛应用于自然语言处理任务,如命名实体识别(NER)、词性标注等。
CRF模型思想主要来源于最大熵模型。观察序列 X 和标注序列 Y 的条件概率 P(Y∣X),直接最大化条件概率来训练模型,相对于HMM和最大熵马尔可夫模型(MEMM),CRF模型它没有HMM那样严格的独立性假设,克服了MEMM标记偏置的缺点。
- 序列标注任务:给定输入序列
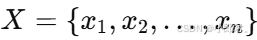 ,预测对应标注序列
,预测对应标注序列 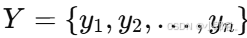 。
。 - CRF假设 Y 的条件概率可以通过一个图结构建模,常用的是线性链CRF。
1. 特征设计
因为输入序列X一般是一段文本序列,机器学习算法是不能直接使用的,需要将它们转化成机器学习算法可以识别的数值特征,然后再交给机器学习的算法进行操作。对于序列标注问题,需要先对输入序列进行特征提取。
"设随机变量X取值记为x,Y取值记为y。序列x的特征提取是通过构建特征函数来完成的。特征函数包含四个参数,分别为文本x、参数i(表示文本x中第i个词)、(第i个词的标注值)和
(第i+1个词的标注值)。因为linear-CRF 满足马尔科夫性,所以只有上下文相关的局部特征函数,没有不相邻节点之间的特征函数。

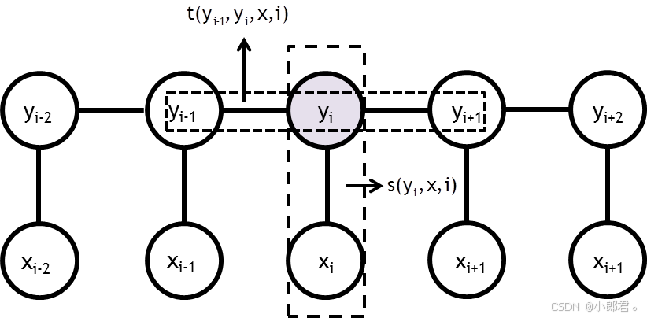
那么特征函数可以按照以下去定义,主要有两类:状态特征函数s和转移特征函数t,其中s特征函数只和当前节点有关,t特征函数与当前节点和上一个节点有关。

例如:假设x=“我去广州旅游”,标注的状态集合为S={B,I.O},分别代表命名实体的开始、实体中间、其它。设定两个特征函数s、t。
对于“广”字来说:S是一个标签集合,里面有三个标签,对于每个标签类都有一个值(0或者1)去表示,即s特征函数。t函数就是yi-1和yi满足某种搭配条件,这个特征函数考虑了当前节点和上一个节点。


2. 模型构建
线性链CRF的条件概率分布定义为:
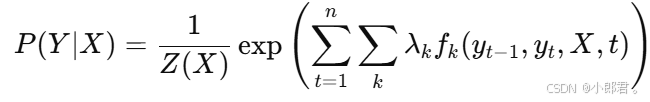
其中:
:特征函数,描述标注
、
和观察序列 X 的关系。
:特征权重,通过训练学习得到。
- Z(X):归一化因子,是所有可能标记序列的和。
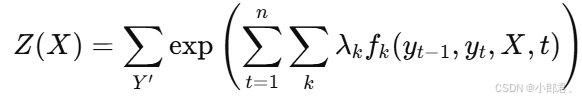
3. 模型训练
训练目标是最大化条件概率 P(Y∣X)
![]()
即最小化对数似然损失:
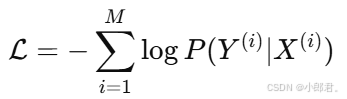
有了目标函数,那就用最优化的方法求呗,通过梯度下降(如LBFGS、AdaGrad等)求得最优参数 。
五、当前主流的命名实体识别(NER)模型
随着深度学习的发展,NER任务从传统机器学习逐渐转向深度学习,当前主流的NER模型可以分为以下几类:
1. 基于BiLSTM-CRF的模型
这种模型结合了双向LSTM和CRF的优势:
-
BiLSTM:从上下文中捕捉长距离依赖信息。
-
CRF:对输出序列进行全局优化,解决标注一致性问题。
特点:
-
高效处理序列依赖。
-
已成为NER的经典深度学习基线模型。
2. 基于Transformer的模型
Transformer是当前最主流的架构,尤其是基于预训练模型的NER方法取得了显著进展。
-
BERT-based NER:BERT预训练模型通过Fine-tuning用于NER,利用其强大的上下文表示能力。
-
RoBERTa, GPT, T5等模型也可用于NER任务。
特点:
-
不需要额外的特征工程。
-
对低资源场景表现出色。
3. 基于混合架构的模型
- CNN-BiLSTM-CRF:结合CNN捕捉局部特征、BiLSTM获取全局特征,以及CRF的序列标注能力。
- Transformer + CRF:在Transformer输出层加上CRF,进一步增强序列依赖建模。
六、使用sklearn-crfsuite库进行命名实体识别的代码实现
中文命名实体识别中,比较常见的是对文本中的时间、人名、地名及组织机构名四种类型进行识别。
sklearn-crfsuite是基于CRFsuite库的一款轻量级的CRF库,提供了条件随机场的训练、预测及评测方法。该库可兼容sklearn算法,因此可以结合sklearn库的算法设计命名实体识别系统。CRFsuite 是基于C/C++实现了条件随机场模型,可用于快速训练和序列标注。
代码运行准备前工作!!!!看重点
1、降级numpy,降到1.x版本,因为有的模块可能不支持2.x版本。
如果你用的pycharm,在pycharm里找到设置,在右侧找到:
接着找到numpy和上边“-”卸载,再点“+”重新安装:
2、安装其他用到的库,输入代码后,代码检查器会自动提示你没有哪些库,按照上边的安装即可。
3、修改代码中训练数据路径,我用的是1980_01rmrb.txt文本进行训练的,我也会把这个数据放到文章末尾;修改保存预处理后的文本数据路径和名字,我用的wzm.txt保存的;修改保存的模型参数文件路径和名字,我用的wzm.pkl。而且他们都在一个data的文件夹下,所以路径这点小问题你就看着办吧。
我建议你在你代码所在路径下新建一个data文件夹,然后只用把1980_01rmrb.txt文件放进去,其他不用管。
啰嗦这么多,终于上代码。第一次训练时间有点长,没事,也很快。
训练数据格式:词/词性 以空格分开

# 代码3-22
import joblib
import sklearn
import sklearn_crfsuite
from sklearn_crfsuite import metrics
class CorpusProcess(object):
def __init__(self):
# 定义属性 process_corpus_path 和 raw_corpus_path
self.process_corpus_path = r"data\wzm.txt"
self.raw_corpus_path = r"data\1980_01rmrb.txt"
self.tag_seq = []
self.word_seq = []
self._maps = {
"nr": "PER", # 人名
"ns": "LOC", # 地名
"nt": "ORG", # 机构名
# 可以根据具体需求补充映射规则
}
# 由词性提取标签
def pos_to_tag(self, p):
t = self._maps.get(p, None)
return t if t else 'O'
# 标签使用BIO模式
def tag_perform(self, tag, index):
if index == 0 and tag != 'O':
return 'B_{}'.format(tag)
elif tag != 'O':
return 'I_{}'.format(tag)
else:
return tag
#全角转半角
def q_to_b(self, q_str):
b_str = ""
for uchar in q_str:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格直接转换
inside_code = 32
elif 65374 >= inside_code >= 65281: # 全角字符(除空格)根据关系转化
inside_code -= 65248
b_str += chr(inside_code)
return b_str
# 语料初始化
def initialize(self):
self.process_corpus_path = r"data\wzm.txt"
lines = self.read_corpus_from_file(self.process_corpus_path)
words_list = [line.strip().split(' ') for line in lines if line.strip()]
del lines
self.init_sequence(words_list)
# 初始化字序列、词性序列
def init_sequence(self, words_list):
words_seq = [[word.split('/')[0] for word in words] for words in words_list]
pos_seq = [[word.split('/')[1] for word in words] for words in words_list]
tag_seq = [[self.pos_to_tag(p) for p in pos] for pos in pos_seq]
self.tag_seq = [[[self.tag_perform(tag_seq[index][i], w)
for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))]
for index in range(len(tag_seq))]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [['<BOS>'] + [w for word in word_seq for w in word]
+ ['<EOS>'] for word_seq in words_seq]
# 窗口切分
def segment_by_window(self, words_list, window=3):
words = []
begin, end = 0, window
for _ in range(1, len(words_list)):
if end > len(words_list):
break
words.append(words_list[begin: end])
begin = begin + 1
end = end + 1
return words
# 特征提取
def extract_feature(self, word_grams):
features, feature_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])):
word_gram = word_grams[index][i]
feature = {'w-1': word_gram[0],
'w': word_gram[1], 'w+1': word_gram[2],
'w-1:w': word_gram[0] + word_gram[1],
'w:w+1': word_gram[1] + word_gram[2],
'bias': 1.0}
feature_list.append(feature)
features.append(feature_list)
feature_list = []
return features
# 训练数据
def generator(self):
word_grams = [self.segment_by_window(word_list) for word_list in self.word_seq]
features = self.extract_feature(word_grams)
return features, self.tag_seq
# 读取文件
def read_corpus_from_file(self, process_corpus_path):
with open(process_corpus_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
return lines
def pre_process(self):
self.raw_corpus_path = r"data\1980_01rmrb.txt"
# 加载原始语料文件
lines = self.read_corpus_from_file(self.raw_corpus_path)
# 清洗和规范化处理
processed_lines = [self.q_to_b(line.strip()) for line in lines if line.strip()]
# 保存预处理结果到新的路径
with open(self.process_corpus_path, 'w', encoding='utf-8') as f:
f.writelines('\n'.join(processed_lines))
# 代码3-23
class CRF_NER(object):
# 初始化CRF模型参数
def __init__(self):
self.algorithm = 'lbfgs'
self.c1 = '0.1'
self.c2 = '0.1'
self.max_iterations = 100 # 迭代次数
self.model_path = 'data/wzm.pkl'
self.corpus = CorpusProcess() # 加载语料预处理模块
self.model = None
# 定义模型
def initialize_model(self):
self.corpus.pre_process() # 语料预处理
self.corpus.initialize() # 初始化语料
algorithm = self.algorithm
c1 = float(self.c1)
c2 = float(self.c2)
max_iterations = int(self.max_iterations)
self.model = sklearn_crfsuite.CRF(algorithm=algorithm, c1=c1, c2=c2,
max_iterations=max_iterations,
all_possible_transitions=True)
# 模型训练
def train(self):
self.initialize_model()
x, y = self.corpus.generator()
x_train, y_train = x[500:], y[500:]
x_test, y_test = x[:500], y[:500]
self.model.fit(x_train, y_train)
# 获取标签
labels = list(self.model.classes_)
labels.remove('O')
# 预测
y_predict = self.model.predict(x_test)
# 计算 F1 分数
f1_score = metrics.flat_f1_score(
y_test, y_predict, average='weighted', labels=labels
)
print(f"F1 Score: {f1_score}")
# 分类报告
sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
print(metrics.flat_classification_report(
y_test, y_predict, labels=sorted_labels, digits=3
))
# 保存模型
joblib.dump(self.model, self.model_path)
def predict(self, sentence):
# 尝试加载模型
try:
self.model = joblib.load(self.model_path)
except FileNotFoundError:
raise FileNotFoundError(f"模型文件未找到: {self.model_path}")
except EOFError:
raise EOFError(f"模型文件损坏或不完整: {self.model_path}")
except Exception as e:
raise RuntimeError(f"加载模型时发生未知错误: {e}")
# 预处理输入语句
u_sent = self.corpus.q_to_b(sentence)
word_lists = [['<BOS>'] + [c for c in u_sent] + ['<EOS>']]
word_grams = [
self.corpus.segment_by_window(word_list) for word_list in word_lists]
features = self.corpus.extract_feature(word_grams)
# 使用模型预测
y_predict = self.model.predict(features)
entity = ''
for index in range(len(y_predict[0])):
if y_predict[0][index] != 'O':
if index > 0 and (
y_predict[0][index][-1] != y_predict[0][index - 1][-1]):
entity += ' '
entity += u_sent[index]
elif entity and entity[-1] != ' ':
entity += ''
return entity
# 代码3-24:主程序逻辑,确保训练后再进行预测
import os
# 初始化实体识别类
ner = CRF_NER()
# 检查模型是否存在
if not os.path.exists(ner.model_path):
print(f"模型文件未找到: {ner.model_path},开始训练模型...")
ner.train()
print("模型训练完成!")
# 进行预测
sentence1 = '香港回归23周年升旗仪式今天(7月1日)8时在金紫荆广场举行。行政长官'\
'林郑月娥、一众特区政府官员、中央机构驻港代表及外国驻港使节等约100人出席。'
output1 = ner.predict(sentence1)
print("预测结果:", output1)
训练数据下载,记得替换文件名为1980_01rmrb.txt

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 49
49 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)