在机器学习中,怎么对超参数Hyper parameter优化?我总结了以下常见的方法
@Author:Runsen机器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter)。还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper parameter)。超参数是在开始学习过程之前设置值的参数。相反,其他参数的值通过训练得出。在机器学习中,怎么对超参数Hyper parameter优化?我总结了以下常见的方法超参数优化超
@Author:Runsen
机器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter)。还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper parameter)。超参数是在开始学习过程之前设置值的参数。相反,其他参数的值通过训练得出。
在机器学习中,怎么对超参数Hyper parameter优化?我总结了以下常见的方法
超参数优化
超参数优化是机器/深度学习中最常见的方法之一。机器学习模型调优是一种优化问题。我们有一组超参数(例如学习率、隐藏单元的数量等),我们的目标是找出最小值(例如损失)或最大值(例如精度)的组合。
使用的数据集是信用卡欺诈检测 Kaggle 数据集,具体下载链接:https://www.kaggle.com/mlg-ulb/creditcardfraud
import pandas as pd
df = pd.read_csv("creditcard.csv")
首先,我们需要将数据集划分为训练集和测试集。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X = df[['V17', 'V9', 'V6', 'V12']]
Y = df['Class']
X = StandardScaler().fit_transform(X)
X_Train, X_Test, Y_Train, Y_Test = train_test_split(X, Y, test_size = 0.30,
random_state = 101)
在本文中,我们将使用随机森林分类器作为我们的模型进行优化。
随机森林模型由大量不相关的决策树组成,它们共同构成一个集成。在随机森林中,每个决策树都做出自己的预测,并且选择整体模型输出作为出现频率最高的预测。
我们现在可以开始计算我们的基本模型精度。
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
model = RandomForestClassifier(random_state= 101).fit(X_Train,Y_Train)
predictionforest = model.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc1 = accuracy_score(Y_Test,predictionforest)
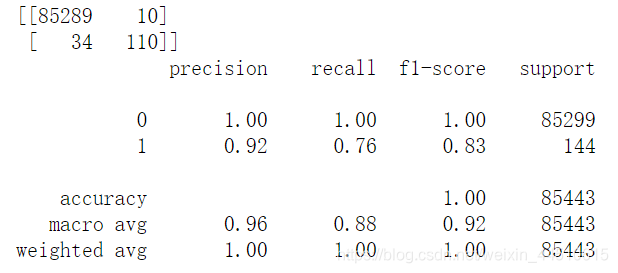
使用带有默认 scikit-learn 参数的随机森林分类器可实现预测0的 100% 的整体准确率和预测1的92%的整体准确率。现在让我们看看是否应用一些优化技术我们可以获得更好的准确性。
现在让我们看看是否应用一些优化技术我们可以获得更好的准确性。
手动搜索
使用手动搜索时,我们会根据自己的判断/经验选择一些模型超参数。然后我们训练模型,评估其准确性并再次开始该过程。重复此循环,直到获得令人满意的准确度。
随机森林分类器使用的主要参数是:
- criterion = 用于评估拆分质量的函数。
- max_depth = 每棵树允许的最大级别数。
- max_features = 拆分节点时考虑的最大特征数。
- min_samples_leaf = 可以存储在树叶中的最小样本数。
- min_samples_split = 节点中导致节点分裂所需的最小样本数。
- n_estimators = 集成树的数量。
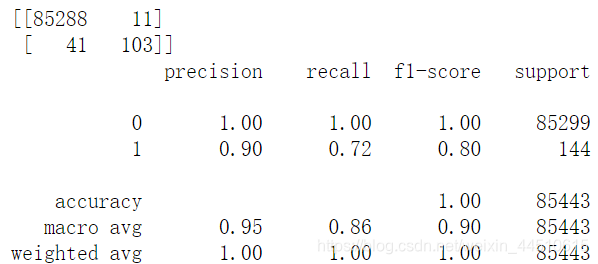
作为手动搜索的一个例子,我试图在我们的模型中指定估计器的数量。不幸的是,这并没有导致准确性的任何提高。
model = RandomForestClassifier(n_estimators=10, random_state= 101).fit(X_Train,Y_Train)
predictionforest = model.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc2 = accuracy_score(Y_Test,predictionforest)
随机搜索
在随机搜索中,我们创建了一个超参数网格,并仅在这些超参数的一些随机组合上训练/测试我们的模型。在这个例子中,我还决定对训练集执行交叉验证。
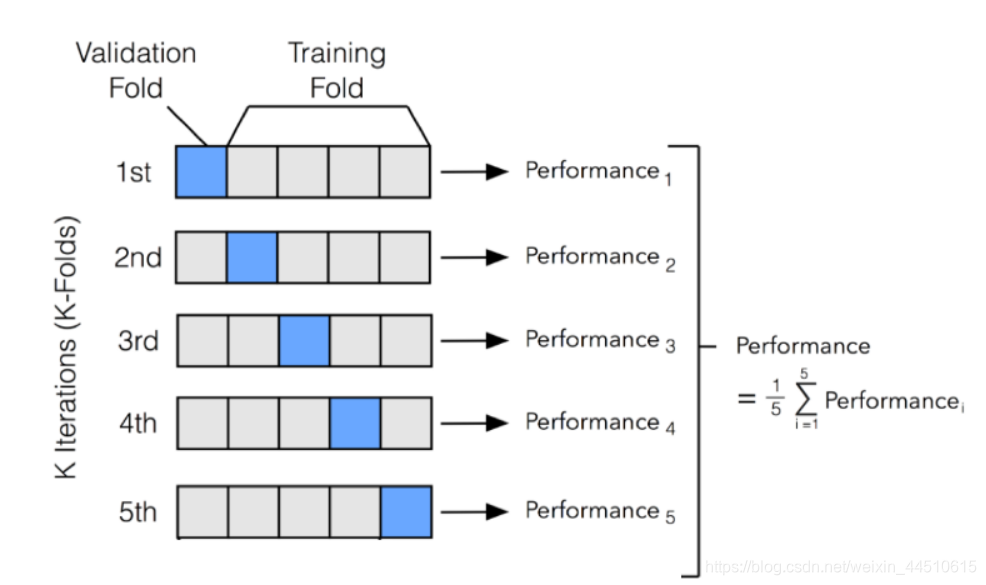
在执行机器学习任务时,我们通常将数据集划分为训练集和测试集。这样做是为了在训练后测试我们的模型(这样我们可以在处理看不见的数据时检查它的性能)。使用交叉验证时,我们将训练集划分为 N 个其他分区,以确保我们的模型不会过度拟合我们的数据。
最常用的交叉验证方法之一是 K 折验证。在 K-Fold 中,我们将训练集划分为 N 个分区,然后使用 N-1 个分区迭代训练我们的模型,并使用剩余分区进行测试(在每次迭代中我们更改剩余分区)。一旦对模型进行了 N 次训练,我们就可以对每次迭代中获得的训练结果进行平均以获得我们的整体训练性能结果。
我们现在可以通过首先挑战超参数网格来开始实现随机搜索,当调用RandomizedSearchCV()时,超参数网格将被随机采样。
对于这个例子,我决定将我们的训练集划分为 4 折(cv = 4)并选择 80 作为要采样的组合数(n_iter = 80)。使用 scikit-learn best_estimator_属性,然后我们可以检索在训练期间表现最佳的超参数集以测试我们的模型。
import numpy as np
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
random_search = {'criterion': ['entropy', 'gini'],
'max_depth': list(np.linspace(10, 1200, 10, dtype = int)) + [None],
'max_features': ['auto', 'sqrt','log2', None],
'min_samples_leaf': [4, 6, 8, 12],
'min_samples_split': [5, 7, 10, 14],
'n_estimators': list(np.linspace(151, 1200, 10, dtype = int))}
clf = RandomForestClassifier()
model = RandomizedSearchCV(estimator = clf, param_distributions = random_search, n_iter = 80,
cv = 4, verbose= 5, random_state= 101, n_jobs = -1)
model.fit(X_Train,Y_Train)

一旦训练了我们的模型,我们就可以可视化更改其某些超参数如何影响整体模型精度。
import seaborn as sns
table = pd.pivot_table(pd.DataFrame(model.cv_results_),
values='mean_test_score', index='param_n_estimators',
columns='param_criterion')
sns.heatmap(table)

predictionforest = model.best_estimator_.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc3 = accuracy_score(Y_Test,predictionforest)

网格搜索
在网格搜索中,我们设置了一个超参数网格,并在每个可能的组合上训练/测试我们的模型。
为了选择在网格搜索中使用的参数,我们现在可以查看哪些参数最适合随机搜索,并根据它们形成一个网格,看看是否可以找到更好的组合。
网格搜索可以使用 scikit-learn GridSearchCV()函数在 Python 中实现。同样在这种情况下,我决定将我们的训练集分成 4 折(cv = 4)。
使用网格搜索时,会尝试网格中所有可能的参数组合。在这种情况下,训练期间将使用 128000 个组合(2 × 10 × 4 × 4 × 4 × 10)。相反,在之前的网格搜索示例中,仅使用了 80 种组合。
from sklearn.model_selection import GridSearchCV
grid_search = {
'criterion': [model.best_params_['criterion']],
'max_depth': [model.best_params_['max_depth']],
'max_features': [model.best_params_['max_features']],
'min_samples_leaf': [model.best_params_['min_samples_leaf'] - 2,
model.best_params_['min_samples_leaf'],
model.best_params_['min_samples_leaf'] + 2],
'min_samples_split': [model.best_params_['min_samples_split'] - 3,
model.best_params_['min_samples_split'],
model.best_params_['min_samples_split'] + 3],
'n_estimators': [model.best_params_['n_estimators'] - 150,
model.best_params_['n_estimators'] - 100,
model.best_params_['n_estimators'],
model.best_params_['n_estimators'] + 100,
model.best_params_['n_estimators'] + 150]
}
clf = RandomForestClassifier()
model = GridSearchCV(estimator = clf, param_grid = grid_search,
cv = 4, verbose= 5, n_jobs = -1)
model.fit(X_Train,Y_Train)
predictionforest = model.best_estimator_.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc4 = accuracy_score(Y_Test,predictionforest)
与随机搜索相比,网格搜索速度较慢,但总体上更有效,因为它可以遍历整个搜索空间。相反,随机搜索可以更快,但可能会错过搜索空间中的一些重要点。
自动超参数调整
使用自动超参数调整时,要使用的模型超参数是使用以下技术确定的:贝叶斯优化、梯度下降和进化算法。
贝叶斯优化
可以使用 Hyperopt 库在 Python 中执行贝叶斯优化。贝叶斯优化使用概率来找到函数的最小值。最终目标是找到一个函数的输入值,它可以为我们提供尽可能低的输出值。
贝叶斯优化已被证明比随机、网格或手动搜索更有效。因此,贝叶斯优化可以在测试阶段提高性能并减少优化时间。
在 Hyperopt 中,可以实现贝叶斯优化,为函数fmin()提供 3 个三个主要参数。
- 目标函数= 定义要最小化的损失函数。
- 域空间= 定义要测试的输入值范围(在贝叶斯优化中,该空间为每个使用的超参数创建概率分布)。
- 优化算法= 定义用于选择在每次新迭代中使用的最佳输入值的搜索算法。
此外,还可以在fmin() 中定义要执行的最大评估次数。
贝叶斯优化可以通过选择输入值并记住过去的结果来减少搜索迭代的次数。通过这种方式,我们可以从一开始就将搜索集中在更接近我们期望输出的值上。
我们现在可以使用fmin()函数运行我们的贝叶斯优化器。一个试验()首先创建的对象,以使可能的可视后来发生了什么事情,而FMIN()函数运行(例如,损失函数是如何变化的,以及如何使用超参数进行更改)。
from hyperopt import hp, fmin, tpe, STATUS_OK, Trials
space = {'criterion': hp.choice('criterion', ['entropy', 'gini']),
'max_depth': hp.quniform('max_depth', 10, 1200, 10),
'max_features': hp.choice('max_features', ['auto', 'sqrt','log2', None]),
'min_samples_leaf': hp.uniform ('min_samples_leaf', 0, 0.5),
'min_samples_split' : hp.uniform ('min_samples_split', 0, 1),
'n_estimators' : hp.choice('n_estimators', [10, 50, 300, 750, 1200])
}
def objective(space):
model = RandomForestClassifier(criterion = space['criterion'],
max_depth = space['max_depth'],
max_features = space['max_features'],
min_samples_leaf = space['min_samples_leaf'],
min_samples_split = space['min_samples_split'],
n_estimators = space['n_estimators'],
)
accuracy = cross_val_score(model, X_Train, Y_Train, cv = 4).mean()
# We aim to maximize accuracy, therefore we return it as a negative value
return {'loss': -accuracy, 'status': STATUS_OK }
trials = Trials()
best = fmin(fn= objective,
space= space,
algo= tpe.suggest,
max_evals = 80,
trials= trials)
best
上面代码运行非常慢,具体结果如下
{'criterion': 1,
'max_depth': 120.0,
'max_features': 2,
'min_samples_leaf': 0.0006380325074247448,
'min_samples_split': 0.06603114636418073,
'n_estimators': 1}
一些参数已经使用索引以数字形式存储在最佳字典中,因此,我们需要先将它们转换回字符串,然后再将它们输入到我们的随机森林中。
crit = {0: 'entropy', 1: 'gini'}
feat = {0: 'auto', 1: 'sqrt', 2: 'log2', 3: None}
est = {0: 10, 1: 50, 2: 300, 3: 750, 4: 1200}
trainedforest = RandomForestClassifier(criterion = crit[best['criterion']],
max_depth = best['max_depth'],
max_features = feat[best['max_features']],
min_samples_leaf = best['min_samples_leaf'],
min_samples_split = best['min_samples_split'],
n_estimators = est[best['n_estimators']]
).fit(X_Train,Y_Train)
predictionforest = trainedforest.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc5 = accuracy_score(Y_Test,predictionforest)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)