人工智能-聚类问题与异常检测——KMeans算法
本节从聚类问题入手,介绍KMeans算法的流程以及异常点检测的拓展,同时提供质心敏感问题的解决思路,从原理到代码实现都讲懂!
本节内容我们将讲述K-Means方法在从聚类问题到异常值检测的应用。分讲范数、布尔数组与索引提取的小连招、以及不可避免的质心敏感问题的解法。
框架和线性回归几乎是一模一样的!也可直接食用。
聚类问题
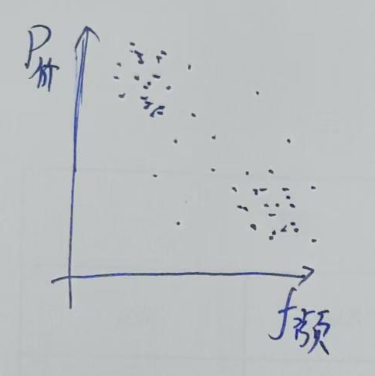
原始数据集的维度不定,可能是一维的密度线、二维的散点面,三维的散点球,几维空间代表这些数据由几个自变量(特征x)生成的。聚类问题就是将相似的数据归为一类,找到最合适的划分标准。
比如你有1000个顾客的购物记录,记录由“购买价格”“购买频次”两个自变量构成,归类问题就是把行为相似的顾客分到同一组。
那么对于购买价格较低,购买频次较高的用户就可以归类「pdd党」;对于购买价格高但频次低的用户可以归类「品质追求党」。
在图上,这个二维数据构成的图就会呈现如下的聚集规律:
K-Means方法
K-means算法是一种常用的聚类分析方法,用于将数据集划分成k个簇(cluster),使得同一簇内的数据点彼此间相似度尽可能高,而不同簇之间的数据点尽可能相异。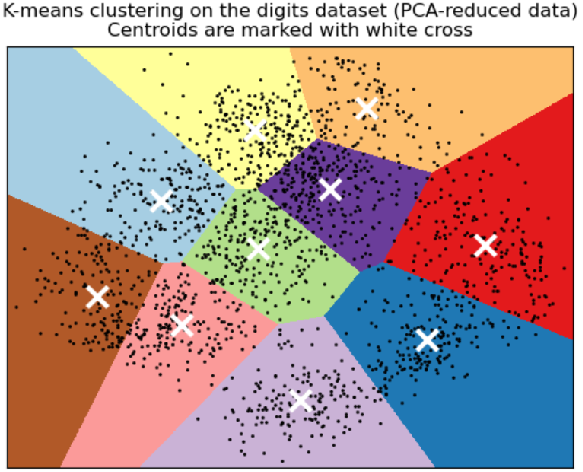
需要将多坨离散的点群分离开,我们如何实现?
首先要确定要分成几类,接着将周围一定范围的点划进这个类中,如果有些界限比较模糊,就需要重新划分,保证清晰。
一般来说,要划定几类是我们要求的(后面优化会提到肘部法和投影法),接下来的问题就是如何衡量“划分标准”:
我们首先先随机生成类对应的簇心,就是类的核心,然后数据点分配给离他最近的簇心,由此每个数据点都会被分配到某个簇内,从而粗略完成分类。
K-means算法的基本流程
-
选择k值:输入需要分成多少类(k类)。
-
初始化质心:随机选择k个数据点作为初始质心(centroid)。质心是每个簇的中心点,代表着簇内所有点的平均位置。
-
分配数据点到最近的质心:对于每一个数据点,计算其与各个质心的距离,然后将该点分配给距离最近的质心所对应的簇。
-
重新计算质心:针对上一步得到的簇,重新计算每个簇的质心。新质心是当前簇中所有点的平均值。
-
重复步骤3和4:重复进行分配数据点和更新质心的过程,直到质心不再发生显著变化或达到预设的最大迭代次数为止。
-
输出结果
异常点
问题来了,假设我们的数据存在一些距离任何簇心都很远的异常点,由上文,异常点肯定会分配到某个簇,因此这个簇的质心在第二次更新的时候就会被“拉”到偏向异常值的位置。
原先本属于这个簇的数据很可能就被划分给别的簇了,误差就很大了。
这怎么办呢,有什么办法可以减少或者消除这些异常值的影响吗?
我们考虑以下这些方法:
Ⅰ舍弃异常值:可以选择距离超过某个阈值的点作为异常值(距离或者百分比)。聚类的时候可以舍弃。
Ⅱ 约束质心移动范围:防止质心被异常值“拉偏”,我们将质心束缚在某个范围内。
如此就可以完成聚类的目的了。
异常值检测
欸,那既然我们能排除异常值,那么判断异常值就是前提条件了,因此KMeans也可以解决异常点检测问题。
梳理思路
整个思路和我们写线性回归是极为类似的:
第一步也是生成数据,线性回归我们的数据是手搓的,这里我们要自行引入异常值,因此也可以手搓。
第二步也是模型初始化——构建KMeans类并传入参数。
第三步是初始化质心——需要初始化质心的位置,并将样本分配到最近的簇中。
第四步也是衡量损失函数——用于衡量误差。
第五步也是优化函数——得到这个误差我们肯定要通过优化参数减小误差,于是需要建立误差和方程参数的关系,通过移动质心的位置使得簇内各点距其质心距离最短。
第六步也是训练模型
第七步是异常提取与绘图
流程图如下:
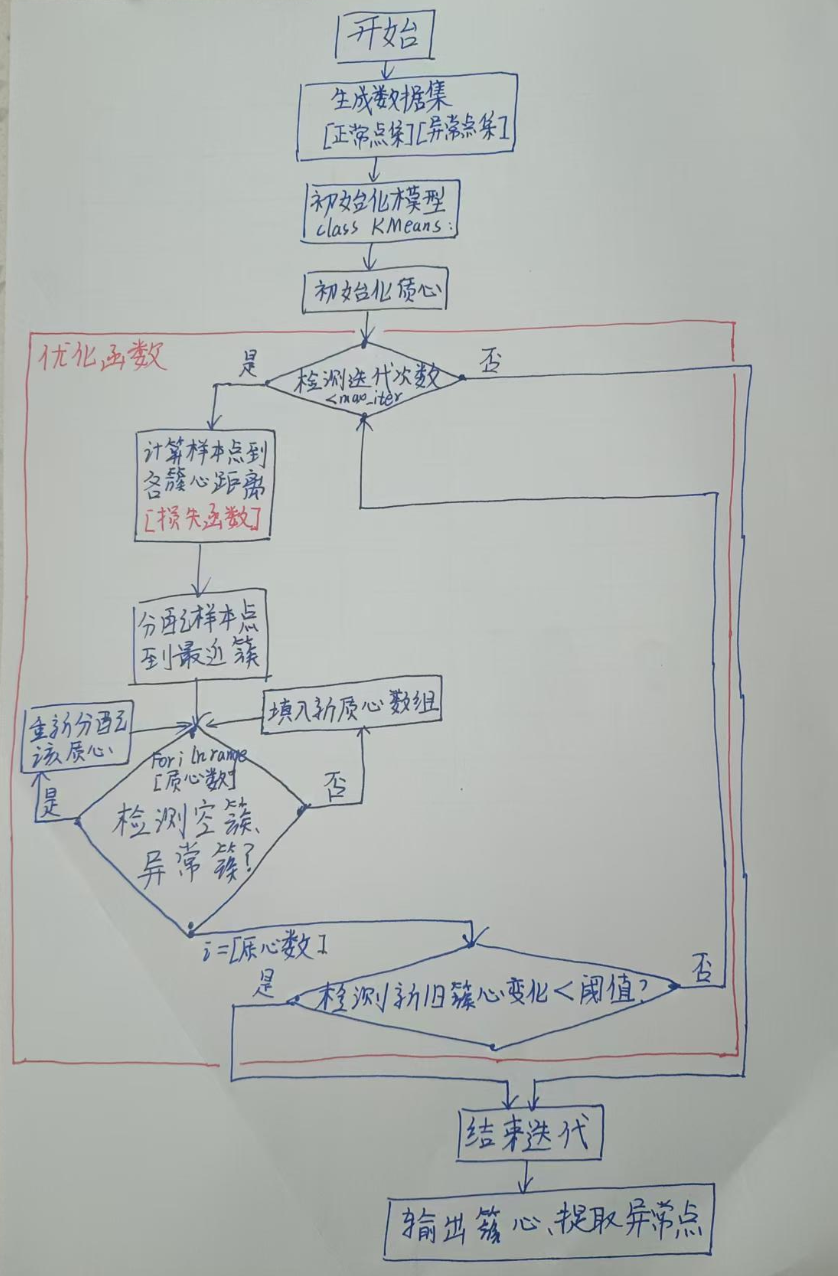
首先手搓数据集,包括正常点集和异常点集。
由于我们的目的是完成聚类,评价的指标关联于 每个正常点离其所属簇心的距离,当这个指标小于某个设定值时就可以判断为优化到可以接受的范围了,另外,如果点分布过散,则有可能始终无法优化到这个设定值,因此需要设定迭代上限值。
那么结束条件就是 ① 误差小于设定值 或 ② 达到迭代上限值
因此在初始化模型(类)的时候,需要设定这两个参数,并初始化聚类模型的相关参数以及训练模型的常用参数。
接着传入数据,完成初始化——随机设定k个质心,代表k个聚类的中心,并计算每个点到各个质心的距离,将每个点分配给 距离自己最近的质心 对应的簇内。
这样随机生成的质心与聚类肯定不是最佳分配方式,因此要设定损失函数,计算这样分配的误差,并设置优化方法,尝试更新质心位置迭代减少误差。
当无论如何更新,新旧质心的变化的幅度都很小的时,意味着已经优化到最佳聚类了,停止迭代。
最后启动模型训练,并使用matplotlib展现聚类图像,有需要我们可以提取异常点。
实现思路:
一、生成数据
我们的目的是生成一组混合散点,包括绝大多数的正常点,可以被聚类为我们设定的k类,以及极少的异常点。
这个操作已经有库帮我们封装好了:
from sklearn.datasets import make_blobs我们使用这个库的make_blobs函数随机生成正常聚类点,需要四个参数——
n_samples:样本数
centers:聚类数
cluster_std:生成样本的标准差(波动性)
random_state:随机种子
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)由于需要随机种子,因此提前生成
np.random.seed(42)
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)接下来生成异常点集,他们不属于任何聚类,因此可以直接用numpy生成。
以防生成点混入正常簇,我们需要加个较大的偏置值,同时为了使得异常点更分散,将随机偏差放大三倍:
X_outliers = np.random.randn(outlier_count, 2) * 3 + np.array([10, 10])
#生成outlier_count个随机点,方差为2,扩大三倍再加上偏置(10,10)最后将正常点集和异常点集叠在一起,合成为输入矩阵X:我们考虑用numpy库的叠加函数vstack(),他可以将两个同形状矩阵合成在一起:
if __name__ == "__main__":
np.random.seed(42)
outlier_count = 6
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(outlier_count, 2) * 3 + np.array([10, 10])
X = np.vstack([X_normal, X_outliers])#vertical stack垂直堆叠合成二、模型初始化
我们定义一个KMeans类方便操作,并定义一个初始化函数(和构造函数类似,创建即调用)
和线性回归类似,需要传入模型训练的参数:
因为要通过质心代表类别,因此需要存储质心的位置——centroieds
因为要给点分配所属类,因此需要给点打上标签——labels
对于聚类模型,特有的参数是:
聚类数:n_clusters
异常点数:outlier_count
核心坐标:centroieds
样本所属类别:labels
加上结束条件 ① 误差小于设定值 或 ② 达到迭代上限值
收敛阈值:tol
迭代次数:max_iter
为了能访问自己的属性,__init__自然带self。
class KMeans:
def __init__(self,n_clusters=3,max_iter=100,tol=10e-4,outlier_count = 7):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.tol = tol # 收敛阈值
self.centroieds = None
self.labels = None三、初始化质心
Ⅰ、初始化质心:
根据K-Means初始化质心的方法:先随机选择k个数据点作为初始质心,将这些质心放进上面定义的self.centroieds中。
要获取k个数据点,就要传入数据矩阵X,因此定义:X的长相可能如下
def fit(self, X):
'''X = np.array([
里面都是特征,二维特征合在一起就是坐标
[1.0, 1.0], # 样本 0
[4.0, 3.0], # 样本 1
[2.0, 8.0] # 样本 2
[4.0, 5.0], # 样本 3
[1.0, 4.0] # 样本 4
])'''接着,有多少个数据点就要多少个可以抽取的质心,大小就是X的行数,我们用.shape属性获取样本大小,其返回值有两个,一个是行数,一个是列数,我们只要第一个作为抽取范围的大小。
def fit(self, X):
n_samples, _ = X.shape #获取样本数接着,随机抽取k个样本点作为质心,chioce()接受三个参数——
n_samples——从0到多少
self.n_clusters——抽取多少个
replace——是否重复抽取
random_idx = np.random.choice(n_samples, self.n_clusters, replace=False)其返回值是一个表示样本下标数组,比如random_idx = [0,3,4]
最后将对应下标的这些样本点当作质心存储在self.centroieds中:
我们将数据集中对应下标的点存进去
self.centroids = X[random_idx]self.centroieds是一个numpy数组,存完可能长这样:
'''self.centroids = np.array([
相当于特征构成的坐标
[1.0, 1.0], 对应idx[0]
[4.0, 5.0], 对应idx[3]
[1.0, 4.0] 对应idx[4]
])'''Ⅱ、将样本分配到最近的簇中
要分配到最近的簇中,自然需要计算其到各质心的距离。
我们先定义后实现,用_calc_distances(X)函数返回所有样本点与所有质心的距离,
接着用labels标记某个样本点对应的最短距离的质心,意味着它属于这个簇:
for _ in range(self.max_iter):#分配样本
distances = self._calc_distances(X) # 计算距离并分配标签
self.labels = np.argmin(distances, axis=1) #分配样本到最近簇这段代码在第五部分还会做详细讲解。 接下来先看一下_calc_distances()是如何计算误差的。
四、损失函数
def _calc_distances(self, X):
TODO:
return distances如何衡量散点与质心的聚集程度呢?
我们考虑使用每个点与其质心距离的平方求和,即簇内平方差和(SSE)
巧的是,numpy库为我们提供了简便方式——范数
范数
n-范数是一种衡量向量/矩阵“大小”或“长度”的数值,因此也就可以作为优化问题中的约束以及误差分析。在此我们用来衡量误差,因此提到范数,你可以理解为“误差”。
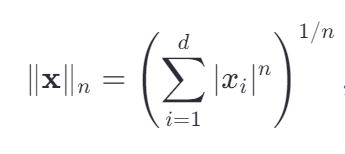
它长这样,不要慌,这是n阶的,我们降到一阶:
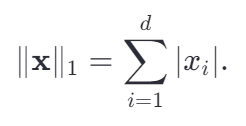
他就是|x1|+|x2|+|x3|+...+|xd|,绝对值之和。俗称曼哈顿范数。
二阶就是我们熟悉的平方差和,也称欧几里得范数。
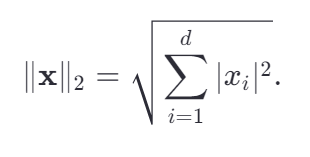
我们在衡量模型的复杂度的时候还会提到,此处仅作了解
使用的时候,调用np.linalg.norm()即可。由于我们是矩阵计算“平方差和”,因此按行按列计算是不一样的,因此我们需要指定范数计算的方向,用axis指定,axis=0是按列,axis=1是按行计算。
np.linalg.norm(对象, 范数计算方向)为了接受这个范数返回的数据,我们先定义一个numpy数组:
distances = np.zeros((X.shape[0], self.n_clusters))
'''创建一个【所有点数量】行,【所有质心数量】列的矩阵,用于存储每个样本到每个簇心的距离'''我们希望当想要知道第n个点属于哪个质心,就从第n行中找距离最小的质心即可。
于是我们定义这个存储矩阵的 每一列 代表 每个点 对于第 i 个质心的距离;因此 每一行 代表 第n个点 对于 每个质心的距离。
这个距离自然就被定义为了误差距离,每次更新我们都能获取一个新的距离,我们期望这个距离越小越好。
接下来就是计算每个点相对于第i个质心的距离,然后遍历【所有质心数量】次,就能填充这个矩阵了。
步骤是:
1.生成容器并初始化:生成误差容器distances,是【所有点数量】行,【所有质心数量】列的矩阵,用于存储每个样本到每个簇心的距离,并用np.zeros初始化矩阵内容为0。
2.两点曼哈顿距离:X - self.centroids[i] 对 X 的每一行减去中心点 centroids[i],得到一个形状为(x,d)的数组,表示每个样本点到中心点的差值。
3.差值的二范数计算:np.linalg.norm(..., axis = 1):对上述差值数组的每一行(即每个样本点)计算 L2-范数。
循环【所有质心数量】,最终结果是一个长度为n的一维数组,表示每个样本点到该中心点的距离。
4.输出distances
'''centroids结构:(坐标x,y)'''
def _calc_distances(self, X):
'''1.生成误差容器distances,是【所有点数量】行,【所有质心数量】列的矩阵,用于存储每个样本到每个簇心的距离'''
distances = np.zeros((X.shape[0], self.n_clusters))#初始化矩阵为0
'''2.循环【质心个数】次填充distances'''
for i in range(self.n_clusters):
'''3.范数计算:调用广播机制,先完成点与点差距计算,再算每个点差的L2范数'''
distances[:, i] = np.linalg.norm(X - self.centroids[i], axis=1)
return distances
'''4.输出:范数返回列矩阵,[:,i]指将这n_clusters个质心对应所有数据的距离,
并在一起,每一列都是所有数据相对于质心i的距离'''
跟着流程图我们过一遍:
首先生成存储误差的容器distances,每一行是点 n 离各个质心的距离;每一列是质心 i 距离各个点的距离;大小是【质心数量】【点数量】。
接着根据输入的矩阵大小,使用广播机制,扩展centroids[i]成为一个和输入矩阵大小一致的矩阵,完成曼哈顿距离计算,输出是每个点与该质心的相对坐标差(Δx,Δy)。
接着,按指定方向计算2-范数,即平方和开根。
最后将这一列输出到distances的第[i]列上即可。
再次强调:distances每一行是点 n 离各个质心的距离;每一列是质心 i 距离各个点的距离,我们想要知道第n个点属于哪个质心,就从第n行中找距离最小的质心即可。
五、优化函数(迭代更新)
得到了数据点距离各个质心位置的矩阵后,我们就可以给数据点分配质心了。
Ⅰ 数据点分配
前文强调过,我们可以通过获取每一行中范数最小的元素,判断这个数据点属于哪个簇。
numpy提供了argmin()函数帮我们查找这些下标:
self.labels = np.argmin(distances, axis=1) #分配样本到最近簇axis=1指明最小值是按行查找的,输出是一个【样本点数】大小的列向量,保存着每个样本点所属的簇标签。
由于我们指定了最大迭代次数,也就是更新质心和距离的次数,因此更新前要套一层遍历:
for _ in range(self.max_iter):
'''调用损失函数获取距离'''
distances = self._calc_distances(X)
'''获取每一个点对应距离最小的质心,分配到这个簇内'''
self.labels = np.argmin(distances, axis=1) 形象理解:假设distances结构如下:
distances = np.array([
[2.0, 5.0, 8.0], # 样本 1 到质心 1、2、3 的距离
[3.0, 6.0, 4.0], # 样本 2 到质心 1、2、3 的距离
[1.0, 7.0, 9.0], # 样本 3 到质心 1、2、3 的距离
[4.0, 2.0, 6.0], # 样本 4 到质心 1、2、3 的距离
[5.0, 3.0, 1.0] # 样本 5 到质心 1、2、3 的距离
])每个样本点距离最近质心的索引很明显应该是0,0,0,1,2
那么argmin()就会返回数组中最小值的索引构成的数组:
self.labels = np.array([0, 0, 0, 1, 2])分配完数据点,就该实现质心更新了。
Ⅱ 更新质心位置
刚刚我们完成了第一次分配,由于质心是随机生成的,误差(范数)很大,绝非最优值,因此就需要优化函数通过更新质心位置,将部分误分的数据点修改到正确的簇内,从而减少簇内数据点与簇心的距离,从而减少误差(范数)。
和更新距离矩阵类似,我们也要先定义一个数组,准备存储更新后质心的位置,大小自然是【质心数量】个。
new_centroids = np.zeros_like(self.centroids)
'''新建和质心大小相同数组,存储更新后的质心位置'''由于更新逻辑是 该簇内所有数据点的平均值作为新的质心,因此要先得到属于该簇的这些数据点,然后计算均值,得到新质心。同时只要循环【质心个数】次,就能完成每个质心的更新了。
那么如何从数据点集X中获取属于这个簇的数据点呢?
布尔数组与索引提取
我们考虑用索引。
self.labels = np.array([0, 0, 0, 1, 2])这是前一轮分配的结果,那么我们要获取簇[0]的所属数据点,考虑用:
(self.labels == i)
这句话的意思是,依次判断这个数组每个元素是否等于i,输出布尔数组。
比如我们查找簇[0]对应的元素,它就会返回[1,1,1,0,0],即前三个元素是属于簇[0]的!
而布尔数组可以用来从数组中提取满足条件的元素或行,自动从X矩阵中提取索引为1的数据:
复用一下这个X。
X = np.array([
[2.0, 5.0, 8.0], # 样本 1 到质心 1、2、3 的距离
[3.0, 6.0, 4.0], # 样本 2 到质心 1、2、3 的距离
[1.0, 7.0, 9.0], # 样本 3 到质心 1、2、3 的距离
[4.0, 2.0, 6.0], # 样本 4 到质心 1、2、3 的距离
[5.0, 3.0, 1.0] # 样本 5 到质心 1、2、3 的距离
])
self.labels = np.array([0, 0, 0, 1, 2])cluster_samples = X[self.labels == 0]
print(cluster_samples)那么就会返回X数据点集的前三个元素:
[[2.0, 5.0, 8.0],
[3.0, 6.0, 4.0],
[1.0, 7.0, 9.0]]总结:
- 匹配:同时巧妙运用(labels == i)可以获取匹配 i 的数组下标
- 提取:也就是说,我们可以通过X[1,1,1,0,0]这种方式提取对应下标的元素
对应代码:cluster_samples是第 i 个质心拥有的数据点的坐标的numpy数组。
cluster_samples = X[self.labels == i]要重复【质心个数】轮,则要套一层for:
for i in range(self.n_clusters):
cluster_samples = X[self.labels == i]获取属于这个簇的数据点后就要计算平均值作为新的质心了,在更新之前,我们还需要判断这个簇是否有元素,如果没有元素就要重新生成一个新的质心:
为什么要这么做呢?
当簇为空,则唯一的可能就是最近的数据点都被其他质心抢走了,意味着这个点偏离了正常点集,很可能就是异常点了!!!
簇非空:就可以执行计算平均值作为新的质心了,对当前簇cluster_samples的所有数据点沿列计算平均值,即分别安装坐标x,坐标y计算平均坐标(,
)作为该簇的新簇心。
if cluster_samples.size > 0:
new_centroids[i] = cluster_samples.mean(axis=0)簇为空:则重新生成质心位置:从X中随机选择一个点作为新质心。
else:
new_centroids[i] = X[np.random.choice(n_samples)]遍历n轮后,new_centroids被新的质心填充。
最后验证是否满足结束条件——当无论如何更新,新旧质心的变化的幅度都很小的时,意味着已经优化到最佳聚类了。
我们依然使用二范数衡量误差:
if np.linalg.norm(new_centroids - self.centroids) < self.tol:即新旧质心误差小于规定阈值。
如果满足则退出这个函数,否则将新质心集赋给self.centroids,实现迭代更新。
if np.linalg.norm(new_centroids - self.centroids) < self.tol:
'''当新质心与原质心的误差小于阈值时,则结束迭代'''
break
'''否则更新质心列表'''
self.centroids = new_centroids完整代码:
# 2. 迭代优化
for _ in range(self.max_iter):#分配样本
distances = self._calc_distances(X) # 计算距离并分配标签
self.labels = np.argmin(distances, axis=1) #分配样本到最近簇
'''distances是一个samples行n_clusters列的矩阵,
每一列保存着所有数据相对于某个簇心的距离,
每一行则保存有每个数据点相对于各个簇心的距离,
axis指定为1是为了选择distances矩阵中每一行中距离最短的簇心 作为标签贴给该数据'''
# 3. 更新质心
#复制一份质心副本
new_centroids = np.zeros_like(self.centroids)#新建和质心大小相同数组,存储更新后的质心位置
for i in range(self.n_clusters):#遍历每个簇,检查是否存在异常簇
cluster_samples = X[self.labels == i]
if cluster_samples.size > 0:
new_centroids[i] = cluster_samples.mean(axis=0)
else:
new_centroids[i] = X[np.random.choice(n_samples)]
#通过二范数判断收敛距离
if np.linalg.norm(new_centroids - self.centroids) < self.tol:
break
self.centroids = new_centroids六、训练模型与异常点提取
以上,我们完成了从数据生成、模型初始化、初始化质心、误差测量以及更新质心的实现,接下来创建KMeans实例,训练模型:
'''创建KMeans对象并调用训练函数fit()'''
kmeans = KMeans(n_clusters=5)
kmeans.fit(X)接着,提取异常点:
阈值设定为:【各点到其所属质心距离的平均距离+2*距离的标准差】
'''判断并提取异常点,依据是【各点到其所属质心距离的平均距离+2*距离的标准差】'''
distances = np.min(kmeans._calc_distances(X), axis=1)#返回每个数据点到所属簇的距离
threshold = np.mean(distances) + 2 * np.std(distances)#计算阈值当某点距离大于阈值时则判定为异常点,我们使用 np.where(条件) 函数,
Ⅰ 条件就是【距离大于阈值】,返回一个布尔数组,表示哪些样本点的距离大于给定的阈值。
Ⅱ where()函数返回一个元组,包含满足条件的索引。
Ⅲ 最后提取这个元组的第0个元素,即包含异常点下标的numpy数组。
outliers = np.where(distances > threshold)where输入为多维数组则有其他的提取方式,我们只处理一维的,不多赘述
有点抽象不是吗,我们一步步调试:
设输入的distances如下
distances = np.array([1, 2, 3.5, 4, 5])
threshold = 3
print(distances > threshold)
'''[False False True True True]'''
indices = np.where(distances > threshold)
print(indices)
'''(array([2, 3, 4]),)'''
outliers = np.where(distances > threshold)[0]
print(outliers)
'''[2, 3, 4]'''
'''
disrances>threshold返回一个布尔数组,
where将布尔数组转化为一个元组,元组中包含满足条件的索引,
[0]返回第一个元素,就是满足条件的下标数组
'''七、绘图
我们不涉及matplotlib的讲解,直接给出代码放在最后。
质心敏感问题
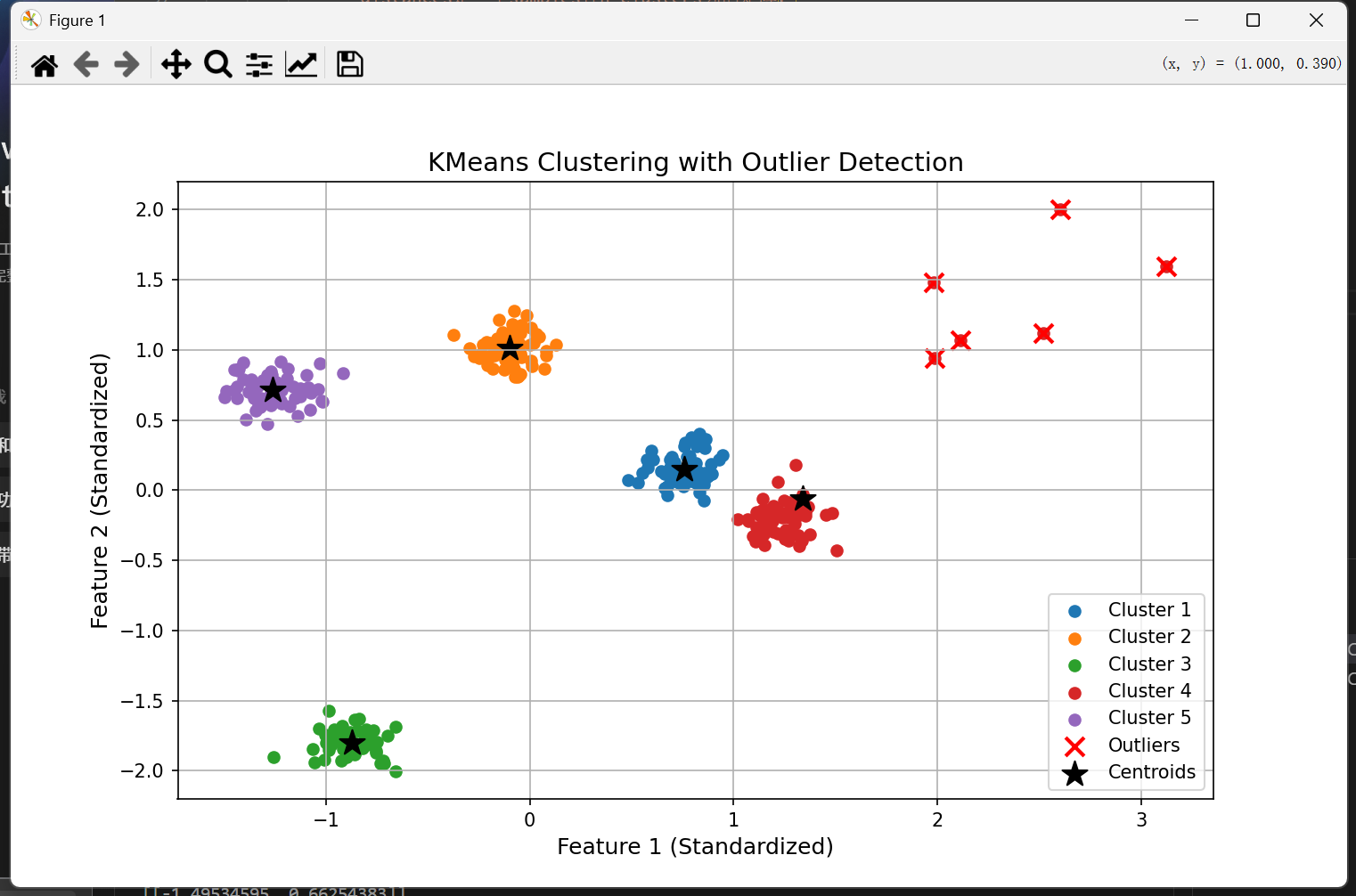
如果我们将异常点个数生成更多一些,就有概率出现如下图像:
簇数设为5,异常点设为6,阈值设为5
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(6, 2) * 3 + np.array([10, 10])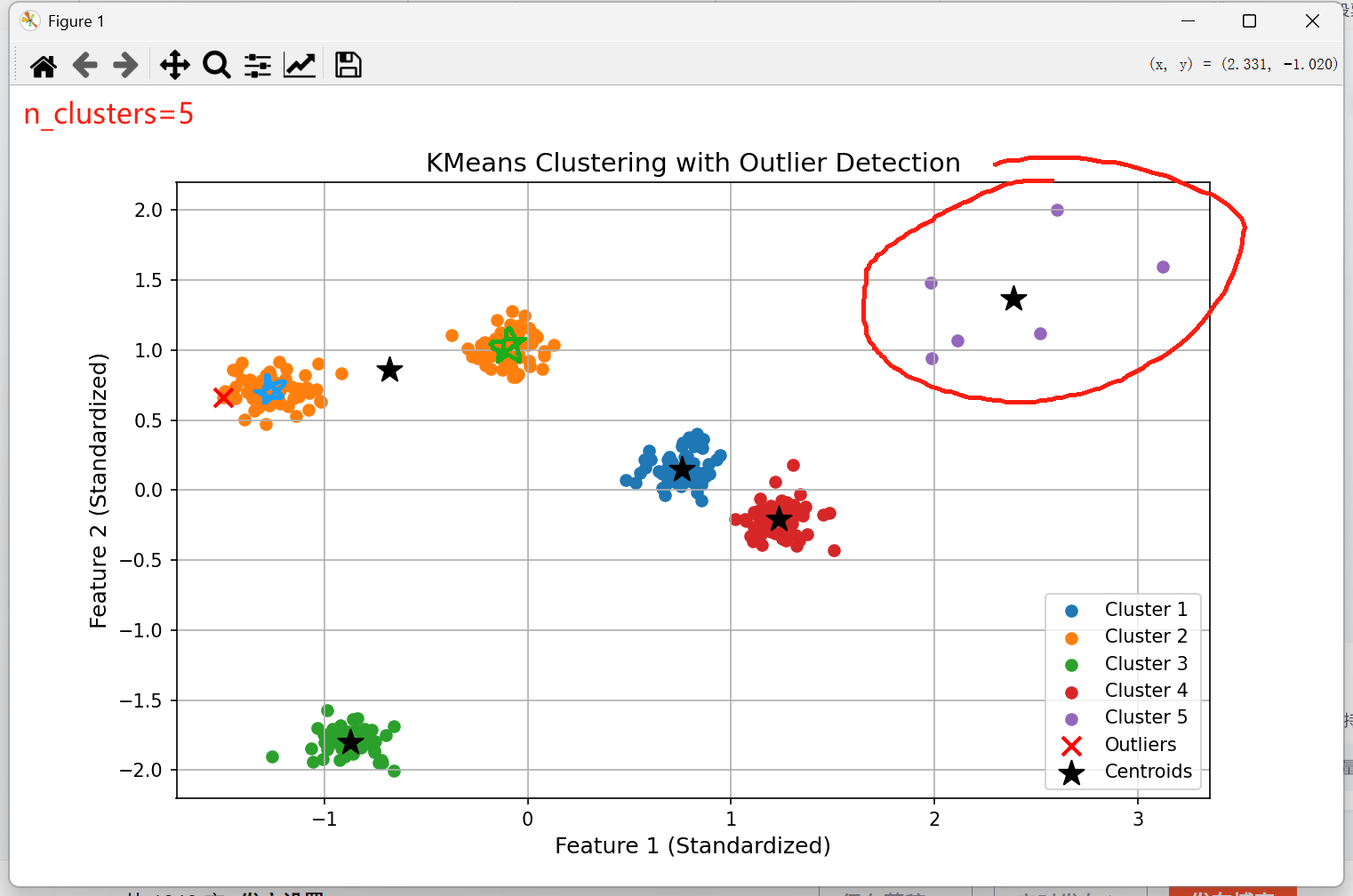
这是为什么呢?
由于我们K个质心是随机选取样本点得到的,因此有一定概率会生成在异常点上。由于我们分配样本是基于最近的质心的距离,这个任何正常点离这个簇心都很远,只有离这个“异常簇”最近的几个异常点会被分进这个簇中,从而导致有的类无法被聚集,而异常点反而变成了正常点。
(应该在蓝星和绿星的位置生成质心)
为了解决这个问题,我们引入了阈值,只有聚集大于一定数量的簇才能被认定为簇,这样即便随机生成在异常点上也会在下一轮重新生成。
这个阈值我们设为 threshold>outliers ,因为此时哪怕生成在异常点,这个簇最大只有outliers个,小于threshold,无法被认定为正常簇,从而在下一轮被重新生成!
修改如下几处:
Ⅰ 将质心更新逻辑改为当簇中元素小于异常点数的时候则要求重新生成,cluster_samples是数组,因此计算簇的元素个数使用len()函数:
if len(cluster_samples) > self.outlier_count:
#判断簇中样本数量是否大于5,因为小于五个可能是异常簇
new_centroids[i] = cluster_samples.mean(axis=0)
else:
#如果簇小于异常点数则重新分配核心
new_centroids[i] = X[np.random.choice(n_samples)]Ⅱ 由于函数内部使用了outlier_count异常点个数,因此在初始化函数处添加这个属性,并在参数列表补充默认值:
def __init__(self,n_clusters=3,max_iter=100,tol=10e-4,outlier_count = 0):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.tol = tol # 收敛阈值
self.centroieds = None
self.labels = None
self.outlier_count = outlier_countⅢ 创建KMeans实例时也要将这个参数传入:
kmeans = KMeans(n_clusters=5,outlier_count=outlier_count)Ⅳ 在生成异常数据的时候,单独定义outlier_count变量,并传入X_outliers异常点列表:
if __name__ == "__main__":
np.random.seed(42)
outlier_count = 6
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(outlier_count, 2) * 3 + np.array([10, 10])
X = np.vstack([X_normal, X_outliers])#vertical stack垂直堆叠合成我们修改后一切恢复正常:
这个版本的代码也放在最后。
当然,在实际使用的时候我们显然是不确定异常点的数量的,因此这个阈值设为多少合适还需要测试。
那么,有没有什么科学的方法呢?
目前常用的是KMeans++、密度规则、多次随机取最好几种方式,我们在下一节补充节做出简要介绍,不作实现要求。
调试说明
你可以先划到最下面cv最后的代码,调整#==============Main=================下面的输入参数观察是否也会出现质心敏感问题。
if __name__ == "__main__":
np.random.seed(42)
outlier_count = 6
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(outlier_count, 2) * 3 + np.array([10, 10])
X = np.vstack([X_normal, X_outliers])#vertical stack垂直堆叠合成接着cv倒数第二段代码,保持输入参数不变,看看是否也会呈现质心敏感问题解决后的图例。
同时你可以修改阈值,观察异常点的提取效果
阈值设定为:【各点到其所属质心距离的平均距离+2*距离的标准差】
'''判断并提取异常点,依据是【各点到其所属质心距离的平均距离+2*距离的标准差】'''
distances = np.min(kmeans._calc_distances(X), axis=1)#返回每个数据点到所属簇的距离
threshold = np.mean(distances) + 2 * np.std(distances)#计算阈值代码集
质心敏感问题解决后完整代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
'''2.模型初始化'''
class KMeans:
def __init__(self,n_clusters=3,max_iter=100,tol=10e-4,outlier_count = 7):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.tol = tol # 收敛阈值
self.centroieds = None
self.labels = None
self.outlier_count = outlier_count
'''3.初始化质心'''
def fit(self, X):
'''X = np.array([
里面都是特征,二维特征合在一起就是坐标
[1.0, 2.0], # 样本 1
[4.0, 5.0], # 样本 2
[7.0, 8.0] # 样本 3
])'''
n_samples, n_features = X.shape #获取样本数和特征数[3,2]
# 1. 随机初始化质心(numpy实现)
random_idx = np.random.choice(n_samples, self.n_clusters, replace=False)
#从0-samples-1选出n_cluster个不重复的随机数
#返回numpy数组
self.centroids = X[random_idx] # 提取初始质心
'''self.centroids = np.array([
相当于特征构成的坐标
[1.0, 2.0],
])'''
#也是numpy数组
'''4.优化函数'''
for _ in range(self.max_iter):#分配样本
distances = self._calc_distances(X) # 计算距离并分配标签
self.labels = np.argmin(distances, axis=1) #分配样本到最近的簇
#复制一份质心副本
new_centroids = np.zeros_like(self.centroids)#新建和质心大小相同数组,存储更新后的质心位置
for i in range(self.n_clusters):#遍历每个簇,检查是否存在异常簇
cluster_samples = X[self.labels == i]
if len(cluster_samples) > self.outlier_count: #判断簇中样本数量是否大于5,因为小于五个可能是异常簇
new_centroids[i] = cluster_samples.mean(axis=0)
else:
#如果簇小于5则重新分配核心
new_centroids[i] = X[np.random.choice(n_samples)]
#通过二范数判断收敛距离
if np.linalg.norm(new_centroids - self.centroids) < self.tol:
break
self.centroids = new_centroids
'''5.损失函数'''
def _calc_distances(self, X):
distances = np.zeros((X.shape[0], self.n_clusters))
for i in range(self.n_clusters):
distances[:, i] = np.linalg.norm(X - self.centroids[i], axis=1)
return distances #distances 是一个二维数组,形状为 (n_samples, self.n_clusters)
# ====================== Main ======================
'''1.数据生成'''
if __name__ == "__main__":
np.random.seed(42)
outlier_count = 6
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(outlier_count, 2) * 3 + np.array([10, 10])
X = np.vstack([X_normal, X_outliers])#vertical stack垂直堆叠合成
# 2. 标准化
X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
'''6.训练模型与异常点提取'''
# 3. Train KMeans model
kmeans = KMeans(n_clusters=5,outlier_count=outlier_count)
kmeans.fit(X)
# 4. Detect outliers (points > mean + 2*std deviation)
distances = np.min(kmeans._calc_distances(X), axis=1)#返回每个数据点到所属簇的距离
threshold = np.mean(distances) + 2 * np.std(distances)#计算阈值
outliers = np.where(distances > threshold)[0]#返回所有异常点的索引:where返回索引,disrances>threshold返回一个布尔数组,[0]表示返回布尔数组中为True的元素的索引
'''7.可视化'''
# 5. Visualize results
plt.figure(figsize=(10, 6))
# Plot normal points (colored by cluster)
for i in range(kmeans.n_clusters):
cluster_points = X[kmeans.labels == i]
plt.scatter(cluster_points[:, 0], cluster_points[:, 1], label=f'Cluster {i + 1}')
# Plot outliers
plt.scatter(X[outliers, 0], X[outliers, 1],
c='red', marker='x', s=100, linewidths=2, label='Outliers')
# Plot centroids
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1],
c='black', marker='*', s=200, label='Centroids')
plt.title("KMeans Clustering with Outlier Detection", fontsize=14)
plt.xlabel("Feature 1 (Standardized)", fontsize=12)
plt.ylabel("Feature 2 (Standardized)", fontsize=12)
plt.legend()
plt.grid(True)
plt.show()
# Print results
print("===== Results =====")
print(f"Centroid coordinates:\n{kmeans.centroids}")
print(f"Outlier indices: {outliers}")
print(f"Outlier coordinates:\n{X[outliers]}")未修正质心敏感问题前完整代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
class KMeans:
def __init__(self, n_clusters=3, max_iter=300, tol=1e-4):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.tol = tol
self.centroids = None
self.labels = None
def fit(self, X):
n_samples, n_features = X.shape
# Initialize centroids randomly
random_idx = np.random.choice(n_samples, self.n_clusters, replace=False)
self.centroids = X[random_idx]
for _ in range(self.max_iter):
# Calculate distances and assign labels
distances = self._calc_distances(X)
self.labels = np.argmin(distances, axis=1)
# Update centroids
new_centroids = np.zeros_like(self.centroids)
for i in range(self.n_clusters):
cluster_samples = X[self.labels == i]
if cluster_samples.size > 0:
new_centroids[i] = cluster_samples.mean(axis=0)
else:
# Handle empty cluster
new_centroids[i] = X[np.random.choice(n_samples)]
# Check convergence
if np.linalg.norm(new_centroids - self.centroids) < self.tol:
break
self.centroids = new_centroids
def _calc_distances(self, X):
"""Calculate Euclidean distances to all centroids"""
distances = np.zeros((X.shape[0], self.n_clusters))
for i in range(self.n_clusters):
distances[:, i] = np.linalg.norm(X - self.centroids[i], axis=1)
return distances
# ====================== Main ======================
if __name__ == "__main__":
# 1. Generate sample data (3 clusters + 5 outliers)
np.random.seed(42)
X_normal, _ = make_blobs(n_samples=300, centers=5, cluster_std=0.6, random_state=42)
X_outliers = np.random.randn(5, 2) * 3 + np.array([10, 10])
X = np.vstack([X_normal, X_outliers])
# 2. Standardize data
X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# 3. Train KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# 4. Detect outliers (points > mean + 2*std deviation)
distances = np.min(kmeans._calc_distances(X), axis=1)
threshold = np.mean(distances) + 2 * np.std(distances)
outliers = np.where(distances > threshold)[0]
# 5. Visualize results
plt.figure(figsize=(10, 6))
# Plot normal points (colored by cluster)
for i in range(kmeans.n_clusters):
cluster_points = X[kmeans.labels == i]
plt.scatter(cluster_points[:, 0], cluster_points[:, 1], label=f'Cluster {i + 1}')
# Plot outliers
plt.scatter(X[outliers, 0], X[outliers, 1],
c='red', marker='x', s=100, linewidths=2, label='Outliers')
# Plot centroids
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1],
c='black', marker='*', s=200, label='Centroids')
plt.title("KMeans Clustering with Outlier Detection", fontsize=14)
plt.xlabel("Feature 1 (Standardized)", fontsize=12)
plt.ylabel("Feature 2 (Standardized)", fontsize=12)
plt.legend()
plt.grid(True)
plt.show()
# Print results
print("===== Results =====")
print(f"Centroid coordinates:\n{kmeans.centroids}")
print(f"Outlier indices: {outliers}")
print(f"Outlier coordinates:\n{X[outliers]}")
小结:
Ⅰ 聚类问题是什么
Ⅱ KMeans方法的流程和原理
Ⅲ 异常点导致质心偏移如何解决
Ⅳ 范数的两个作用,p-范数是什么
Ⅴ 布尔数组与索引提取的实现
Ⅵ 质心敏感问题的初步解决
写在后面:
很开心你能耐着性子读到这里,很荣幸能将我的三脚猫知识分享给大家。
星马也是小白,因此更懂小白的心思,大佬认为一眼明白的代码和思路可能在我们眼中就是鸿沟。这篇文章也还有很多不足之处,或是纰漏,希望你发现了及时在评论区提醒我呀~
(人工智能学院就是每周四五天满课的啦,因此更新基本随缘~)
别丢收藏夹吃灰啦好嘛~
星马是刚入门的大菜比,有错望指正,有项目可以带带我。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)