在笔记本电脑上,实现本地知识库和大模型检索增强生成(RAG)
现在,我们可以引入,管理本地知识库,并和Ollama结合起来,实现的智能问答。AnythingLLM是采用MIT许可证的开源框架,支持快速在本地部署基于检索增强生成(RAG)的大模型应用。在不调用外部接口、不发送本地数据的情况下,确保用户数据的安全。最近 AnythingLLM推出了桌面应用,可以在自己的笔记本电脑上下载使用,目前支持的操作系统包括MacOS,Windows和Linux。下载地址:
现在,我们可以引入AnythingLLM,管理本地知识库,并和Ollama结合起来,实现大模型+知识库+RAG的智能问答。
1. 下载AnythingLLM
AnythingLLM是采用MIT许可证的开源框架,支持快速在本地部署基于检索增强生成(RAG)的大模型应用。
在不调用外部接口、不发送本地数据的情况下,确保用户数据的安全。
最近 AnythingLLM推出了桌面应用,可以在自己的笔记本电脑上下载使用,目前支持的操作系统包括MacOS,Windows和Linux。
下载地址:https://useanything.com/download
以MacOS为例,下载AnythingLLM桌面版dmg文件,双击即可安装。初次启动需要5-15秒进行初始化操作。在使用过程中,所有上传的文档、向量和数据库都保存在以下文件夹可供查看。
存储路径:~/Library/Application Support/anythingllm-desktop
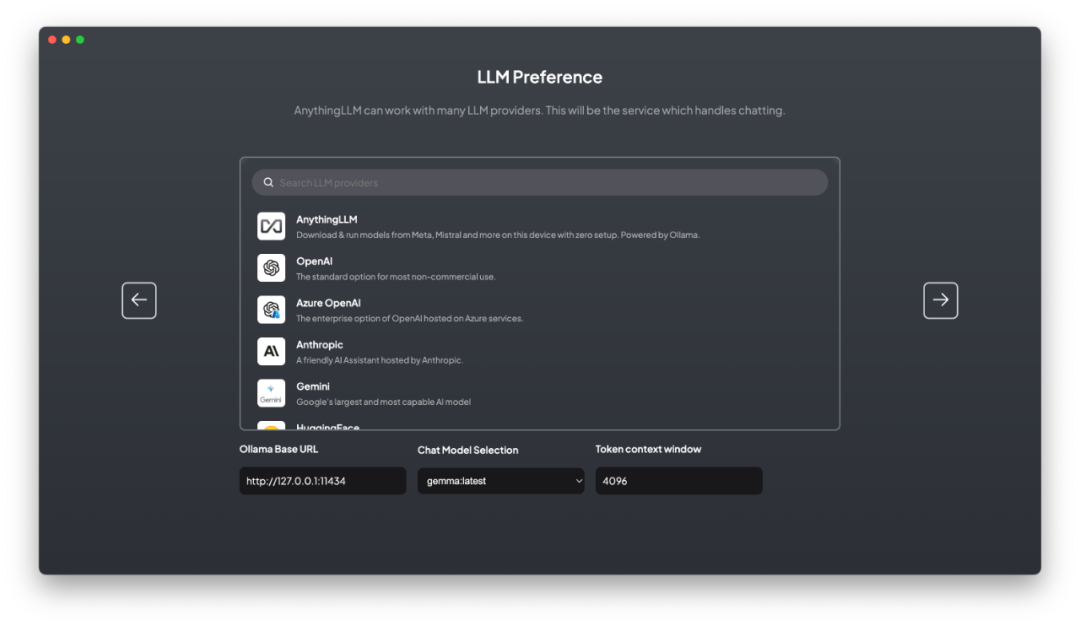
2. 选择大模型
AnythingLLM默认通过Ollama来使用LLama2 7B,Mistral 7B,Gemma 2B等模型,也可以调用OpenAI、Gemini、Mistral等大模型的API服务。
此前,我已经安装了Ollama,那么只要选择Ollama,输入调用的API接口URL,再选择此前已经下载的Gemma模型即可。
3. 选择嵌入模型
AnythingLLM内置了一个嵌入模型 all-Mini-L6-v2,无需任何配置。该模型也可以在HuggingFace下载。同时,系统也支持OpenAI、LocalAi、Ollama提供的嵌入模型。
比如,Ollama上可供下载运行的嵌入模型有nomic-embed-text,据称性能超过OpenAI的text-embedding-ada-002和text-embedding-3-small。
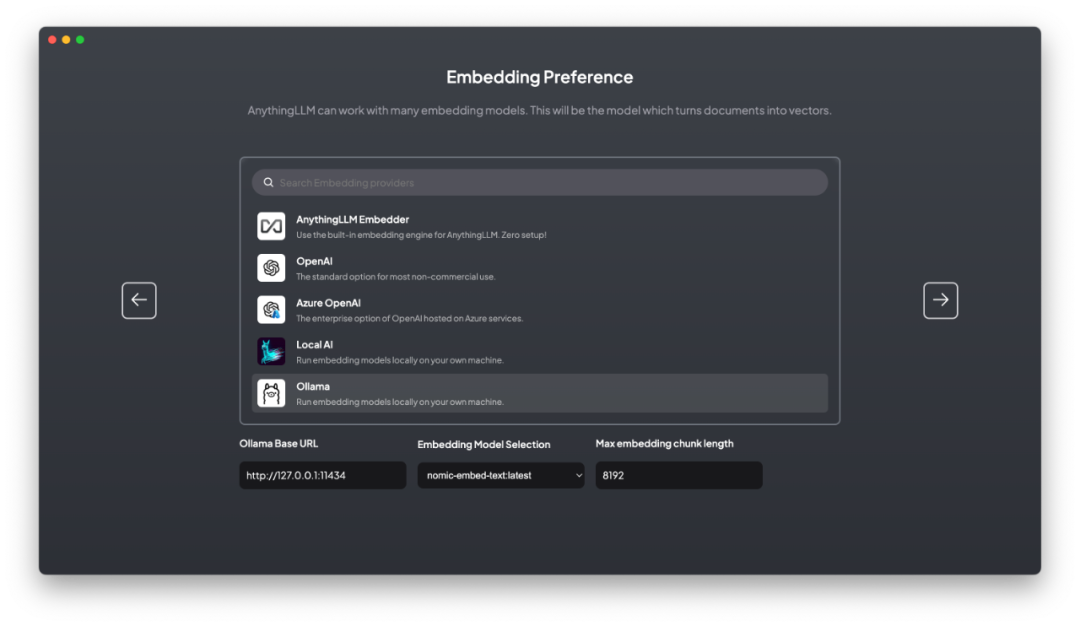
既然已经装了Ollama,那么我就直接选用nomic-embed-text。
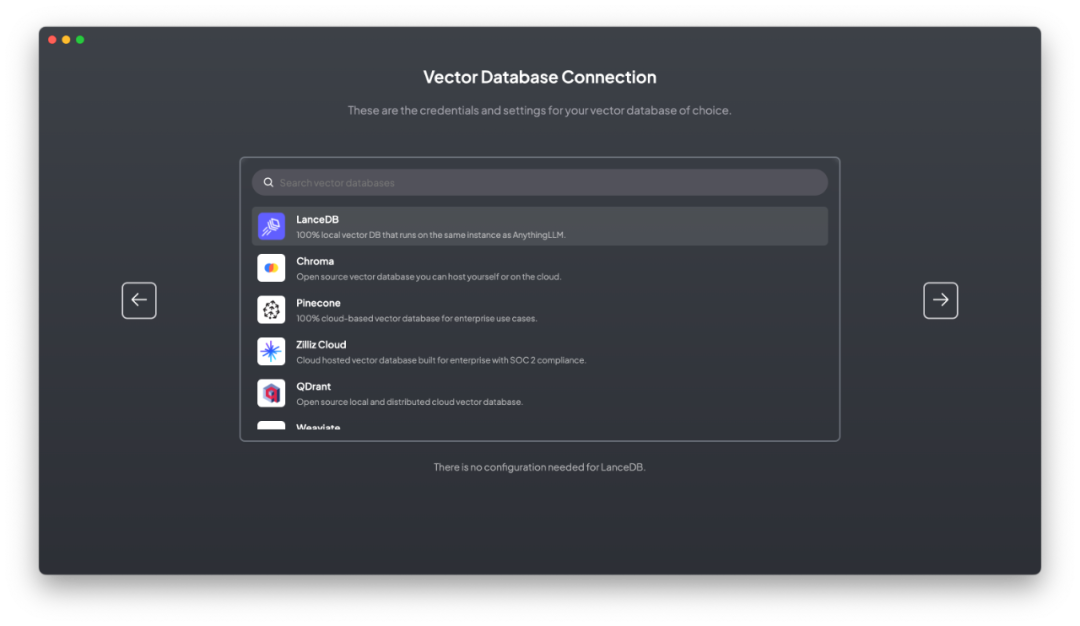
4. 选择向量数据库
AnythingLLM默认使用内置的向量数据库LanceDB。这是一款无服务器向量数据库,可嵌入到应用程序中,支持向量搜索、全文搜索和SQL。我们也可以选用Chroma、Milvus、Pinecone等向量数据库。
5. 知识库管理
AnythingLLM可以支持PDF,TXT,DOCX等文档,可以提取文档中的文本信息,经过嵌入模型(Embedding Models),保存在向量数据库中,并通过一个简单的UI界面管理这些文档。
为管理这些文档,AnythingLLM引入**工作区(workspace)**的概念,作为文档的容器,可以在一个工作区内共享文档,但是工作区之间隔离。
这里,我创建一个工作区,名称“David”。
AnythingLLM既可以上传文档,也可以抓取网页信息。我之前写了关于AI新范式的三篇文章,于是上传了Word版文件,系统抓取数据后,统一保存到向量数据库中。
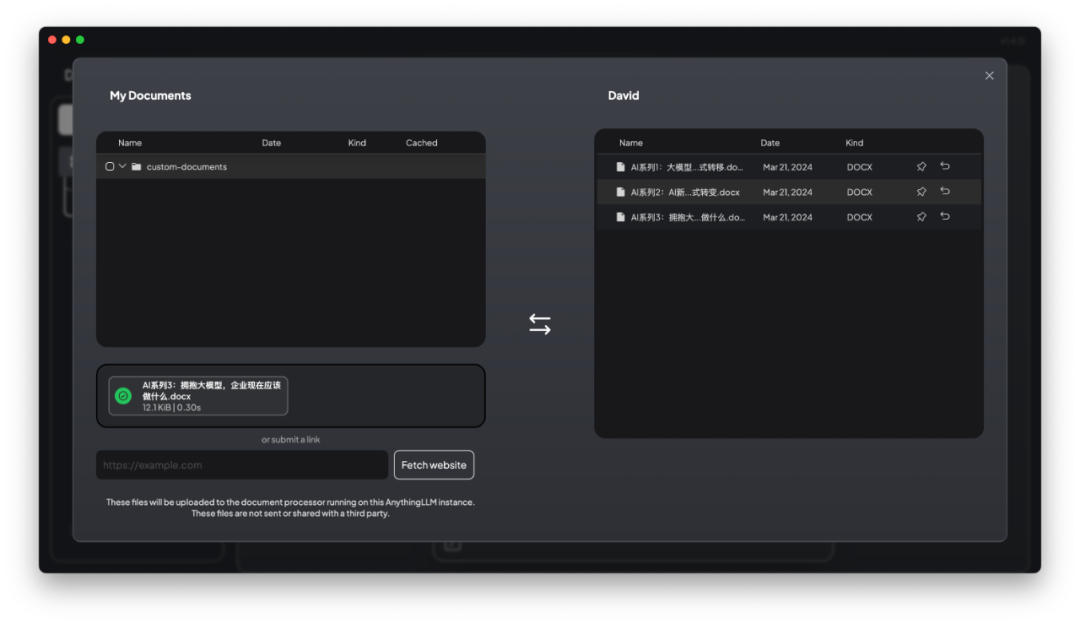
6. RAG智能问答
构建了知识库之后,我给大模型发送了这个问题:“AI将给数字化带来哪些模式转变”。大模型给出了回答,并引用了我之前上传的3份文档。
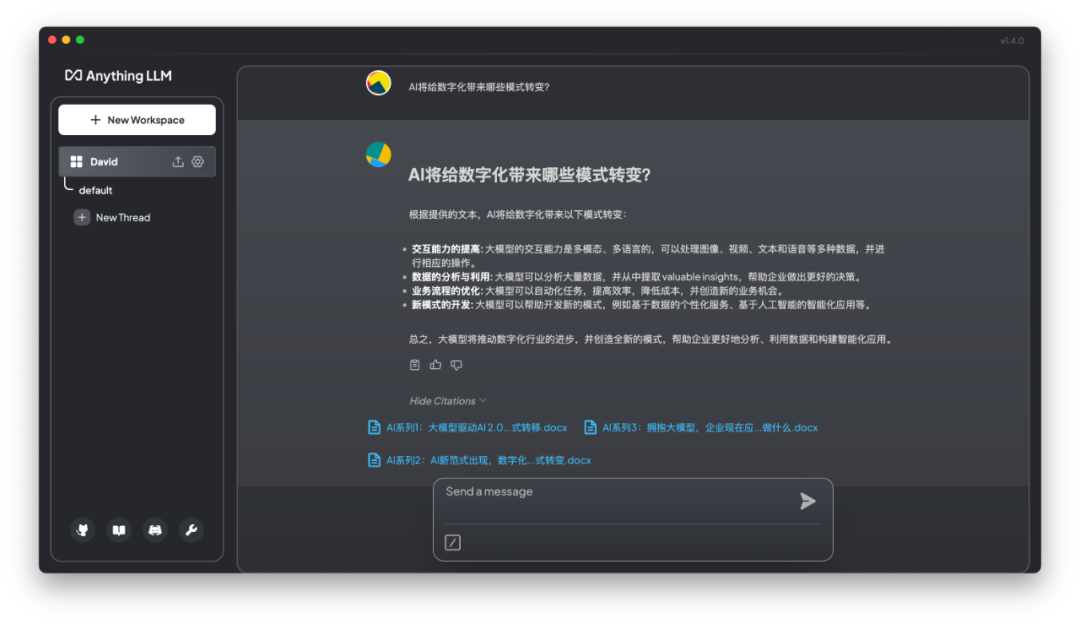
不过,相比我文档中的原文,大模型给出的回答还不够准确。未来,这套系统还可在文本召回和重排等方面,进一步调优和完善。
7. 定制UI界面
值得称许的是,AnythingLLM默认提供了一些界面定制的选项,包括:改用自己的品牌Logo,初次创建工作区的欢迎语。
8. 定制开发 - 技术栈
如果要做更多的个性化定制,就需要自己修改源码了。
同类开源项目大多基于Python语言开发。AnythingLLM采用了Javascript,前端用React,后端用Node,对于全栈工程师非常友好。
-
前端:React和ViteJS,实现创建和管理大模型用到的知识库
-
后端:Node.js Express框架,实现向量数据库的管理和所有与大模型的交互
-
采集器:Node.js Express框架,实现对文档的处理解析
9. 部署方式
AnythingLLM本身对系统硬件资源要求不高(最低要求:2G内存,2核CPU),支持通过Docker进行本地化部署。
export STORAGE_LOCATION=$HOME/anythingllm && \``mkdir -p $STORAGE_LOCATION && \``touch "$STORAGE_LOCATION/.env" && \``docker run -d -p 3001:3001 \``--cap-add SYS_ADMIN \``-v ${STORAGE_LOCATION}:/app/server/storage \``-v ${STORAGE_LOCATION}/.env:/app/server/.env \``-e STORAGE_DIR="/app/server/storage" \``mintplexlabs/anythingllm:master
如果在企业内部使用,可以部署在企业的私有云上,也支持物理服务器(bare metal)部署。
10. 多用户模式
这一点对于企业级应用特别关键,AnythingLLM支持多用户模式,3种角色的权限管理。
系统会默认创建一个管理员(Admin)账号,拥有全部的管理权限。
第二种角色是Manager账号,可管理所有工作区和文档,但是不能管理大模型、嵌入模型和向量数据库。
普通用户账号,则只能基于已授权的工作区与大模型对话,不能对工作区和系统配置做任何更改。

那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!
💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)
👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)
👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!
👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)
👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 16
16 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)