「源力觉醒 创作者计划」_国产大模型巅峰对决:文心4.5 vs Qwen2.5,谁才是你的菜?
在人工智能领域,文心4.5和Qwen2.5是当前国产大模型的代表。本文通过四个回合对这两款大模型进行详细对比:效率对决,看谁更快速且节能;核心能力比拼,谁在语言理解和逻辑推理上更出色;知识储备对比,谁能胜任广泛的领域知识;以及专业能力,谁在特定领域更具优势。通过这一系列对决,帮助你根据实际需求做出选择。让我们揭开这场国产大模型的巅峰对决,选择最适合你的那一款
文章目录
如今的AI圈,“神仙打架”早已从新闻变成常态。趁着文心4.5开源的这波热度,我们邀请两位国产重量级选手同台竞技——来自百度的ERNIE-4.5-VL-28B-A3B(下文简称“文心4.5”)与来自阿里通义千问的Qwen2.5-VL-32B-Instruct(下文简称“Qwen2.5”)。不玩虚的,直接上实测数据,从效率、能力到场景适配,全方位拆解谁更技高一筹。准备好瓜子板凳,这场对决值得细品!

【裁判声明:非专业但真诚,数据全透明!】
在正式开测前,先交代清楚评测的“家底”:
- 评测平台:基于PP飞桨(PaddlePaddle)模型体验场的“对比模式”,确保两款模型面对完全相同的问题,消除“考题差异”干扰。
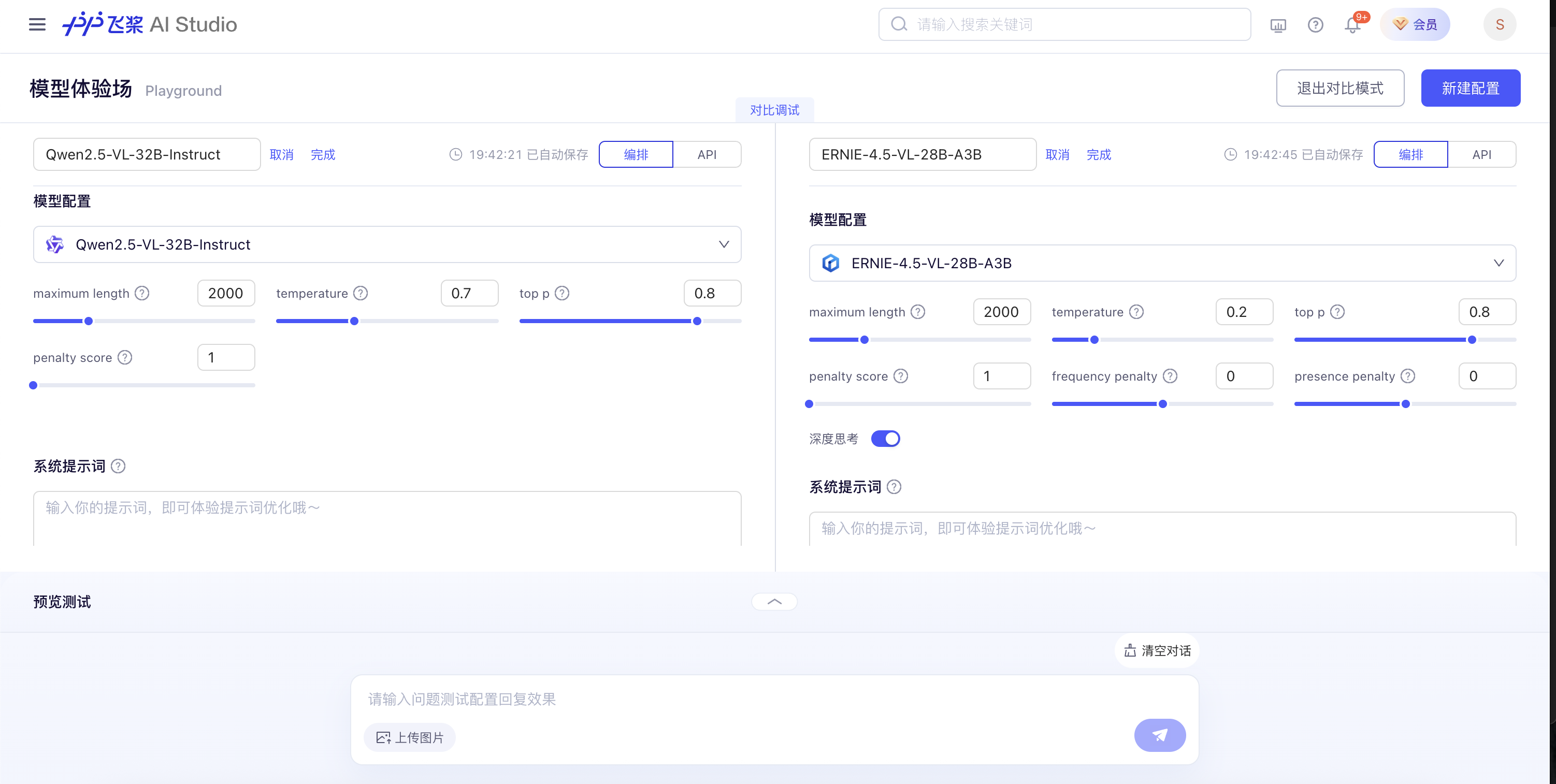
- 评分标准:满分10分,分三档——1-3分(多数错误、逻辑混乱)、4-6分(部分正确、逻辑有漏洞)、7-10分(准确清晰、适应多场景)。
- 数据透明:所有耗时、Token消耗及打分细节均来自实测,原始数据可查阅评测数据与结果明细,欢迎监督验证。

这篇测评更像“第一手体验报告”,旨在抛砖引玉,真正的“王者”还需你在实际场景中验证。话不多说,上擂台!
第一回合:效率对决——谁更快?更省?
在AI领域,“快”意味着响应及时,“省”意味着成本可控——这是衡量模型实用性的第一道门槛。直接看实测数据:
| 问题类型 | Qwen2.5耗时(秒) | Qwen2.5消耗Token | 文心4.5耗时(秒) | 文心4.5消耗Token |
|---|---|---|---|---|
| 歧义消除 | 13.11 | 1548 | 8.35 | 1331 |
| 多义词理解 | 15.05 | 2083 | 9.42 | 1633 |
| 长文核心提取 | 1.81 | 2319 | 4.68 | 1755 |
| 情感倾向分析 | 10.51 | 2727 | 8.05 | 2128 |
| 因果推断 | 14.62 | 3270 | 25.77 | 3751 |
| 条件假设 | 15.58 | 3873 | 12.38 | 3160 |
| 数学逻辑 | 13.17 | 4383 | 9.34 | 3261 |
| 伦理悖论 | 30.89 | 5512 | 15.05 | 3981 |
| 事实准确性 | 13.77 | 6026 | 6.95 | 4005 |
| 跨学科知识 | 28.2 | 7063 | 13.25 | 4716 |
| 时效性验证 | 17.93 | 7686 | 10.74 | 4861 |
| 文化常识 | 22.83 | 8449 | 9.48 | 5198 |
| 代码生成 | 35.8 | 9764 | 23.3 | 6657 |
| Debug能力 | 27.81 | 10825 | 25.62 | 7434 |
| 算法优化 | 32.36 | 11981 | 15.17 | 7021 |
| SQL实战 | 26.67 | 12948 | 10.02 | 7066 |
| 教育辅助 | 30.78 | 14028 | 17.26 | 7989 |
| 法律咨询 | 30.97 | 15123 | 12.87 | 8441 |
| 医疗建议(谨慎) | 24.75 | 16046 | 16.91 | 9460 |
关键结论:
文心4.5在效率上优势明显——除“长文核心提取”(Qwen2.5仅需1.81秒,文心4.5需4.68秒)外,其余18项任务中,文心4.5的耗时均更短,平均耗时约为Qwen2.5的65%;Token消耗上,文心4.5的平均消耗仅为Qwen2.5的70%。
举个直观例子:处理“伦理悖论”这类复杂问题时,文心4.5用15.05秒、3981Token就能完成,而Qwen2.5需要30.89秒、5512Token——相当于文心4.5“一半时间+更少成本”搞定同款任务。对企业用户来说,这意味着更低的算力成本和更流畅的用户体验。
第二回合:核心能力——谁更“聪明”?
效率只是基础,“聪明度”才是核心。我们从语言理解、逻辑推理两大维度拆解:
1. 语言理解:谁更懂人类的“言外之意”?
| 任务类型 | Qwen2.5得分 | 文心4.5得分 | 关键表现 |
|---|---|---|---|
| 歧义消除 | 9分 | 8分 | Qwen2.5对模糊语境的解析相对更加精准并且给出的答案更加简洁明了。 |
| 多义词理解 | 6分 | 5分 | 两者对多义词的场景适配均有提升空间,Qwen2.5略胜在复杂句式的处理。 |
| 长文核心提取 | 7分 | 9分 | 文心4.5对万字以上长文的要点提炼更全面,Qwen2.5偶尔遗漏细节。 |
| 情感倾向分析 | 7分 | 8分 | 文心4.5对“反讽”“隐喻”等复杂情感的识别更敏锐(如“这操作太‘秀’了”的贬义语境)。 |
2. 逻辑推理:谁的“脑子”更清晰?
| 任务类型 | Qwen2.5得分 | 文心4.5得分 | 关键表现 |
|---|---|---|---|
| 数学逻辑 | 9分 | 9分 | 两者对几何证明、概率计算等复杂数学问题的解答正确率持平,均达“理科生优等生”水平。 |
| 因果推断 | 5分 | 7分 | 文心4.5对因果关系的推断更加严谨一些,一些特殊情况也能考虑到。 |
| 条件假设 | 6分 | 7分 | 面对这类问题,文心4.5的推导链条更完整(可以罗列各种可能的情况)。 |
| 伦理悖论 | 8分 | 9分 | 处理这类问题时,文心4.5的回答更贴合人类伦理共识,Qwen2.5则相对生硬一些。 |
小结:文心4.5在长文理解、因果推断等“复杂任务”上更稳定;Qwen2.5在歧义消除、数学逻辑等“精准任务”上更突出。整体而言,文心4.5的逻辑严谨性略胜一筹。
第三回合:知识储备——谁是“行走的百科全书”?
AI的“博学度”直接影响其适用范围,我们从知识的广度、深度、准确性三个维度测评:
| 任务类型 | Qwen2.5得分 | 文心4.5得分 | 关键表现 |
|---|---|---|---|
| 事实准确性 | 10分 | 10分 | 两者对生物知识等硬核事实的回答均零错误,堪称“事实警察”。 |
| 跨学科知识 | 9分 | 7分 | Qwen2.5对跨领域问题的融合解答更流畅。 |
| 时效性验证 | 5分 | 7分 | 文心4.5数据更新到2024年7月,Qwen2.5数据更新到2023年。 |
| 文化常识 | 7分 | 9分 | 文心4.5对中国经典文学等文化细节的解释更精准更细腻,Qwen2.5相对理解表层一些。 |
小结:两者在“事实准确性”上均满分,堪称“靠谱”;但文心4.5更懂“文化”,Qwen2.5更擅长“跨学科融合”,时效性上则文心4.5更优。
第四回合:专业能力——谁是“领域专家”?
针对代码、教育、法律等专业场景,我们进一步测评:
| 任务类型 | Qwen2.5得分 | 文心4.5得分 | 关键表现 |
|---|---|---|---|
| 代码生成 | 8分 | 7分 | Qwen2.5对Python、Java的复杂函数生成更高效,文心4.5在代码注释规范性上更优。 |
| Debug能力 | 8分 | 9分 | 文心4.5对“逻辑漏洞型bug”(如循环死锁)的定位更精准,Qwen2.5擅长“语法错误”修复。 |
| 算法优化 | 7分 | 9分 | 文心4.5对“排序算法优化”“数据库查询效率提升”等任务的方案更实用,Qwen2.5偶有理论化倾向。 |
| SQL实战 | 8分 | 9分 | 两者输出的SQL结果相同,但是文心4.5明细速度快很多。 |
| 教育辅助 | 7分 | 8分 | 文心4.5对“初中物理实验设计”的设计方案更贴近教学逻辑,由简到难适合学生理解。Qwen相对来说表现一般,只是完成了任务。 |
| 法律咨询 | 8分 | 9分 | 文心4.5对“劳动法”的解读更严谨,Qwen2.5在案例类比上更灵活。 |
| 医疗建议 | 6分 | 7分 | 两者均能提供基本诊断以及基础健康建议,但均明确标注“仅供参考,需遵医嘱”,文心4.5的风险提示更细致。 |
小结:文心4.5在算法优化、法律/教育辅助等“专业场景”中更严谨;Qwen2.5在代码生成、跨场景类比上更灵活。需注意:法律、医疗等领域的AI建议需结合专业人士判断,不可直接采信。
终极总结:该选谁?看你的需求!
两款模型各有侧重,没有绝对“王者”,只有“更适合”:
- 选文心4.5,如果你需要:
效率优先(快且省Token)、逻辑严谨(适合长文处理、因果分析)、专业场景适配(法律、教育、算法优化)——它像一位“高效全能的办公室主任”,能稳妥搞定大多数日常任务。 - 选Qwen2.5,如果你需要:
跨学科融合(如科技+人文的内容创作)、精准语言解析(歧义消除、多义词处理)、代码快速生成——它像一位“脑洞大的技术专家”,在创新场景中更易出惊喜。
国产AI的进步,比“谁赢了”更值得关注:从几年前的“勉强能用”到如今的“各有所长”,文心4.5和Qwen2.5的对决,本质是国产大模型技术的“双向奔赴”。
未来,随着迭代升级,我们或许能看到“效率+智能”双全的终极形态——而这,才是用户最期待的“国产之光”。
你更倾向哪款?欢迎在评论区分享你的实测体验!
一起来轻松玩转文心大模型吧——文心大模型免费下载地址:
https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)