【课程笔记】华为 HCIP-AI Solution Architect 人工智能04:华为智算中心解决方案简介
目录华为智算中心解决方案简介一、智算时代数据中心概览1. 数据中心的定义及常用指标2. 智算中心总体方案二、智算中心算力解决方案三、智算中心网络解决方案及关键技术1. AI训练对网络的需求2. 智算中心网络解决方案 - 超融合以太网络3. 华为无损网络关键技术四、智算中心存储解决方案及关键特性(1) 数据中心定义,人工智能计算中心分层概念(2) 数据中心发展史(3) 数据中心物理模型(4) 数据中
华为智算中心解决方案简介
目录
一、智算时代数据中心概览
1. 数据中心的定义及常用指标
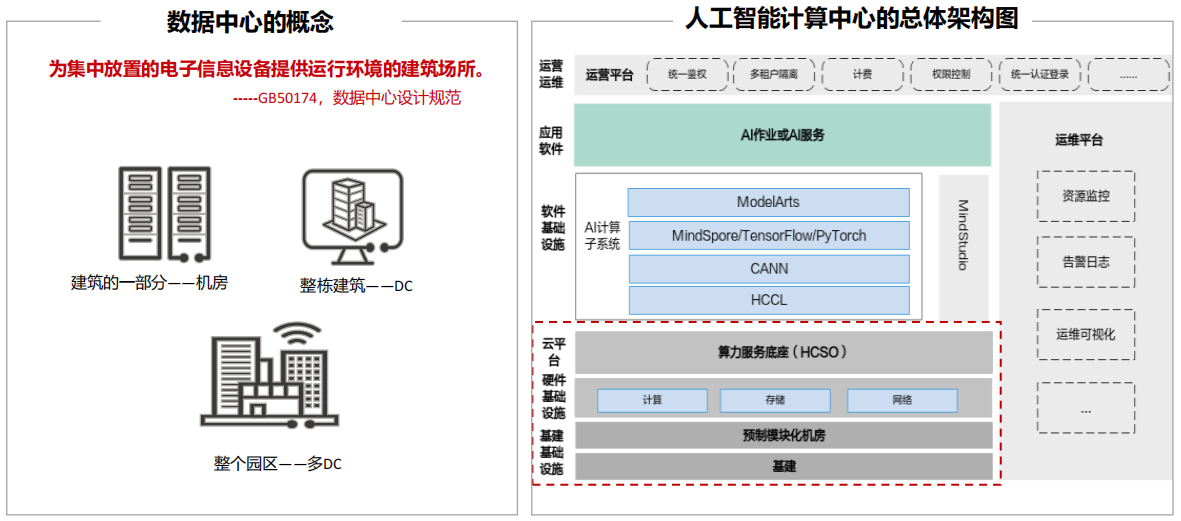
(1) 数据中心定义,人工智能计算中心分层概念
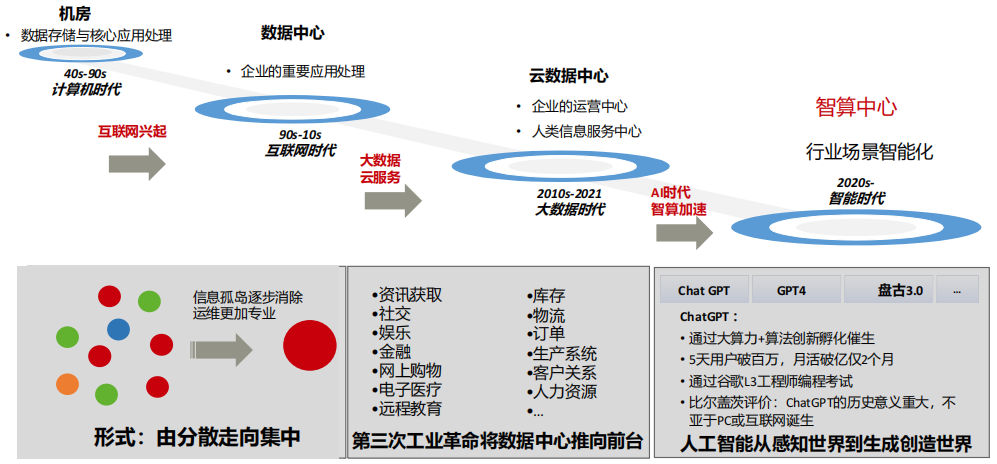
(2) 数据中心发展史
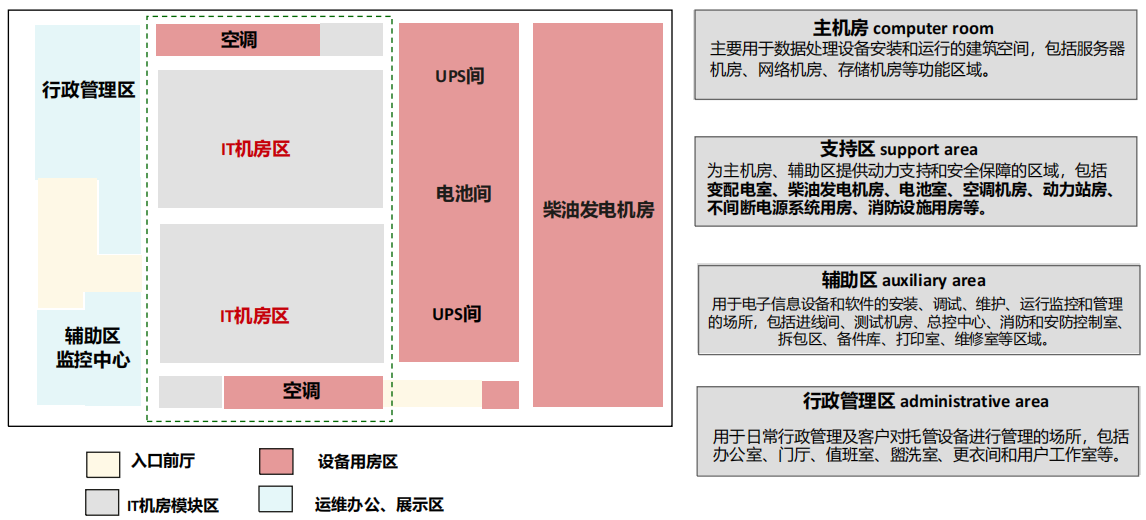
(3) 数据中心物理模型
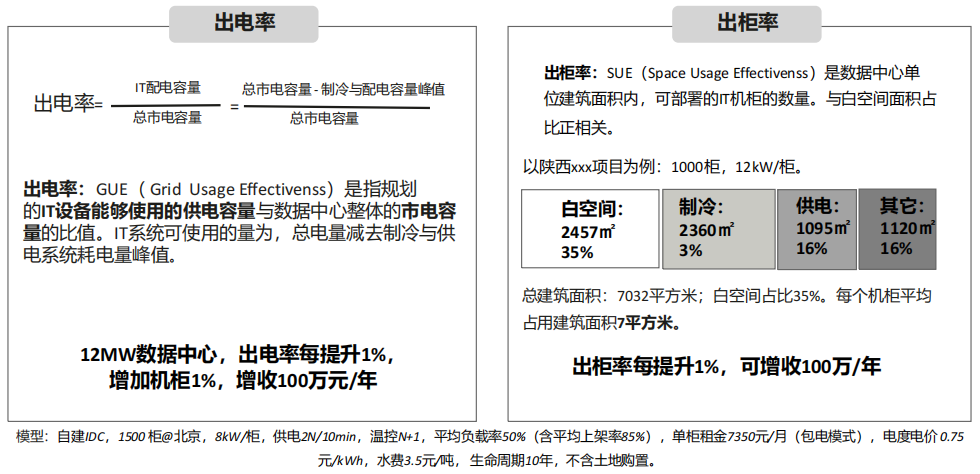
(4) 数据中心关键指标 出电率、出柜率
(5) PUE WUE 电力 面积 机柜数的关系

(6) AI服务器的高密化,推动供配电系统高密
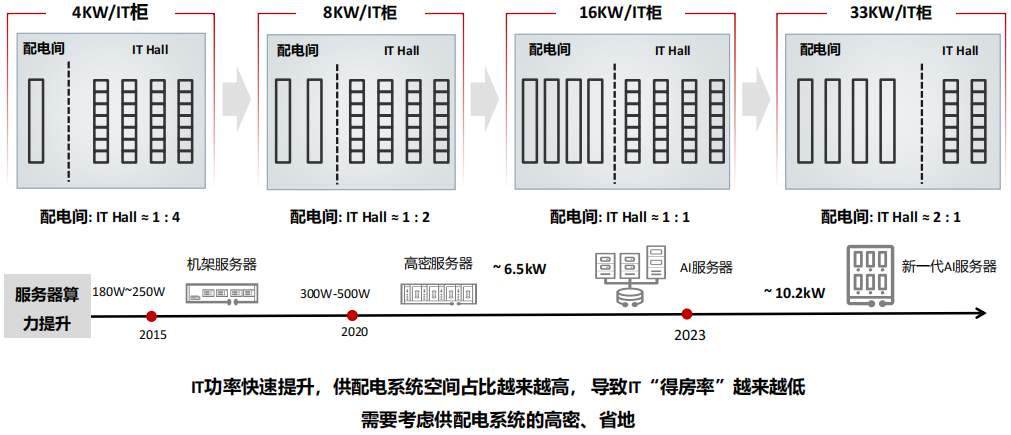
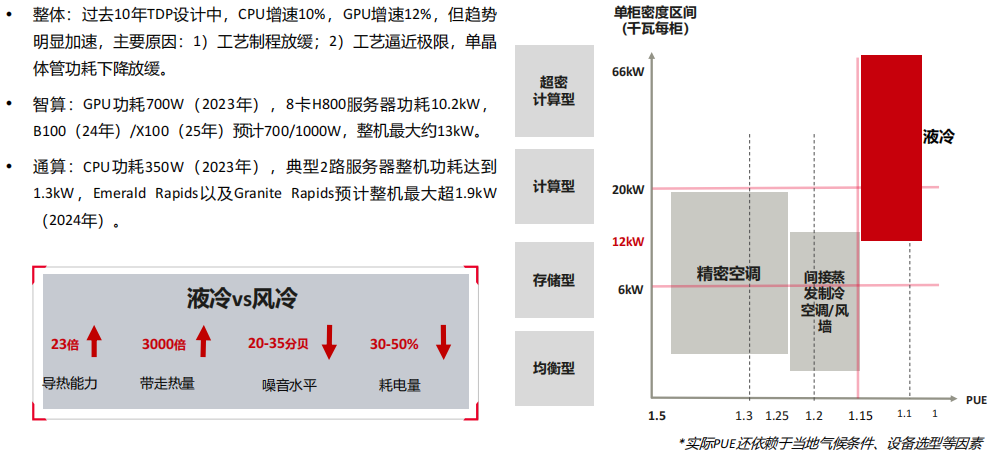
(7) AI服务器的高密化,推动制冷系统进入液冷时代
2. 智算中心总体方案
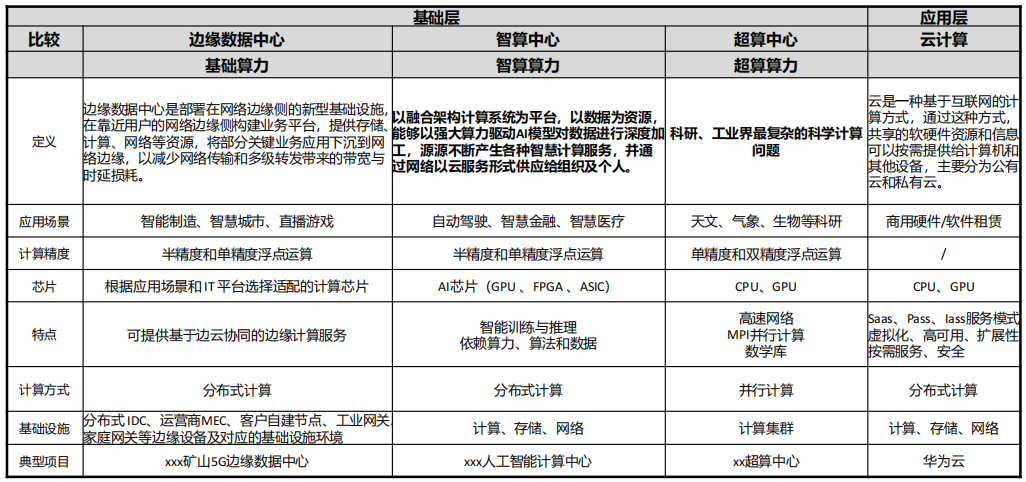
(1) 业界应用场景对算力的需求差异,决定了数据中心的类型
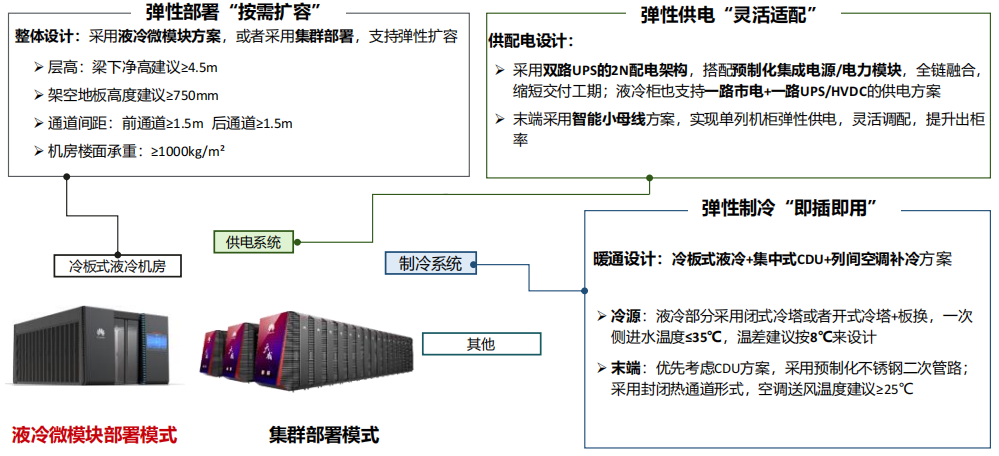
(2) 典型智算中心总体方案:Lacility架构(L1)
(3) 典型智算中心总体方案:L2层基础架构图
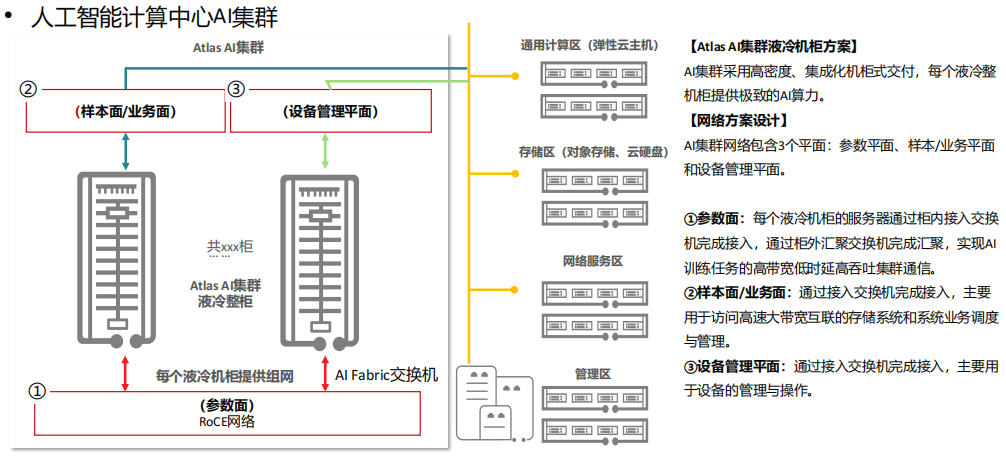
二、智算中心算力解决方案
(1) 人工智能的三大关键要素,从“训练”中学习,到“推理”中应用
算力、算法、数据三大要素构筑人工智能基础:
①算力:人工智能的身体,体现人工智能计算速度和效率
②算法:人工智能的大脑,对资源有效利用的思想和灵魂
③数据:人工智能的粮食,是一切智慧物体的学习资源
AI训练及推理基本概念:
①AI训练:从现有的数据中学习新能力,形成算法(模型)
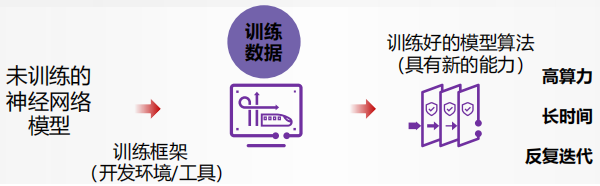
②AI推理:把训练好的模型部署到应用或服务中

(2) 通用计算 vs AI计算:“分工”不同,共建多样性计算
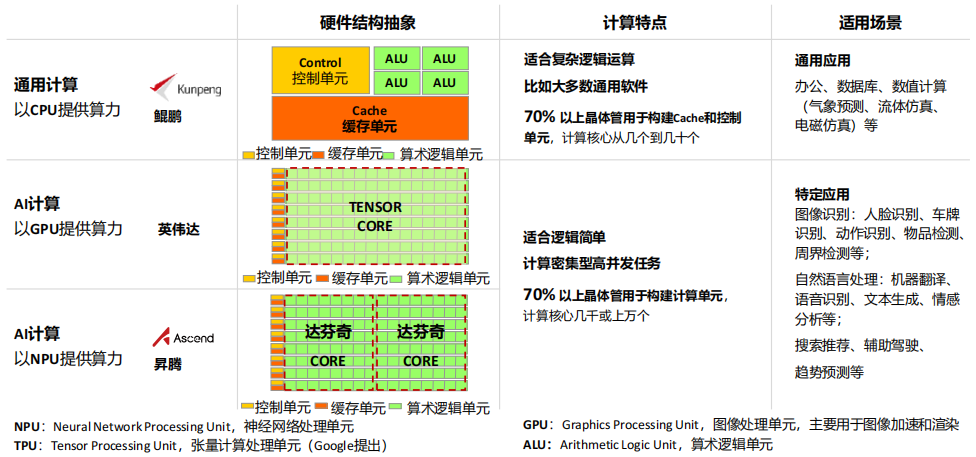
(3) AI芯片
从技术架构来看,大致分为四个类型:
①CPU(中央处理器):是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心(Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据
②GPU(图形处理器):又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器
③ASIC(专用集成电路):适合于某一单一用途的集成电路产品
④FPGA(现场可编程门阵列):其设计初衷是为了实现半定制芯片的功能,即硬件结构可根据需要实时配置灵活改变
从业务应用来看,可以分为Training(训练)和Inference(推理)两个类型:
①Training环境通常需要通过大量的数据输入,或采取增强学习等非监督学习方法,训练出一个复杂的深度神经网络模型。训练过程涉及海量的训练数据和复杂的深度神经网络结构,运算量巨大,需要庞大的计算规模,对于处理器的计算能力、精度、可扩展性等性能要求很高。常用的例如NVIDIA的GPU集群、Google的TPU等
②Inference环节指利用训练好的模型,使用新的数据区“推理”出各种结论。虽然Inference的计算量相比Training少很多,但仍然涉及大量的矩阵运算。在推理环节,GPU、FPGA和ASIC都有很多应用价值
(4) 人工智能芯片行业背景
基于FPGA的半定制人工智能芯片,利用具备可重构性的FPGA芯片来半定制的人工智能芯片是最佳选择
针对深度学习算法的全定制人工智能芯片,该类芯片是完全采用ASIC设计方法全定制,性能、功耗和面积等指标面向深度学习算法都做到了最优。谷歌的TPU芯片、我国中科院计算所的寒武纪深度学习处理器芯片就是这类芯片的典型代表
类脑计算芯片,这类芯片的设计目的不再局限于仅仅加速深度学习算法,而是在芯片基本结构甚至器件层面上希望能够开发新的计算机体系结构。这类芯片的典型代表是IBM的Truenorth芯片
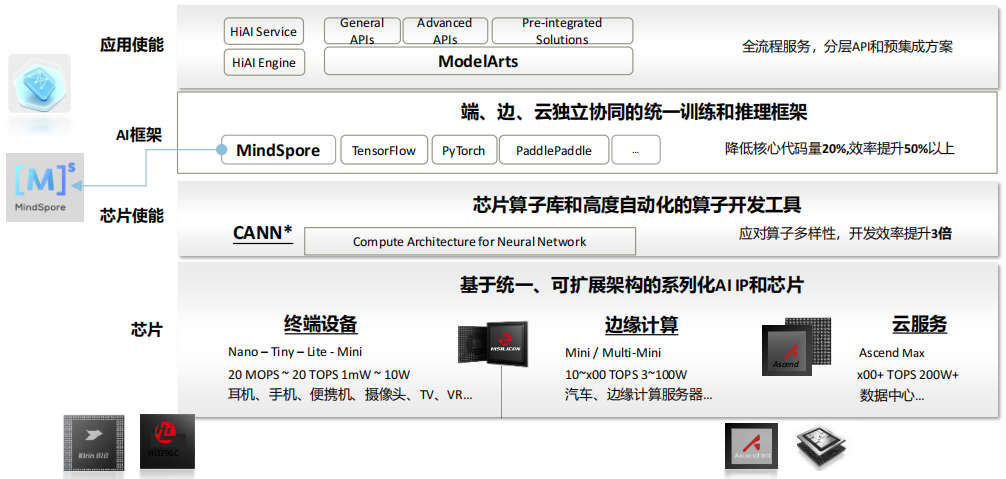
(5) 华为AI全栈解决方案
(6) 昇腾(Ascend)AI处理器
NPU(神经网络处理器):在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理
NPU的典型代表:华为昇腾AI芯片(Ascend)、IBM的TrueNorth
华为昇腾AI芯片主要有两种类型:面向推理场景的芯片、面向训练场景的芯片
(7) AI Core:在昇腾处理器中的位置
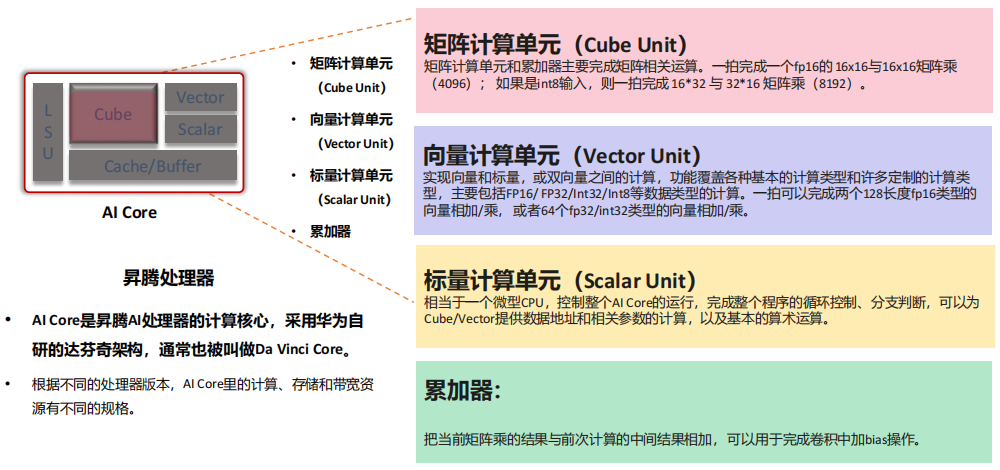
总结
算力芯片分类
训练芯片:算力高,运行时间长,迭代次数多 -> GPU、TPU、NPU
推理芯片:算力低、快速计算 -> GPU、CPU、NPU、FPGA、ASIC
三、智算中心网络解决方案及关键技术
1. AI训练对网络的需求
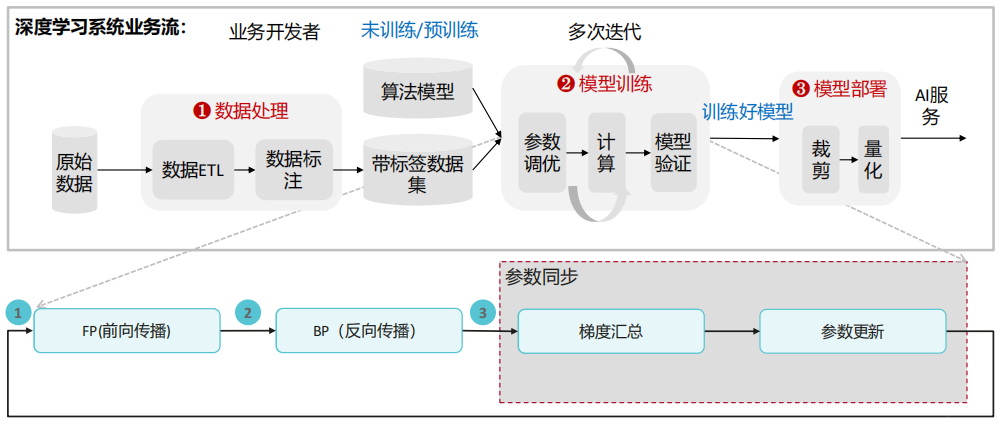
(1) 人工智能基本工作流程
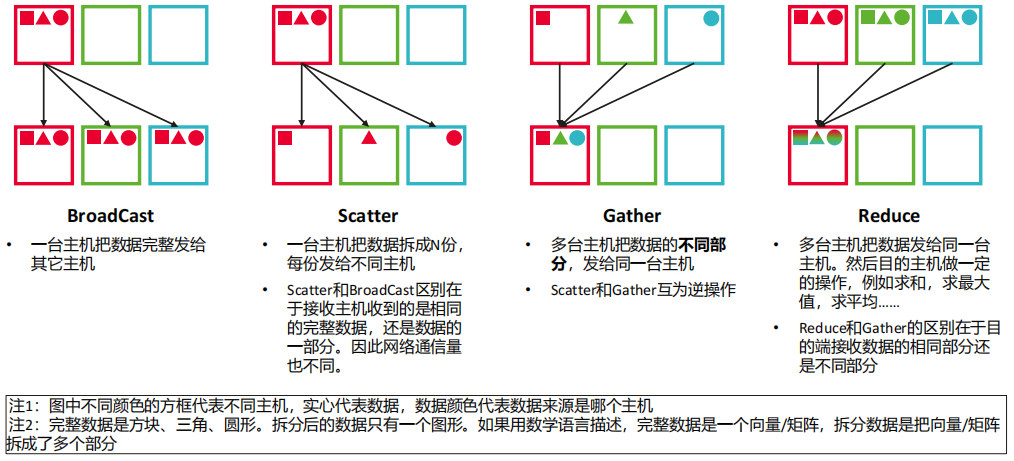
(2) 大模型的集合通信模式:基本操作
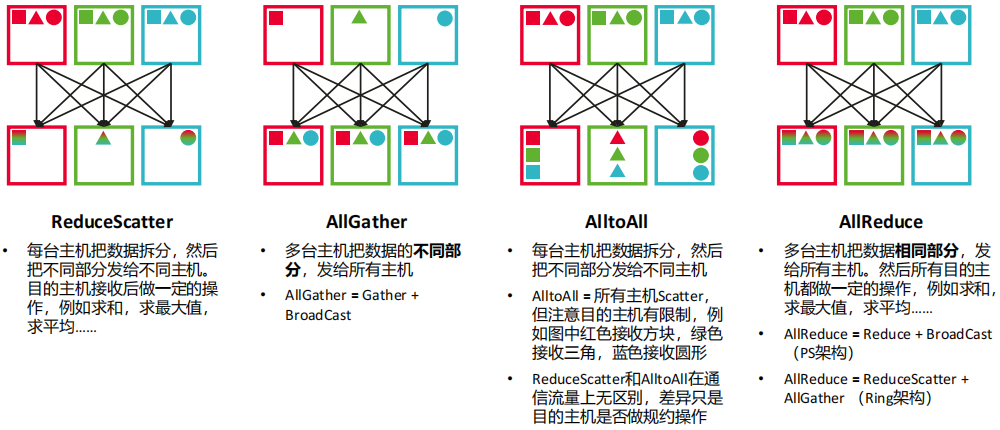
(3) 大模型的集合通信模式:组合操作
(4) 并行训练的通信模式
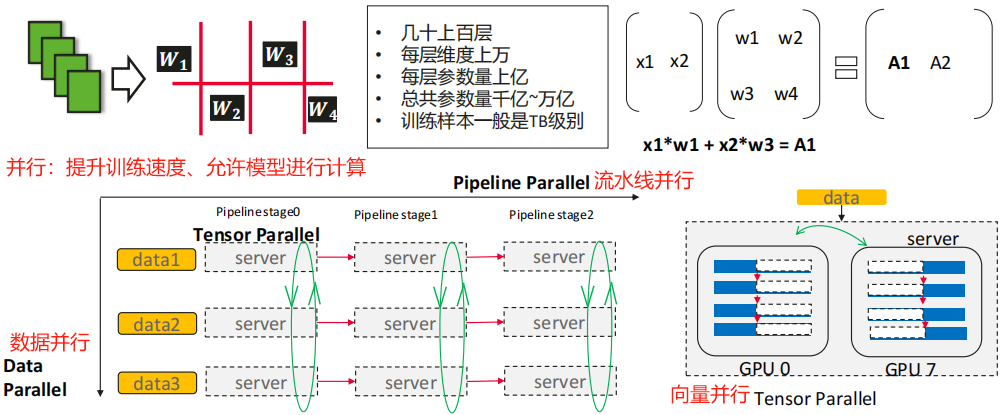
数据并行(Data Parallel)-> 拆数据(人人独立干活)
①拆什么:数据(比如100张图 → 4份,每份25张)
②怎么算:每个GPU用完整模型计算自己的数据,最后汇总梯度
③优点:简单,适合数据量大、模型能塞进单卡的任务
④缺点:模型太大时,单卡装不下
⑤例子:4个人抄同一本书,每人抄不同章节
张量并行(Tensor Parallelism)-> 拆模型参数(团队协作算矩阵)
①拆什么:模型参数(比如大矩阵切4块)
②怎么算:每个GPU算模型的一部分,所有数据都传给它,最后拼结果
③优点:能跑超大模型(如GPT-3)
④缺点:通信频繁,实现复杂
⑤例子:4个人合写一句话,每人写几个字
流水线并行(Pipeline Parallelism)-> 拆模型层(流水线式接力计算)
①拆什么:模型层(比如10层模型 → GPU1算1-3层,GPU2算4-6层…)
②怎么算:数据像流水线一样依次流过各GPU,每卡处理特定层
③优点:适合超深模型(如Transformer)
④缺点:存在“气泡”闲置时间(等上游传数据)
⑤例子:工厂流水线,每个工人只装一个零件
| 特性 | 数据并行 | 张量并行 | 流水线并行 |
|---|---|---|---|
| 拆分对象 | 数据 | 模型参数 | 模型层 |
| 适用场景 | 数据多、模型小 | 模型超大 | 模型超深 |
| 通信开销 | 低(同步梯度) | 高(传中间结果) | 中(层间传递) |
| 典型应用 | CNN训练 | GPT-3 | Transformer |
(5) 模型训练的通信量估计
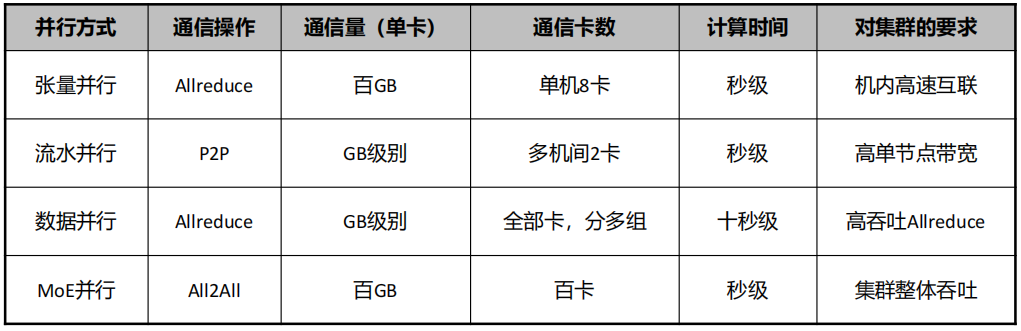
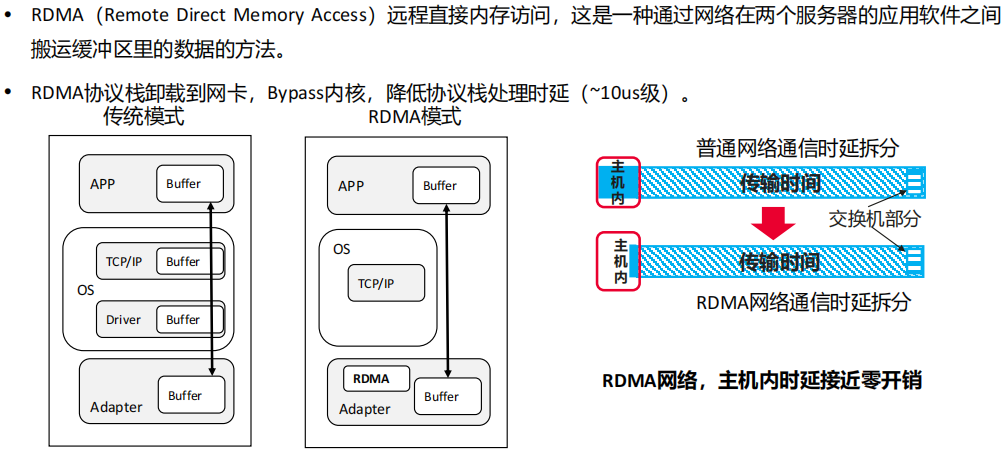
(6) 模型训练的网络特性要求1:RDMA是刚需
(7) 模型训练的网络特性要求2:大带宽是基础

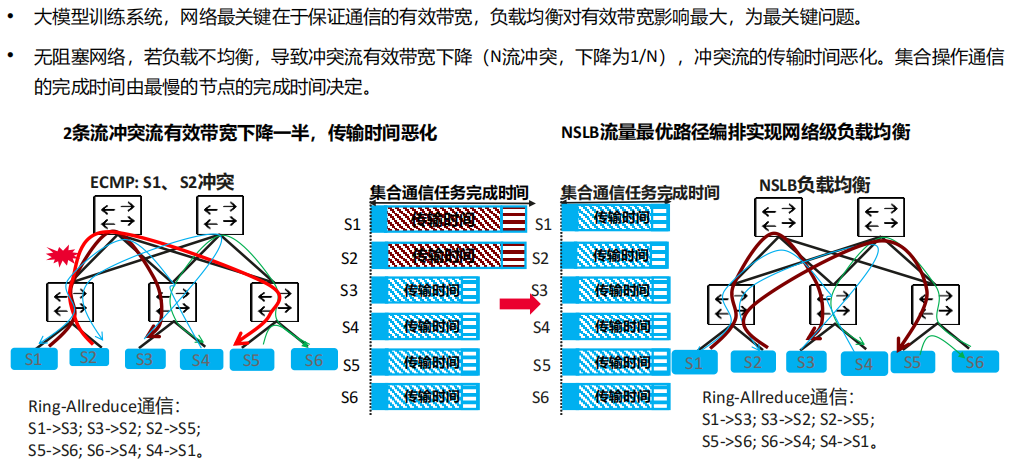
(8) 模型训练的网络特性要求3:负载均衡是关键
2. 智算中心网络解决方案 - 超融合以太网络
(1) 无损以太网络协议发展
无损以太网最早在2008年提出,主要的两个基础协议为PFC(基于优先级的流控)和ECN(明确拥塞通告)
高性能分布式计算和高性能存储RDMA的普及以及融合以太网的应用,使得ECN技术和PFC技术等无损协议得到广泛应用,由此诞生了无损以太网的概念
无损以太网除了涉及网络侧的技术,还包括服务器网卡侧的特性,包括为了支持RDMA协议在以太网传输的RoCE特性以及NVMe协议在以太网传输的NoF
(2) 技术路线:IB

(3) 技术路线:RoCE

3. 华为无损网络关键技术
(1) 流控技术:PFC(Priority-based Flow Control)

(2) 技术演进趋势
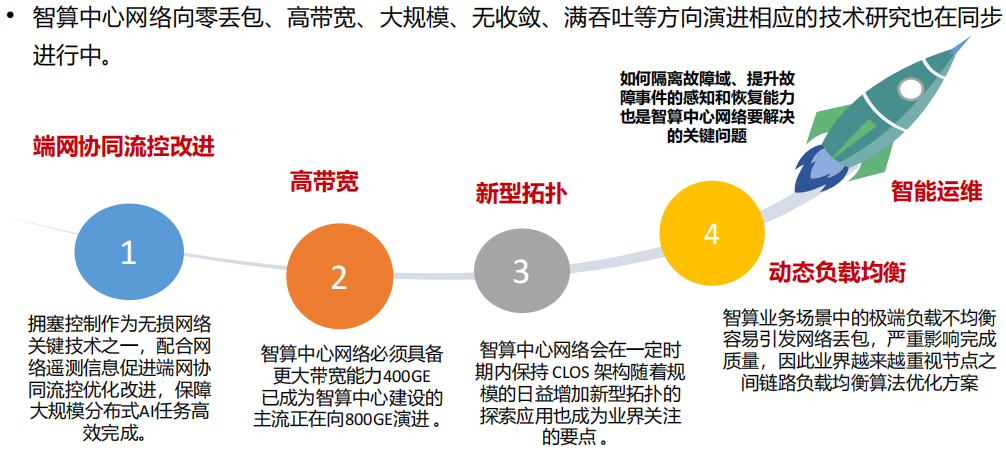
四、智算中心存储解决方案及关键特性
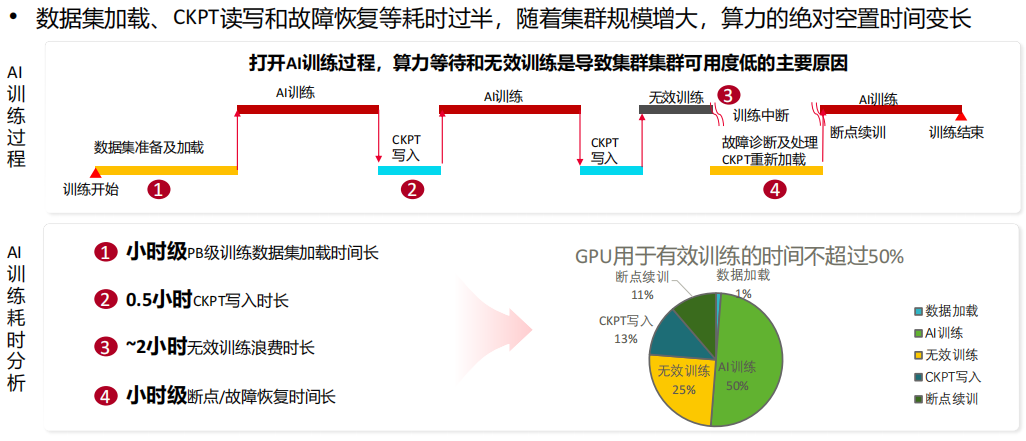
(1) AI场景下存储的挑战1:集群可用度低

(2) AI场景下存储的挑战2:存储集群性能受制约
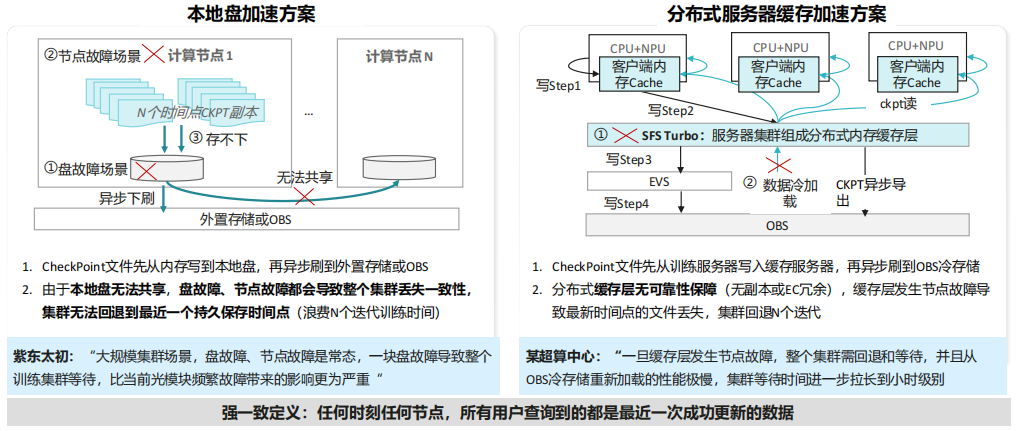
(3) AI场景下存储的挑战3:现有本地盘/缓存加速方案,难以满足万亿级多模态训练数据强一致性诉求
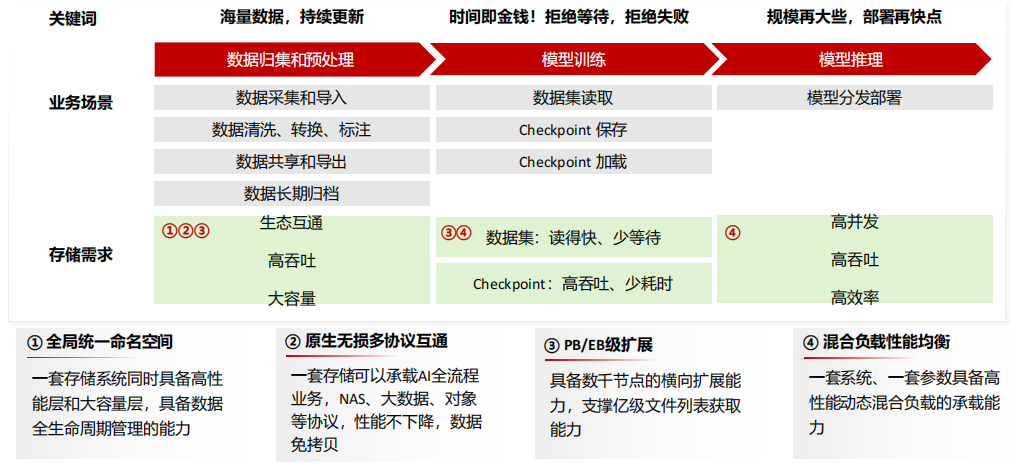
(4) 从“堆算力”到“提效率”AI数据存储的要求

(5) AI大模型时代的存储需求
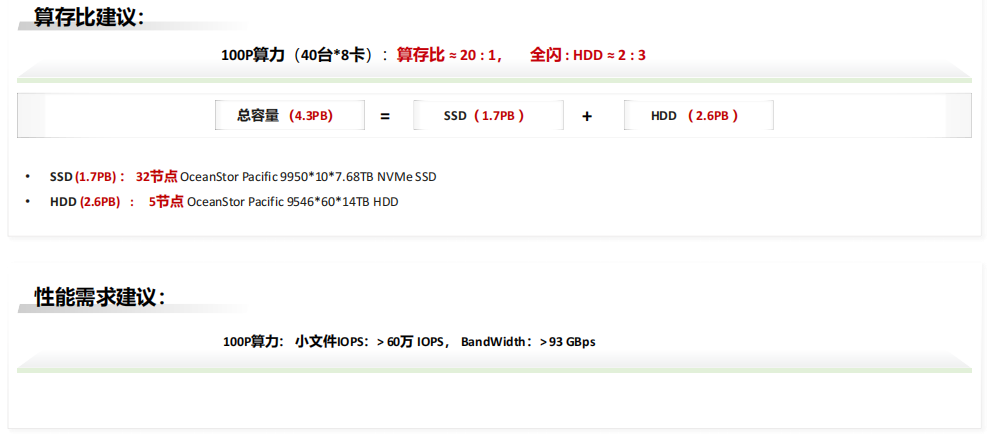
(6) 智算中心AI存力平台规划建议

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 37
37 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)