深入浅出大模型量化(三): AWQ,让低比特大模型重获新生
深入浅出大模型量化(三): AWQ,让低比特大模型重获新生
告别精度焦虑:揭秘激活感知权重量化 AWQ,让低比特大模型重获新生
大家好!我是你们的老朋友小雲。在追求更大、更强的 LLM 的道路上,模型大小和推理速度一直是绕不开的挑战。"模型量化"作为一项关键的压缩技术,旨在用更少的比特数表示模型参数(权重)和/或中间计算结果(激活),从而减少内存占用、提升推理速度。
然而,将 LLM 量化到极低比特(如 INT4甚至 INT3)并非易事。
- 量化感知训练 (Quantization-Aware Training, QAT): 虽然效果好,能在训练中模拟量化误差并进行调整,但需要完整的训练或微调流程,计算成本高昂,对于动辄千亿参数的 LLM 来说不太现实。
- 训练后量化 (Post-Training Quantization, PTQ): 无需重新训练,成本低廉。但传统的 PTQ 方法(如简单的取整 RTN)在低比特场景下精度损失严重。像 GPTQ 这样的先进 PTQ 方法,虽然利用二阶信息进行误差补偿,提高了精度,但它在量化过程中可能“用力过猛”,过度拟合用于校准的小数据集,损害了 LLM 作为“通才模型”在广泛任务上的泛化能力。

(左图:AWQ仅需极小的校准集即可达到优异的量化性能。与GPTQ相比,AWQ使用仅1/10规模的校准集就能实现更优的困惑度。右图:AWQ对校准集分布变化具有更强的鲁棒性。实验表明,当校准集与评估集分布一致时(如PubMed-PubMed、Enron-Enron),两种方法均达到最佳性能。但当校准集分布不同时(如PubMed-Enron或Enron-PubMed),AWQ的困惑度仅增加0.5-0.6,而GPTQ的困惑度却显著恶化(增加2.3-4.9)。所有实验均在OPT-6.7B模型上采用INT3-g128量化配置完成。)
有没有一种 PTQ 方法,既能实现低比特权重量化,保持高精度,又不损害模型的泛化能力,还对硬件友好呢?
答案是肯定的!今天,我们就来深入了解 激活感知权重量化 (Activation-aware Weight Quantization, AWQ) 技术。
AWQ 的核心洞察:权重的重要性由激活决定!
AWQ 的出发点非常直观:LLM 中的权重并非生而平等,并非所有权重都同等重要。 存在一小部分(约 0.1% - 1%)的显著权重 (salient weights),它们对模型的整体性能起着决定性的作用。
那么,如果我们只量化那些“不太重要”的权重,而保护好这一小撮“关键先生”,是不是就能在低比特下保持精度呢?
研究人员首先尝试了一个想法:直接保留那些数值本身比较大(L2 范数较大)的权重通道(不量化,保持 FP16),其他通道进行量化。结果发现,效果并不理想,和随机选择保留通道差不多。
关键的转折点来了: 研究人员意识到,判断一个权重通道是否“重要”,不应该只看权重本身的大小,而应该看它处理的激活值 (activation) 的幅度!
为什么呢?因为激活值代表了流经模型的信息。那些经常处理具有较大激活幅度的特征的权重通道,自然承载了更重要的信息流。 保留这些与大激活值对应的权重通道(保持 FP16),效果立竿见影!仅仅保留 0.1% - 1% 的这类权重,量化后的模型性能就得到了显著提升,甚至能媲美复杂的 GPTQ 方法。
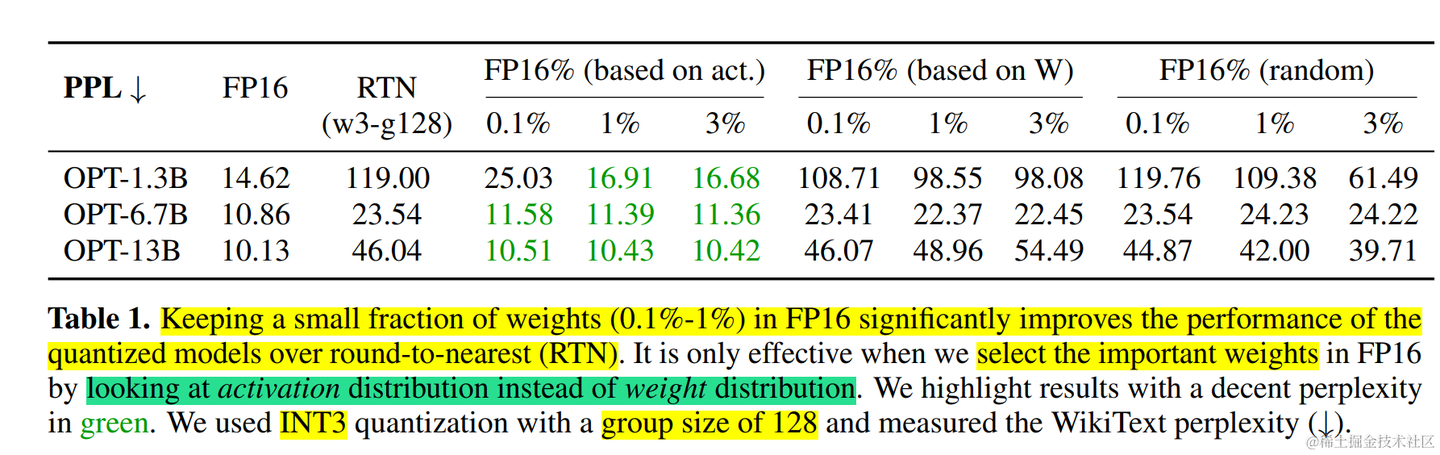
(表一:仅保留少量权重(0.19%-19%)为FP16格式即可显著提升量化模型性能,相较最近邻舍入法(RTN)量化优势明显。但此方法仅在通过激活分布(而非权重分布)筛选重要权重时有效。绿色标记表示困惑度(Perplexity)表现较优的结果。所有实验均采用分组量化(group size=128)的INT3量化配置,并在WikiText数据集上评测困惑度)
这个发现揭示了 AWQ 的第一个核心原则:权重的显著性是由激活感知的 (Activation-aware)。
AWQ 技术原理:巧妙缩放,保护关键权重
虽然保留 1% 的 FP16 权重听起来不错,但它引入了混合精度的问题。在硬件层面,高效处理这种混合数据类型(比如 INT3 权重和 FP16 权重混合在一个矩阵里)是非常困难的,会严重拖慢推理速度,使得量化的加速优势荡然无存。
我们需要一种方法,既能保护这些重要的权重,又不引入硬件不友好的混合精度。AWQ 的第二个妙招登场了:激活感知缩放 (Activation-aware Scaling)。
这个想法借鉴了 SmoothQuant 的思路,但应用场景和目标不同。我们来分析一下仅权重量化 (Weight-only Quantization) 的误差来源。
考虑一个线性运算 y = w x y = wx y=wx,其中 w w w 是一组权重(比如一个 group 或 block), x x x 是对应的输入激活。量化后的运算是 y q = Q ( w ) x y_q = Q(w)x yq=Q(w)x。
一个常见的量化函数 Q ( w ) Q(w) Q(w)(以对称量化为例)是:
Q ( w ) = Δ ⋅ Round ( w Δ ) Q(w) = \Delta \cdot \text{Round}\left(\frac{w}{\Delta}\right) Q(w)=Δ⋅Round(Δw)
其中 Δ = max ( ∣ w ∣ ) 2 N − 1 \Delta = \frac{\max(|w|)}{2^{N-1}} Δ=2N−1max(∣w∣) 是量化步长(scale), N N N 是比特数, Round \text{Round} Round 是取整操作。量化误差主要来自 Round \text{Round} Round 操作和 Δ \Delta Δ 的选择。
现在,AWQ 提出:如果我们找到那些“重要”的权重 w salient w_{\text{salient}} wsalient(对应大激活值 x salient x_{\text{salient}} xsalient),在量化前,将这些权重乘以一个缩放因子 s > 1 s > 1 s>1,变成 w salient ⋅ s w_{\text{salient}} \cdot s wsalient⋅s。同时,为了保持数学等价性,将对应的激活除以 s s s,变成 x salient / s x_{\text{salient}} / s xsalient/s。那么,量化后的运算就变成了:
y q ′ = Q ( w salient ⋅ s ) ⋅ ( x salient s ) y'_q = Q(w_{\text{salient}} \cdot s) \cdot \left(\frac{x_{\text{salient}}}{s}\right) yq′=Q(wsalient⋅s)⋅(sxsalient)
这个操作对量化误差有什么影响呢?
-
取整误差 (RoundErr):
Round ( w ⋅ s Δ ′ ) \text{Round}\left(\frac{w \cdot s}{\Delta'}\right) Round(Δ′w⋅s)
相对于 Round ( w / Δ ) \text{Round}(w/\Delta) Round(w/Δ),其期望误差(通常认为是均匀分布在 [ − 0.5 , 0.5 ] [-0.5, 0.5] [−0.5,0.5] 或 [ 0 , 0.5 ] [0, 0.5] [0,0.5] 区间)变化不大。 -
量化步长 ( Δ ′ \Delta' Δ′):
如果我们只缩放一小部分权重 ( w salient w_{\text{salient}} wsalient),并且 s s s 不是特别大,那么整个权重组 w w w 的最大绝对值 max ( ∣ w ∣ ) \max(|w|) max(∣w∣) 可能变化不大。这意味着新的量化步长 Δ ′ \Delta' Δ′ 与原来的 Δ \Delta Δ 近似相等:
Δ ′ ≈ Δ \Delta' \approx \Delta Δ′≈Δ -
最终误差:
量化后的值 Q ( w ⋅ s ) Q(w \cdot s) Q(w⋅s) 乘以 x / s x/s x/s 引入的误差大约是:
Err ′ ≈ Δ ′ ⋅ RoundErr ⋅ ( 1 s ) \text{Err}' \approx \Delta' \cdot \text{RoundErr} \cdot \left(\frac{1}{s}\right) Err′≈Δ′⋅RoundErr⋅(s1)
与原始误差 Err ≈ Δ ⋅ RoundErr \text{Err} \approx \Delta \cdot \text{RoundErr} Err≈Δ⋅RoundErr 相比,误差的比例大约是:
Err ′ Err ≈ ( Δ ′ Δ ) ⋅ ( 1 s ) \frac{\text{Err}'}{\text{Err}} \approx \left(\frac{\Delta'}{\Delta}\right) \cdot \left(\frac{1}{s}\right) ErrErr′≈(ΔΔ′)⋅(s1)
由于 Δ ′ ≈ Δ \Delta' \approx \Delta Δ′≈Δ 且 s > 1 s > 1 s>1,那么 Err ′ / Err < 1 \text{Err}'/\text{Err} < 1 Err′/Err<1。
这意味着,通过放大显著权重 w salient w_{\text{salient}} wsalient(乘以 s > 1 s > 1 s>1),其对应的相对量化误差被有效地减小了! 我们在不改变数据类型(所有权重最终都量化为 INT N)的情况下,达到了保护重要权重的目的。
实验也验证了这一点:对 OPT-6.7B 模型,仅将 1% 的显著通道权重乘以 s(比如 s=2),困惑度 (PPL) 从基线 RTN 量化的 23.54 大幅降低到 11.92。
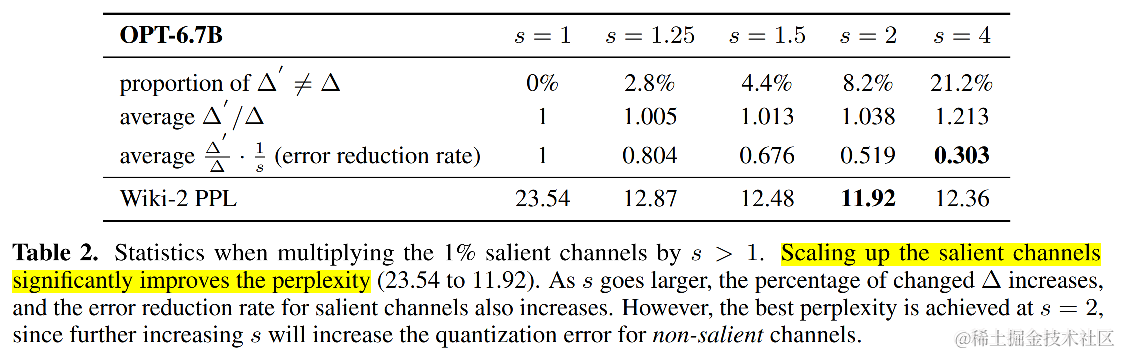
但是,s 也不是越大越好。 从上图可以看到,当 s 过大时(如 s=4),虽然显著权重的误差继续减小,但它会导致整个权重组的 max(|w|) 显著增大,从而使得量化步长 Δ' 变大 (Δ'/Δ > 1)。这反而会增加那些非显著权重的量化误差,损害整体性能。最佳性能出现在 s=2 附近。
如何找到最优的缩放因子 s 呢?
我们需要找到一个 s s s(实际上是每个输入通道一个 s j s_j sj),使得缩放和量化后的输出与原始输出之间的误差最小。优化目标可以写成:
s ∗ = arg min s L ( s ) s^* = \arg\min_s L(s) s∗=argsminL(s)
L ( s ) = ∥ Q ( W ⋅ diag ( s ) ) ⋅ ( diag ( s ) − 1 ⋅ X ) − W X ∥ L(s) = \| Q(W \cdot \text{diag}(s)) \cdot (\text{diag}(s)^{-1} \cdot X) - WX \| L(s)=∥Q(W⋅diag(s))⋅(diag(s)−1⋅X)−WX∥
这里 W W W 是权重矩阵, X X X 是来自校准集的输入激活, diag ( s ) \text{diag}(s) diag(s) 是对角线为缩放因子 s j s_j sj 的矩阵。
直接优化这个目标很难,因为量化函数 Q Q Q 不可微。AWQ 再次展现了其简洁而有效的设计哲学:
-
简化搜索空间: 既然权重的显著性由激活决定,那么最优的缩放因子 s j s_j sj 也应该主要与对应通道的激活尺度 s X j = E [ ∣ X j ∣ ] s_{X_j} = \mathbb{E}[|X_j|] sXj=E[∣Xj∣](激活绝对值的期望或某个分位数)相关。AWQ 提出用一个非常简单的关系来参数化 s j s_j sj:
s j = ( s X j ) α s_j = (s_{X_j})^\alpha sj=(sXj)α这里引入了一个单一的超参数 α \alpha α(取值范围通常在 [ 0 , 1 ] [0, 1] [0,1]),它像一个杠杆,平衡了对显著通道(大 s X j s_{X_j} sXj)和非显著通道(小 s X j s_{X_j} sXj)的保护程度。 α = 0 \alpha=0 α=0 意味着不缩放(等同于 RTN), α = 1 \alpha=1 α=1 意味着最激进的缩放。
-
快速网格搜索: 我们只需要在一个小的校准集上,通过网格搜索 (grid search) 找到最优的 α \alpha α 值,使得量化误差 L ( s X α ) L(s_X^\alpha) L(sXα) 最小。这个搜索过程非常快。
锦上添花:权重裁剪 (Weight Clipping)
在找到最优 α \alpha α 并计算出 s s s 后,AWQ 还会做一个可选的权重裁剪操作。在量化 W scaled = W ⋅ diag ( s ) W_{\text{scaled}} = W \cdot \text{diag}(s) Wscaled=W⋅diag(s) 之前,可以将 W scaled W_{\text{scaled}} Wscaled 中超过某个阈值的数值裁剪掉。这样做可以进一步降低 max ( ∣ W scaled ∣ ) \max(|W_{\text{scaled}}|) max(∣Wscaled∣),从而减小量化步长 Δ ′ \Delta' Δ′,进一步降低整体量化误差。
AWQ 总结:
整个 AWQ 流程如下:
- 收集激活尺度: 在校准集上运行 FP16 模型,计算每个输入通道的激活尺度 s X j s_{X_j} sXj。
- 搜索最优 α \alpha α: 通过网格搜索找到最佳 α \alpha α,使得量化误差 L ( s X α ) L(s_X^\alpha) L(sXα) 最小。
- 计算缩放因子: s j = ( s X j ) α s_j = (s_{X_j})^\alpha sj=(sXj)α。
- 缩放权重: W scaled = W ⋅ diag ( s ) W_{\text{scaled}} = W \cdot \text{diag}(s) Wscaled=W⋅diag(s)。
- (可选) 裁剪权重: 对 W scaled W_{\text{scaled}} Wscaled 进行裁剪。
- 量化权重: W q = Q ( W scaled ) W_q = Q(W_{\text{scaled}}) Wq=Q(Wscaled)(例如,INT4 或 INT3 量化)。
- 保存: 保存量化后的权重 W q W_q Wq 和每个通道的缩放因子 s j s_j sj(或者说 1 / s j 1/s_j 1/sj,因为推理时需要用它来缩放激活)。

AWQ 的优势:
- 高精度: 在 INT4/INT3 权重量化下,精度显著优于 RTN,与 GPTQ 相当或更好。
- 强泛化能力: 不依赖反向传播或复杂的重构,仅使用激活尺度信息,对校准集依赖小,不易过拟合,能很好地保持 LLM 在各种任务上的原始能力。
- 硬件友好: 最终产物是纯粹的低比特权重,没有混合精度问题,易于在现有硬件上实现高效推理(通常是 W4A16 或 W3A16 形式,即 INT4/3 权重 + FP16 激活/计算)。
- 速度快: 量化过程本身非常快(主要是网格搜索
α)。
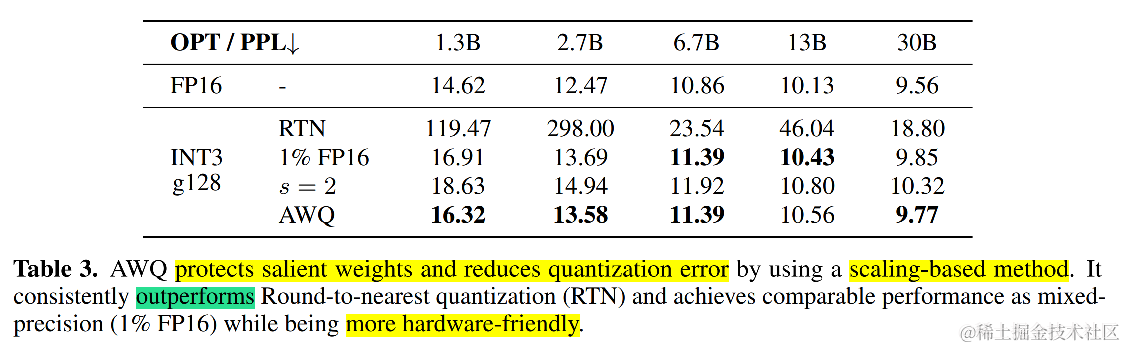
(OPT 模型上的消融实验,AWQ 性能接近混合精度,远超 RTN)
AWQ 实验效果惊艳
AWQ 在各种模型家族(LLaMA, OPT, BLOOM 等)和不同模型大小上都取得了 SOTA (State-of-the-Art) 的量化效果。
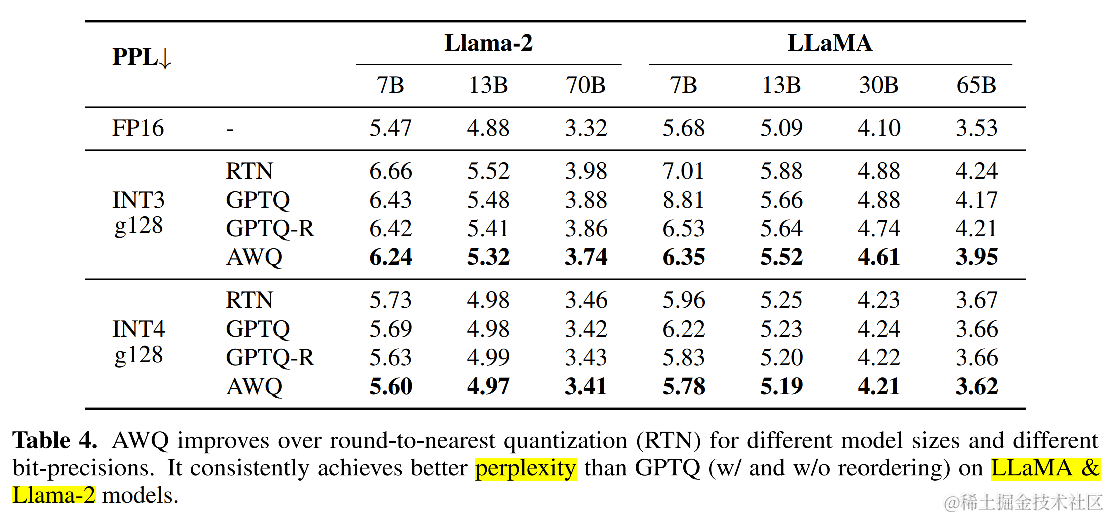
更重要的是,由于其良好的泛化性,AWQ 在经过指令精调的模型(如 Vicuna)和多模态模型(如 OpenFlamingo)上也表现出色。

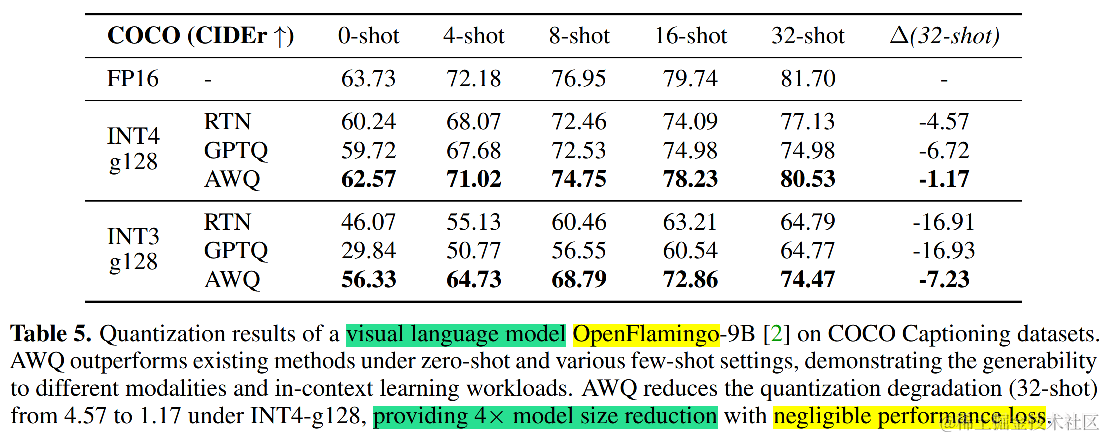
AWQ 生态与实践:AutoAWQ 入门
AWQ 的出色表现吸引了业界的广泛关注,目前已经有众多开源项目和工具提供了对 AWQ 的支持:
- 官方实现: MIT Han Lab 的 llm-awq
- 社区工具:
- AutoAWQ: 一个易于使用的 AWQ 量化库,已被 Hugging Face Transformers 集成。
- vLLM: 高性能 LLM 推理和服务框架。
- Hugging Face TGI: Hugging Face 的文本生成推理服务。
- LMDeploy: 上海人工智能实验室开发的 LLM 部署工具链。
- NVIDIA TensorRT-LLM: 英伟达官方的 LLM 推理优化库。
- FastChat: 用于训练、服务和评估 LLM 的平台。
我们以 AutoAWQ 为例,看看如何在实践中使用 AWQ。
理解 Compute-bound vs. Memory-bound
在讨论 AWQ 加速效果前,需要了解一个概念:推理瓶颈。
- Memory-bound (内存带宽受限): 当模型较小或 Batch Size 很小时,推理的主要时间花费在从 GPU 显存读取权重到计算核心。此时,权重越小,读取越快,推理速度越快。AWQ (W4A16) 通过将权重压缩 3-4 倍,能有效缓解内存带宽瓶颈,带来显著加速。
- Compute-bound (计算受限): 当模型很大或 Batch Size 很大时,推理的主要时间花费在矩阵乘法等计算本身。AWQ 虽然权重是 INT4/3,但实际计算通常在 FP16 下进行(需要在线反量化
INT4 -> FP16)。这个反量化操作会带来额外的计算开销。在计算受限的情况下,这个开销可能会抵消掉权重读取加快带来的好处,甚至导致速度变慢。
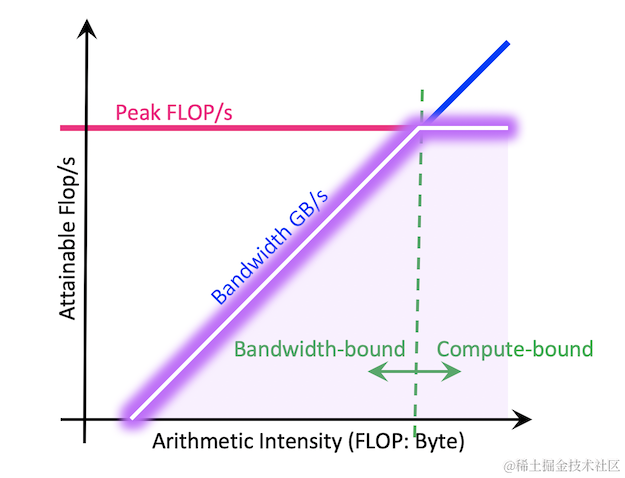
因此,AWQ 主要在内存带宽受限的场景下(例如,小批量、本地部署、边缘设备)提供推理加速。
AutoAWQ 使用示例 (集成于 Transformers)
AutoAWQ 使得 AWQ 量化变得非常简单。
-
使用 AutoAWQ 量化 LLM:
from awq import AutoAWQForCausalLM from transformers import AutoTokenizer model_path = "facebook/opt-125m" # 你想量化的模型 quant_path = "opt-125m-awq" # 量化后模型的保存路径 # 定义量化配置 quant_config = { "zero_point": True, # 是否使用零点 "q_group_size": 128, # 权重量化的组大小 "w_bit": 4, # 权重比特数 (4-bit) "version": "GEMM" # AWQ kernel 版本 (GEMM/GEMV) } # 加载模型和 Tokenizer model = AutoAWQForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True) # 使用 low_cpu_mem_usage 减少内存占用 tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) # 执行量化 (需要少量校准数据,这里省略了数据加载步骤,AutoAWQ 默认会使用 wiktext 或 c4) print("Starting quantization...") model.quantize(tokenizer, quant_config=quant_config) print("Quantization complete.") # (注意:实际量化需要一些时间,具体取决于模型大小和硬件) -
修改配置以兼容 Transformers:
from transformers import AwqConfig # 创建符合 Transformers 格式的 AwqConfig quantization_config = AwqConfig( bits=quant_config["w_bit"], group_size=quant_config["q_group_size"], zero_point=quant_config["zero_point"], version=quant_config["version"].lower(), ) # 将量化配置附加到模型配置中 model.model.config.quantization_config = quantization_config # 保存量化后的模型权重和 Tokenizer print(f"Saving quantized model to {quant_path}...") model.save_quantized(quant_path) tokenizer.save_pretrained(quant_path) print("Model saved.") -
加载并使用量化后的模型:
from transformers import AutoTokenizer, AutoModelForCausalLM import torch quant_model_dir = "opt-125m-awq" # 上一步保存的路径 device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Loading quantized model from {quant_model_dir}...") # Transformers 会自动识别 AwqConfig 并加载相应的 INT4 模型 tokenizer = AutoTokenizer.from_pretrained(quant_model_dir) # 使用 device_map="auto" 自动分配设备 model = AutoModelForCausalLM.from_pretrained(quant_model_dir, device_map="auto") print("Model loaded.") # 进行推理 text = "Hello my name is" inputs = tokenizer(text, return_tensors="pt").to(device) print("Generating text...") # 注意:max_new_tokens 控制生成长度 out = model.generate(**inputs, max_new_tokens=20) generated_text = tokenizer.decode(out[0], skip_special_tokens=True) print("Generated text:", generated_text)(请注意:运行上述代码需要安装
autoawq库,并确保你的环境中有合适的 CUDA 版本。对于加载模型,Transformers >= 4.35 版本内置了对 AutoAWQ 的支持。)
SmoothQuant 和 AWQ
相同之处
- 都是训练后量化 (PTQ) 方法: 两者都属于 PTQ 范畴,只需要少量的校准数据来分析模型特性,不需要重新训练模型,计算成本相对较低。
- 都利用了激活信息: 两者都认识到仅仅看权重本身不足以做出最优的量化决策,都需要在校准阶段分析激活值的分布或尺度。
- 都使用了逐通道缩放 (Per-Channel Scaling): 两者都引入了与输入通道数维度相同的缩放因子
s,并对权重和激活应用了数学上等价的变换,形式上都是Y = WX = (W * S) * (S^-1 * X)(这里S是diag(s)对角矩阵)。 - 目标都是提升低比特量化下的模型精度: 两者都是为了解决低比特量化(尤其是大模型)时精度下降严重的问题。
- 都考虑了硬件效率: 两者都试图设计出能够在现代硬件(如 GPU)上高效运行的量化方案。
关键区别
| 特性 | SmoothQuant | AWQ (Activation-aware Weight Quantization) |
|---|---|---|
| 主要目标 | 实现高精度、硬件友好的 W8A8 量化 | 实现极低比特(如 W4A16, W3A16)的仅权重量化,保持高精度和泛化性 |
| 解决的核心问题 | 激活异常值 (Activation Outliers) 导致激活难以量化到 INT8 | 少数关键权重(由激活识别) 对模型性能影响巨大,在极低比特下需要特殊保护 |
| 量化对象 | 权重 (W) 和 激活 (A) 都量化到 INT8 | 主要量化 权重 (W) 到 INT4/INT3,激活 (A) 通常保持 FP16 |
| 缩放机制的目的 | "平滑"激活,将量化难度从激活转移到更容易量化的权重上 | 通过放大关键权重的数值来减小其相对量化误差,保护它们不受低比特量化影响 |
缩放因子 s 的计算 |
平衡权重和激活的量化难度:`s_j ∝ max( | X_j |
| 硬件效益侧重 | 利用 INT8 计算单元 加速矩阵乘法 (GEMM) | 大幅减少模型内存占用和内存带宽需求(权重减小 3-4 倍) |
| 主要精度挑战 | 如何在平滑激活的同时,不过度增加权重的量化难度 | 如何在保护关键权重的同时,不过度放大非关键权重的误差 |
| 最终推理格式 | W8A8 (INT8 权重, INT8 激活/计算) | W4A16 / W3A16 (INT4/3 权重, FP16 激活/计算) |
简单来说:
- SmoothQuant 想让激活变得“乖巧”,方便和权重一起打包成 INT8。 它的核心是“难度转移”。
- AWQ 认为有些权重是“VIP”,需要特殊照顾,通过放大它们的值来抵抗低比特量化的“伤害”,而激活保持原样 (FP16)。 它的核心是“重点保护”。
目前哪个更主流?为什么?
目前来看,AWQ(及其代表的 W4A16/W3A16 这类仅权重量化方案)在社区和实际应用中似乎更为主流和受关注,尤其是在大型语言模型的部署场景下。
主要原因如下:
- 内存是首要瓶颈: 对于非常大的 LLM(几十B到几百B参数),显存容量 (VRAM) 往往是部署的最大障碍。将权重从 FP16 量化到 INT4/INT3 可以直接将模型大小减少 75%-80%!这种数量级的减少使得原本无法在单张甚至多张消费级/专业级 GPU 上运行的模型成为了可能。相比之下,SmoothQuant (W8A8) 只能减少 50% 的内存占用,吸引力相对较小。
- W4A16 精度足够好: 令人惊讶的是,像 AWQ 和 GPTQ 这样的方法证明了,即使只用 4 比特量化权重,只要方法得当(比如保护关键权重),LLM 仍然可以在很多任务上保持相当高的精度,损失在可接受范围内。这使得 W4A16 成为了一个性价比极高的选择。
- 推理速度瓶颈的变化: 在很多实际的 LLM 推理场景(尤其是小批量或单用户交互),内存带宽 (Memory Bandwidth) 往往是比计算本身更大的瓶颈(Memory-bound)。读取更小的 INT4/INT3 权重可以显著降低对内存带宽的需求,从而带来实际的推理加速,即使计算本身仍然是 FP16。SmoothQuant 虽然利用了 INT8 计算,但在内存带宽受限场景下,其加速效果可能不如 W4A16 带来的内存读取优势明显。
- 生态系统和工具链的成熟: 围绕 W4A16 的量化和推理加速方案(如 AutoAWQ、vLLM 对 AWQ 的支持、TensorRT-LLM 对 W4A16 的优化、bitsandbytes 等)发展迅速,提供了易于使用的工具和高效的推理内核,降低了使用门槛。
但这并不意味着 SmoothQuant 没有价值:
- INT8 端到端加速: 在计算密集型 (Compute-bound) 场景,或者在拥有高效 INT8 计算单元的特定硬件(如一些服务器级 GPU 或专用 AI 加速器)上,SmoothQuant 的 W8A8 方案可能因为利用了更快的 INT8 计算而获得更高的吞吐量。
- 精度要求极高: 在某些对精度极其敏感的应用中,W8A8 的精度损失通常比 W4A16 更小,可能是更好的选择。
- 工业界部署: 像 NVIDIA TensorRT-LLM 等工业级推理引擎也集成了 SmoothQuant,表明它在追求极致性能优化时仍有一席之地。
总结
AWQ (Activation-aware Weight Quantization) 是一种创新且高效的训练后权重量化技术,它抓住了问题的关键:权重的重要性由激活决定。通过巧妙的激活感知缩放机制,AWQ 能够在不引入硬件不友好的混合精度的前提下,有效保护对模型性能至关重要的权重通道,从而在 INT4/INT3 等低比特场景下,实现与复杂方法(如 GPTQ)相媲美甚至更高的精度,同时保持了 LLM 优异的泛化能力。
由于其简洁、高效、硬件友好的特点,AWQ 已经成为低比特 LLM 量化领域一个重要的里程碑,并得到了社区和业界的广泛支持。理解 AWQ 的原理和优势,无疑会让你在 LLM 优化和部署方面更具竞争力。
希望这篇深入浅出的解析能帮助你掌握 AWQ 的精髓!如果你觉得这篇文章对你有帮助,请不要吝啬你的点赞、收藏和关注哦!我们下次再见!
参考材料:
大模型量化技术原理-AWQ、AutoAWQ近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破 - 掘金

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)