[论文阅读] 人工智能 | 代码生成模型新范式:将推理深度作为可控资源管理
本文解读了代码生成模型领域的最新研究——将推理深度作为可控资源进行全生命周期管理。研究指出,当前LLMs在代码生成中面临正确性、延迟和成本的三角矛盾,而通过动态调度"快速思考"与"慢速思考"模式,可在数据生成、基准测试和部署阶段实现最优权衡。该研究为构建更高效、安全的代码生成系统提供了全新思路。
代码生成模型新范式:将推理深度作为可控资源管理
摘要
本文提出在代码生成模型设计中,应将推理深度视为可控资源,明确管理“快速思考”(直接回答)与“慢速思考”(链式推理)的权衡,通过优化模型生命周期(包括合成数据生成、基准测试和实际部署)中的推理预算,实现准确性、延迟和成本的更佳平衡,旨在让编码代理在必要时深入思考、可能时快速行动。
研究背景:代码生成模型的"速度-质量-成本"三角困境
想象你在使用AI助手生成代码时,它要么快速给出答案但偶尔出错,要么经过冗长思考后输出精准代码但等待时间漫长——这正是当前大型语言模型(LLMs)在代码生成领域的真实写照。尽管LLMs在HumanEval和MBPP等基准测试中已超越人类编写的代码基线,但它们面临着一个核心矛盾:正确性、延迟和token成本的三方权衡。
比如,当模型使用"链式思维"(CoT)进行深度推理时,代码准确率会提升,但生成过程需要更多token,不仅增加计算成本,还会导致响应延迟。反之,直接生成答案(“快速思考”)虽然高效,却可能在复杂问题上出错。这种矛盾就像开车时"速度与安全"的权衡——开得快省油但风险高,开得慢安全但耗时。而传统模型设计往往将推理深度视为提示工程的副产品,缺乏系统性管理,如同任由汽车在所有路况下以固定速度行驶。
论文信息
Li, Z., & Wang, S. (2025). Reasoning as a Resource: Optimizing Fast and Slow Thinking in Code Generation Models. arXiv preprint arXiv:2506.09396v1.
思维导图
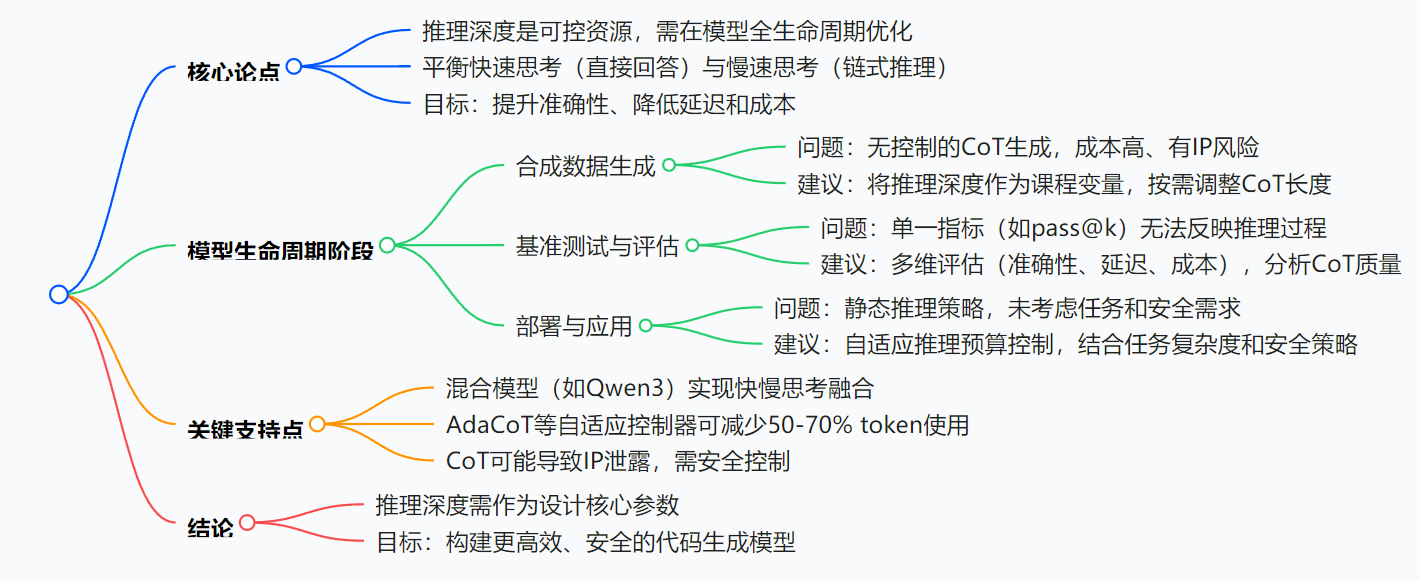
详细总结
一、引言:代码生成模型的推理优化新视角
- LLM的代码生成表现与挑战:大型语言模型在HumanEval和MBPP等基准上已超越人类编写基线,但面临正确性、延迟和token成本的三方矛盾。
- 推理深度的定义:指模型在生成解决方案前进行的逐步问题解决过程,以链式思维(CoT)痕迹为主要实现机制和量化指标。
- 混合模型的趋势:如Qwen3等模型显式区分“快速”和“慢速”模式,标志着推理深度成为可配置参数。
二、合成代码数据生成:优化推理深度作为课程变量
- 合成数据的必要性:公开源代码有限且不均衡,StarCoder等模型超半数token来自机器生成。
- 当前方法的问题:
- 推理痕迹嵌入导致token预算膨胀,AdaCoT等控制器可减少50-70% token使用仍保持准确性。
- 长推理痕迹带来安全和IP风险,多智能体系统中可能泄露敏感信息。
- 优化建议:按任务需求调度推理深度,简单任务用短痕迹,复杂或安全关键任务用长痕迹。
三、推理时测试与基准测试:多维评估框架
- 当前评估的不足:主流基准依赖pass@k等单一指标,掩盖了推理过程的成本和效率差异。
- 多维评估建议:
- 记录CoT痕迹,引入推理质量与解决方案正确性的诊断矩阵。
- 报告延迟、token计数等指标,如AdaCoT可实现70%的token节省。
四、部署与下游应用:自适应推理控制
- 生产环境的需求:企业应用中,每个token都带来GPU和金钱成本,需动态调整推理预算
- 自适应策略:
- 按任务复杂度调整:复杂算法用深度推理, boilerplate代码用快速响应。
- 安全考虑:CoT可能泄露 proprietary逻辑,需结合prompt过滤、代码水印等防御措施。
五、结论:推理作为核心设计参数
全文主张将推理深度作为代码LLM的核心设计参数,通过在数据生成、评估和部署阶段的主动管理,实现更高效、可靠的代码生成模型。
关键问题
- 核心论点问题:本文的核心主张是什么?
- 答案:本文主张将推理深度视为代码生成模型的可控资源,在模型生命周期(数据生成、基准测试、部署)中优化推理预算,以平衡准确性、延迟和成本。
- 数据生成问题:在合成数据生成阶段,如何优化推理深度?
- 答案:将推理深度作为课程变量,根据任务类型调度CoT长度,简单任务用短痕迹,复杂或安全关键任务用长痕迹,以平衡监督丰富性和token经济性。
- 基准测试问题:当前代码LLM评估框架的主要不足是什么?
- 答案:依赖pass@k等单一正确性指标,未报告延迟、token成本等多维性能,也不分析推理过程本身,导致无法捕捉模型在效率和鲁棒性上的差异。
创新点:从"被动接受"到"主动调度"的推理范式革新
这篇论文的核心突破在于提出:将推理深度视为可精确调控的资源,而非模型的默认行为。其创新亮点体现在三个方面:
-
全生命周期管理:不同于仅在推理时调整策略,论文主张从数据生成、基准测试到实际部署的全流程中控制推理深度。这就像工厂生产汽车时,不仅在出厂测试中优化性能,还在零部件采购、组装流程中就预设不同场景的性能参数。
-
快慢思考的互补机制:借鉴Qwen3等混合模型的思路,将"快速直接回答"与"慢速链式推理"视为可动态切换的模式。例如,生成简单的循环代码时用"快速模式",而处理加密算法时自动切换到"慢速模式"进行深度推理。
-
多维优化目标:突破传统仅关注准确率的评估方式,将延迟、成本和安全性纳入核心指标。就像评价一台电脑不能只看CPU速度,还要考虑功耗、散热和价格。
研究方法和思路:三阶段推理资源调度框架
1. 合成数据生成:按需定制推理深度的"教学材料"
传统数据生成往往盲目追求最长CoT痕迹,如同给小学生讲解微积分时堆砌所有推导步骤,既浪费资源又难以消化。论文提出将推理深度作为"课程变量":
- 简单任务(如函数补全)生成短CoT,类似给小学生讲解加减乘除时用简单例题;
- 复杂任务(如算法设计)生成详细CoT,类似给高中生讲解微积分时分步推导。
这种方法可使数据合成成本降低50-70%,同时避免长痕迹泄露专利算法的风险。
2. 基准测试:从"单一分数"到"全景体检"
现有评估如pass@k指标,就像只看学生考试分数而不关心解题过程——两个得分相同的学生,可能一个是真正理解,另一个是蒙对的。论文建议:
- 新增延迟、token消耗等维度,如同体检时不仅量体温,还要测血压、心率;
- 引入"推理质量-解决方案正确性"矩阵(如下表),区分"正确推理正确解"和"错误推理正确解"等情况,避免模型靠记忆而非理解通过测试。
| 推理质量 | 解决方案正确性 | |
|---|---|---|
| 正确解 | 错误解 | |
| 正确CoT | 理想情况(真理解) | 执行错误(如语法错) |
| 错误CoT | 偶然正确(需警惕) | 全面失败 |
3. 部署应用:自适应推理的"智能调度员"
在企业场景中,代码生成可能用于IDE补全(需快速响应)或安全审计(需深度推理),传统"一刀切"策略如同用同一把钥匙开所有锁。论文提出:
- 基于任务类型动态分配推理预算:生成网页模板时用"快速模式",分析漏洞时自动启用"深度模式";
- 集成安全策略:敏感场景中缩短CoT以防止IP泄露,类似银行系统在处理机密数据时减少中间日志记录。
主要贡献:给代码生成领域带来的三大实在价值
-
效率革命:通过自适应推理控制,在保持准确率的前提下减少50-70%的token消耗,相当于用一半的计算资源完成相同任务,大幅降低企业部署成本。
-
评估升级:多维基准测试框架让研究者能区分"真正理解问题的模型"和"靠记忆蒙对的模型",推动模型向更可靠的方向进化。就像从"应试教育"转向"素质教育",关注能力而非分数。
-
安全增强:将推理深度与安全策略绑定,避免CoT痕迹成为攻击面。例如,在多智能体系统中自动过滤敏感推理步骤,防止专利算法被窃取。
总结:让代码生成模型"该快则快,该深则深"
这篇论文颠覆了代码生成模型的设计逻辑:推理深度不应是模型的"默认配置",而应是可按需调节的"资源滑块"。通过在数据生成阶段定制推理复杂度、评估阶段引入多维指标、部署阶段结合任务与安全动态调度,最终实现模型"该快则快(如简单代码补全),该深则深(如加密算法设计)"的智能行为。这种范式转变有望推动代码生成技术在效率、可靠性和安全性上的全面提升。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)