python简介及开发环境配置总结
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。Python 由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年。像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。官方宣布,2020 年 1 月 1 日, 停止 Python 2 的更新。Python 2
参考:Python3 教程 | 菜鸟教程 (runoob.com)
本系列文章主要作为自己的笔记使用,以菜鸟的Python3为参考。
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python 由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年。像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。
官方宣布,2020 年 1 月 1 日, 停止 Python 2 的更新。Python 2.7 被确定为最后一个 Python 2.x 版本。
Python 的 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。为了不带入过多的累赘,Python 3.0 在设计的时候没有考虑向下兼容。
执行Python程序
对于大多数程序语言,第一个入门编程代码便是 "Hello World!",Python 3.0+ 版本已经把 print 作为一个内置函数,输出 "Hello World!" 代码如下:
实例(Python 3.0+)
#!/usr/bin/python3 print("Hello, World!")关于脚本第一行的 #!/usr/bin/python 的解释,相信很多不熟悉 Linux 系统的同学需要普及这个知识,脚本语言的第一行,只对 Linux/Unix 用户适用,用来指定本脚本用什么解释器来执行。
有这句的,加上执行权限后,可以直接用 ./ 执行,不然会出错,因为找不到 python 解释器。
#!/usr/bin/python 是告诉操作系统执行这个脚本的时候,调用 /usr/bin 下的 python 解释器。
#!/usr/bin/env python 这种用法是为了防止操作系统用户没有将 python 装在默认的 /usr/bin 路径里。当系统看到这一行的时候,首先会到 env 设置里查找 python 的安装路径,再调用对应路径下的解释器程序完成操作。
#!/usr/bin/python 相当于写死了 python 路径。
#!/usr/bin/env python 会去环境设置寻找 python 目录,可以增强代码的可移植性,推荐这种写法。
分成两种情况:
(1)如果调用 python 脚本时,使用:
$ python3 hello.py#!/usr/bin/python 被忽略,等同于注释
(2)如果调用python脚本时,使用:
./script.py#!/usr/bin/python 指定解释器的路径
PS:shell 脚本中在第一行也有类似的声明。
Python 发展历史
Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。
Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。
像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
现在 Python 是由一个核心开发团队在维护,Guido van Rossum 仍然占据着至关重要的作用,指导其进展。
Python 2.0 于 2000 年 10 月 16 日发布,增加了实现完整的垃圾回收,并且支持 Unicode。
Python 3.0 于 2008 年 12 月 3 日发布,此版不完全兼容之前的 Python 源代码。不过,很多新特性后来也被移植到旧的Python 2.6/2.7版本。
Python 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。
Python 2.7 被确定为最后一个 Python 2.x 版本,它除了支持 Python 2.x 语法外,还支持部分 Python 3.1 语法。
为什么说python是一个脚本语言?C/C++不可以做脚本语言吗?
关于 “脚本语言” 的定义,不同语境下可能有细微差异,但通常可从执行方式、应用场景、语言特性三个维度区分。以下是 Python 被视为脚本语言而 C/C++ 不是的核心原因:
一、执行方式:解释型 vs 编译型
Python(脚本语言的典型特征)
解释执行: Python 代码无需提前编译为二进制文件,而是由解释器(如 CPython)逐行读取并执行。
例如:保存为
.py的文件可直接通过命令python script.py运行,修改代码后无需重新编译即可生效。动态类型: 变量类型在运行时确定,无需显式声明(如
x = 10和x = "hello"可直接赋值),降低了编写门槛。C/C++(典型的编译型语言)
编译执行: C/C++ 代码必须通过编译器(如 GCC、Clang)编译为机器码(
.exe、.o等二进制文件)才能运行。例如:C 代码
hello.c需通过gcc hello.c -o hello编译生成可执行文件hello后才能运行,修改代码后必须重新编译。静态类型: 变量类型必须提前声明(如
int x = 10;),类型错误会在编译阶段报错,需严格遵循语法规则。二、设计目标:快速开发 vs 性能优先
Python(脚本语言的设计初衷)
强调效率和易用性:
- 语法简洁(如用缩进代替大括号),代码量通常比 C/C++ 少 50% 以上。
- 内置丰富的标准库(如文件操作、网络请求、数据处理),无需从零开始编写底层代码。
适合快速迭代: 脚本语言常用于一次性任务、临时工具、自动化流程(如数据清洗、爬虫、测试脚本),允许开发者快速编写、调试、运行代码。
C/C++(系统级语言的定位)
强调性能和底层控制:
- 直接操作内存和硬件,执行效率极高(C++ 的速度通常是 Python 的 10-100 倍)。
- 需要手动管理内存(如
malloc/free、指针),允许编写高度优化的代码。适合复杂系统开发: 编译型语言常用于操作系统内核、大型软件、高性能服务、游戏引擎等对性能要求苛刻的场景,而非快速脚本任务。
三、应用场景:胶水工具 vs 基建工程
Python 的脚本语言典型场景
自动化脚本: 批量处理文件、部署测试环境、监控系统状态(如用 Python 脚本每天自动生成报表)。
胶水代码: 连接不同语言或组件(如用 Python 调用 C/C++ 编译的库,或调用 Shell 命令)。
快速验证: 科研计算、算法原型设计(如用 Python 编写机器学习模型,验证逻辑后再用 C++ 优化)。
C/C++ 难以作为脚本语言的场景
不适合临时任务: 编写一个简单的 “文件重命名” 工具,Python 可能只需 10 行代码,而 C++ 需要包含头文件、处理参数、编写文件操作逻辑,代码量多且需编译。
动态性不足: 无法在运行时修改代码逻辑(如通过字符串动态执行表达式),而 Python 的
eval()、exec()等功能支持动态编程。四、例外情况:脚本语言的边界并非绝对
C/C++ 的 “脚本化” 尝试
部分嵌入式系统会用 C 语言编写类似脚本的 “配置文件解析器”,但本质仍是编译型代码,需提前编译到程序中。
例如:游戏引擎用 C++ 编写,但可能嵌入 Lua/Python 作为脚本语言(如 Unity 用 C#+Boo 脚本)。
Python 的 “非脚本” 用途
Python 也可用于开发大型应用(如 Web 框架 Django、数据分析库 Pandas),但此时它更接近 “通用编程语言”,而非单纯的脚本。
总结:一句话区分
脚本语言(如 Python):是 “可以直接运行的指令集”,适合快速解决具体问题,像 “螺丝刀” 一样即取即用。
编译型语言(如 C/C++):是 “需要提前锻造的工具”,适合构建复杂系统,像 “钢铁” 一样需要精心冶炼才能发挥威力。
两者并无优劣之分,只是设计目标和应用场景不同。Python 的脚本语言特性使其成为 “自动化神器”,而 C/C++ 的编译型特性使其成为 “性能基石”。
Python特点
1.易于学习:Python 有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
2.易于阅读:Python 代码定义的更清晰。
3.易于维护:Python的 成功在于它的源代码是相当容易维护的。
4.一个广泛的标准库:Python 的最大的优势之一是丰富的库,跨平台的,在 UNIX、Windows 和 Mac 兼容很好。
5.互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片段。
6.可移植:基于其开放源代码的特性,Python 已经被移植(也就是使其工作)到许多平台。
7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用 C 或 C++ 完成那部分程序,然后从你的 Python 程序中调用。
8.数据库:Python 提供所有主要的商业数据库的接口。
9.GUI 编程:Python 支持 GUI 可以创建和移植到许多系统调用。
10.可嵌入: 你可以将 Python 嵌入到 C/C++ 程序,让你的程序的用户获得"脚本化"的能力。
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
Python 应用
- Youtube - 视频社交网站
- Reddit - 社交分享网站
- Dropbox - 文件分享服务
- 豆瓣网 - 图书、唱片、电影等文化产品的资料数据库网站
- 知乎 - 一个问答网站
- 果壳 - 一个泛科技主题网站
- Bottle - Python微Web框架
- EVE - 网络游戏EVE大量使用Python进行开发
- Blender - 使用Python作为建模工具与GUI语言的开源3D绘图软件
- Inkscape - 一个开源的SVG矢量图形编辑器。
- ...
python常见应用比如数据处理、网络爬虫、人工智能等等
数据处理
#!/usr/bin/env python # -- coding: utf-8 -- import pandas as pd def sort_excel_file(input_file, output_file, sort_column, ascending=True): """ 对 Excel 文件中的数据按指定列进行排序,并保存为新文件 参数: input_file (str): 输入 Excel 文件路径 output_file (str): 输出 Excel 文件路径 sort_column (str): 排序依据的列名 ascending (bool): 是否升序排列,默认为 True """ try: # 读取 Excel 文件 df = pd.read_excel(input_file) # 检查排序列是否存在 if sort_column not in df.columns: print(f"错误: 列 '{sort_column}' 不存在于文件中。") return False # 按指定列排序 sorted_df = df.sort_values(by=sort_column, ascending=ascending) # 将排序后的数据保存到新的 Excel 文件 sorted_df.to_excel(output_file, index=False) print(f"成功排序并保存到 {output_file}") return True except FileNotFoundError: print(f"错误: 文件 '{input_file}' 不存在。") return False except Exception as e: print(f"发生未知错误: {e}") return False # 使用示例 if __name__ == "__main__": # 输入和输出文件路径 input_file = r"C:\Users\admin\Desktop\data.xlsx" # 请替换为你的 Excel 文件路径 output_file = r"C:\Users\admin\Desktop\sorted_data.xlsx" # 按指定列排序(请替换为你要排序的列名) sort_excel_file(input_file, output_file, sort_column="编号", ascending=True)网络爬虫
import requests from bs4 import BeautifulSoup import csv from time import sleep import random # 设置请求头,模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } def get_poems(url): """爬取古诗文网主页的古诗""" try: response = requests.get(url, headers=headers) response.encoding = 'utf-8' # 设置编码 soup = BeautifulSoup(response.text, 'html.parser') poems = [] # 查找古诗条目 for item in soup.find_all('div', class_='left'): for poem_div in item.find_all('div', class_='sons'): # 提取标题 title_tag = poem_div.find('b') title = title_tag.text.strip() if title_tag else "无标题" # 提取作者和朝代 source_div = poem_div.find('p', class_='source') if source_div: author = source_div.find_all('a')[0].text.strip() dynasty = source_div.find_all('a')[1].text.strip() else: author = "未知" dynasty = "未知" # 提取内容 content_div = poem_div.find('div', class_='contson') content = content_div.text.strip().replace('\n', ' ') if content_div else "无内容" poems.append({ '标题': title, '作者': author, '朝代': dynasty, '内容': content }) return poems except Exception as e: print(f"爬取失败: {e}") return [] def save_to_csv(poems, filename='poems.csv'): """将古诗保存到CSV文件""" with open(filename, 'w', newline='', encoding='utf-8-sig') as f: writer = csv.DictWriter(f, fieldnames=['标题', '作者', '朝代', '内容']) writer.writeheader() writer.writerows(poems) print(f"数据已保存到 {filename}") def main(): base_url = 'https://www.gushiwen.cn/' # 爬取首页古诗 print("开始爬取古诗文网...") poems = get_poems(base_url) if poems: print(f"共爬取到 {len(poems)} 首古诗") save_to_csv(poems) # 打印前3首作为示例 print("\n示例古诗:") for i, poem in enumerate(poems[:3], 1): print(f"\n{i}. {poem['标题']}") print(f"作者: {poem['作者']} ({poem['朝代']})") print("内容:") print(poem['内容']) else: print("未爬取到古诗数据") if __name__ == '__main__': main()人工智能-机器学习:加州房价预测简单示例
# 导入必要的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score # 1. 加载加州房价数据集 housing = fetch_california_housing() X = housing.data # 特征 y = housing.target # 目标变量(房价) # 2. 数据探索(可选) print("数据基本信息:") print(housing.DESCR) # 打印数据集描述 # 转换为DataFrame便于查看 housing_df = pd.DataFrame(X, columns=housing.feature_names) housing_df['MedHouseVal'] = y print("\n数据集行数和列数:", housing_df.shape) print("\n数据前几行信息:") print(housing_df.head()) # 3. 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42) # 4. 特征标准化 scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # 5. 模型训练(使用随机森林回归器) model = RandomForestRegressor(n_estimators=100, random_state=42) model.fit(X_train_scaled, y_train) # 6. 模型预测 y_pred = model.predict(X_test_scaled) # 7. 模型评估 mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) r2 = r2_score(y_test, y_pred) print("\n模型评估结果:") print(f"均方误差 (MSE): {mse:.4f}") print(f"均方根误差 (RMSE): {rmse:.4f}") print(f"决定系数 (R²): {r2:.4f}") # 8. 特征重要性可视化 importances = model.feature_importances_ features = housing.feature_names plt.figure(figsize=(10, 6)) plt.bar(features, importances) plt.title('特征重要性') plt.xlabel('特征') plt.ylabel('重要性') plt.xticks(rotation=45) plt.tight_layout() plt.show() # 9. 预测值与真实值对比可视化 plt.figure(figsize=(10, 6)) plt.scatter(y_test, y_pred, alpha=0.6) plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--') plt.title('预测值 vs 真实值') plt.xlabel('真实房价') plt.ylabel('预测房价') plt.show()更多待补充。
Python环境搭建
接下来我们将向大家介绍如何在本地搭建Python开发环境。
Python可应用于多平台包括 Win、Linux 和 Mac OS X等等。
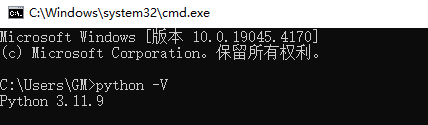
你可以通过终端窗口输入 "python" 命令来查看本地是否已经安装Python以及Python的安装版本。
我们可以在命令窗口(Windows 使用 win+R 调出 cmd 运行框)使用以下命令查看我们使用的 Python 版本:
python -V 或 python --version比如:
Python下载
Python最新源码,二进制文档,新闻资讯等可以在Python的官网查看到:
Python官网:Welcome to Python.org
你可以在以下链接中下载 Python 的文档,你可以下载 HTML、PDF 和 PostScript 等格式的文档。
Python文档下载地址:Our Documentation | Python.org
Python安装
Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。
您需要下载适用于您使用平台的二进制代码,然后安装Python。
如果您平台的二进制代码是不可用的,你需要使用C编译器手动编译源代码。
编译的源代码,功能上有更多的选择性, 为python安装提供了更多的灵活性。
以下是各个平台安装包的下载地址:
以下为不同平台上安装 Python 的方法:
Unix & Linux 平台安装 Python:
以下为在 Unix & Linux 平台上安装 Python 的简单步骤:
打开 WEB 浏览器访问Python Source Releases | Python.org
选择适用 于Unix/Linux 的源码压缩包。
下载及解压压缩包。
如果你需要自定义一些选项修改Modules/Setup
执行 ./configure 脚本
make
make install
执行以上操作后,Python 会安装在 /usr/local/bin 目录中,Python 库安装在 /usr/local/lib/pythonXX,XX 为你使用的 Python 的版本号。
Window 平台安装 Python:
以下为在 Window 平台上安装 Python 的简单步骤:
打开 WEB 浏览器访问Python Releases for Windows | Python.org
在下载列表中选择Window平台安装包,包格式为:python-XYZ.msi 文件 , XYZ 为你要安装的版本号。
下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。


python安装目录简介
默认安装路径如下:
C:\Users\GM\AppData\Local\Programs\Python\Python311
这里的GM是windows登录账号名。
目录如下;
参考:
Python教程:Python安装目录说明_新建的python项目中的include lib scripts pyvenv.cfg都是有什么作用-CSDN博客
在 python 开发中,深入了解 Python 的安装目录结构对于开发者来说是至关重要的。本文以Python 3.11.9为例,详细介绍 Python 的安装目录结构、各个子目录和文件的作用。
Python311/ │ ├── Lib/ # Python 标准库 ├── DLLs/ # Python 解释器所需的 DLL 文件 ├── include/ # 头文件和静态库文件 ├── Scripts/ # 存放 pip 等脚本文件 ├── tcl/ # Tcl/Tk 相关文件 ├── Tools/ # 辅助工具和脚本 ├── python.exe # Python 解释器可执行文件 ├── pyvenv.cfg # Python 虚拟环境配置文件 ├── README.txt # Python 安装说明文件 └── ... # 其他辅助文件和目录Lib/
Lib/ 目录是 Python 3.8.6 的标准库目录,包含了大量的内置模块和包,提供了丰富的功能和工具供开发者使用。在这里可以找到各种用于开发的模块和包。DLLs/
DLLs/ 目录包含了 Python 解释器运行所需的 DLL 文件,这些动态链接库通常包括与操作系统交互和底层功能相关的库。它们是 Python 解释器正常运行所必需的组件。include/
include/ 目录包含了头文件和静态库文件,这些文件通常用于编译和链接 C/C++ 扩展模块。如果您需要扩展 Python 的功能,您将会在这里找到所需的文件。Scripts/
Scripts/ 目录存放了一些 Python 相关的脚本文件,例如 pip 工具的可执行文件就会被安装到这个目录下。这些脚本文件是与 Python 开发和环境配置密切相关的工具。tcl/
tcl/ 目录通常包含了与 Tcl/Tk 相关的文件,这些文件用于支持 Python 的 Tkinter 等 GUI 库功能。Tcl/Tk 是 Python 中常用的图形用户界面库,这些文件提供了 GUI 开发所需的支持。Tools/
Tools/ 目录包含了一些辅助工具和脚本,这些工具和脚本有助于配置、构建和调试 Python 的运行环境。在这里可以找到一些实用的工具,帮助您更有效地管理 Python 开发过程。python.exe(执行python命令启动时就是执行的这个exe程序)
python.exe 是 Python 3.8.6 解释器的可执行文件,通过运行这个文件可以启动 Python 解释器并执行 Python 脚本。这是您与 Python 交互的入口点,让您能够运行 Python 代码并执行各种任务。pyvenv.cfg
pyvenv.cfg 是 Python 虚拟环境的配置文件,其中包含了虚拟环境的配置信息,如解释器路径、包存储路径等。虚拟环境可以帮助您隔离项目之间的依赖关系,使得项目开发更加独立和可控。README.txt
README.txt 是 Python 的安装说明文件,提供了关于安装 Python 的一些基本信息和注意事项。通过阅读此文件,您可以快速了解如何正确地安装和配置 Python 3.8.6。其他文件和目录
除了上述主要目录和文件外,Python 3.8.6 的安装目录还可能包含其他辅助文件和目录,如示例代码、文档、配置文件等。这些文件和目录对于帮助您更好地理解 Python 的安装和运行机制也非常重要。补充:
Windows系统搭建好Python的环境后,进入Python的安装目录,大家会发现目录中有python.exe和pythonw.exe两个程序。
它们到底有什么区别和联系呢?
概括说明一下:
python.exe在运行程序的时候,会弹出一个黑色的控制台窗口(也叫命令行窗口、DOS/CMD窗口);
pythonw.exe是无窗口的Python可执行程序,意思是在运行程序的时候,没有窗口,代码在后台执行。

环境变量配置
程序和可执行文件可以在许多目录,而这些路径很可能不在操作系统提供可执行文件的搜索路径中。
path(路径)存储在环境变量中,这是由操作系统维护的一个命名的字符串。这些变量包含可用的命令行解释器和其他程序的信息。
Unix或Windows中路径变量为PATH(UNIX区分大小写,Windows不区分大小写)。
在Mac OS中,安装程序过程中改变了python的安装路径。如果你需要在其他目录引用Python,你必须在path中添加Python目录。
在 Unix/Linux 设置环境变量
如果是csh shell: 输入
setenv PATH "$PATH:/usr/local/bin/python"按下 Enter。
如果是bash shell (Linux): 输入
export PATH="$PATH:/usr/local/bin/python"按下 Enter。
如果是sh 或者 ksh shell: 输入
PATH="$PATH:/usr/local/bin/python"按下 Enter。
注意: /usr/local/bin/python 是 Python 的安装目录。
在 Windows 设置环境变量
在环境变量中添加Python目录:
在命令提示框中(cmd) : 输入
path=%path%;C:\Python按下 Enter。
注意: C:\Python 是Python的安装目录。
也可以通过以下方式设置:
右键点击"计算机",然后点击"属性"
然后点击"高级系统设置"
选择"系统变量"窗口下面的"Path",双击即可!
然后在"Path"行,添加python安装路径即可(我的D:\Python32),所以在后面,添加该路径即可。 ps:记住,路径直接用分号";"隔开!
最后设置成功以后,在cmd命令行,输入命令"python",就可以有相关显示。
注意:
如果安装时勾选了自动添加环境变量,就不用再手动添加了
更多待补充。

运行Python
有三种方式可以运行Python:
1、交互式解释器:
这种是直接在命令窗口中写程序。
你可以通过命令行窗口进入 Python,并在交互式解释器中开始编写 Python 代码。
你可以在 Unix、DOS 或任何其他提供了命令行或者 shell 的系统进行 Python 编码工作。
$ python # Unix/Linux或者
C:>python # Windows/DOS以下为Python命令行参数:
更多:


要退出Python交互模式,可以按下Ctrl + Z(Windows系统)或Ctrl + D(Mac和Linux系统)组合键,然后按下Enter键即可。 注意,要按Enter来确认退出。另外,ctrl+c或者esc都无法退出。
2、命令行脚本
这种是已经有py脚本,然后执行脚本。
在你的应用程序中通过引入解释器可以在命令行中执行Python脚本,如下所示:
$ python script.py # Unix/Linux或者
C:>python script.py # Windows/DOS注意:在执行脚本时,请检查脚本是否有可执行权限。
3、集成开发环境
IDE:Integrated Development Environment: PyCharm、idea、vscode等
PyCharm 是由 JetBrains 打造的一款 Python IDE,支持 macOS、 Windows、 Linux 系统。
PyCharm 功能 : 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制……
PyCharm 下载地址 : Download PyCharm: The Python IDE for data science and web development by JetBrains
PyCharm 安装地址:http://www.runoob.com/w3cnote/pycharm-windows-install.html
(可选)安装 PyCharm 中文插件,打开菜单栏 File,选择 Settings,然后选 Plugins,点 Marketplace,搜索 chinese,然后点击 install 安装:
在接下来的学习中请确保您的环境已搭建成功。
在以后的章节中给出的例子已在 Python2.7.6 版本测试通过。


Python 中文编码
前面章节中我们已经学会了如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符 "你好,世界" 就有可能会碰到中文编码问题。
Python 文件中如果未指定编码,在执行过程会出现报错:
#!/usr/bin/python print ("你好,世界")以上程序执行输出结果为:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for detailsPython中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 # coding=utf-8 就行了
注意:# coding=utf-8 的 = 号两边不要空格。
#!/usr/bin/python # -*- coding: UTF-8 -*- print( "你好,世界" )输出结果为:
你好,世界所以如果大家在学习过程中,代码中包含中文,就需要在头部指定编码。
注意:Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
注意:如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation byte
Pycharm 设置步骤:
进入 file > Settings,在输入框搜索 encoding。
找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。

补充
执行python脚本时,到底是使用哪个符号,python还是python2还是python3?
执行 Python 脚本时该用
python、python2还是python3,核心原则是:看脚本的 Python 版本兼容性 + 系统中命令的实际指向,下面分场景讲得明明白白,新手也能直接套用。一、先明确核心规则(记住这 2 点就不懵)
python2= 只执行 Python 2.x 脚本,python3= 只执行 Python 3.x 脚本(这两个命令是「精准指定版本」,不会错);python是「模糊别名」:系统指向哪个版本,就用哪个版本执行,Ubuntu 22.04 默认没有这个命令,你手动创建后才指向 Python 2.7。二、分场景选择执行命令(按优先级排序)
场景 1:知道脚本的目标版本(推荐,最稳妥)
- 如果脚本是 Python 2 写的(比如你 Buildroot 里的旧脚本):
python2 脚本名.py # 精准指定,不会出错- 如果脚本是 Python 3 写的(比如新开发的脚本):
python3 脚本名.py # 精准指定,避免兼容问题场景 2:不知道脚本版本(先检测,再执行)
第一步:看脚本开头的「shebang 行」(第一行),直接告诉你目标版本:
- 脚本第一行是
#!/usr/bin/env python2→ 用python2 脚本名.py;- 脚本第一行是
#!/usr/bin/env python3→ 用python3 脚本名.py;- 脚本第一行是
#!/usr/bin/env python→ 看系统python指向的版本(你这里指向 Python 2.7,就用python 脚本名.py或python2 脚本名.py)。第二步:如果没有 shebang 行,用版本检测命令:
# 检测脚本是否兼容 Python 2 python2 -m py_compile 脚本名.py # 无报错 → 兼容 Python 2 # 检测脚本是否兼容 Python 3 python3 -m py_compile 脚本名.py # 无报错 → 兼容 Python 3三、避坑要点(新手最容易错)
- 不要混用版本:比如用
python3执行 Python 2 脚本,大概率会报语法错误(比如 print 语句少括号、编码问题);- Ubuntu 22.04 不要直接用
python:默认没有这个命令,必须先创建链接,否则报错No such file or directory;- 脚本有可执行权限时(
chmod +x 脚本名.py),直接./脚本名.py即可:
- 脚本 shebang 是
python2→ 自动用 Python 2 执行;- 脚本 shebang 是
python3→ 自动用 Python 3 执行。总结
- 优先用
python2/python3精准指定版本,避免别名带来的混乱;- 旧脚本(如 Buildroot 里的)用
python2,新脚本用python3;- 不确定版本时,先看脚本 shebang 或用
py_compile检测。
有些python脚本第一行的
#!/usr/bin/env python是什么意思?1.
#!→ 「shebang / 释伴」符号(核心标识)
- 这是 Linux/Unix 系统的特殊标记,必须写在脚本第一行的开头;
- 系统看到这个符号,就知道「这不是普通文本,是可执行脚本,需要找对应的解释器来运行」;
- 如果没有这行,直接执行
./脚本.py会报错,系统不知道用什么程序来解析脚本。2.
/usr/bin/env→ 「找解释器的工具」
/usr/bin/env是系统自带的命令,作用是在系统的PATH环境变量里找后面跟着的程序;- 为什么不用直接写
/usr/bin/python?
- 不同系统的 Python 路径可能不一样(比如有的在
/usr/local/bin/python),用env能自动找,脚本兼容性更强;- 如果你装了多个 Python 版本,
env会找PATH里第一个匹配的python命令。3.
python→ 「要找的解释器」
env会在PATH里找名为python的可执行文件,找到后就用这个python来运行整个脚本;- 对应到你的场景:你创建了
/usr/bin/python指向python2,所以env找到的就是 Python 2.7,脚本就用 Python 2 执行。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)