VerilogEval:解锁大语言模型硬件设计能力的基准框架
VerilogEval的推出为大语言模型在硬件设计领域的应用评估提供了一个全面、可靠、自动化的基准框架。通过精心构建的评估数据集、文本化的问题描述、自动化的测试环境和科学的评估指标,VerilogEval不仅能够准确衡量大语言模型的Verilog代码生成能力,还为模型的优化和改进提供了明确的方向。基于合成数据的监督微调实验结果表明,通过合理的微调策略,大语言模型在Verilog代码生成任务上的性能
论文名称:VerilogEval: Evaluating Large Language Models for
Verilog Code Generation
论文地址:https://arxiv.org/pdf/2309.07544
在数字化浪潮席卷全球的当下,大语言模型(LLMs)正以惊人的速度重塑各个领域。从金融工程到生物医药,从通用编程到专业科研,这些模型凭借其强大的文本理解与生成能力,不断突破着技术边界。而在电子设计自动化领域,大语言模型同样展现出了巨大的应用潜力,有望为硬件工程师在Verilog代码编写、电路优化和自动化验证等方面提供强有力的支持。
然而,要充分发挥大语言模型在硬件设计领域的价值,一个科学、全面的评估框架至关重要。正是在这样的背景下,VerilogEval应运而生。作为首个专门针对大语言模型Verilog代码生成能力的基准测试框架,它的出现填补了该领域的研究空白,为相关技术的发展提供了关键的评估依据。
硬件设计领域的大语言模型评估困境
在电子设计自动化领域,大语言模型的应用探索早已展开。Thakur等人曾对CodeGen模型进行微调并在17个设计任务上进行评估;后续研究进一步展示了ChatGPT在芯片级电路设计方面的能力;RTLLM则提出了包含30个设计的基准框架,并通过提示工程技术提升了解决方案质量。
但这些早期研究存在明显的局限性。从问题覆盖范围来看,现有评估大多集中在数量有限的设计任务上,难以全面反映模型在不同类型硬件设计场景下的表现。问题多样性方面,现有基准缺乏对各类Verilog编程任务的均衡覆盖,从简单的组合逻辑电路到复杂的有限状态机,不同难度和类型的任务分布不均。
更关键的是评估的可靠性与自动化程度。硬件设计的特殊性使得代码正确性验证远比软件编程复杂,现有评估方法往往依赖人工检查或半自动化测试,不仅效率低下,还容易引入主观误差。同时,获取高质量的标注数据成本高昂,严重制约了模型微调与性能提升的研究进展。
这些问题共同构成了硬件设计领域大语言模型评估的困境,也凸显了构建一个全面、可靠、自动化的基准测试框架的迫切需求。
VerilogEval基准框架的构建
为解决上述困境,研究团队推出了VerilogEval——一个开源的基准测试框架。该框架的核心目标是提供多样化的问题集、清晰明确的问题描述以及自动化、可复现的测试流程,从而实现对大语言模型Verilog代码生成能力的全面评估。
多元化的评估数据集
VerilogEval的评估数据集源自知名的Verilog教学网站HDLBits,经过精心筛选和整理,最终包含156个问题。这些问题涵盖了从简单组合电路的模块实现到复杂有限状态机设计、代码调试以及测试平台构建等多个方面,全面覆盖了硬件设计的基础与核心任务。
与其他编程基准相比,VerilogEval在数据集构建上有其独特之处。从表格中可以清晰地看到,相较于HumanEval、MBPP等Python编程基准,VerilogEval不仅专注于硬件描述语言Verilog,还通过VerilogEval-machine和VerilogEval-human两种形式提供了更丰富的评估资源。其中,VerilogEval-machine包含8502个训练样本和143个测试样本,而VerilogEval-human则提供了156个高质量的人工转换测试样本。
| 基准名称 | 语言 | 训练样本数 | 测试样本数 |
|---|---|---|---|
| HumanEval [21] | Python | - | 164 |
| MBPP [22] | Python | 374 | 500 |
| APPS [23] | Python | 5,000 | 5,000 |
| VerilogEval-machine | Verilog | 8,502 | 143 |
| VerilogEval-human | Verilog | - | 156 |
文本化的问题描述转换
HDLBits上的问题描述原本包含多种形式,如电路 schematic 图像、状态转换图、布尔逻辑表和卡诺图等,这些非文本形式的数据难以直接被语言模型处理。为此,VerilogEval采用了两种方法将其转换为纯文本描述:
VerilogEval-machine通过大语言模型自动生成问题描述。研究团队使用GPT-3.5-turbo,基于特定的提示模板,先以零样本方式生成问题描述,再通过验证筛选出有效的描述。对于未解决的问题,采用少样本方式进一步生成,最终得到143个有效的机器生成描述。
VerilogEval-human则通过人工审核和转换,将网站上的问题描述转化为纯文本结构。在转换过程中,特别关注解决描述中的歧义问题,如时钟的触发边沿、复位和使能信号的有效电平及同步特性等。对于状态转换图等复杂图形,借鉴ChatGPT的指导采用边列表格式进行文本化表示,最终完成了156个问题描述的人工转换。
两种转换方式各有特点。机器生成的描述往往更为冗长,且倾向于逐行反映代码实现细节而非聚焦电路的整体功能;人工转换的描述则更注重完整性和准确性,包含了状态转换图、波形图、卡诺图等多种文本化表示形式,更贴近实际硬件设计中的问题描述方式。
自动化测试环境搭建
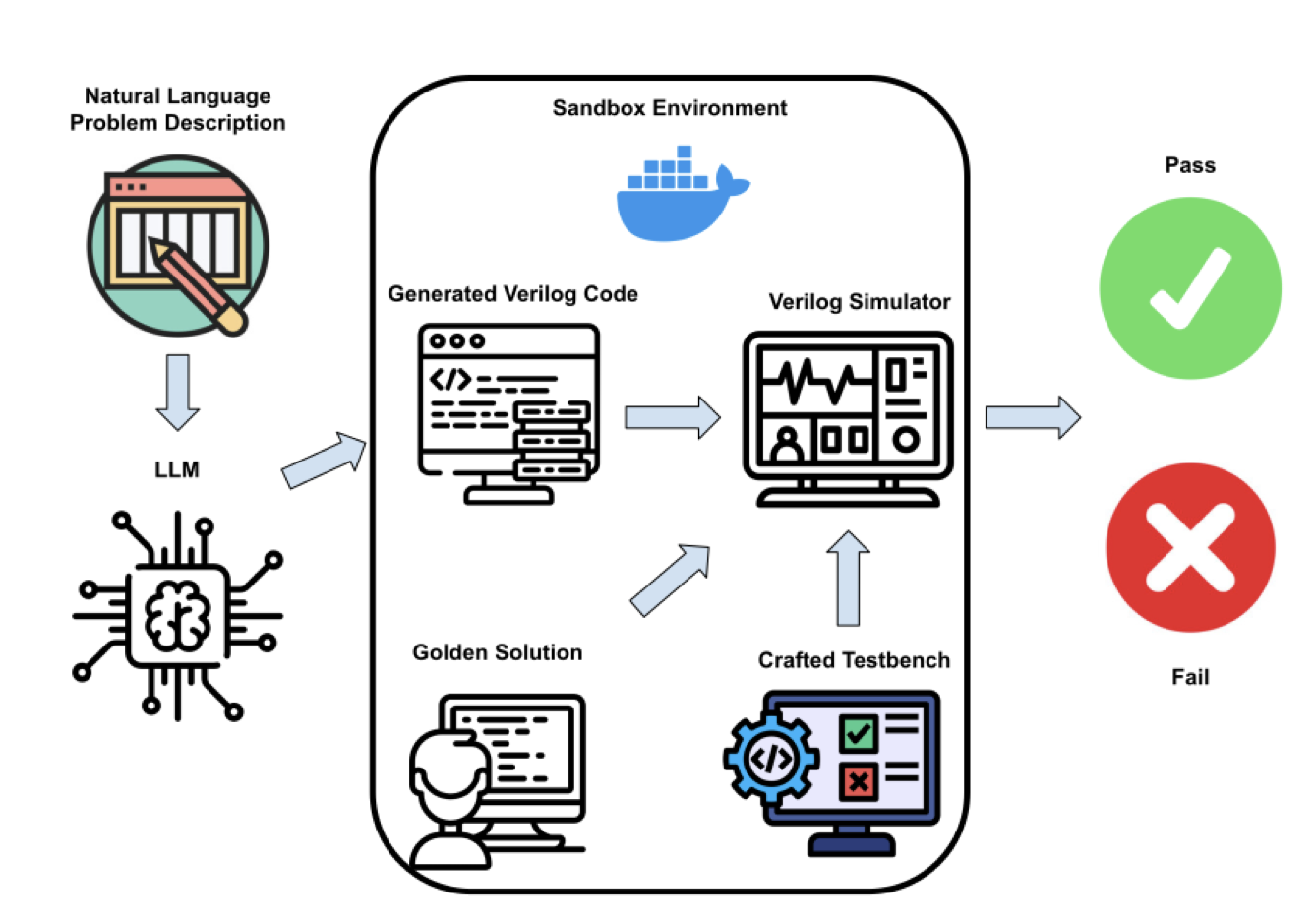
与Python等软件编程语言不同,Verilog模块的行为通常需要通过仿真来评估。为实现自动化测试,VerilogEval构建了一个基于Docker容器的沙箱环境,集成了开源的ICARUS Verilog模拟器,能够安全地运行未经验证的代码。
测试过程中,通过比较生成代码与黄金参考解决方案的仿真结果来验证功能正确性。对于时序电路,在时钟的上升沿和/或下降沿检查输出信号的正确性;对于组合电路,则在输入信号变化时进行验证。每个问题的测试集包含人工设计的关键测试模式和随机生成的测试模式,其中随机测试模式的时钟周期数根据问题复杂度从几百到几千不等。
这种自动化测试环境不仅确保了评估的客观性和可重复性,还大大提高了评估效率,使得大规模测试成为可能。
科学的评估指标
早期的代码评估常采用BLEU分数等基于匹配的指标,但研究表明这些指标与功能正确性的相关性较差。在Verilog编码评估中也存在类似问题,正确与错误解决方案的BLEU分数概率密度分布重叠度高,难以清晰区分。
因此,VerilogEval采用了近年来被广泛认可的pass@k指标,即如果k个样本中任何一个通过单元测试,则认为问题已解决。同时,使用无偏估计器计算pass@k值:
pass@k:=EProblems[1−(n−ck)(nk)]pass@k := \underset{ Problems }{\mathbb{E}}\left[1-\frac{\left(\begin{array}{c}n-c \\ k\end{array}\right)}{\left(\begin{array}{c}n \\ k\end{array}\right)}\right]pass@k:=ProblemsE 1−(nk)(n−ck)
其中,n表示每个任务生成的样本数,c表示通过测试的样本数,且n ≥ k,c ≤ n。研究还表明,当样本数n达到72时,可以产生低方差的pass@k估计,确保了评估结果的可靠性。
基于合成数据的监督微调实验
为提升大语言模型在Verilog代码生成任务上的性能,研究团队探索了利用合成数据进行监督微调(SFT)的方法,开展了一系列实验并取得了有价值的发现。
合成SFT数据集的生成
研究团队通过bootstrapping过程生成合成SFT数据。首先从GitHub数据中识别和提炼自包含的Verilog模块,利用Pyverilog提取代码的抽象语法树,并通过一系列过滤步骤确保模块的质量和自包含性:验证代码是否包含module和endmodule关键字且位置正确;移除超过200行代码或1024个token的模块;确保代码包含至少一个关键关键字(如always、assign等);保证提取的模块不包含任何模块实例化。
随后,基于MinHash算法进行近似去重,采用Jaccard相似度阈值0.8。最后,使用GPT-3.5-turbo,基于特定的提示模板生成每个Verilog模块对应的描述文本,形成机器描述和代码对。最终生成了8502个问题描述和代码对,文件大小为11MB。
微调实验设计与结果分析
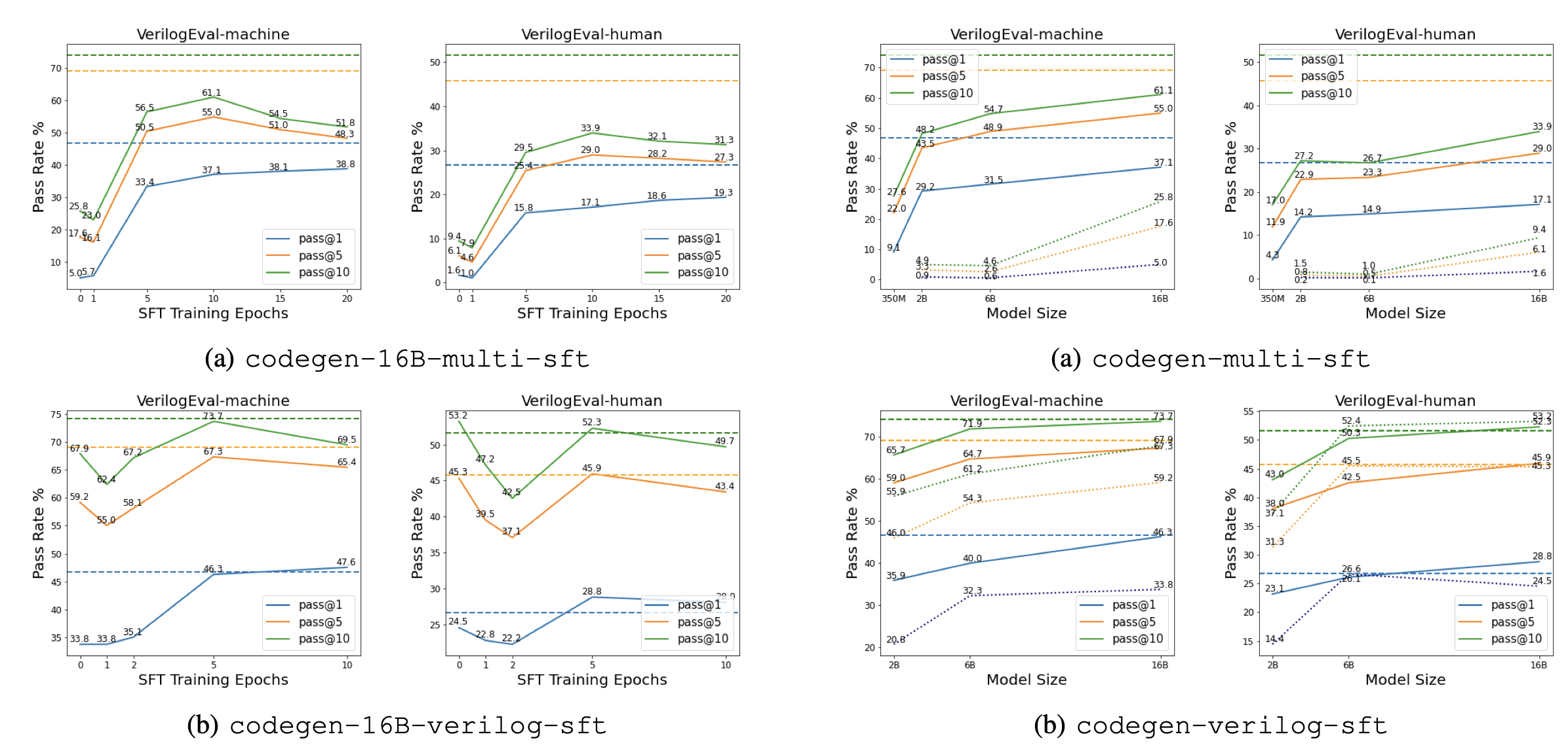
实验主要针对CodeGen模型系列及其Verilog训练版本,涵盖350M、2B、6B和16B等不同规模的模型。微调过程采用Adam优化器,设置β₁=0.9,β₂=0.999,ε=10⁻⁸,学习率为2e⁻⁵,有效批大小为1M token,不应用权重衰减。每个任务生成20个代码完成样本,使用nucleus采样(top p=0.95,temperature=0.8),上下文长度为2048。实验在配备8个A100和2TB RAM的单NVIDIA DGX节点上进行。
-
训练轮次的影响:实验结果显示,在大多数情况下,随着SFT训练轮次的增加,pass@1指标持续提升,而pass@5和pass@10指标则开始下降。这表明增加训练轮次可能导致模型过拟合SFT数据,限制了其生成多样化解决方案以应对复杂挑战的能力。但过拟合也提高了模型在简单问题上的信心和成功率,凸显了pass@1和pass@10指标之间的权衡。基于此,研究建议未来研究应同时报告这两个指标,特别是对齐后的模型。最终,多模型采用10轮微调,Verilog模型采用5轮微调。
-
模型规模和基础模型的影响:结果表明,更强大、规模更大的模型通常具有更好的Verilog编码能力。使用合成生成的数据进行SFT在大多数情况下能显著提升下游模型性能,尤其是对于未在大量Verilog代码语料上明确训练的多模型。对于Verilog模型,VerilogEval-machine表现出显著的性能提升,而VerilogEval-human的提升相对较小,甚至有时略有下降。这可能是因为SFT数据源自GitHub Verilog语料库,未引入模型在Verilog训练中未接触过的额外代码,但通过提供问题-代码对促进了模型的更好对齐,从而在VerilogEval-machine上取得更好结果。而SFT数据与VerilogEval-human之间的“错位”(生成的描述主要是低层次的,缺乏人类示例中的文本多样性)可能导致Verilog-sft模型性能略有下降。
-
与GPT模型的比较:实验结果显示,性能最佳的codegen-16B-verilog-sft模型与GPT-3.5性能相当。GPT-4在VerilogEval-machine和VerilogEval-human上的pass@1指标分别为60.0和43.5,显著高于GPT-3.5和codegen-16B-verilog-sft,展示了其在Verilog代码生成任务上的优势。
| 模型 | VerilogEval-machine | VerilogEval-human | ||||
|---|---|---|---|---|---|---|
| pass@1 | pass@5 | pass@10 | pass@1 | pass@5 | pass@10 | |
| gpt-3.5 | 46.7 | 69.1 | 74.1 | 26.7 | 45.8 | 51.7 |
| gpt-4 | 60.0 | 70.6 | 73.5 | 43.5 | 55.8 | 58.9 |
| verilog-sft | 46.2 | 67.3 | 73.7 | 28.8 | 45.9 | 52.3 |
- 不同基础模型的比较:比较以codegen-nl和codegen-multi为基础模型的sft模型结果发现,尽管多模型在大量多语言代码数据上进行了预训练,但在Verilog编码任务上仅表现出约3%的小幅提升。这表明软件编程语言(如C++)与硬件描述语言(如Verilog)之间的知识迁移有限,强调了在大量Verilog语料上预训练对提升模型在Verilog相关任务上性能的重要性。
| 模型 | VerilogEval-machine | ||
|---|---|---|---|
| pass@1 | pass@5 | pass@10 | |
| codegen-16B-nl-sft | 33.9 | 51.9 | 58.1 |
| codegen-16B-multi-sft | 37.1 | 55.0 | 61.1 |
- SFT数据质量的影响:通过将问题描述与不协调的Verilog代码解决方案打乱,创建错误的问题-代码对(sft-error)进行对比实验。结果显示,包含错误的问题-代码对会对模型性能产生不利影响,凸显了保持高质量SFT数据的关键重要性。
| 模型 | VerilogEval-machine | ||
|---|---|---|---|
| pass@1 | pass@5 | pass@10 | |
| codegen-2B-verilog | 20.1 | 46.0 | 55.9 |
| codegen-2B-verilog-sft | 35.9 | 59.0 | 65.7 |
| codegen-2B-verilog-sft-error | 21.4 | 38.8 | 46.1 |
VerilogEval的局限性与未来展望
尽管VerilogEval为大语言模型的Verilog代码生成能力评估提供了一个强大的框架,但它仍存在一些局限性,同时也为未来的研究指明了方向。
当前的局限性
VerilogEval目前主要关注大语言模型从自然语言文本描述直接生成自包含的Verilog模块的能力。虽然通过人工生成的描述涵盖了广泛的硬件设计主题,但当前的评估仅限于相对小规模设计的样板代码生成。模块实例化作为Verilog中的关键能力,在构建复杂的系统级设计中起着至关重要的作用,但目前尚未纳入基准测试范围。
此外,测试环境仅评估功能正确性,并未确保生成的Verilog代码符合可综合格式标准,也没有评估下游电路实现的性能,这一空白由RTLLM的相关工作部分填补。
更重要的是,当前VerilogEval及类似工作所解决的样板硬件描述语言(HDL)代码生成问题,在更广泛的硬件设计领域中仅占极小的范围。完整的硬件设计需要多学科知识,涉及晶体管器件、电路设计到硬件系统架构等多个层面。同时,硬件设计过程中很大一部分精力用于优化功率、性能和面积(PPA)指标,以及进行 extensive 的设计验证,以确保硬件的可靠性和良率,这些方面均未在当前的评估框架中体现。
未来研究方向
针对上述局限性,未来的研究可以在以下几个方面展开:
拓展基准测试范围,将模块实例化纳入评估,以更好地反映模型在构建复杂系统级设计方面的能力。借鉴其他领域在LLM基于代码的基准测试方面的最新进展,探索超越独立函数的实用代码生成评估。
完善测试环境,不仅评估代码的功能正确性,还应关注代码的可综合性以及下游电路实现的PPA指标,使评估更加贴近实际硬件设计需求。
提升SFT数据和Verilog预训练数据的多样性和质量,以进一步提高模型性能。可以探索更先进的合成数据生成技术,引入更多样化的问题描述形式和更复杂的硬件设计场景。
深入研究硬件设计领域的知识迁移问题,探索如何更好地利用软件编程语言的预训练知识来提升模型在硬件描述语言任务上的性能,或者开发专门针对硬件设计领域的预训练策略。
探索大语言模型与领域专家的协作模式,利用大语言模型的 vast 知识和自然语言理解能力,与领域专家共同制定新问题、设计创新解决方案,推动硬件设计过程的变革。这种人机协作模式有望在提高设计效率、可靠性和灵活性方面取得突破性进展。
结语
VerilogEval的推出为大语言模型在硬件设计领域的应用评估提供了一个全面、可靠、自动化的基准框架。通过精心构建的评估数据集、文本化的问题描述、自动化的测试环境和科学的评估指标,VerilogEval不仅能够准确衡量大语言模型的Verilog代码生成能力,还为模型的优化和改进提供了明确的方向。
基于合成数据的监督微调实验结果表明,通过合理的微调策略,大语言模型在Verilog代码生成任务上的性能可以得到显著提升,甚至达到与GPT-3.5相当的水平。这一发现为大语言模型在硬件设计领域的实际应用奠定了基础。
尽管VerilogEval仍存在一定的局限性,但它为未来的研究指明了清晰的方向。随着基准测试范围的拓展、测试环境的完善、数据质量的提升以及人机协作模式的探索,大语言模型有望在硬件设计领域发挥越来越重要的作用,推动硬件设计过程的智能化、自动化和高效化变革。
在大语言模型技术飞速发展的背景下,VerilogEval将持续进化,为硬件设计领域的创新发展提供有力的支持,助力构建更高效、更可靠、更具创新性的硬件系统。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)