基于Transformer的NLP下游任务实战之掩码语言模型(MLM)训练实战
MLM模型” 通常指的是 Masked Language Model(掩码语言模型),它是一种常用于自然语言处理(NLP)中的语言模型训练方法,是诸如 BERT(Bidirectional Encoder Representations from Transformers)模型的核心训练机制。MLM 的基本思想是:给定一个句子,随机将其中的一些词(Token)遮住(Mask),然后让模型预测这些被
系列文章目录
第一章 基于Transformer的NLP下游任务实战之命名实体识别(纯小白)
第二章 基于Transformer的NLP下游任务实战之掩码语言模型(MLM)训练实战
文章目录
前言
“MLM模型” 通常指的是 Masked Language Model(掩码语言模型),它是一种常用于自然语言处理(NLP)中的语言模型训练方法,是诸如 BERT(Bidirectional Encoder Representations from Transformers)模型的核心训练机制。
一、什么是 Masked Language Model(MLM)?
MLM 的基本思想是:给定一个句子,随机将其中的一些词(Token)遮住(Mask),然后让模型预测这些被遮住的词是原来是什么。
示例:
原句:
“机器学习是人工智能的一个分支。”
输入给模型的句子(被遮盖):
“机器学习是 [MASK] 智能的一个 [MASK]。”
模型的任务是预测:
[MASK] → “人工”
[MASK] → “分支”
简而言之,MLM就是一个做类似于完形填空任务的模型。我们给模型一句话,中间挖去几个空,模型来预测这几个空里面该填什么样子的词。那我们该怎么去用数据集训练掩码模型,提高模型能力呢?
二、训练步骤
Step1 引入库
from transformers import AutoTokenizer, AutoModelForMaskedLM, DataCollatorForLanguageModeling, TrainingArguments, Trainer
from datasets import load_dataset, Dataset
与命名实体识别训练一样,我们使用的模型是基于transformer框架的模型,所以我们需要导入transformers库中的相关包:
- 分词器:
AutoTokenizer - 模型加载器:
AutoModelForMaskedLM (模型加载器根据不同模型一定要选对) - 模型训练框架:
TrainingArguments、Trainer、DataCollatorForLanguageModeling - 数据集加载器:
load_dataset、Dataset
Step2 加载数据集
代码如下(示例):
# 这里选用Huggingface上的维基百科数据集,首次需要下载
datasets = load_dataset("pleisto/wikipedia-cn-20230720-filtered",cache_dir="./wiki_cn_filtered")
# mlm模型只针对训练,我们只取训练集
datasets = datasets["train"]
# 打乱数据集
datasets = datasets.shuffle(seed=42)
# 因为数据集数据比较多,我们只取前1w条
datasets = datasets.select(range(10000))
datasets
""" 数据集信息:
Dataset({
features: ['completion', 'source'],
num_rows: 10000
})
"""
Step3 数据处理
相比上一章命名实体识别任务,训练掩码模型的数据处理简单很多。我们来思考回顾一下mlm模型任务的输入,输入是一段被随机掩码后的句子。我们现在的数据集具备了什么条件?我们现在是原始的文本句子,那么为了能喂给模型我们是不是首先得把文本通过tokenizer把句子转换成token。
第一步:把数据从文本转换成token
#首先加载模型的分词器,这里模型使用的还是上一章命名实体的模型
tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-macbert-base", cache_dir="../model")
# 定义处理函数
def process_func(examples):
# 因为数据集里 features: ['completion', 'source'],但是我们只需要 completion 所以我们只拿 completion 部分
return tokenizer(examples["completion"], max_length = 384, truncation = True)
# 使用我们定义的处理函数来把 datasets 转换成 tokenized_ds
tokenized_ds = datasets.map(process_func, batched=True, remove_columns=datasets.column_names)
""" tokenized_ds 信息:
Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 10000
})
"""
我们可以看到通过上面代码我们把原始的 文本数据 转换成了大模型需要的 token 数据,那么下一步我们需要为这些输入的数据打上掩码。这一步该怎么做呢?
其实这一步根本不需要我们来做,我们上面引用包时引用了 DataCollatorForLanguageModeling 数据构造器,这个构造器就可以帮我们完成随机掩码的插入,后面我们用到了再说。
Step4 加载模型
# 将模型加载到本地,如果本地没有就会从Huggingface上下载
model = AutoModelForMaskedLM.from_pretrained("hfl/chinese-macbert-base", cache_dir="../model")
Step5 配置训练数据
# 这里我们就简单配置一下
args = TrainingArguments(
output_dir="./masked_lm", # 模型输出目录
per_device_train_batch_size=32, # 训练 batch size
logging_steps=10, # 每10步打印一下log
num_train_epochs=1 # 训练轮数
)
Step6 创建训练器
trainer = Trainer(
args=args, # 训练参数矩阵
model=model, # 训练模型
train_dataset=tokenized_ds, # 训练数据集
data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15) # 数据构造器
)
这里我们在创建训练器的时候选择了DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15),这个就是我们上面说到的可以自动为我们数据添加掩码的构造器,注意这里面有三个参数,首先是tokenizer这里选择我们模型的分词器,然后是mlm这个参数是是否开启掩码模式,我们就是用它来做掩码所以选择True,最后是mlm_probability,这个参数是设置我们一句话里需要掩码的token的比例,这里选择bert论文中的0.15。
Step7 开始训练
# 开始训练
trainer.train()
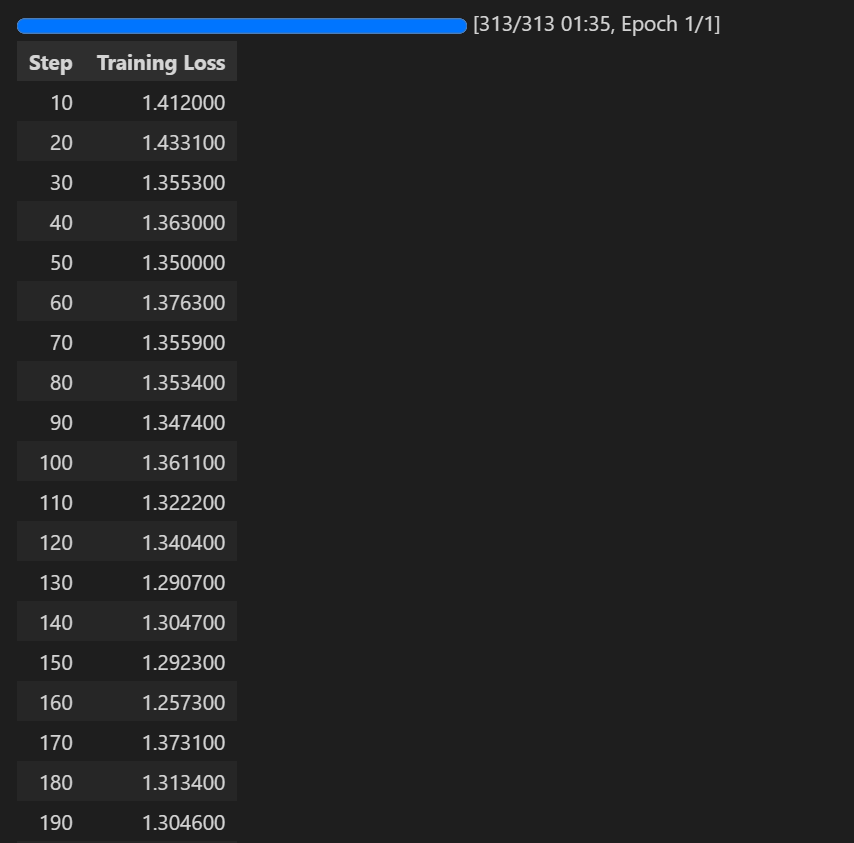
总结
对于掩码模型的训练我认为比上一章命名实体识别任务简单了太多太多了。主要是这一部分数据处理很简单,借助一写 transformer 的工具包很简单就是实现了。所以关键的还是整个训练流程,我们要明确我们的任务目标。希望这篇文章可以帮到大家,我们下一章再见!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)