YOLOv8个人数据集使用ONNX推理部署C++
这个问题我在一开始使用VS2017+onnxruntime1.15,搭配yolov8源代码时也遇到了,我这里是因为我的模型只有四种类型,而且写在前四列(见上面classes.txt)输出只有 8 列,但代码试图访问第 4 到 83 列(共 80 列)这超出了矩阵的实际列范围,这种维度不匹配通常是因为自定义模型与原始 YOLOv8 模型输出结构不同导致的。打开pycharm,打开本次将要处理的项目,
目录
一、知识储备
yolov8训练后的模型要将其.pt格式的文件转换成onnx格式,这个格式就是相当于一个翻译器。将pytorch模型转化为ONNX这个中间过渡模型,好再转为其他模型。如将model.pt转化为model.onnx, model.onnx就代表ONNX格式的权重文件,这个权重文件不仅包含了权重值,也包含了神经网络的网络流动信息以及每一层网络的输入输出信息和一些其他的辅助信息。
二、个人数据集训练
2.1准备好自己要用来训练的视频或者是图片
我的视频路径在下图
2.2对原始视频进行抽帧处理
打开pycharm,打开本次将要处理的项目,例如我的是FlameTrcker1.0.新建.py文件,命名为extract_flames。其功能是从视频文件夹中抽取帧并保存到输出文件夹
参数:video_folder: 包含MP4视频的源文件夹路径
output_folder: 保存帧的目标文件夹路径
frame_interval: 抽帧间隔(每隔多少帧取一帧)
import cv2
import os
import argparse
def extract_frames(video_folder, output_folder, frame_interval=1):
"""
从视频文件夹中抽取帧并保存到输出文件夹
参数:
video_folder: 包含MP4视频的源文件夹路径
output_folder: 保存帧的目标文件夹路径
frame_interval: 抽帧间隔(每隔多少帧取一帧)
"""
# 确保输出目录存在
os.makedirs(output_folder, exist_ok=True)
# 遍历视频文件夹中的所有MP4文件
for filename in os.listdir(video_folder):
if filename.endswith(".mp4"):
video_path = os.path.join(video_folder, filename)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频: {video_path}")
continue
# 获取视频基本信息
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
video_name = os.path.splitext(filename)[0]
print(f"处理视频: {filename} | 总帧数: {total_frames} | 帧率: {fps:.2f}")
frame_count = 0
saved_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 按间隔保存帧
if frame_count % frame_interval == 0:
frame_file = f"{video_name}_{saved_count:06d}.jpg"
output_path = os.path.join(output_folder, frame_file)
cv2.imwrite(output_path, frame)
saved_count += 1
frame_count += 1
cap.release()
print(f"已保存 {saved_count} 帧到 {output_folder}\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='从视频中抽取帧')
parser.add_argument('--input', type=str, default=r"D:\project\FlameTracker1.0\videos",
help='输入视频文件夹路径 (默认: D:\project\FlameTracker1.0\videos)')
parser.add_argument('--output', type=str, default="D:\project\FlameTracker1.0\Data sets",
help='输出帧的文件夹路径 (默认: ./frames)')
parser.add_argument('--interval', type=int, default=15,
help='抽帧间隔 (每隔多少帧取一帧, 默认:30)')
args = parser.parse_args()
extract_frames(
video_folder=args.input,
output_folder=args.output,
frame_interval=args.interval
)抽帧成功后在对应的文件夹可以看到被抽取出来的图片集
2.3 标注图片
使用的是roboflow。需要梯子。参考教程深度学习(10)之Roboflow 使用详解:数据集标注、训练 及 下载-CSDN博客 本文只使用到获得自己的数据集这一步,标注下载好后可以得到自己的数据集如图
2.4训练自己的数据集
在pycharm中项目文件夹下新建.py文件,命名为train_yolov8.加载预训练基础模型(yolov8s.pt)使用自定义数据集进行训练。
train_yolov8.py
from ultralytics import YOLO
if __name__ == '__main__':
# 加载模型
model = YOLO("yolov8s.pt")
# 训练模型
results = model.train(data=r"D:\project\FlameTracker1.0\Flame_Detection\data.yaml",
# resume=True,
epochs=100,
batch=16,
# patience=30,
# name='FlameTracker1.0',
amp=False)
训练好后会获得最佳权重文件best.pt
 2.5验证自己的数据集
2.5验证自己的数据集
新建.py文件,命名为pre_yolov8.其功能是加载PyTorch格式的预训练模型(best.pt)对指定视频文件进行预测。
pro_yolov8.py
from ultralytics import YOLO
model= YOLO(r"D:\project\FlameTracker1.0\runs\detect\train2\weights\best.pt")
# result=yolo(source=r"D:\project\FlameTracker1.0\Flame_Detection\test\images")
model.predict(source=r"D:\project\FlameTracker1.0\videos\test_indoor.mp4", save=True, save_conf=True, save_txt=True, name='output')
# source后为要预测的图片数据集的的路径
# save=True为保存预测结果
# save_conf=True为保存坐标信息
# save_txt=True为保存txt结果,但是yolov8本身当图片中预测不到异物时,不产生txt文件得到的预测结果保存在自己对应的文件夹下。我的保存在D:\project\FlameTracker1.0\runs\detect\output。点开后可以看到预测的结果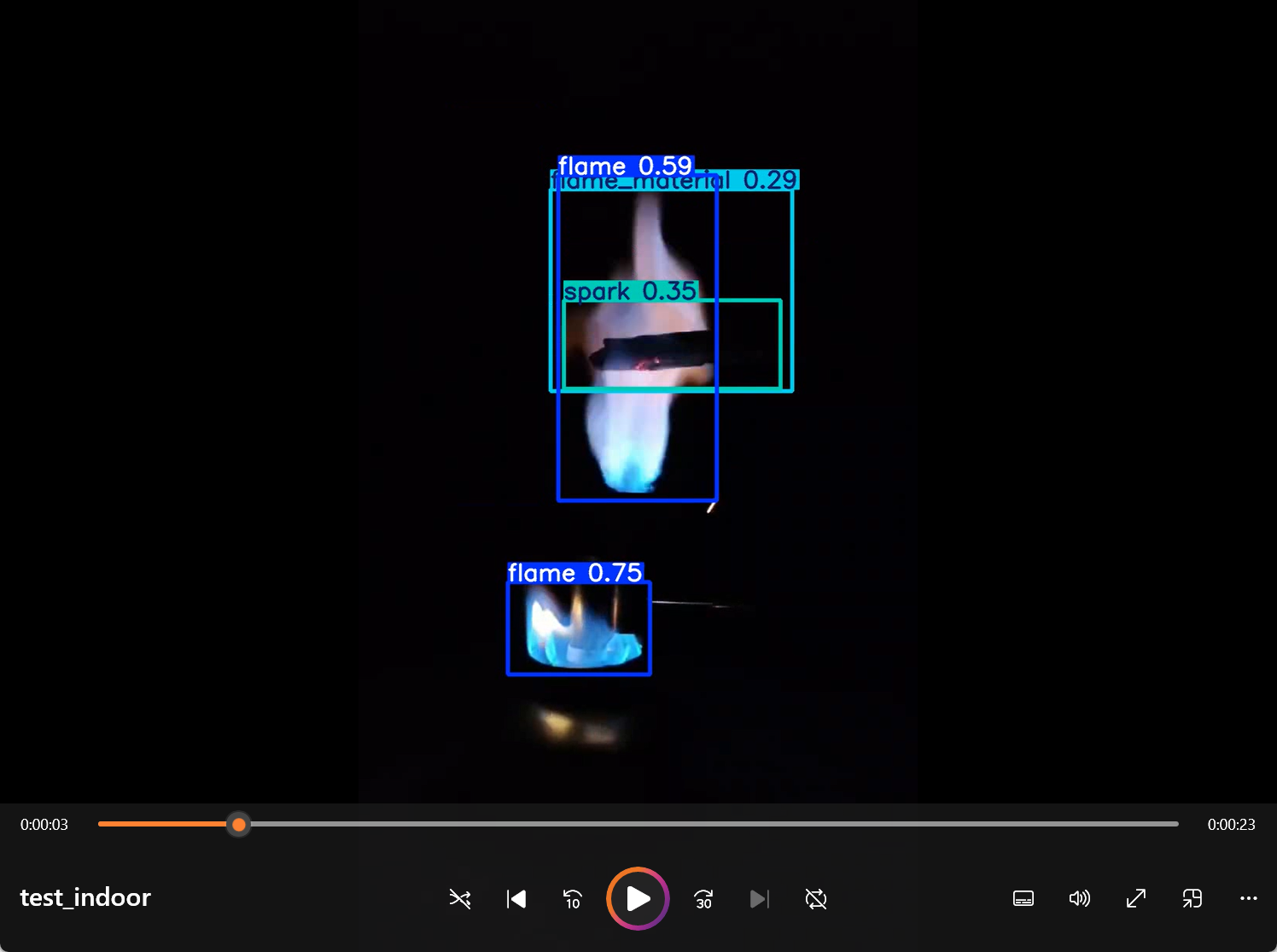
2.6 转化为ONNX格式
新建convert_onnx.py文件,拷贝以下代码。
convert_onnx.py
from ultralytics import YOLO
# 加载模型
model = YOLO(r'D:\project\FlameTracker1.0\runs\detect\train2\weights\best.pt') # 加载官方模型(示例)
# model = YOLO('D:/Web page download/best2.pt') # 加载自定义训练模型(示例)
# 导出模型
model.export(format='onnx')三、推理和部署
使用onnxruntime推理,参考【C++】使用opencv+onnxruntime推理YOLOv8目标检测_c++ yolov8-CSDN博客
环境准备:
- 系统:Win11;
- Visual Studio 2019;
- Opencv版本4.9.0;
- Onnxruntime版本1.17(CPU版)
- C++标准:>=C++17
确定自己的opencv版本,我有4.9.0和4.5.5两个版本,查看方式是进入D:\soft\OpenCV\opencv-4.5.5\opencv\build,用记事本打开OpenCVConfig-version.cmake,第一行就是版本信息
ONNXRunTime的Cpu版和gpu版的区别是CPU更简单普适但是性能相对较差,而且容易损耗设备。Gpu版计算能力强适合大规模项目,但是更难部署,所以我也用CPU版
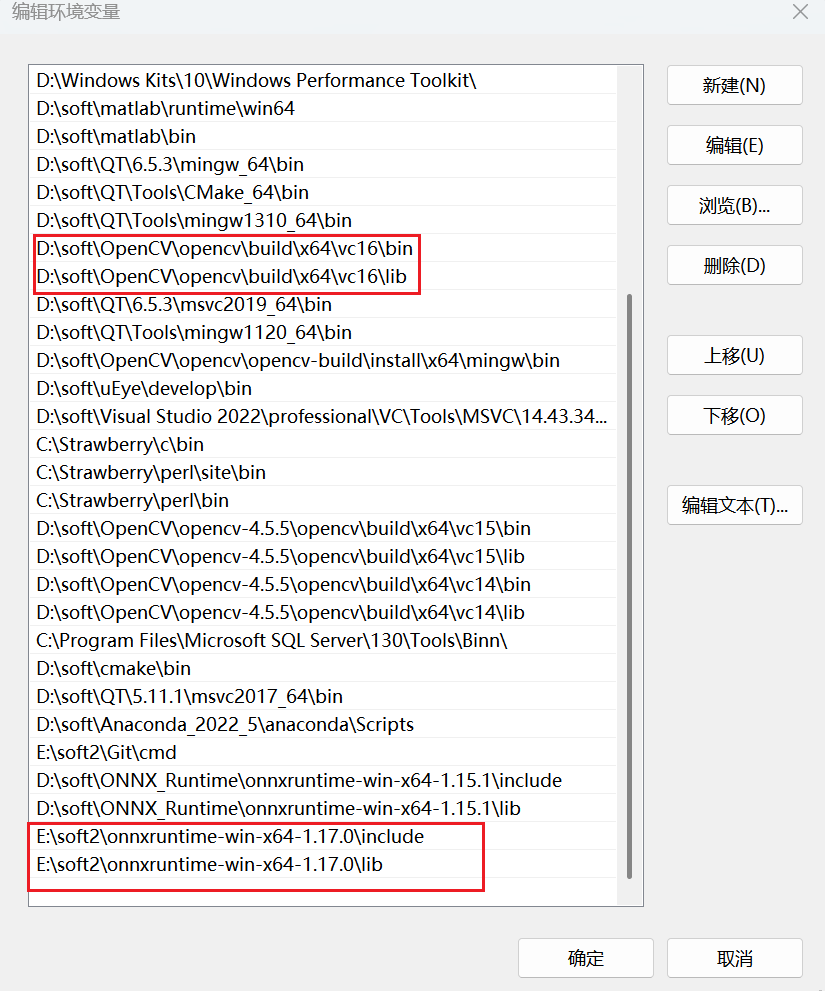
3.1环境变量添加
Opencv和ONNXRuntime的路径分别在D:\soft\OpenCV\opencv和E:\soft2\onnxruntime-win-x64-1.17.0,然后添加环境变量
3.2项目属性
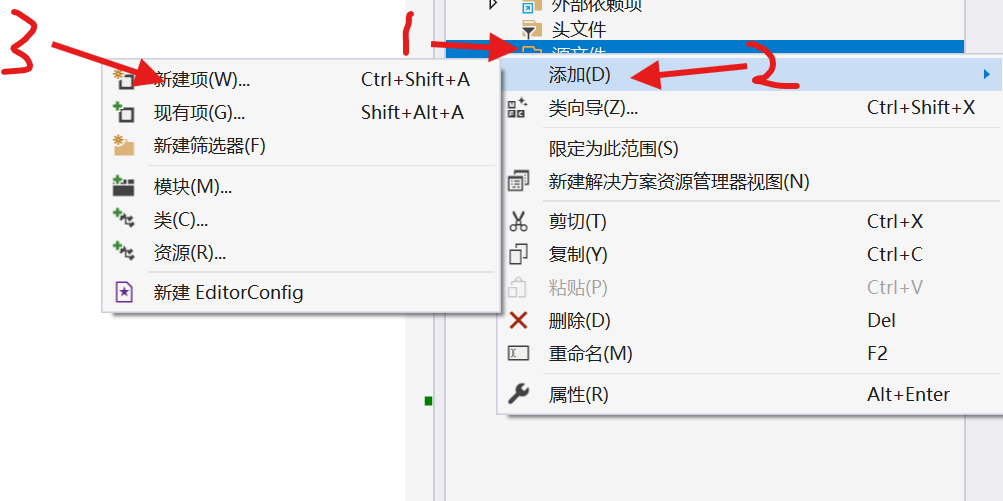
3.2.1新建项目
在VS2019中新建项目,然后右击源文件-添加-新建项-C++文件,名称main.cpp
将以下代码复制进main.cpp(这是一个大佬写得,在大佬的代码上改了一点。但是做教程时找不到之前的参考文章了),先不要运行,里面的路径还没修改。
main.cpp
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <fstream>
#include <filesystem>
using namespace cv;
using namespace std;
std::string labels_txt_file = "E:/Project_2/FT_YOLOV8_1.1/classes.txt";//读取类别标签文件
std::vector<std::string> readClassNames();
std::vector<std::string> readClassNames()
{
std::vector<std::string> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
int main(int argc, char** argv) {
std::vector<std::string> labels = readClassNames();
/*cv::Mat frame = cv::imread("E:/Project_2/FT_YOLOV8_1.1/test.jpg");
if (frame.empty()) {
std::cout << "Error: Could not load image!" << std::endl;
return -1;
}*/
// 替换图像读取代码
cv::VideoCapture cap("E:/Project_2/FT_YOLOV8_1.1/test.mp4"); // 或使用摄像头: cap(0)
if (!cap.isOpened()) {
std::cerr << "Error: Could not open video source!" << std::endl;
return -1;
}
// 验证模型文件
std::string onnxpath = "E:/Project_2/FT_YOLOV8_1.1/best.onnx";
if (!std::filesystem::exists(onnxpath)) {
std::cerr << "Error: Model file not found at " << onnxpath << std::endl;
return -1;
}
// 验证文件大小
auto file_size = std::filesystem::file_size(onnxpath);
if (file_size < 1024) {
std::cerr << "Error: Model file is too small (" << file_size << " bytes)" << std::endl;
return -1;
}
// 初始化 ONNX Runtime
//Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "yolov8-onnx"); // 提高日志级别
Ort::Env env(ORT_LOGGING_LEVEL_VERBOSE, "yolov8-onnx"); // 改为详细日志
Ort::SessionOptions session_options;
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
std::cout << "onnxruntime inference using CPU" << std::endl;
std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());
Ort::Session session_(nullptr); // 声明但不初始化
try {
// 打印 ONNX Runtime 版本
auto ort_version = Ort::GetVersionString();
std::cout << "ONNX Runtime version: " << ort_version << std::endl;
// 创建会话
std::wcout << L"Loading model from: " << modelPath << std::endl;
session_ = Ort::Session(env, modelPath.c_str(), session_options);
std::cout << "Model loaded successfully!" << std::endl;
}
catch (const Ort::Exception& e) {
std::cerr << "ONNX Runtime Error [" << e.GetOrtErrorCode() << "]: " << e.what() << std::endl;
return -1;
}
catch (const std::exception& e) {
std::cerr << "Standard Exception: " << e.what() << std::endl;
return -1;
}
// 确保会话创建成功
if (!session_) {
std::cerr << "Error: Session creation failed!" << std::endl;
return -1;
}
std::vector<std::string> input_node_names;
std::vector<std::string> output_node_names;
size_t numInputNodes = session_.GetInputCount();
size_t numOutputNodes = session_.GetOutputCount();
Ort::AllocatorWithDefaultOptions allocator;
input_node_names.reserve(numInputNodes);
output_node_names.reserve(numOutputNodes);
// 获取输入信息
int input_w = 0;
int input_h = 0;
for (int i = 0; i < numInputNodes; i++) {
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
Ort::TypeInfo input_type_info = session_.GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_w = input_dims[3];
input_h = input_dims[2];
std::cout << "input format: NxCxHxW = " << input_dims[0] << "x" << input_dims[1] << "x" << input_dims[2] << "x" << input_dims[3] << std::endl;
}
// 获取输出信息
int output_h = 0;
int output_w = 0;
Ort::TypeInfo output_type_info = session_.GetOutputTypeInfo(0);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_h = output_dims[1]; // 84
output_w = output_dims[2]; // 8400
// == = 输出节点初始化 == =
// 1. 先清空可能存在的旧数据
output_node_names.clear();
// 2. 遍历所有输出节点
for (int i = 0; i < numOutputNodes; i++) {
auto out_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(out_name.get());
}
// 3. 打印输出信息用于调试
std::cout << "output format : HxW = " << output_dims[1] << "x" << output_dims[2] << std::endl;
std::cout << "input: " << input_node_names[0] << " output: " << output_node_names[0] << std::endl;
// 创建显示窗口
cv::namedWindow("YOLOv8+ONNXRUNTIME 对象检测 (CPU)", cv::WINDOW_NORMAL);
// ===== 3. 视频处理主循环 =====
cv::Mat frame;
while (cap.read(frame)) {
if (frame.empty()) break;
/*std::cout << "output format : HxW = " << output_dims[1] << "x" << output_dims[2] << std::endl;
for (int i = 0; i < numOutputNodes; i++) {
auto out_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(out_name.get());
}
std::cout << "input: " << input_node_names[0] << " output: " << output_node_names[0] << std::endl;*/
// 图像预处理
int64 start = cv::getTickCount();
int w = frame.cols;
int h = frame.rows;
int _max = std::max(h, w);
cv::Mat image = cv::Mat::zeros(cv::Size(_max, _max), CV_8UC3);
cv::Rect roi(0, 0, w, h);
frame.copyTo(image(roi));
// 计算缩放因子
float x_factor = image.cols / static_cast<float>(input_w);
float y_factor = image.rows / static_cast<float>(input_h);
cv::Mat blob = cv::dnn::blobFromImage(image, 1 / 255.0, cv::Size(input_w, input_h), cv::Scalar(0, 0, 0), true, false);
size_t tpixels = input_h * input_w * 3;
std::array<int64_t, 4> input_shape_info{ 1, 3, input_h, input_w };
// 设置输入数据并进行推理 (CPU)
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, blob.ptr<float>(), tpixels, input_shape_info.data(), input_shape_info.size());
const std::array<const char*, 1> inputNames = { input_node_names[0].c_str() };
const std::array<const char*, 1> outNames = { output_node_names[0].c_str() };
std::vector<Ort::Value> ort_outputs;
try {
ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());
}
catch (std::exception e) {
std::cout << e.what() << std::endl;
}
// 处理输出数据
const float* pdata = ort_outputs[0].GetTensorMutableData<float>();
cv::Mat dout(output_h, output_w, CV_32F, (float*)pdata);
cv::Mat det_output = dout.t(); // 8400x84
// 后处理
std::vector<cv::Rect> boxes;
std::vector<int> classIds;
std::vector<float> confidences;
int num_classes = labels.size(); // 获取实际类别数量
for (int i = 0; i < det_output.rows; i++) {
cv::Mat classes_scores = det_output.row(i).colRange(4, 4 + num_classes);
cv::Point classIdPoint;
double score;
minMaxLoc(classes_scores, 0, &score, 0, &classIdPoint);
// 置信度阈值过滤
if (score > 0.25)
{
float cx = det_output.at<float>(i, 0);
float cy = det_output.at<float>(i, 1);
float ow = det_output.at<float>(i, 2);
float oh = det_output.at<float>(i, 3);
int x = static_cast<int>((cx - 0.5 * ow) * x_factor);
int y = static_cast<int>((cy - 0.5 * oh) * y_factor);
int width = static_cast<int>(ow * x_factor);
int height = static_cast<int>(oh * y_factor);
cv::Rect box;
box.x = x;
box.y = y;
box.width = width;
box.height = height;
boxes.push_back(box);
classIds.push_back(classIdPoint.x);
confidences.push_back(score);
}
}
// NMS非极大值抑制
std::vector<int> indexes;
cv::dnn::NMSBoxes(boxes, confidences, 0.25, 0.45, indexes);
for (size_t i = 0; i < indexes.size(); i++) {
int index = indexes[i];
int idx = classIds[index];
cv::rectangle(frame, boxes[index], cv::Scalar(0, 0, 255), 2, 8);
cv::rectangle(frame, cv::Point(boxes[index].tl().x, boxes[index].tl().y - 20),
cv::Point(boxes[index].br().x, boxes[index].tl().y), cv::Scalar(0, 255, 255), -1);
putText(frame, labels[idx], cv::Point(boxes[index].tl().x, boxes[index].tl().y), cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
}
// 计算并显示FPS
/*float t = (cv::getTickCount() - start) / static_cast<float>(cv::getTickFrequency());
putText(frame, cv::format("FPS: %.2f", 1.0 / t), cv::Point(20, 40), cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
cv::imshow("YOLOv8+ONNXRUNTIME 对象检测 (CPU)", frame);
cv::waitKey(0);*/
float t = (cv::getTickCount() - start) / static_cast<float>(cv::getTickFrequency());
float fps = 1.0 / t;
putText(frame, cv::format("FPS: %.2f", fps), cv::Point(20, 40),
cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
cv::imshow("YOLOv8+ONNXRUNTIME 对象检测 (CPU)", frame);
// 退出条件
if (cv::waitKey(1) == 'q') break;
}
// ===== 4. 释放资源 =====
cap.release();
cv::destroyAllWindows();
return 0;
}
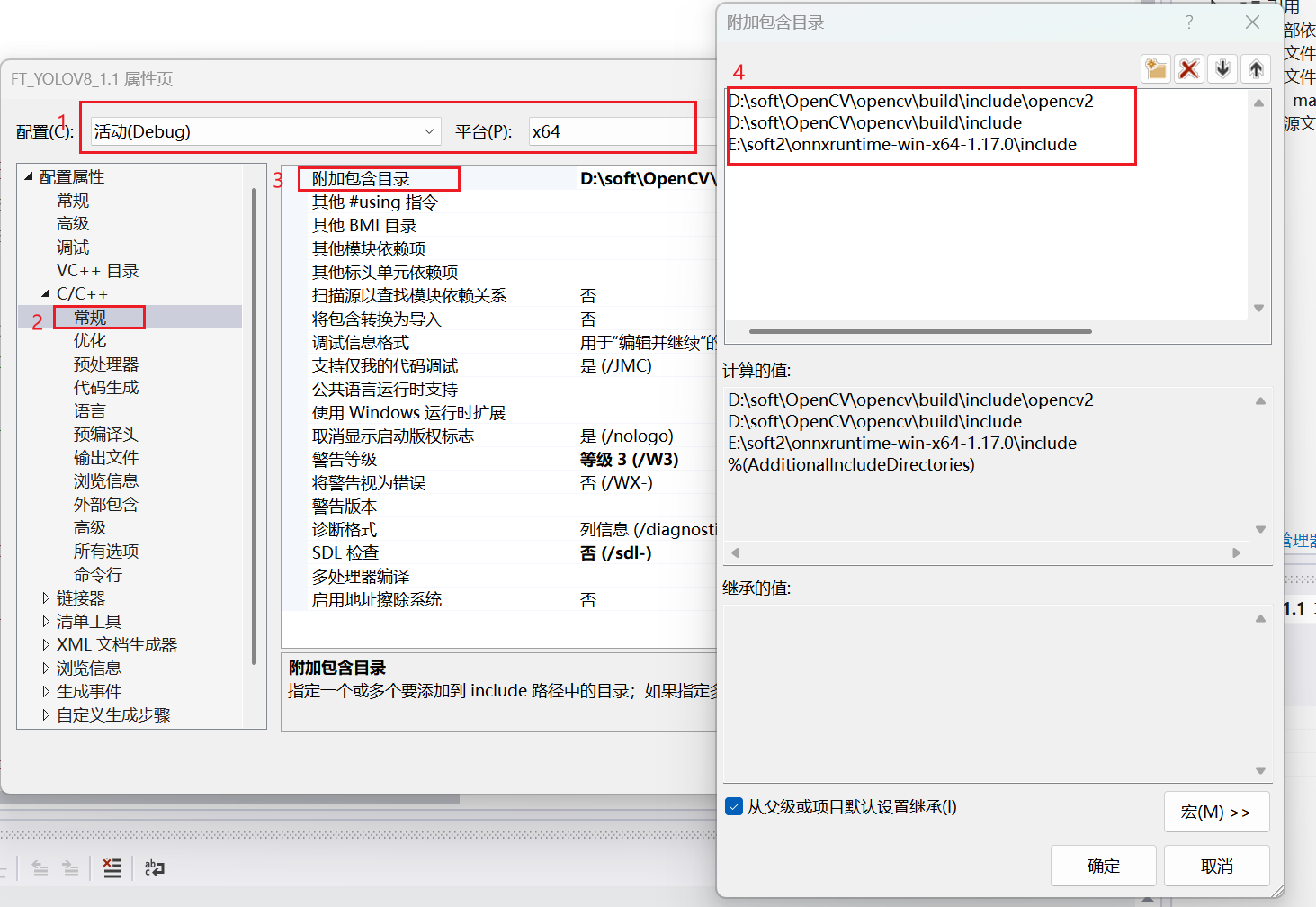
3.2.2附加包含目录
右击项目-属性-C++-常规-附加包含目录-编辑-添加,添加下图中的路径
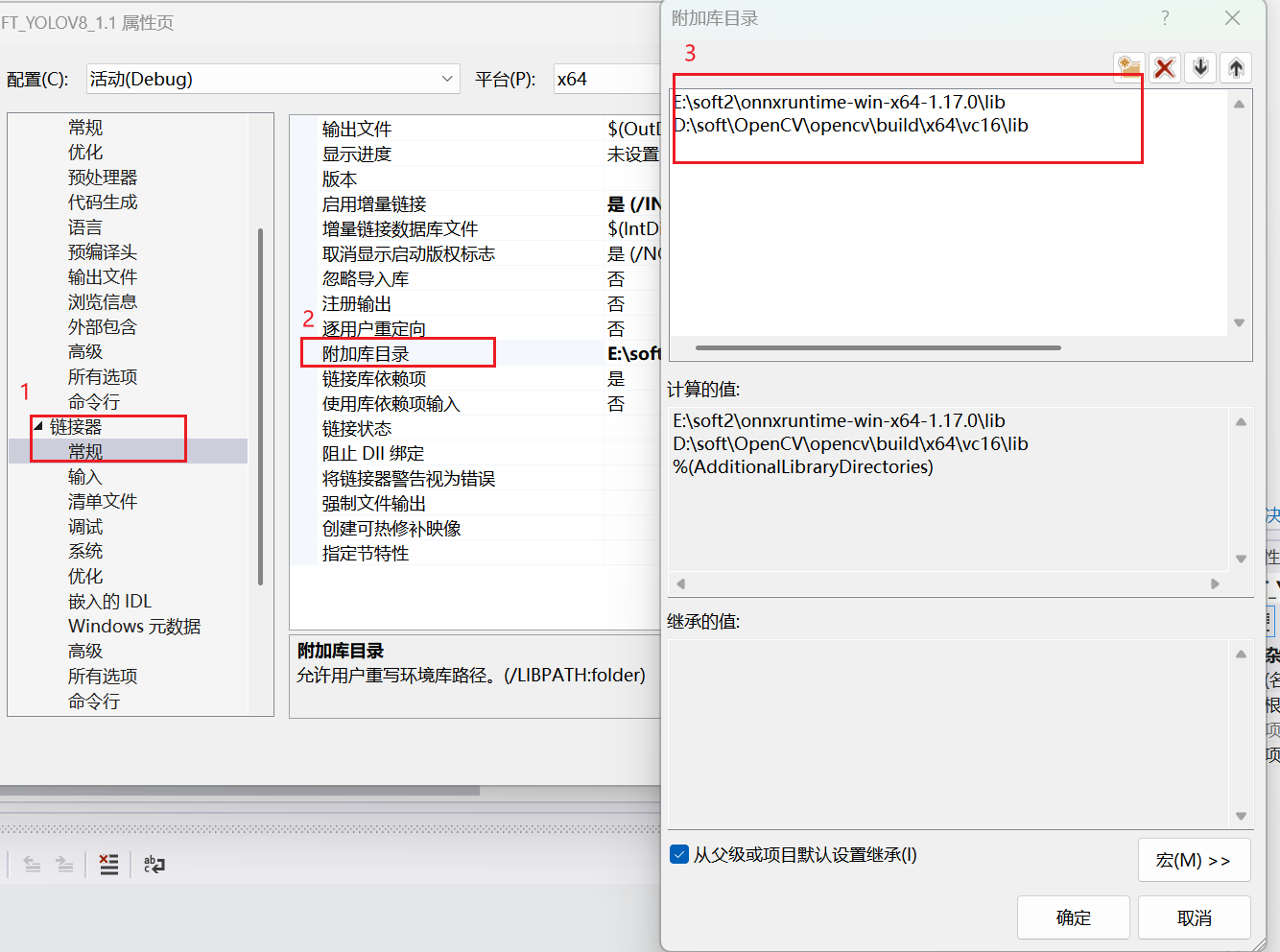
3.2.3 附加库目录
右击项目-属性-链接器-常规-附加库目录-编辑-添加,添加下图中的路径
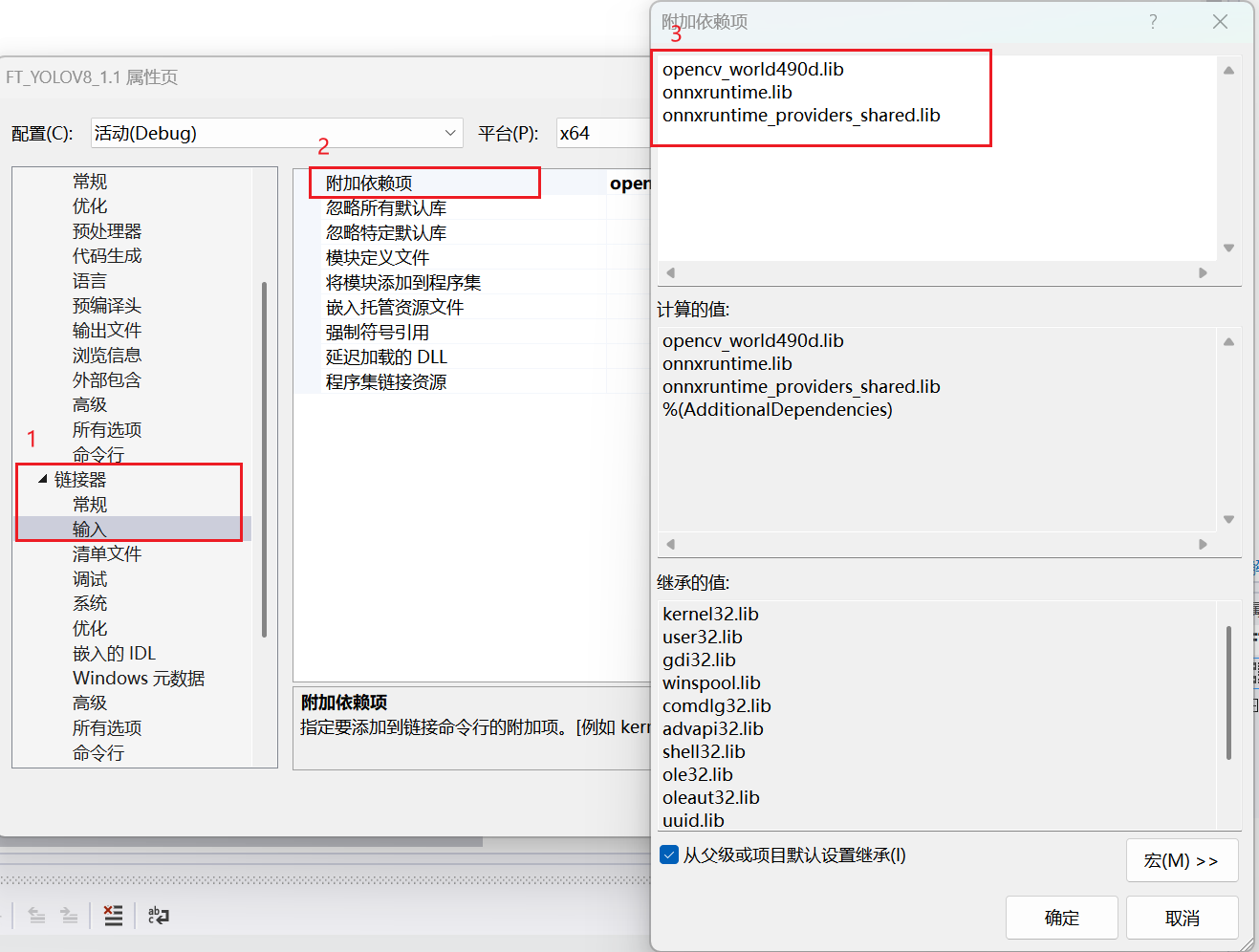
3.2.4 附加依赖项
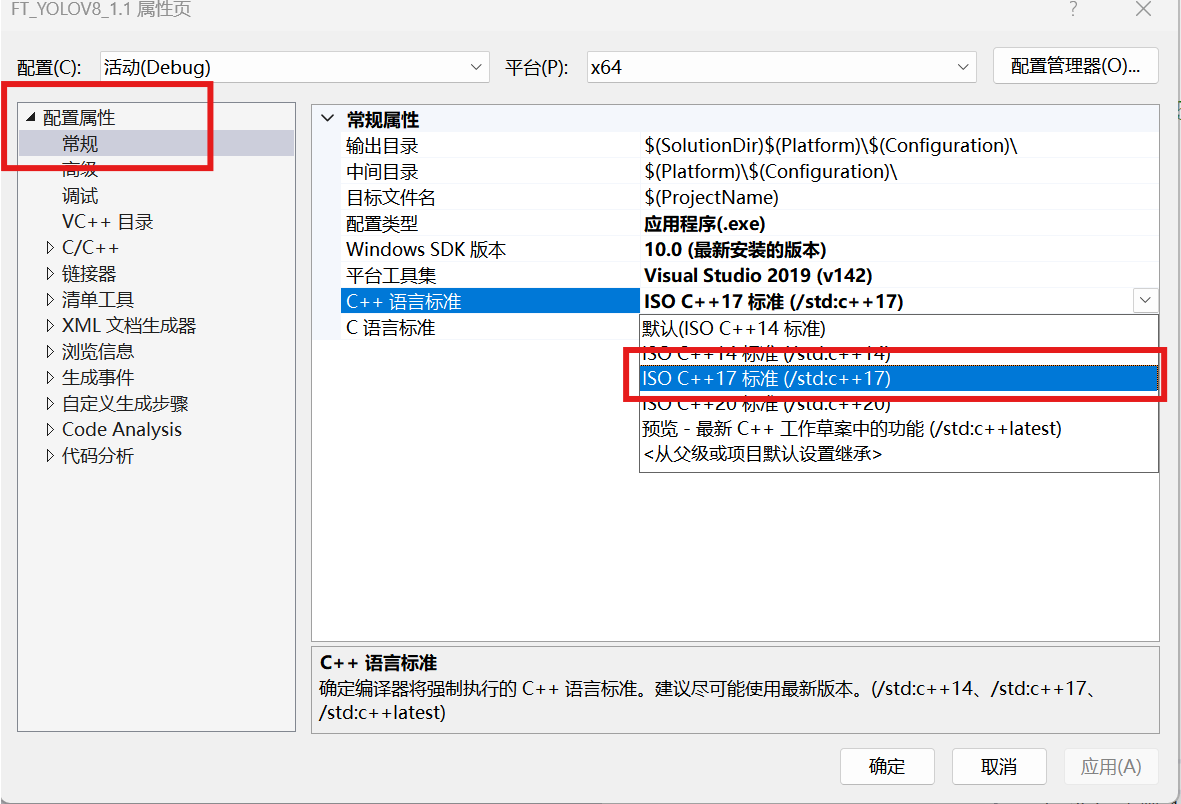
3.2.5语言配置
右键项目-属性-配置属性-常规-C++语言标准选择如下图
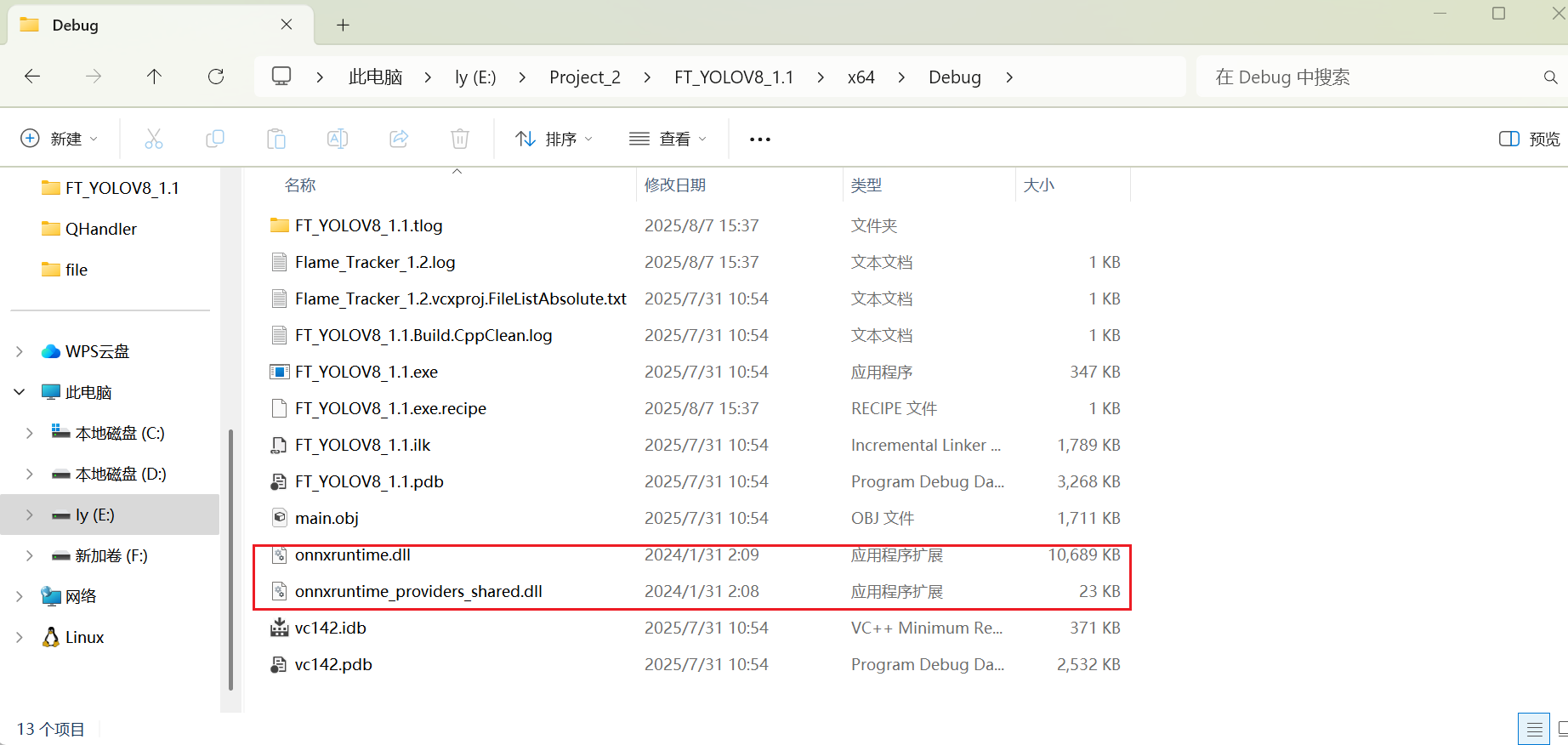
3.2.6 移植ONNX的dll文件
运行项目,出现报错不用管。目的是生成一个debug文件夹,将E:\soft2\onnxruntime-win-x64-1.17.0\lib下的全部DLL文件复制到…\x64\Debug文件夹中
四、运行
4.1添加标签类别文件
自己可以写一个classes.txt,其中包含了自己一开始在roboflow中设置的标签类型。下图是我的标签名称

4.2 修改main.cpp
将main.cpp中约第9行替换为自己的classes.txt路径
![]()
将第39行替换为自己需要检测的视频路径
![]()
将46行替换为自己的onnx文件路径
![]()
4.3 运行项目
在vs中上方点击生成-重新生成解决方案
生成成功之后点击运行![]() 实现对视频的预测
实现对视频的预测
运行结果如下
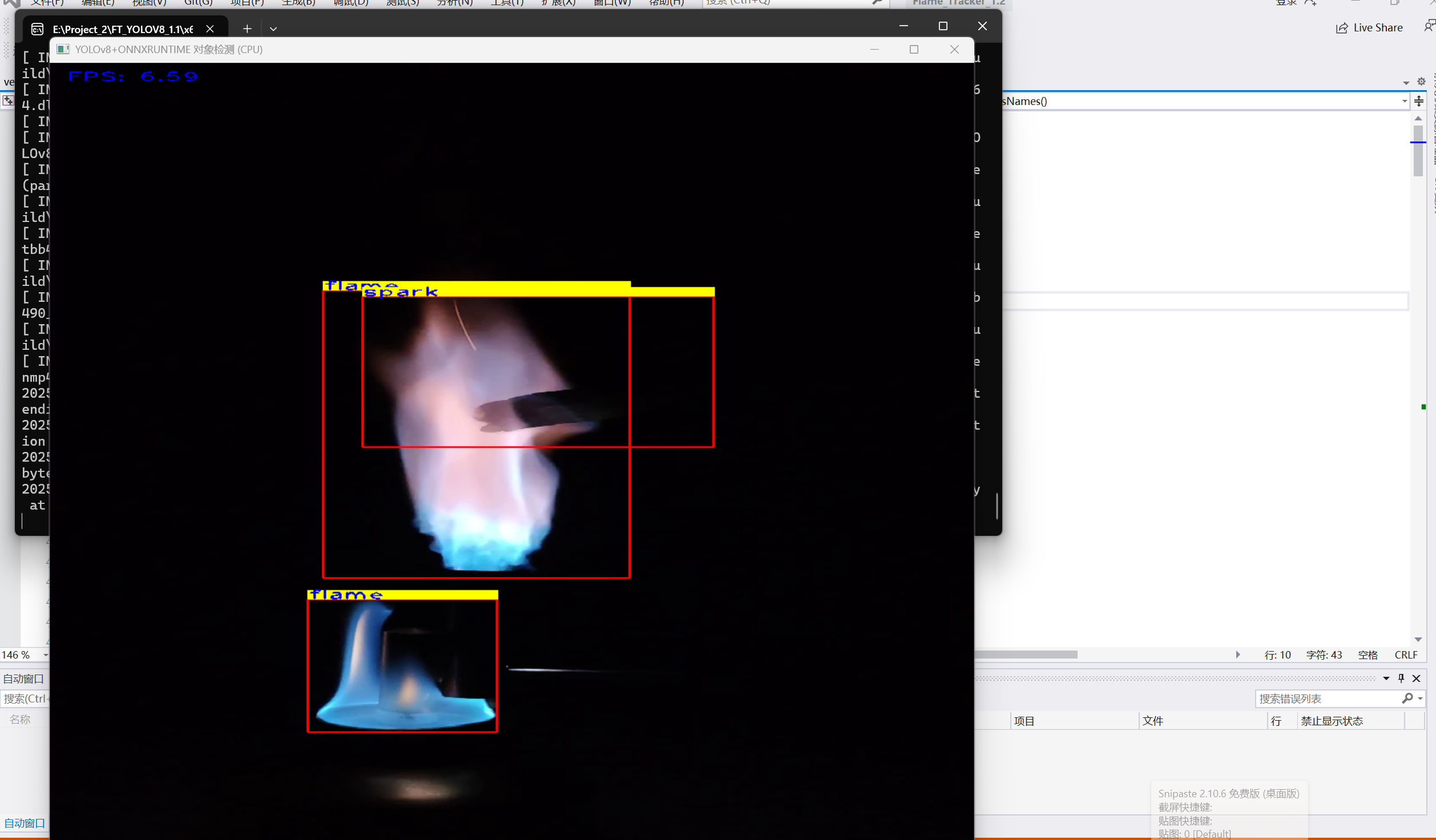
五、常见问题
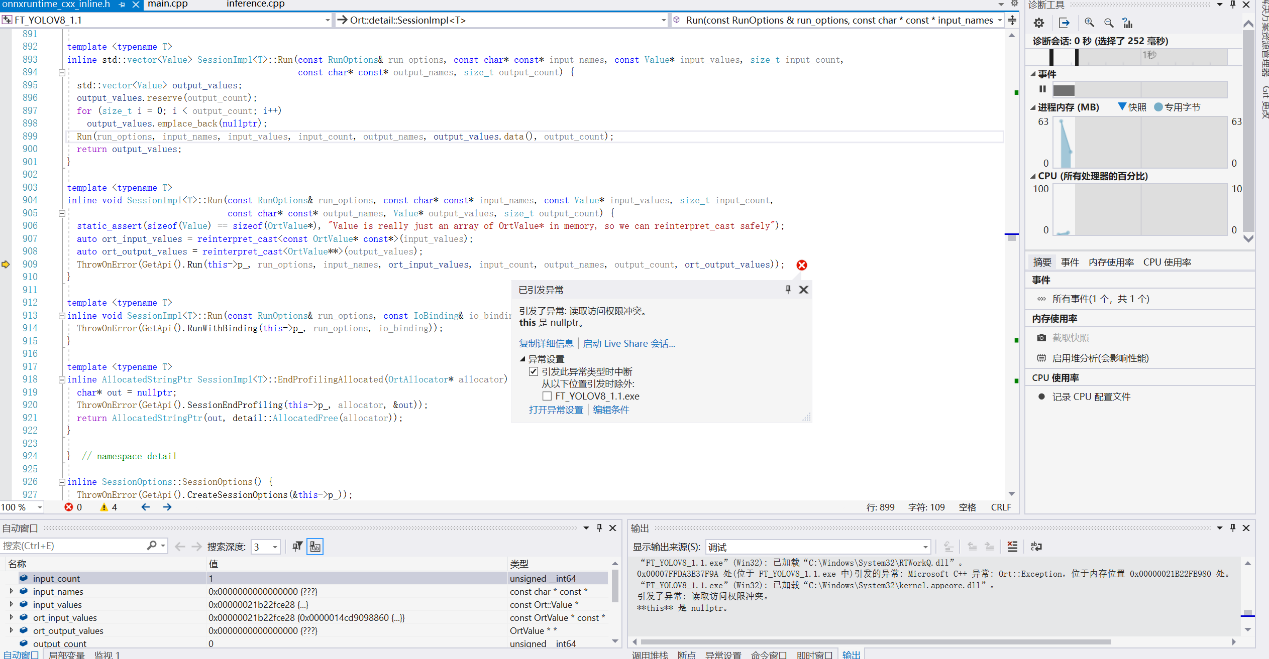
这个问题我在一开始使用VS2017+onnxruntime1.15,搭配yolov8源代码时也遇到了,我这里是因为我的模型只有四种类型,而且写在前四列(见上面classes.txt)输出只有 8 列,但代码试图访问第 4 到 83 列(共 80 列)这超出了矩阵的实际列范围,这种维度不匹配通常是因为自定义模型与原始 YOLOv8 模型输出结构不同导致的。改为获取实际标签数量之后就没有这个问题了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)