AI绘图教程|Stable Diffusion(SD)文生图参数详解及吉尼龟小案例
SD学习绘图最开始的第一步是文生图,这也是最基础的学习,今天我带大家先学习下文生图
SD学习绘图最开始的第一步是文生图,这也是最基础的学习,今天我带大家先学习下文生图
01
—
文生图参数
01
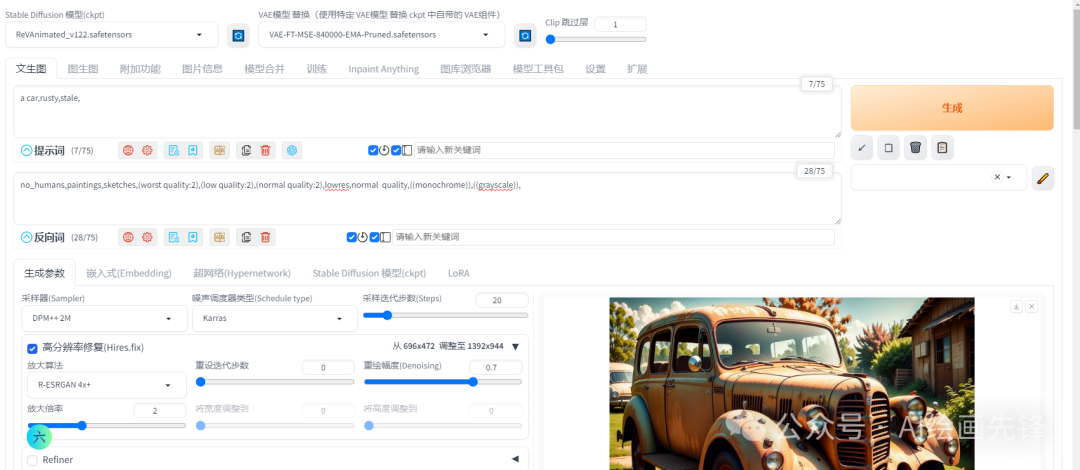
****模型选择
模型选择主要分大模型选择和VAE模型选择,这里根据你画的图具体进行选择,这个参数的选择难度不大。
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

02
Clip跳过层
Clip跳过层参数修改的比较少,为内容的完整性,简单阐述下它的作用。我们先开始测试看下,提示词输入“吉尼龟”、“可爱”、“帽子”和“水”这些关键词,固定种子点,调整Clip跳过层看下效果。
这里我们使用X\Y\Z图表脚本进行对比测试
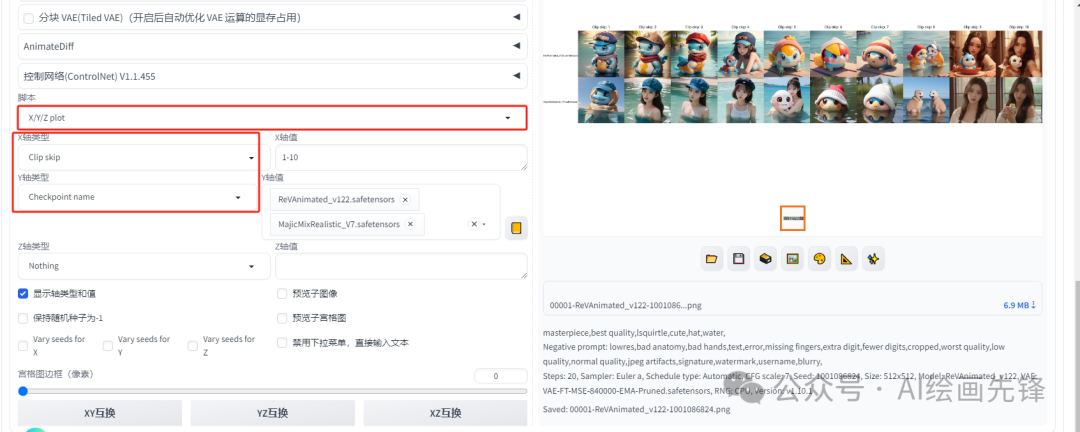
通过横向对比Clip跳过层从1到10的不同设置,并结合两个模型的纵向对比,我们可以观察到一个总体的趋势:随着Clip跳过层数值的增高,所生成的图像中缺失了我们在提词器中设定内容的情况就越为明显。

最后结论:Clip跳过层的数值设置得越高,生成的图片与提词器中的关键词之间的相关性就越低。
这个结论作为新手我们知道就可以,大部分情况使用默认值1,不用修改参数
03
采样迭代步数
采样迭代步数就是用多少次来计算你提示词里的内容,我们设置1-40迭代步数并在里面选取10张图片进行对比看下
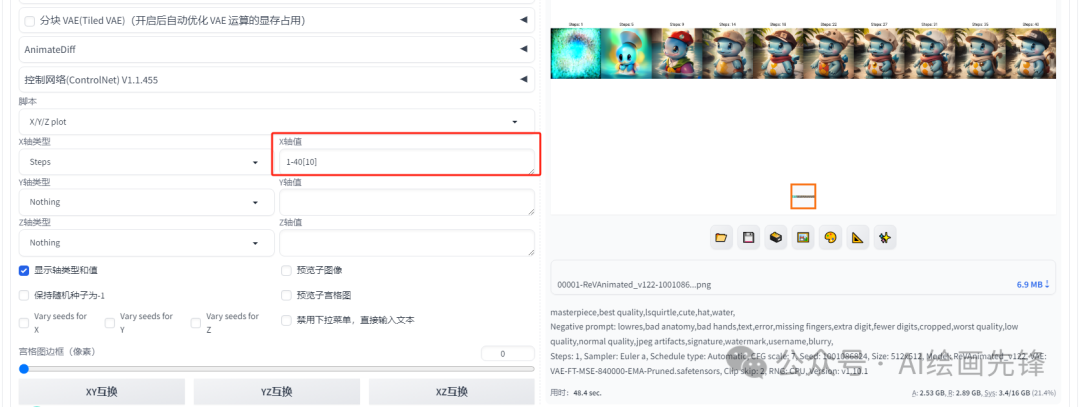
可以看到,当步数设置得过低时,生成的图像几乎无法展现出任何内容。因此,通常建议将步数控制在30步以内,因为一旦超过这个范围,虽然可能会继续提升图片生成的质量,但所需的时间和对GPU显存会显著增加,而收益却可能相对有限。

04
采样方法
采样方法也就是不同的算法选择。我们在之前关于采样迭代步数的对比基础上,增加了对所有采样方法的对比,以便进行更为全面的纵向对比分析。
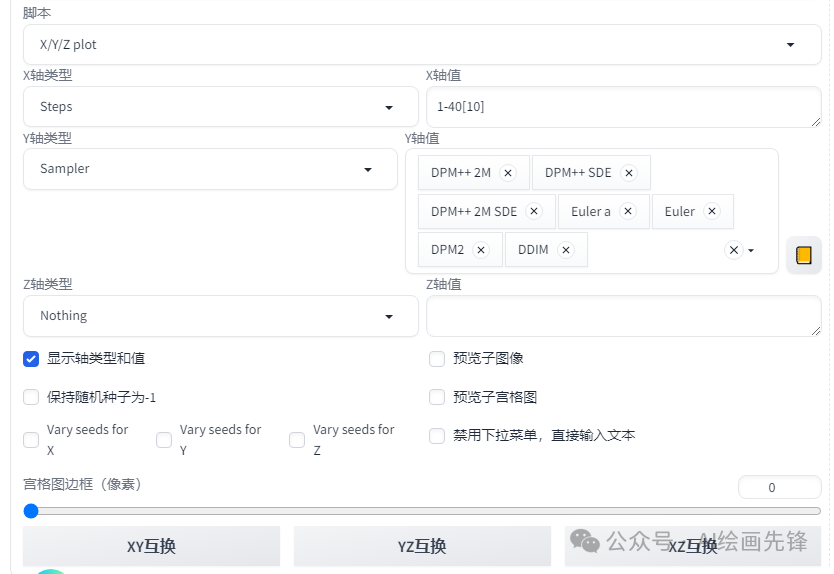
在选择采样方法时,最佳方法就是亲身尝试,并结合个人的偏好来做出选择。
当前,网络上最为流行的几种采样方式包括:Euler a、DPM++ 2M Karras、DPM++ SDE Karras以及DDIM。

05
****高清修复
高清修复功能主要图像的像素的扩大和高清处理,在一定程度上也可以帮助改善面部效果。
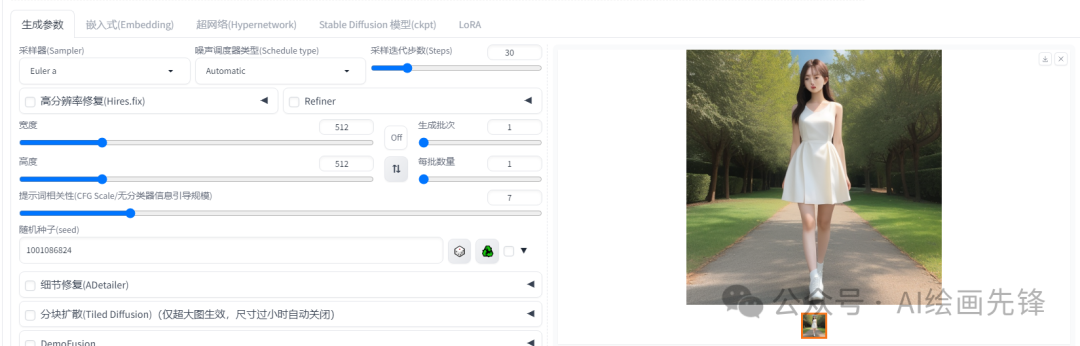
未开启高清修复,分辨率512*512,采样步数30,脸部稍微有点瑕疵
开启高清修复,分辨率1024*1024,采样步数30,放大算法:R-ESRGAN 4x+
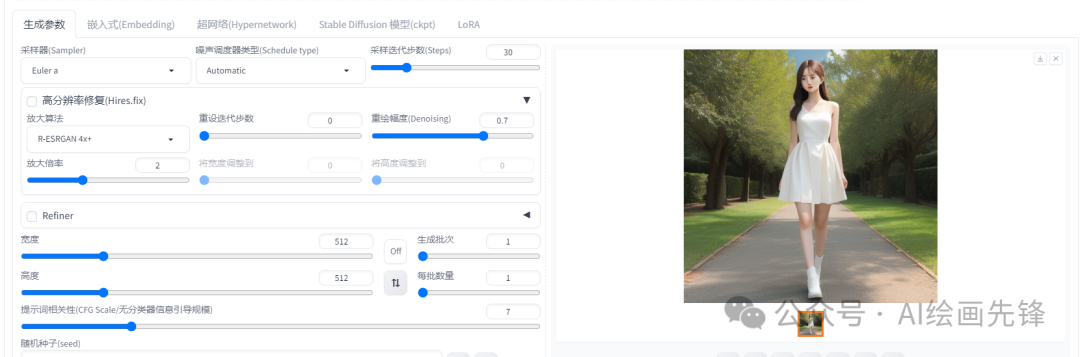
脸部做了修复,但修复效果不是太好,这种情况最好进行脸部修复
对于三次元图像的处理,推荐选用R-ESRGAN 4x+算法;而对于二次元图像,则更适合使用R-ESRGAN 4x+ Anime6B算法。这两种算法在进行高清修复时通常能取得令人满意的效果。
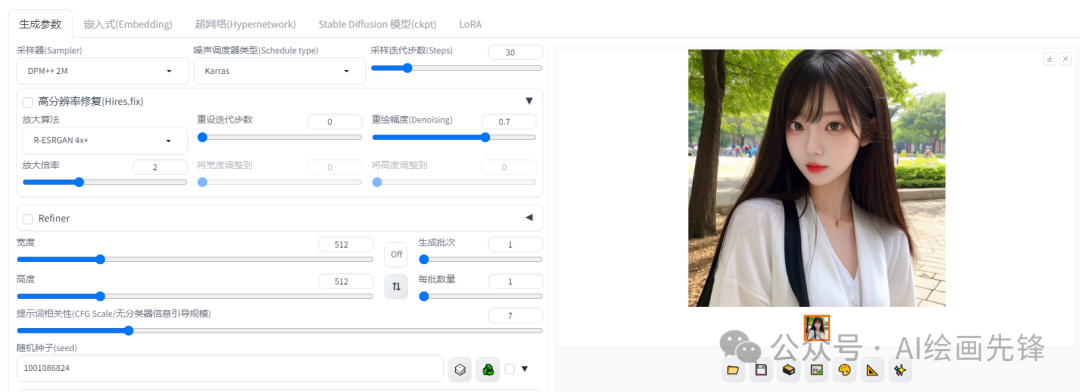
一般来说,高清修复功能中的采样次数可以保持默认值0,这样它就会与采样迭代步数保持同步。
至于重绘幅度,该数值越高,最终生成的图像与原始图像的差异就会越大。通常情况下,将重绘幅度设置在0.4到0.7之间,效果会比较理想。
重绘幅度调整到1,生成的图像和原来差别较大
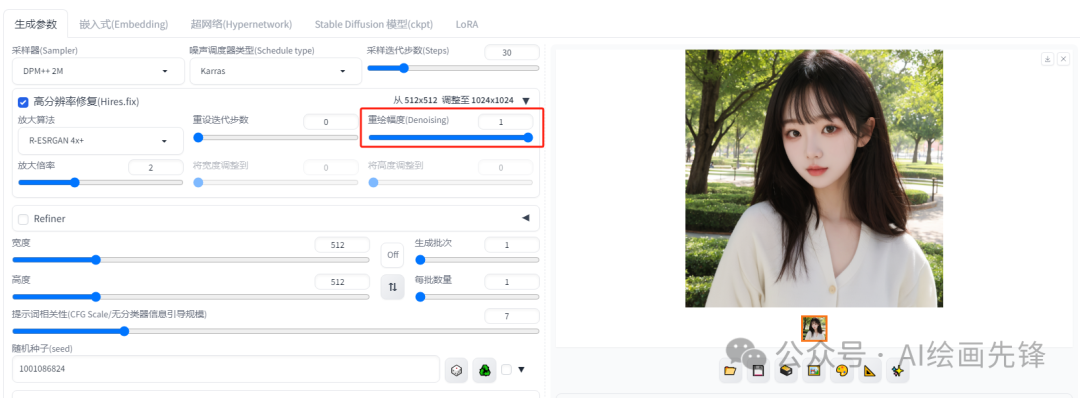
放大倍率这一参数,顾名思义,就是要在原有分辨率的基础上将图像放大多少倍。但需要注意的是,放大倍率不宜设置得过高,否则可能会导致显卡崩溃。一般来说,将放大倍率设置为2倍就足够了。
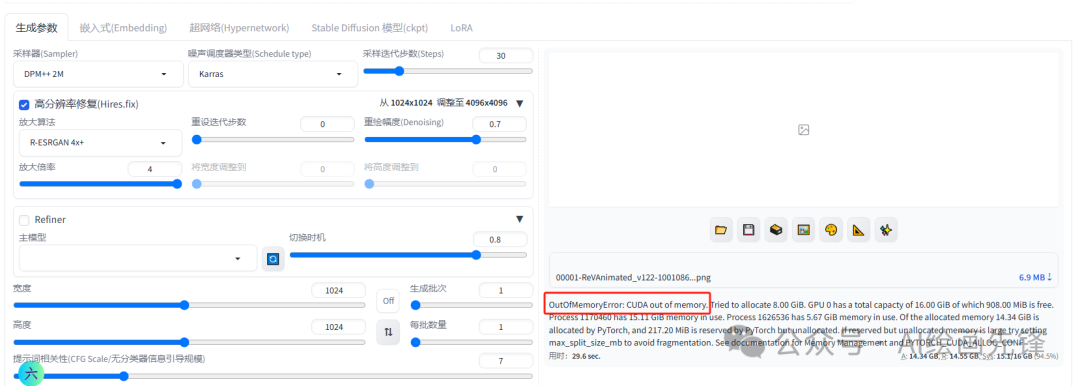
还需要注意的一点是,当遇到面部崩坏的情况时,面部修复和高清修复功能应该二选一,建议不要同时开启,否则可能会适得其反。
06
****分辨率
分辨率的设置比较关键,SD 1.5的模型训练的图片分辨率是512*512,
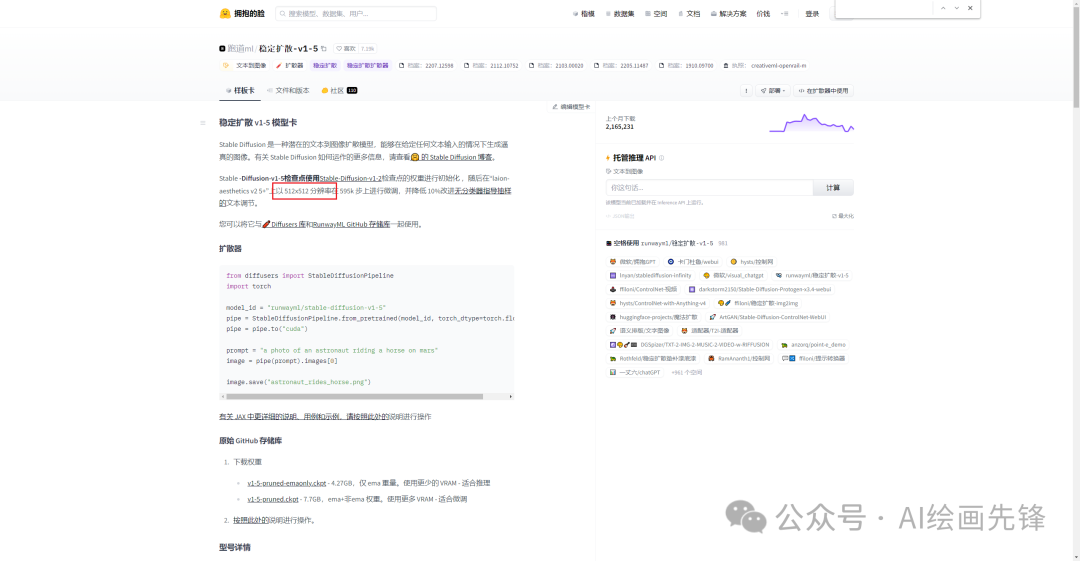
SD2.1模型训练图片分辨率新增了768*768,这也就是说几乎所有的模型训练的尺寸都是512*512或者768*768。当图像的分辨率过低。
如低于256x256时,SD的性能可能会受到限制,从而可能导致图像质量的降低。
然而,如果我们将分辨率设置得过高,比如超过1024x1024,SD可能会胡乱处理,导致构图出现问题,甚至产生不协调或怪异的效果。
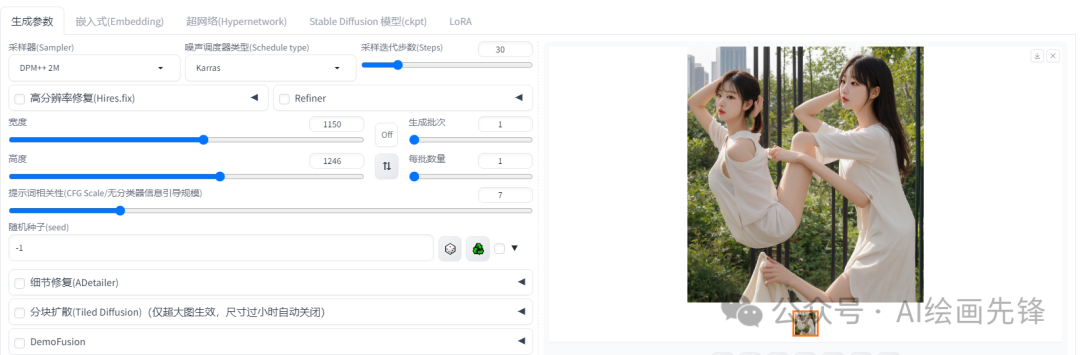
具体分辨率的设置,建议至少确保其中一个宽度或高度为512或768像素。有些图像处理模型还会明确给出推荐的分辨率范围。
如果你确实希望生成高分辨率的图像,一个可行的做法是首先生成一个较小分辨率的图像,然后在此基础上应用高清修复功能来进一步提升图像的清晰度。
07
****生成批次和CFG
生成批次的概念很容易理解,它指的是每次生成多少组图像,而这些图像的随机种子则是按顺序递增的。
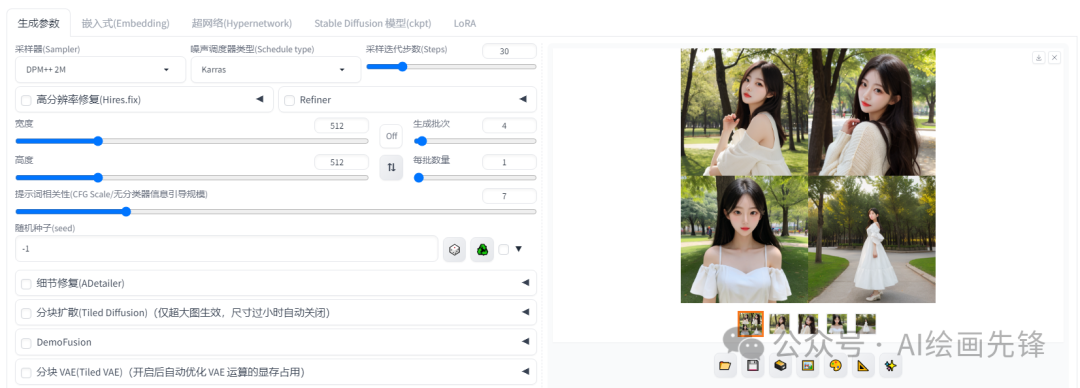
每批数量指的是每一组中包含的图像张数。如果我选择了生成3批图像,且每批数量为4张,那么最终我将得到总共12张图像。
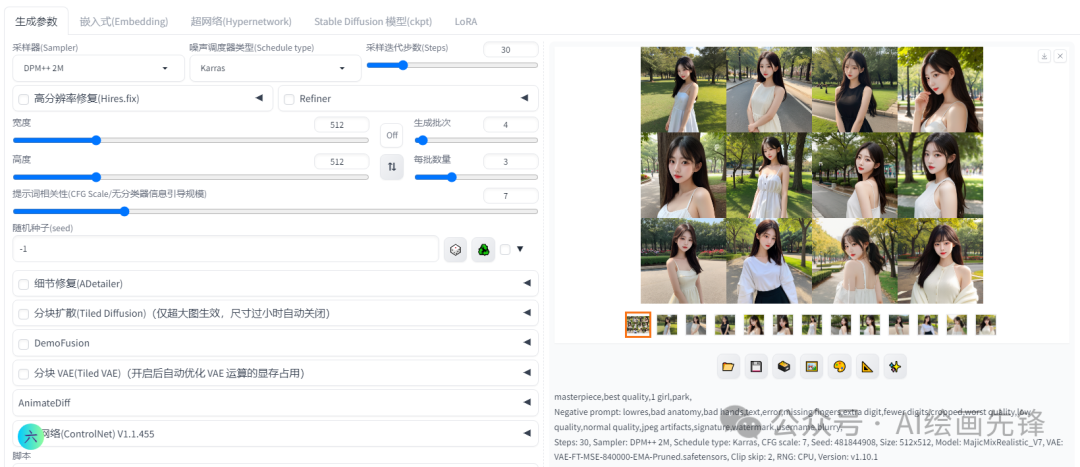
CFG参数用于调节生成图像与给定提示词的相关性。该参数值越高,生成的图像越贴近提示词内容,但过高的设置可能会导致图像饱和度过高,出现过曝现象。

08
****随机数种子
说到随机种子,我们首先需要了解一下AI绘图的基本工作原理。简单来说,AI绘图的过程就是从一张噪声图开始,然后通过不断地调整和优化,使其逐渐接近并符合我们给出的提示词,最终生成出一张图片。
在这个过程中,随机种子就扮演着决定这张初始噪声图角色的重任。为了更直观地展示这一过程,我使用了DPM++ 2M Karras这种采样模式,并生成了一个从采样迭代步数1到15的对比图。
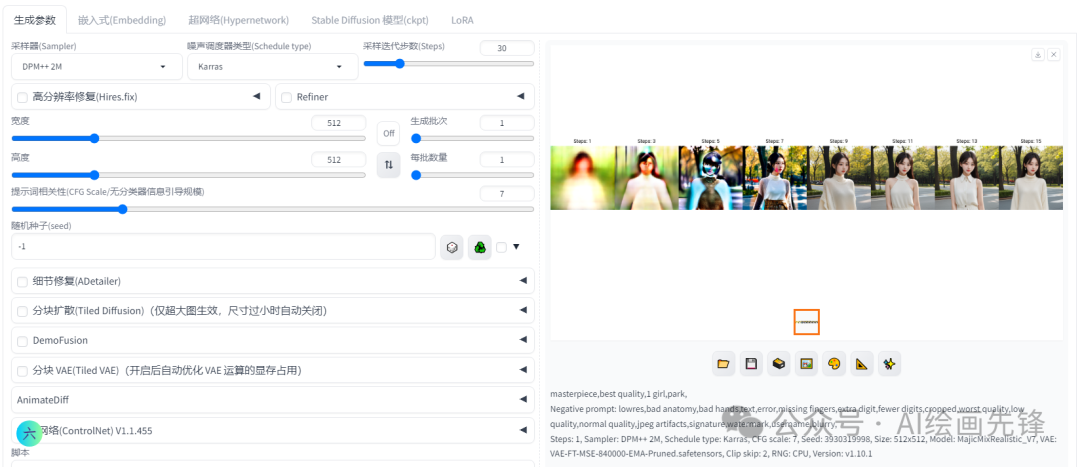
可以看到,当采样迭代步数为1时,画面呈现为一个纯粹的噪声图。随后,随着步数的逐渐增多,这些噪声开始慢慢汇聚、成形,最终演变成为一张完整的图片。

之前我们已经提到过,当你对某个生成效果感到满意时,可以点击那个环保的图标按钮来固定当前的随机种子。
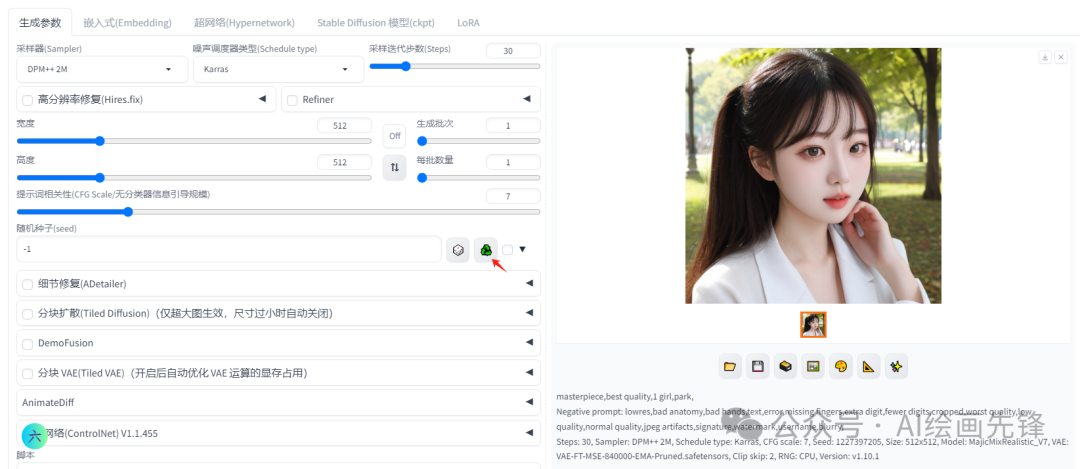
在硬件环境和参数设置保持不变的情况下,这样做可以确保你每次生成的图片都能达到99%的相似度。
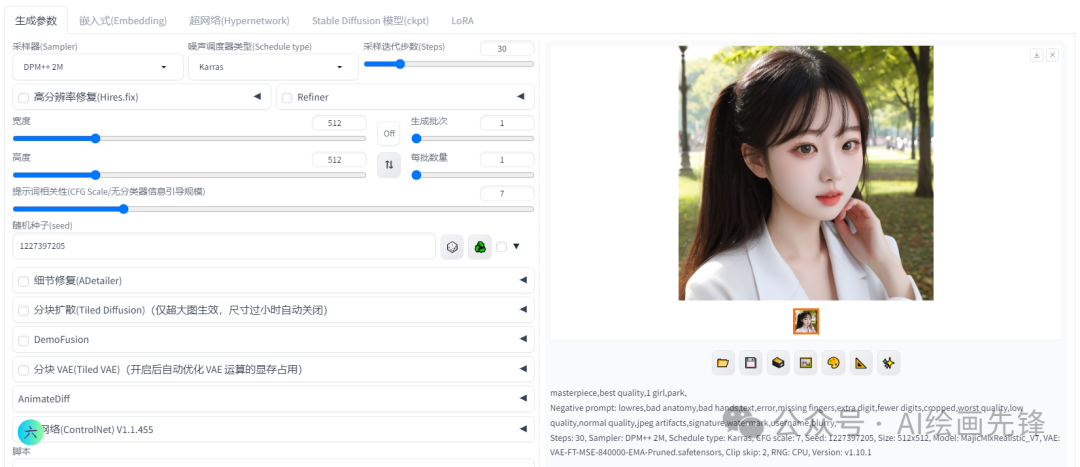
另外,如果你点击骰子按钮,随机种子的数值会变为-1,这意味着每次都会采用一个新的随机种子来生成图片。
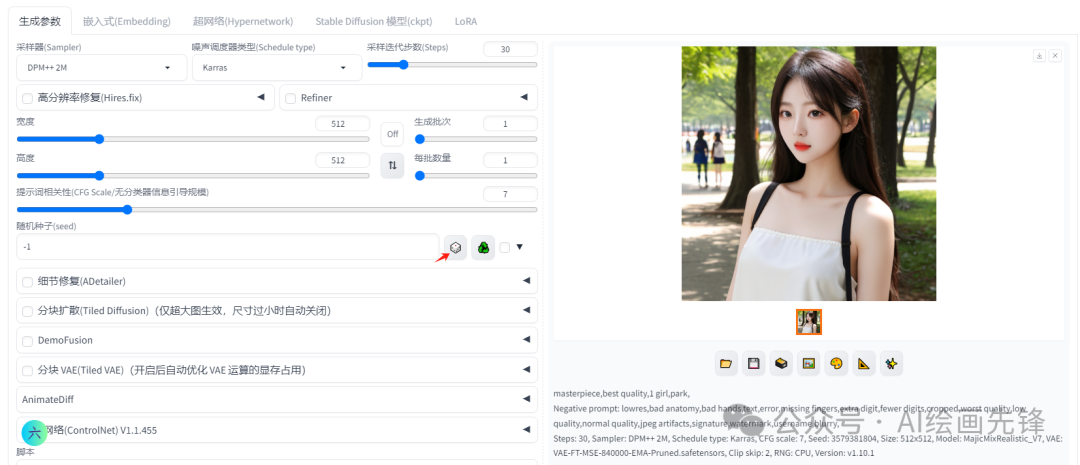
此外,激活倒三角旁边的按钮后,你还可以额外设置一个随机种子。通过调整差异强度,你可以将这两个种子的图片进行混合处理。
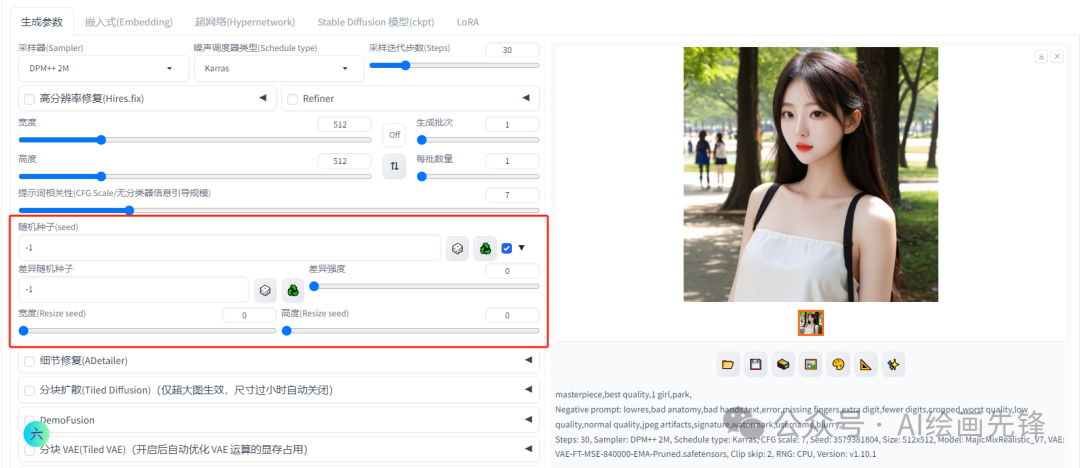
至于下面的宽度和高度选项,它们实际上是指定生成图片时按照你给出的分辨率进行构图或应用效果,但最终图片的分辨率仍然取决于你之前设置的出图分辨率。这个功能相对来说使用得比较少。
02
—
吉尼龟案例实践
上面详细讲述文生图的各项参数,现在我们把最开始做的吉尼龟做完,使用的提示词:一个吉尼龟,可爱,帽子,水,一个批次生成5张图片
正向提示词:terpiece,best quality,lsquirtle,cute,hat,water,
反向提示词:lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,
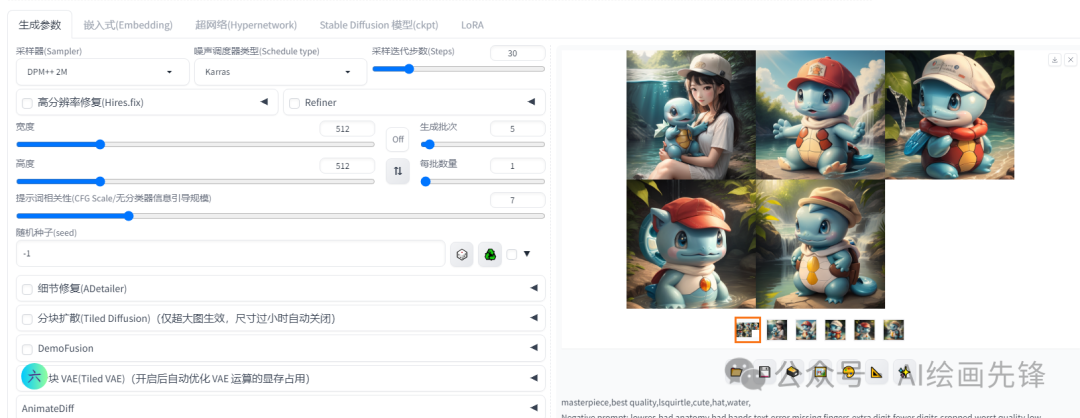
出问题了,生成出的图片多了个女孩,跟我们只想要一个吉尼龟不相符,可以通过正向提示词中加入“没有人类”进行控制。
同时为了避免翻车,反向提词里我输入了“NSFW(不适合在工作时间浏览的内容)”,权重为1.4:,再一个批次生成5张图片,选择一张比较满意的固定种子点:
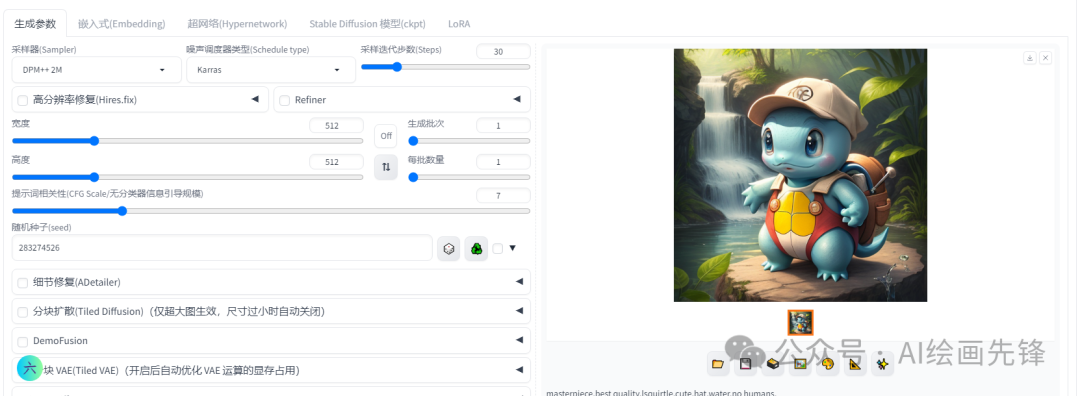
现在已经初步生成自己满意的吉尼龟形象,下面我们开始微调:
提词内首先把“一个吉尼龟,可爱,帽子,水”改成了“吉尼龟戴着绿色的帽子,红色眼睛,可爱,水”,角色用“chibi”,Q版形象,说明吉尼龟是一个Q版的,
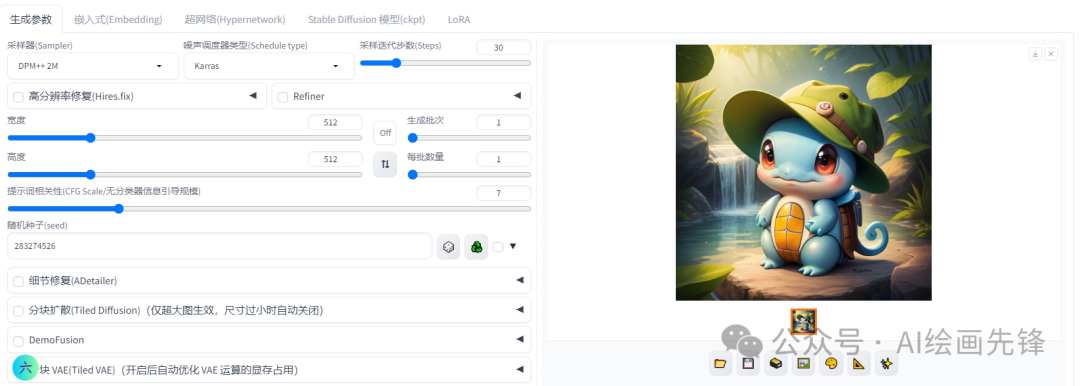
再加上“站立,张开短手臂,短腿,微笑”,说明吉尼龟的动作,一个Q版形象的吉尼龟已经画出来
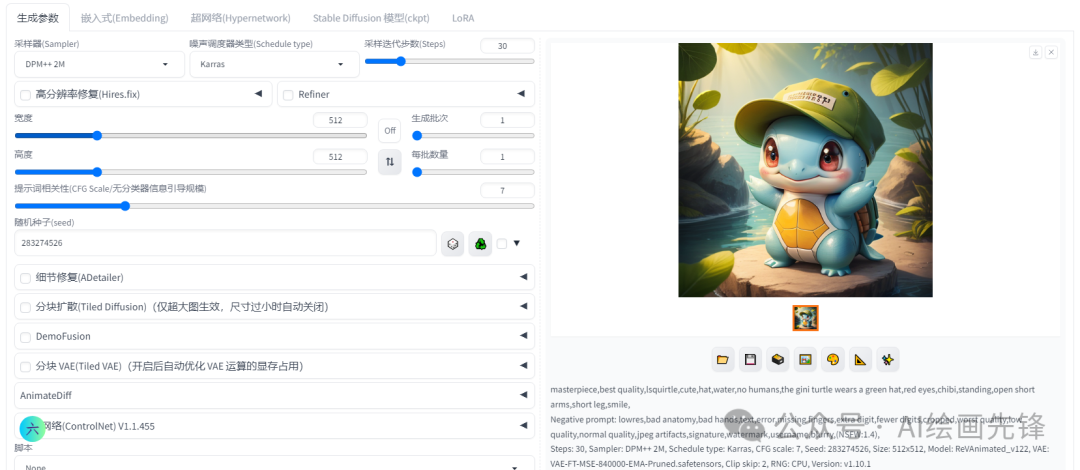
现在图片的分辨率是512*512,,打开高分辨率修复,扩大图片。放大算法使用R-ESRGAN 4x+,放大倍率:2倍,我想保持这个形象,重绘幅度使用0.3,不要太大重绘,先看下效果
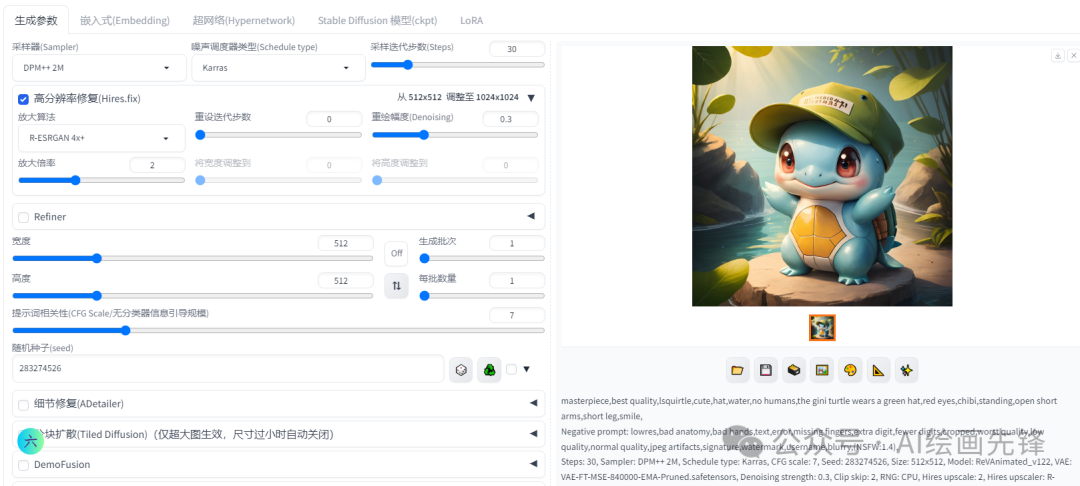

是不是挺不错,如果文生图的过程中出现“多手”、“多肢体”,可以在反向提示词中进行控制,调整提示词顺序,避免出现这种不好的现象!
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)