python的pandas.read_sql()函数
read_sql是Pandas提供的用于从数据库读取数据的方法。它允许我们执行SQL查询并将结果直接转换为DataFrame。版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/weixin_52908342/article/details/136119146。params:SQL查询中的参数
read_sql是Pandas提供的用于从数据库读取数据的方法。它允许我们执行SQL查询并将结果直接转换为DataFrame。下面我们将深入探讨read_sql的关键参数:
sql:SQL查询语句,必须提供。
con:数据库连接对象,可以是字符串(表示连接字符串)或SQLAlchemy引擎。
index_col:指定作为DataFrame索引的列。
parse_dates:指定需要解析为日期时间的列。
params:SQL查询中的参数,可以使用字典形式提供。
实例演示
假设我们有一个SQLite数据库,其中包含一张名为employees的表,结构如下:
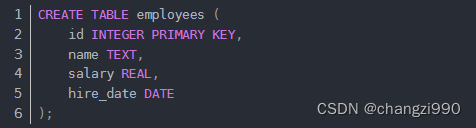
我们可以使用以下代码查询并将结果存储到Pandas DataFrame中:
import pandas as pd
from sqlalchemy import create_engine
# 创建SQLite引擎
engine = create_engine('sqlite:///example.db')
# 定义SQL查询语句
sql_query = 'SELECT * FROM employees'
# 使用read_sql读取数据
df = pd.read_sql(sql_query, con=engine)
# 打印结果
print(df)
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_52908342/article/details/136119146

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)