YAYI2学习资料汇总-新一代多语言开源大语言模型
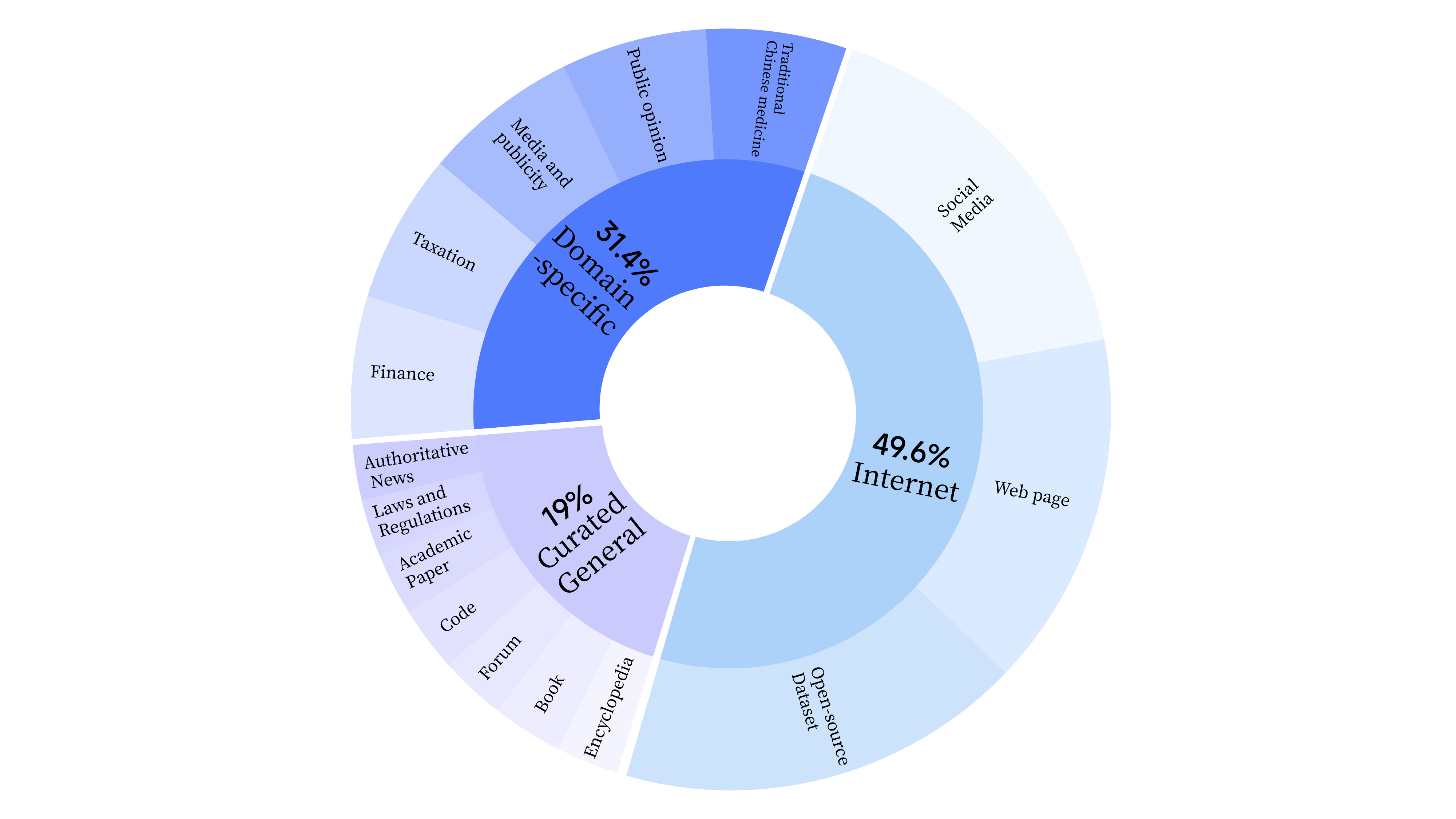
YAYI2是由中科闻歌研发的新一代开源大语言模型,包括Base和Chat两个版本,参数规模为30B。该模型基于Transformer架构,采用了超过2万亿Tokens的高质量多语言语料进行预训练,并通过百万级指令微调和人类反馈强化学习,实现了与人类价值观的对齐。YAYI2在多个基准测试中展现出了优异的性能,特别是在中文任务上表现突出。目前开源的是YAYI2-30B Base模型,Chat版本即将发
YAYI2简介
YAYI2是由中科闻歌研发的新一代开源大语言模型,包括Base和Chat两个版本,参数规模为30B。该模型基于Transformer架构,采用了超过2万亿Tokens的高质量多语言语料进行预训练,并通过百万级指令微调和人类反馈强化学习,实现了与人类价值观的对齐。
YAYI2在多个基准测试中展现出了优异的性能,特别是在中文任务上表现突出。目前开源的是YAYI2-30B Base模型,Chat版本即将发布。
学习资源
- 官方资源
- 模型下载
- Hugging Face: YAYI2-30B模型
- ModelScope: 魔搭社区模型下载
- 数据集
- 使用教程
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("wenge-research/yayi2-30b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("wenge-research/yayi2-30b", device_map="auto", trust_remote_code=True)
inputs = tokenizer('The winter in Beijing is', return_tensors='pt')
inputs = inputs.to('cuda')
pred = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
- 微调指南
YAYI2提供了全参数微调和LoRA微调两种方式,详细教程可参考GitHub仓库。
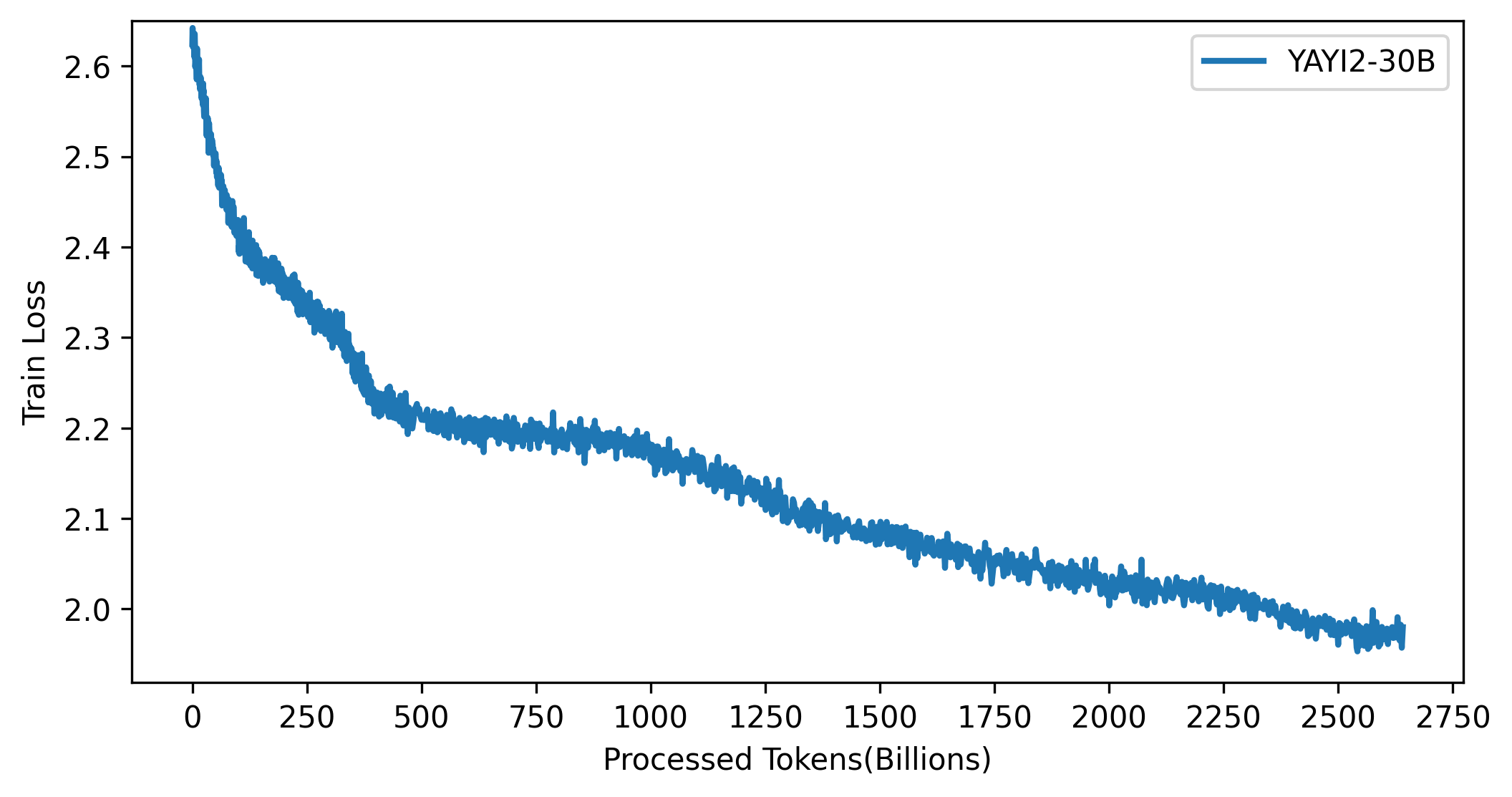
- 评测结果
YAYI2在多个权威基准测试中展现出优异性能,详细结果可查看评测章节。
总结
YAYI2作为一个强大的多语言开源大模型,为研究者和开发者提供了宝贵的资源。通过本文汇总的学习资料,相信读者可以快速上手并充分利用YAYI2的潜力,在各类NLP任务中取得优异成果。
文章链接:www.dongaigc.com/a/yayilanguage-model-resources
https://www.dongaigc.com/a/yayilanguage-model-resources

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 4
4 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)