内存网格hazelcast-IMap数据结构使用
分布式的项目中,由于对延时有较大要求,在对几种分布式内存组件的使用调研后,决定使用hazelcast作为分布式缓存,主要使用了组件提供的IMap数据结构,整理如下资料。Hazelcast Map( IMap) 扩展了接口java.util.concurrent.ConcurrentMap ,因此 java.util.Map,它是Java地图的分布式实现。可以使用众所周知的 get 和 put 方法
1.概述
分布式的项目中,由于对延时有较大要求,在对几种分布式缓存组件的使用调研后,决定使用hazelcast作为分布式缓存,主要使用了组件提供的IMap数据结构,整理如下资料。
hazelcast map
Hazelcast Map( IMap) 扩展了接口java.util.concurrent.ConcurrentMap ,因此 java.util.Map,它是Java地图的分布式实现。可以使用众所周知的 get 和 put 方法执行诸如从 Hazelcast Map读取和写入 Hazelcast Map等操作。
2.监控工具
Management Center
官方文档:https://docs.hazelcast.com/management-center/5.1/getting-started/overview
下载hazelcast-management-center-5.2.1.zip
运用map监控需要把自己用的快照实体的class放置在hazelcast的对应目录下
解压后,将对应jar包放置在 /bin/user-lib目录下
(为了解析我们存进去hazelcast集群的实体类)

nohup sh hz-mc start > hz-mc.log 2>&1 &
启动成功后
访问8080端口
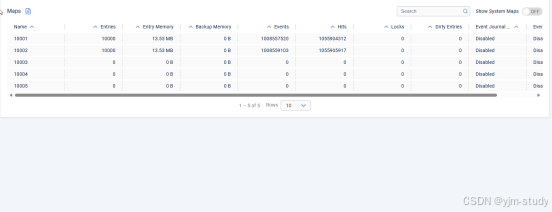
目前主要用到成员列表,客户端列表,和内存map查看功能
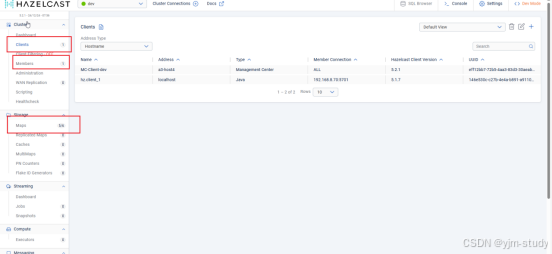
可以观察到2个通道分别有1万个快照,占用空间大小,以及更新了多少次
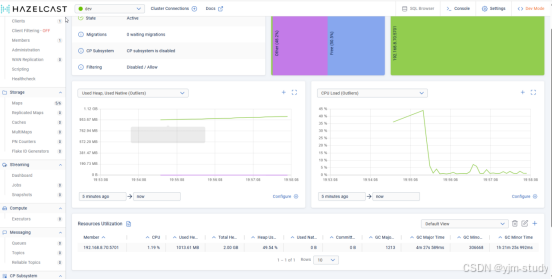
首页可以观察到成员的资源占用情况
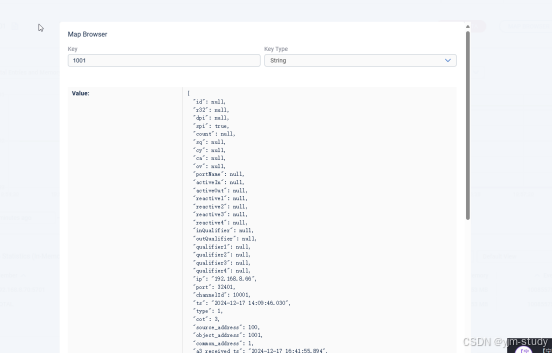
可以通过map控制台,查询某个内存map中的键值的实时快照值
3.hazelcast-map配置相关
backupCount
同步备份
同步备份是一种阻塞操作,为 Map 的默认备份方式。如果操作更改了 Map 的内容,则必须先将该更改写入主数据和所有备份,然后才能继续操作。这可以确保地图的主副本和备份副本之间的一致性,但会增加潜在的阻塞成本,从而可能导致延迟问题。
分布式 Map 默认有一个备份。如果有一个集群成员下线,则使用集群中备份恢复数据。
创建同步备份,使用 backup-count 属性设置备份副本的数量。
当 backup-count 为 1 时,Map 数据将在集群中的另一个成员上进行备份。 如果将其设置为 2,则 Map 数据将在另外两个成员上有其备份。 如果您不希望备份数据,您可以将其设置为 0,例如,如果性能比备份更重要。
备份计数的最大值为 6。
asyncBackupCount
异步备份
异步备份是非阻塞操作。一旦数据写入主副本,任何更改 Map 内容的操作都可以继续。备份副本将在稍后写入。
readBackupData
如果采用嵌入模式下使用 Hazelcast,读取 Map 数据可以从本地成员的本地备份中。通过这样做,本地成员不需要向主分区的所有者发出不必要的请求,从而减少了延迟并提高了性能。
要启用备份读取(读取本地备份条目),将属性值 read-backup-data 设置为 true。为了保持一致性,它的默认值为 false 。启用备份读取可以提高性能,但另一方面,它可能会导致读取到了过期的数据。
当至少有一个 同步备份 或 异步备份 时,备份读取功能可用。
timeToLiveSeconds
time-to-live-seconds,为每个条目在地图中停留的最长时间(以秒为单位)(TTL)。它限制了数据相对于上次对其执行写访问的时间的生命周期。
如果不为0,则生命周期超过此期限的数据(在此期限内没有对其执行任何写访问)将过期并自动驱逐。如果没有为单个数据提供特定的 TTL 值,它将继承为此元素设置的值。
time-to-live-seconds 默认值为 0,意味着没有过期,可接受的最大值为 Integer.MAX VALUE。
maxIdleSeconds
max-idle-seconds 默认值为 0,意味着没有过期,可接受的最大值为 Integer.MAX VALUE。
isOpenEvictionPolicy
是否开启驱逐策略
evictionMaxSizePolicy
max-size-policy 定义了测量 Map 最大值 的策略。
max-size-policy 所有策略如下:
策略名 描述
PER_NODE 每个集群成员的 Map 最大数据条数,这是默认策略
PER_PARTITION 每个分区的 Map 最大数据条数
USED_HEAP_SIZE 每个 Hazelcast 实例的每个 Map 的堆最大使用大小,单位M
USED_HEAP_PERCENTAGE 每个 Hazelcast 实例的每个 Map 的堆最大使用百分比
FREE_HEAP_SIZE 每个 JVM 的最小可用堆大小,单位M
FREE_HEAP_PERCENTAGE 每个 JVM 的最小可用堆百分比
USED_NATIVE_MEMORY_SIZE 每个 Hazelcast 实例的每个 Map 的最大已用本机内存大小,单位M,企业版可用
USED_NATIVE_MEMORY_PERCENTAGE 每个 Hazelcast 实例的每个映射的最大已用本机内存百分比,企业版可用
FREE_NATIVE_MEMORY_SIZE 每个 Hazelcast 实例的最小可用本机内存大小,单位M,企业版可用
FREE_NATIVE_MEMORY_PERCENTAGE 每个 Hazelcast 实例的最小可用本机内存百分比,企业版可用
evictionSize
驱逐 size 定义了 Map 数据大小的最大值,当达到最大大小时,根据 eviction-policy 元素的值删除Map 中的数据。
其有效值为 0 到 Integer.MAX VALUE 之间的整数。它的默认值为0,即没有驱逐,无限制。
如果要将此元素设置为 0 以外的任何大小,则还必须将其对应的 eviction-policy 属性设置为 NONE 以外的值。
evictionPolicy
eviction-policy 该元素定义当 Map 的大小大于 size 指定的值时要删除哪些数据。
eviction-policy 所有策略如下:
无 默认策略。如果设置,则不会驱逐任何项目并且 size 忽略该元素。
LRU 删除最近最少使用的 Map 数据
LFU 删除最不常用的 Map 数据
inMemoryFormat
设置的用于存储数据的内存格式会对应用程序的性能产生重大影响。当数据在客户端和 Hazelcast 集群之间或集群成员之间移动时,数据始终采用序列化(二进制)格式。
设置内存格式的目标是通过仅在必要时执行操作来最大限度地减少序列化的开销。
如果集群的大部分操作是读取 ( get) 和写入 ( put),则保持数据格式 BINARY 是最有效的。在 put 操作中,执行放置的应用程序将数据序列化以便通过网络传输。集群成员只需将接收到的数据写入映射,而不进行任何格式更改。在 get 操作中,集群成员返回所请求的映射条目的二进制副本。应用程序对返回的数据执行必要的反序列化。
但是,如果大多数集群操作都是查询,则反序列化开销就成为一个问题。查询必须针对对象运行,而不是针对二进制数据。通过以 OBJECT 格式存储经常查询的数据 ,在将数据添加到地图时会产生反序列化开销。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)