bytestoread有数据时也为0_数据挖掘--决策树模型挖掘商业信息
之前的市场购物篮分析只考虑了数据集中的商品信息,以发现购买物品之间的关联规则,没有考虑顾客的个人信息。假设把那些购买鱼、水果蔬菜的顾客称为“健康食品偏好者”。本文将继续利用该数据集以挖掘购买物品时什么人偏好“健康食品”。过程如下所示。Step 1 添加一个“变项文件”节点,利用"变项文件”节点读入BASKETS1n 数据集。加入一个“类型”节点,双击该节点,单击“读取值”,读入该数据集中字段的取值
之前的市场购物篮分析只考虑了数据集中的商品信息,以发现购买物品之间的关联规则,没有考虑顾客的个人信息。假设把那些购买鱼、水果蔬菜的顾客称为“健康食品偏好者”。本文将继续利用该数据集以挖掘购买物品时什么人偏好“健康食品”。过程如下所示。
Step 1
添加一个“变项文件”节点,利用"变项文件”节点读入BASKETS1n 数据集。加入一个“类型”节点,双击该节点,单击“读取值”,读入该数据集中字段的取值。观察所用数据会发现该数据集中购买的物品是用“T/F” 来标识是否购买,如下图所示。

如果“读取值”按钮能呈现灰色,可以先单击“清除所有值”按钮,再单击“读取值”按钮就可以读取了。
Step 2
因为该数据集中购买的物品是用“T/F" 来标识是否购买, 因此可以增加一个节点来标识那些“健康食品”。在该数据流中加入一个“导出”节点,双击“导出”节点,对“导出”节点进行设置,出现如下图所示对话框。

Step 3
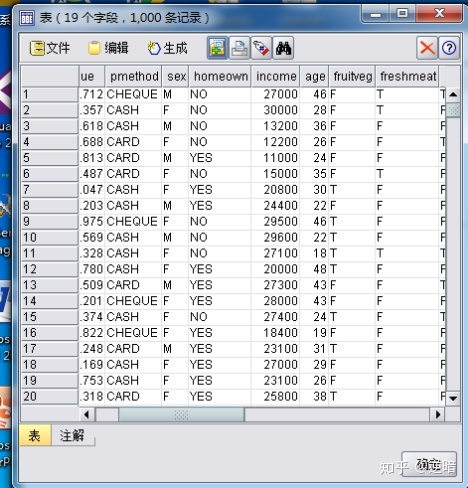
在“导出字段”文本框中重新将该节点命名为“Healthfood",“导出为”下拉列表中选择“标志”选项,“字段类型”下拉列表中选择“标志”选项。“以下情况时为真”文本框中输入"fruitveg= T and fish= T”,表示只选择那些既购买了fruitveg 又购买了fish的那些顾客的数据。单击“确定”按钮之后,可以再加入一个“表”节点,在该节点上单击鼠标右键,从快捷菜单中选择“执行(X)"命令。查看设置“导出”节点之后数据的变化情况,结果如下图所示。
Step 4
在该图中会发现多了一列字段“Healthfood"。它的取值是取fruitveg 和fish 的值的“并”,即如果fruitveg和fish 的值都是“T", 那么Healthfood的值也是“T” ,否则Healthfood
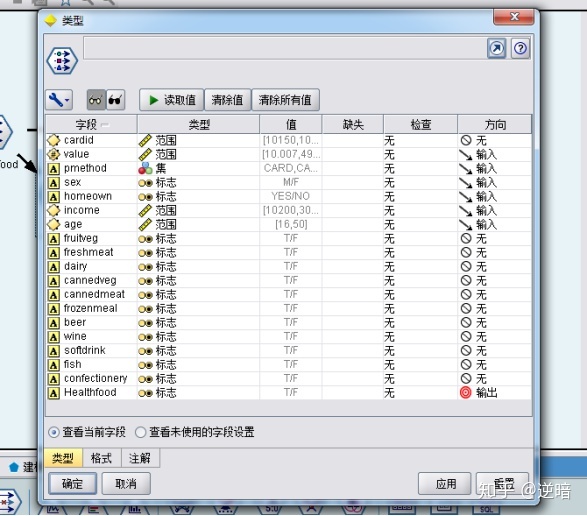
的值就是“F”。 加入“Healthfood"字段之后,在“导出”节点后再加入一个“类型”节点,用来选择哪些字段用来进行数据挖掘。根据挖掘的目标,可以设置个人信息为“输入”,“Healthfood"设置为“ 输出",设置情况如下图所示。
Step 5
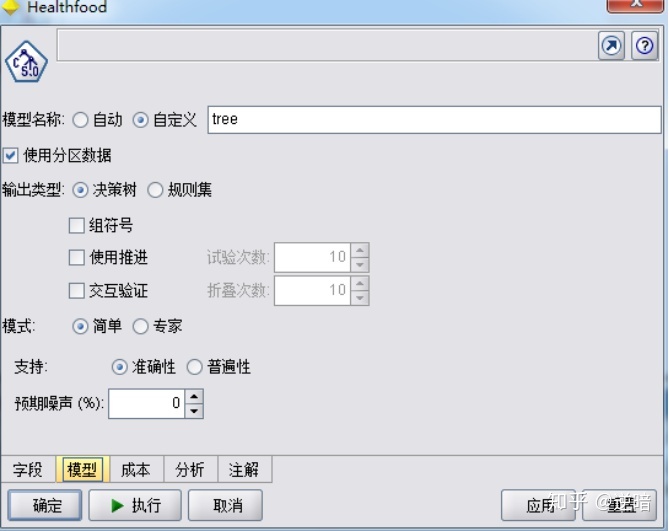
单击“确定”按钮,对挖掘字段设置完成。加入“建模(M)"中的决策树模型“C5.0"节点。双击该节点,对节点进行设置,如下图所示。
Step 6
选中“模型名称”文本框旁的“定制”单选按钮,输入生成结果的名称"tree", 其他设置保持不变。单击“执行(E)"按钮。在管理器窗口中,单击“模型(S)"按钮,发现出现了一个名称为"tree" 的结果。在其上单击鼠标右键,从快捷菜单中选择“浏览( B )"命令。
Step 7
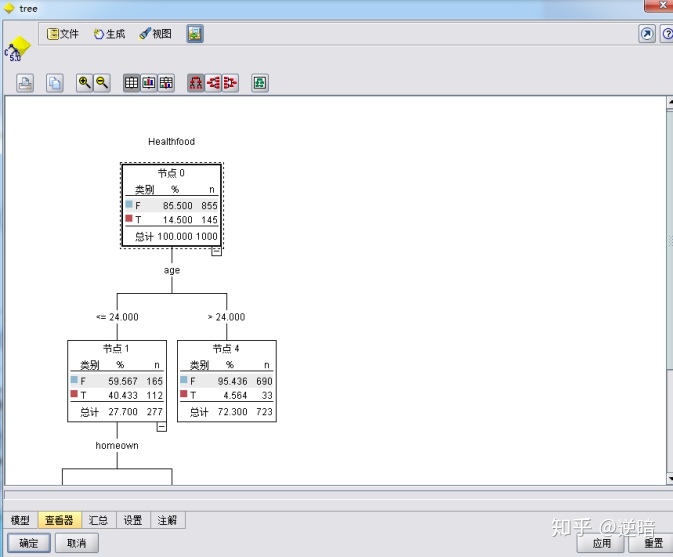
可以从“查看器”中查看该结果用树的形式表示出来的形状。单击“查看器”按钮,结果如下图所示。
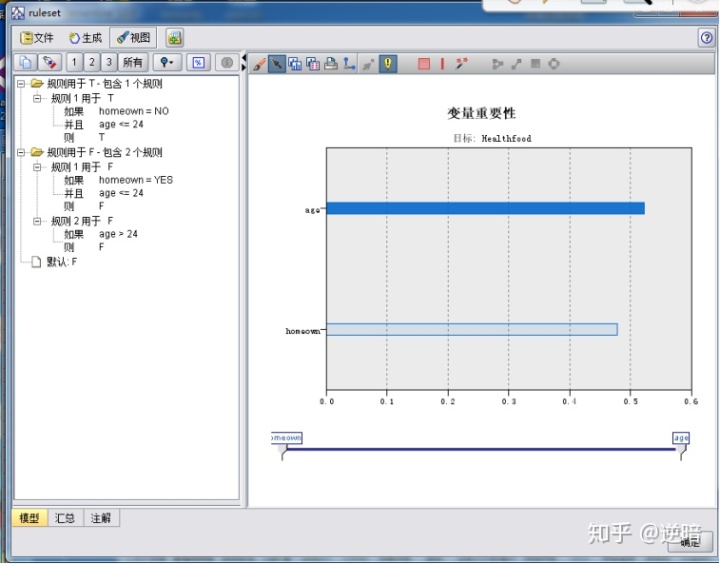
在上图中,输出类型除了选用“决策树”之外,还可以选择“ 规则集”来显示结果。用"规则集”表示的结果很多时候比“决策树”更加直观、易懂。下面来看用"规则集”表示的结果与“决策树”表示的结果有哪些不同。
Step 8
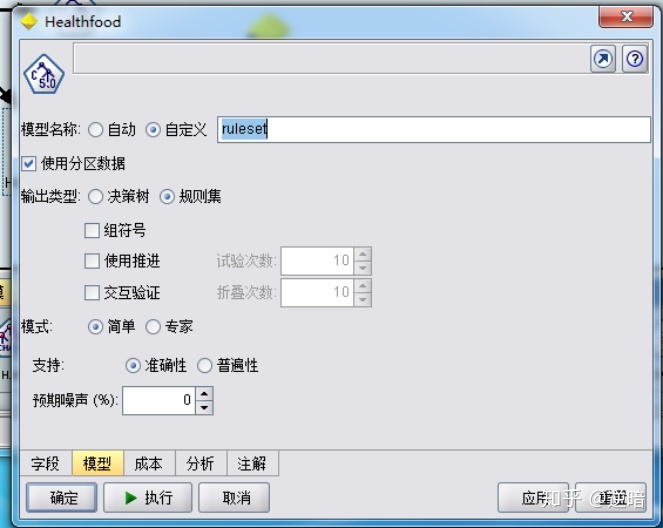
在之前的图中选择“规则集”单选按钮之后,在“模型名称”文本框中选中“定制”单选按钮,输入生成模型结果名称"ruleset", 单击“ 执行”按钮。在右面管理器窗口单击“模型”按钮,在"ruleset”上右击,从快捷菜单中选择“浏览”命令,结果显示如下图所示。
一般生成的决策树都是经过剪枝的。在之前的图中,默认选择的剪枝是剪枝75%。下面看看剪枝程,度的高低对挖掘结果的影响。
Step 9
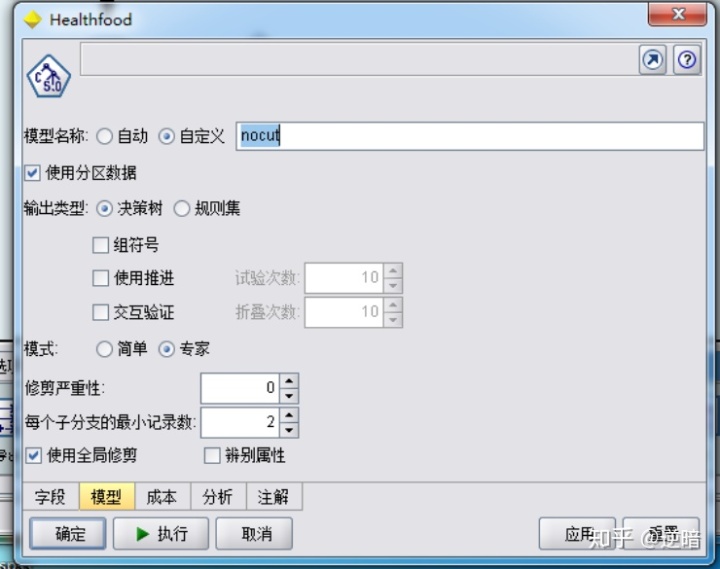
在之前的图中,选中“模式”区域中的“专家”单选按钮,把“修剪严重性”的值改为“0”,这意味着在挖掘过程中,进行的剪枝程度将很小。模型名称改为“nocut”, 设置结果如下图所示。
Step 10
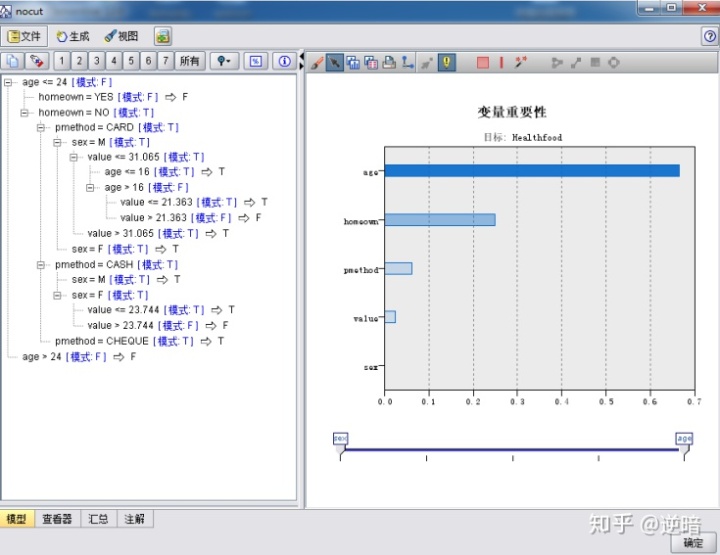
单击“执行”按钮。在右面管理器窗口中选中"模型(S)”,在"nocut” 上右击,从快捷菜单中选择“浏览”命令,查看生成模型结果,如下图所示。从该图中可以看出剪枝程度低的模型比剪枝程度高的模型复杂了很多,剪枝程度高的模型产生的树结果只有两层,而剪枝程度低的却有七层,而且运行的时间也比较长。
生成的以上3种结果,即利用剪枝程度较高的决策树、剪枝程度低的决策树、规则集生成的结果,可以通过Clementine系统提供的很多模型来进行精度测试。
Step 11
选用“分析”节点。在第二个“类型”节点后加入生成的"tree"模型,在"tree" 模型后加入“分析”节点。在刚刚加入的“分析”节点上右击,从快捷菜单中选择“执行”命令。生成的结果显示剪枝程度高的模型正确率为93.8%,如下图所示。
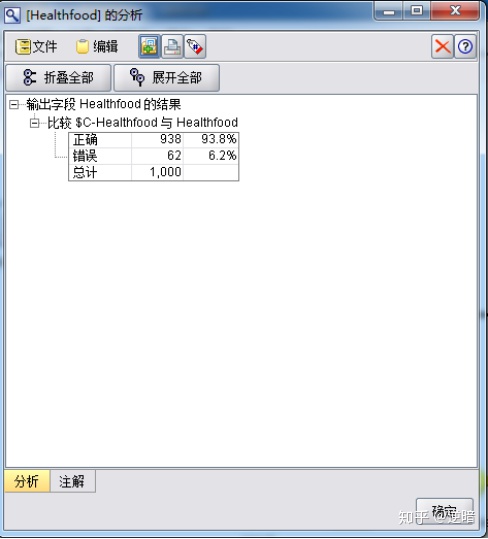
Step 12
同样的原理,测试"nocut", 结果如下图所示。
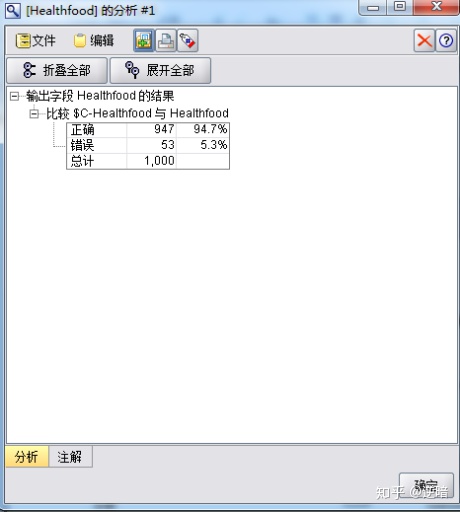
剪枝程度低的精度为94.7%,与剪枝程度高的精度相差不到一个百分点,因此在精度相差不大的情况下,我们首选那些结果模型简单、直观的模型来使用。所以,剪枝程度的高低可以使用精度的高低来作为一个评判的标准。
Step 13
同样的原理,测试"ruleset", 结果如下图所示。
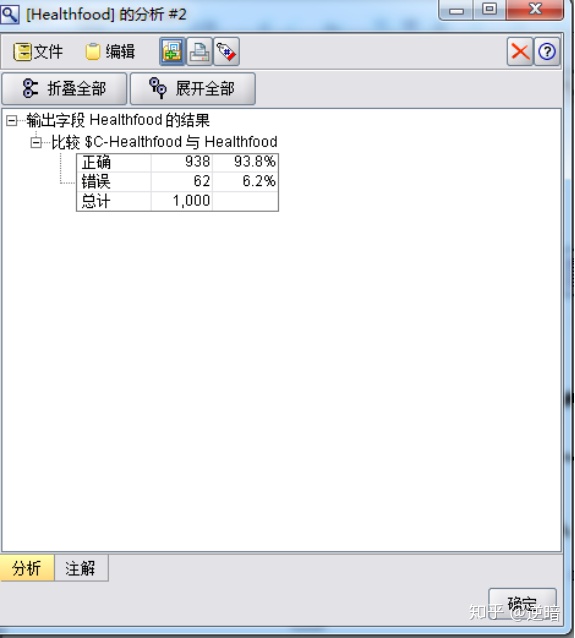
数据流如下图所示。
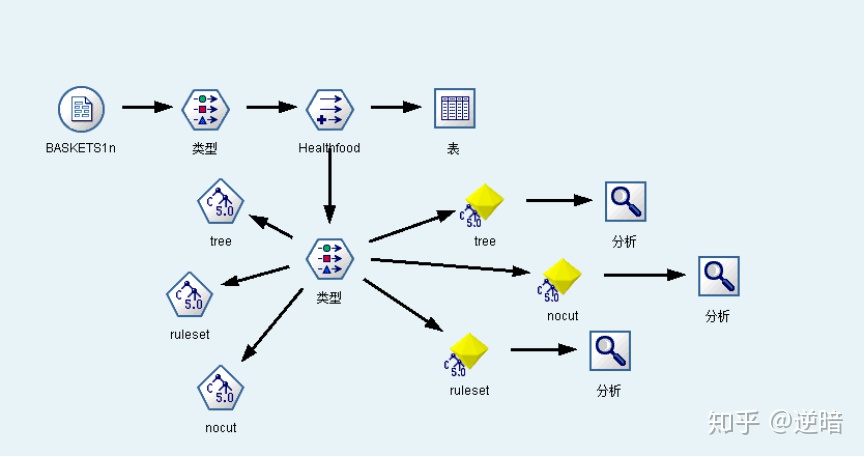
欢迎大家加入人工智能圈参与交流
人工智能学习圈 - 知乎www.zhihu.com

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)