数据结构 -Binary Search Tree -2
二叉搜索树,插入删除的递归写法

💡二叉搜索树
1. 前言
在C++ -Binary Search Tree -1中,我对二叉搜索树进行了简单的介绍,并简单模拟实现了一颗二叉搜索树。
其中,插入和删除操作都是完全用循环实现的,而本文,我将用递归实现这两个操作,并对比递归写法和循环写法的效率。
2. 插入
首先是插入的函数:
bool Insert(const K& key)
{
return _Insert(_root, key);
}
和前文保持一致,返回的是布尔值,这里需注意,不能直接用Insert来递归,不然需要在调用时显示的传递_root指针。因此更为方便的是封装一个_Insert函数。
private:
bool _Insert(Node*& root, const K& key)
{
这里注意传入的是指针的引用,这样改变root就是改变传入的指针:
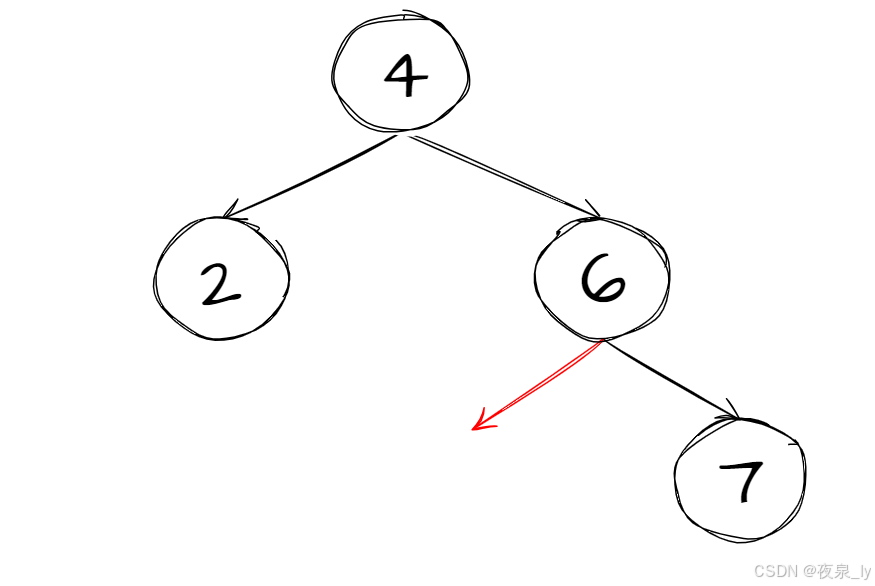
比如在上图中,要插入 5 ,现在走到红线的位置,此时的 root 就是 6 的左指针:
if (root == nullptr)
{
root = new Node(key);
return true;
}
因此可以将新节点直接给 root 。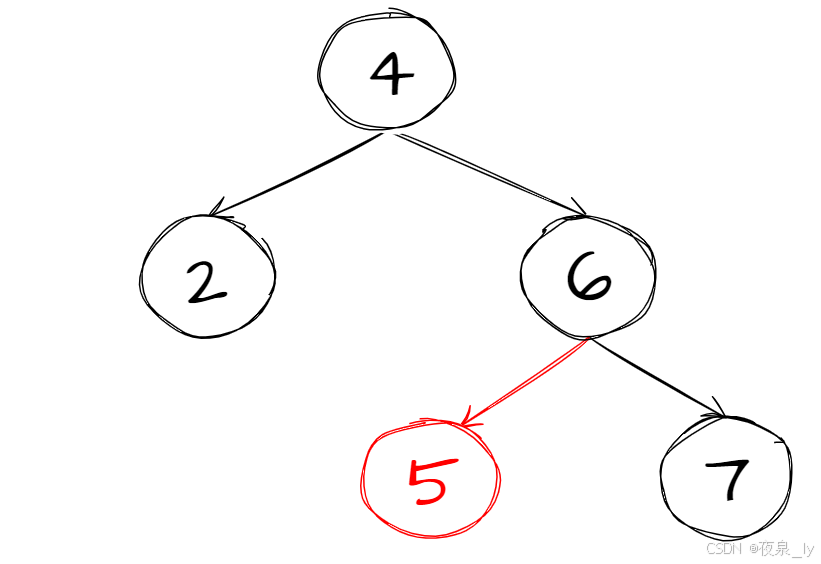
插入的主要操作就完成了,剩下的就是找到目标位置:
if (root->_key == key)
{
return false;
}
if (root->_key < key)
{
return _Insert(root->_right, key);
}
else
{
return _Insert(root->_left, key);
}
这里需要注意,递归时必须传入对应的指针,不能像下面这样传:
// if (root->_key < key)root = root->_right;
// else root = root->_left;
// _Insert(root, key);
}
上面这三句会导致树中最多只有一个节点。因为每次改变的都是root,而不是root的左/右子树。
3. 删除
接下来是删除操作,同插入一样,需要再封装一层函数:
bool Erase(const K& key)
{
return _Erase(_root, key);
}
参数还是设置为指针的引用:
bool _Erase(Node*& root, const K& key)
{
先走到待删除的位置:
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
_Erase(root->_right, key);
}
else
{
_Erase(root->_left, key);
}
在上篇文章中,我分析出删除时的情况可以分为两大类:
- 有空的左子树或右子树:


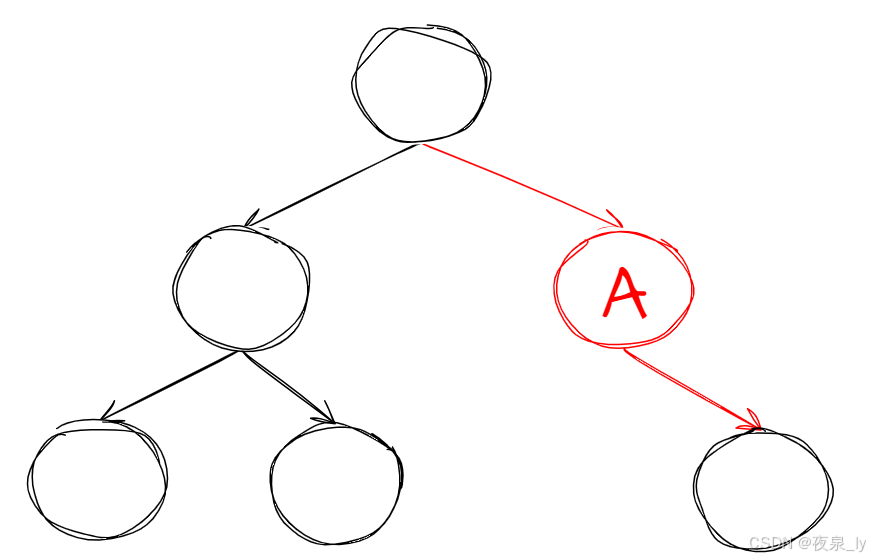
这种情况可以直接将A的子树交给父节点或_root。 - 左右子树都不为空:



这种情况需要先找到替代节点B后再删A。
先解决第一种情况:
if (root->_key == key)
{
if (!root->_left || !root->_right)
{
Node* tmp = root;
if (root->_left)
{
root = root->_left;
}
else
{
root = root->_right;
}
delete tmp;
return true;
}
原理如图: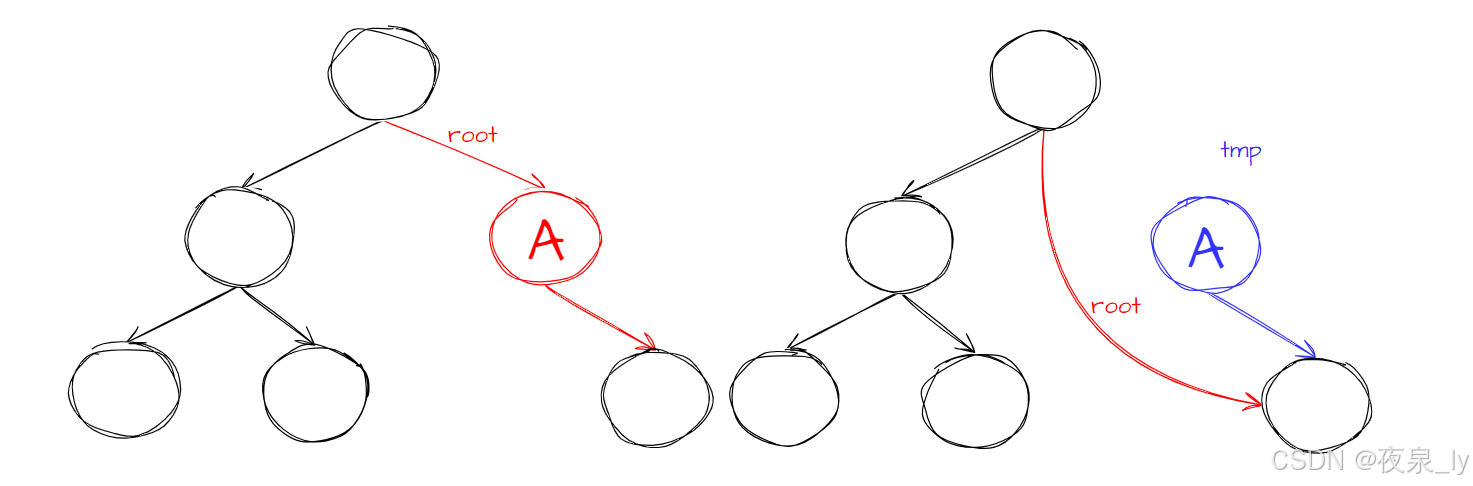
第二种情况:
else
{
Node* tmp = root->_left;
while (tmp->_right)
{
tmp = tmp->_right;
}
std::swap(tmp->_key, root->_key);
_Erase(root->_left, key);
}
}
}
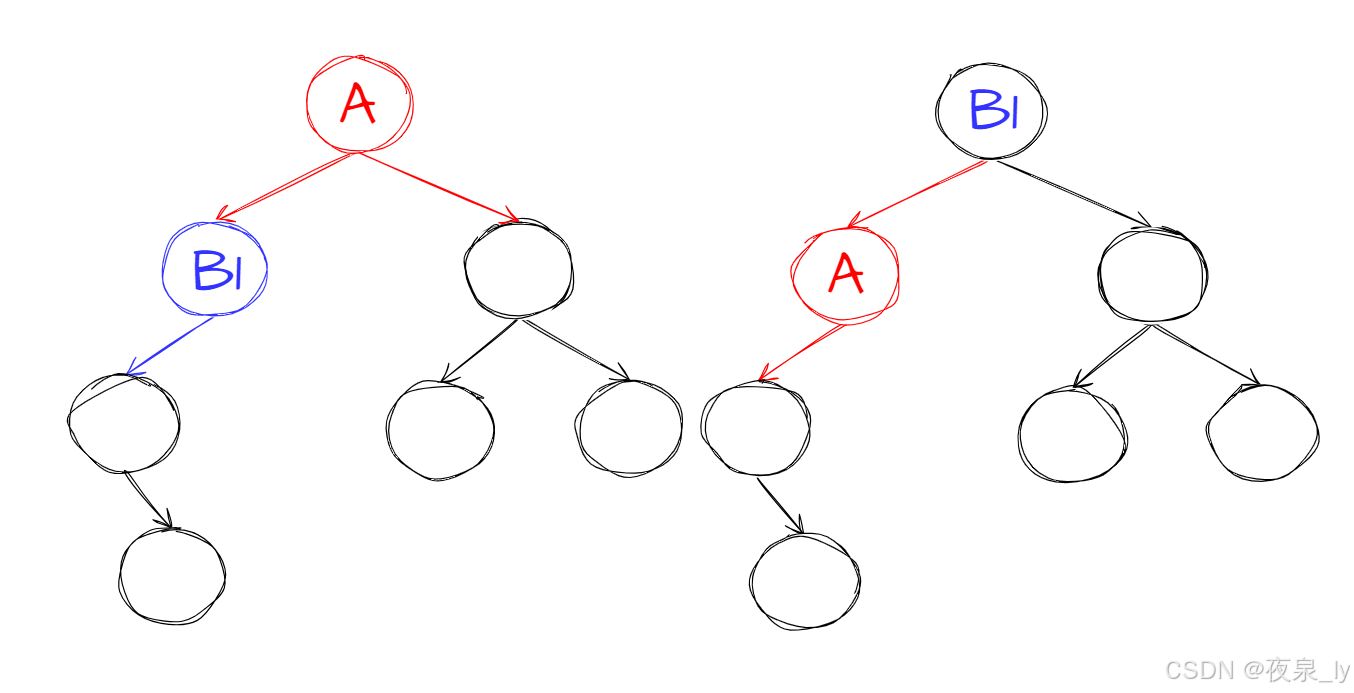
通过_Erase(root->_left, key);,将不断递归至情况一。
4. 效率对比
如果将本文的Insert、Erase与前文的相比,可以明显发现递归写法比循环写法简洁很多,但平时在实现时,最好还是写循环的写法。
这里我试着对比了一下两种写法的效率,将循环写法的树命名为BSTree_Iteration,将递归写法的树命名为BSTree_Recursion。(Iteration意为迭代,Recursion意为递归)
首先是插入随机数据:
void TestInsertRand()
{
BSTree_Iteration<int> Tree_I;
BSTree_Recursion<int> Tree_R;
srand(time(0));
vector<int> v;
int N = 10000000;
for (int i = 0; i < N; i++)
v.push_back(rand());
int Begin_I = clock();
for (int i = 0; i < N; i++)
Tree_I.Insert(v[i]);
int End_I = clock();
int Begin_R = clock();
for (int i = 0; i < N; i++)
Tree_R.Insert(v[i]);
int End_R = clock();
cout << "Insert_I :" << End_I - Begin_I << endl;
cout << "Insert_R :" << End_R - Begin_R << endl;
}
测的一千万个数据,运行了三次,结果如下图: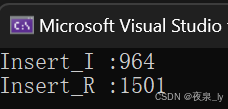
可以发现,递归已经有点慢了,但总的来说效率还行。
然后测试插入有序数列:
void TestInsertOrder()
{
BSTree_Iteration<int> Tree_I;
BSTree_Recursion<int> Tree_R;
int N = 10000;
int Begin_I = clock();
for (int i = 0; i < N; i++)
Tree_I.Insert(i);
int End_I = clock();
int Begin_R = clock();
for (int i = 0; i < N; i++)
Tree_R.Insert(i);
int End_R = clock();
cout << "Insert_I :" << End_I - Begin_I << endl;
cout << "Insert_R :" << End_R - Begin_R << endl;
}
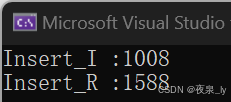
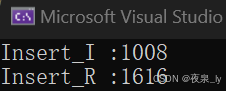
这里只测一万个数据,运行了三次,结果如下图: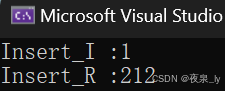
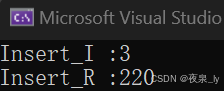
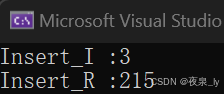
可以发现,如果是有序数列,递归写法的效率会大大降低,原因也不难理解: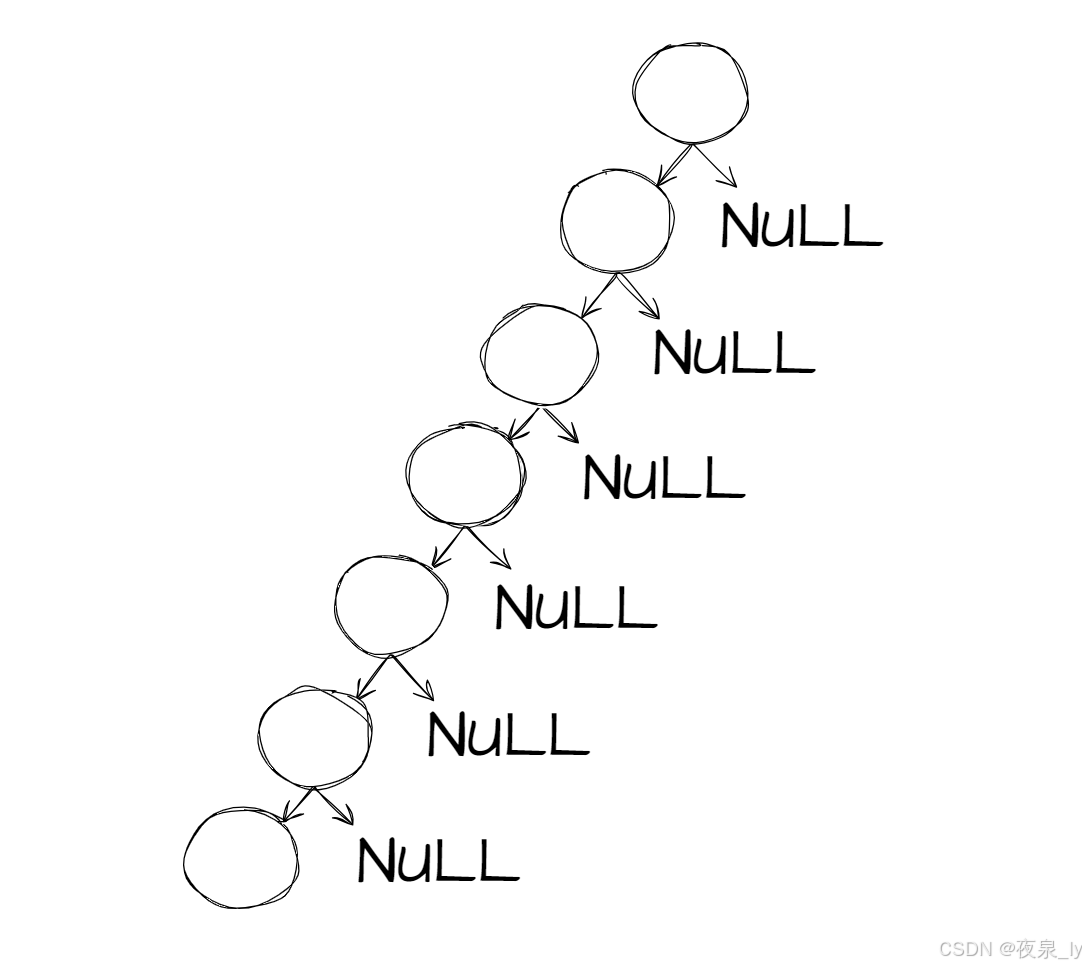
当数组有序,二叉搜索树只会在单侧插入,最后形成类似链表的极端情况,如果是递归,就会在插入过程中不断建立栈帧,使效率大大降低,如果数据量过大,还可能让程序崩掉。
因此在实际中,一般会对二叉搜索树进行优化,以避免极端情况的产生,而优化后的典型就是AVL树和红黑树。
5. 补充
还得补充一点,本文实现的二叉搜索树一般被称为K模型,即每个节点只存了一个 key ,这个 key 直接用于二叉搜索树的搜索, STL 的 set 就类似这种。
而二叉搜索树还有一种KV模型,即每个 key 对应了一个 value ,一般在存 key 时顺便存入value,搜索时也是搜索 key ,不过可以把value也带出来, STL 的 map 就类似这种。

希望本篇文章对你有所帮助!并激发你进一步探索编程的兴趣!
本人仅是个C语言初学者,如果你有任何疑问或建议,欢迎随时留言讨论!让我们一起学习,共同进步!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 62
62 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)