Excel实战 第1章 数据处理
数据处理
目录
1 数据规范
2. 导入数据
3. 数据清洗
3.1 重复数据处理
-
数据透视表法(首选)
选中A、B两列,点击【插入】–》【数据透视表】
把号码拉到【行】,这时候就给出了去重的结果,把【号码】拉到【行】标签的意思是按【号码】进行分组(即然是分组,就是去重后的结果,一个号码只有一个
再将【号码】拉入【 ∑ 值 \sum值 ∑值】(汇总区)进行计数,这就给出了每个号码出现的次数
对结果区右键,进行排序,选择降序,就可以看出 次数最多的号码,计数为 1 的代表不重复。
-
菜单删除法
第一步:选中数据区域
第二步:点击 【数据】-》【数据工具】–》【删除重复项】

这个方法可以给出去重的结果,但是不会给出那个【号码】重复了,不会给出重复了几次
- 条件格式标识法
第一步:选中【号码】列,单击【开始】–》【条件格式】–》【突出显示单元格规则】–》【重复值】

图中,重复的数据都被标红了
这个方法告诉你哪些数据重复了,但是,没有给你去重的结果、没告诉你重复了几次
-
高级筛选法
选中【号码】列,【数据】–》【筛选】边上的【高级】按钮
点击【将筛选结果复制到其他位置】,勾选【选择不重复的记录】,点击【确定】即可
给出了去重的结果,但是不会告诉你重复了几次
-
函数法(CountIF)
可以给出重复了几次
Range这个值,选择完之后,按F4固定,然后进行第 2 步操作
这个方法告诉你重复了几次,但是没有告诉你去重的结果
3.2 缺失数据处理
数据表中不能有合并单元格存在,将合并单元格拆分后,会出现很多空值,本节介绍空值补全
批量填充缺失的数据
取消合并单元格
定位条件:Ctrl+G或者F5,调出定位对话框,单击【定位条件】,
选择【空值】,
这时空值都被选中
然后按=,再按【向上箭头】
自动填充:Ctrl+Enter
就批量填充完毕
3.3 空格数据处理
3.3.1 Ctrl + H


3.3.2 Trim函数



4. 数据抽取
包括字段拆分(截取某一字段中的某一信息)和记录拆分(包括随机抽样、按某个分类字段进行记录分割)
4.1 字段拆分

Mid 是从字符串的中间第几位取几位字符,Left 和 Right 分别是从字符串的左边或右边取几位字符
假设【号码】的前 7 位是号段,包含特殊信息,需要提取
- 函数法
下面介绍 left 函数(right和left很类似,不做重新介绍)


Mid 函数

- 菜单法




更换为G1单元格

选择新的【目标区域】单元格,避免数据覆盖

没有多余列生成
4.2 随机抽样
本节介绍记录抽取的第2种方法,记录拆分
有 19648 个号码,从中随机抽取100个
首先,用Rand函数生成随机数
点击确定
双击小十字,完成批量计算
再用Rank函数进行排序
根据随机数进行排序,
双击小十字
完成
然后,再用填充的方式生成序列号
因为要抽取 100 个号码,就生成 1~100 的序列号,拖动小十字向下填充
直接松开的话,整列都是 1(相当于复制),松开鼠标前,点击 Ctrl ,就会变成1~100的序列

为了避免Rand函数每次点击鼠标都重新计算的问题,需要将其去公式(复制–>无公式粘贴值)。随机数和排名列都已经完成使命,所以我们将其去除公式,改为粘贴值的方式:

再用,Vlookup 函数进行匹配,进行随机抽样
0 代表精确匹配
5. 数据合并
5.1 字段合并
5.2 字段匹配
6. 数据计算

6.2 日期计算 Datedif
该函数在 EXCEL 函数库中无法查找,需要手动收入,
计算工龄,

回车后,双击 + 即可(批量完成),计算出工龄后,就可以进行工龄分布的分析,查看员工主要集中在什么分布

6.3 数据标准化
将数据按比例缩放,使之落入一个特定区间,消除不同量纲的不同

注意,F4 固定的作用在此体现,就是在点击 + 的时候(延续到整列),每行的计算都是选择这个范围。

再输入 右括号
回车
点击 + ,批量完成,最大值为 1,最小值为 0。注意,F4 固定的作用在此体现,就是在点击 + 的时候,每行的计算都是选择这个范围。
公式引用单元格,有“相对引用”与“绝对引用”
美元符号“ $ ”在excel公式中的作用是在“绝对引用”时,锁定行号或列标(单元格地址由列标+行号组成,如A1,A为列标,1为行号),“$”在哪个前边就锁定哪一个:
“A1”样式为“相对引用”,行号与列标都不锁定,横向拖动公式时,变为“B1”,竖向拖动公式时,变为“A2”;
“$ A$ 1”样式,锁定行号与列标,不管公式如何拖动,公式引用的$A$1都不会变化;
“$A1”样式,只锁定列标,公式竖向拖动时,引用变为“A$2”,横向拖动时,不变化;
“A$1”样式,只锁定行号,公式竖向拖动时,不变化,横向拖动时,引用变为“B$1”。
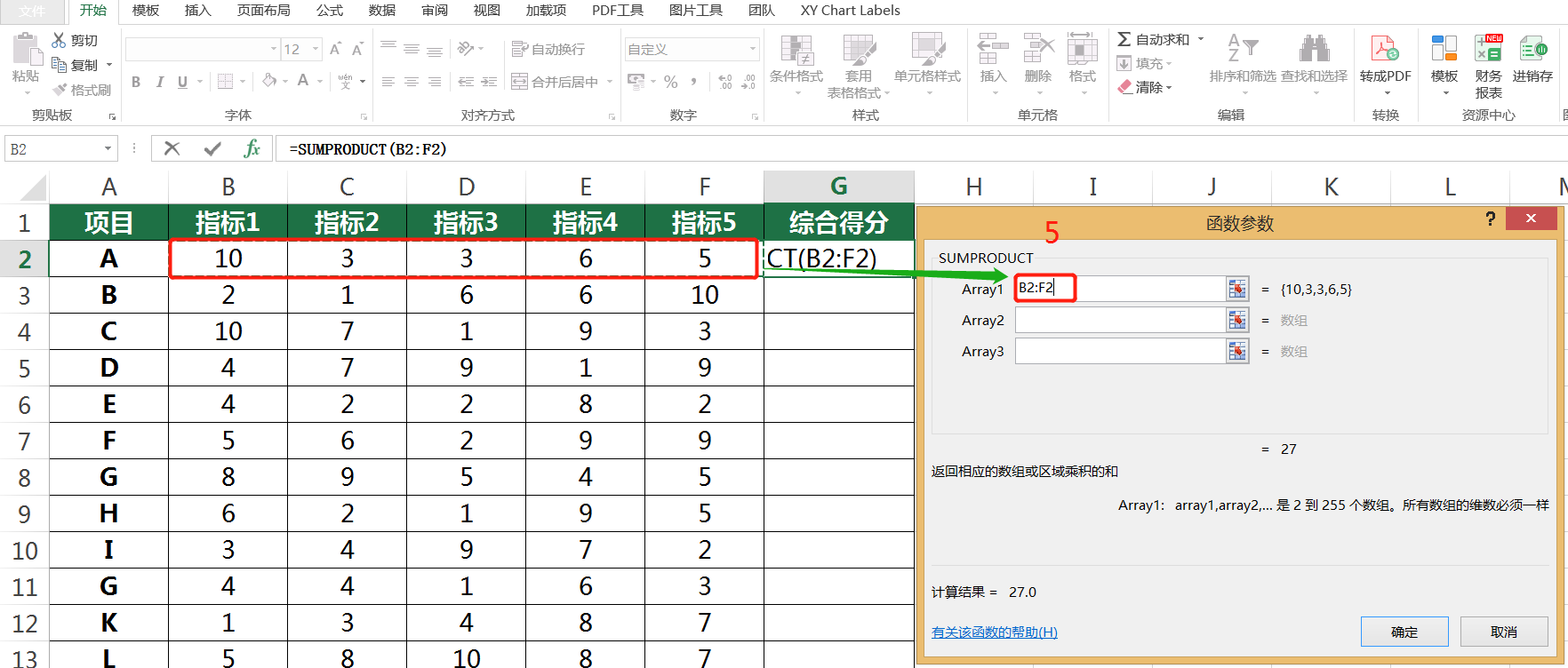
6.4 加权求和
某指标的权重,指该指标在整体评价体系中的相对重要程度,它表示,在其它结果不变的情况下,该指标的变化对结果的影响程度。
数据介绍

计算





6.5 数据分组1——IF函数
缺点
- IF 函数嵌套有层数限制(2007–2013为 64层,100层以上无法使用)








6.6 数据分组2——Vlookup函数
使用 Vlookup 函数时,首先要准备数据分组对应表,主要由阈值和分组标签组成,阈值需要进行升序排序(不是升序的话,结果不正确)。
模糊匹配:原理是查找区的首列,返回小于等于查找区的最大值,
下图为查找区,首列为【阈值】列,比如查找 35, 35 就是查找值,查找区的首列返回小于等于 35 的值中的最大值,下图中,小于等于 35 的有[0, 20],其中最大值为 20 ,且 20 对应的消费分组值为 [20, 40),恰好,35 就是在这个区间内。
下图分组标签为【消费分组】





魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)