python EDA_在Python中从头开始探索性数据分析(EDA)!
介绍探索性数据分析是当今数据科学中使用的最佳实践之一。在开始从事数据科学职业时,人们通常不知道数据分析与探索性数据分析之间的区别。两者之间并没有太大的区别,但是两者的目的不同。探索性数据分析(EDA):探索性数据分析是对推论统计的补充,推论统计通常倾向于使用规则和公式进行严格的处理。在高级方面,EDA涉及从不同角度查看和描述数据集,然后进行汇总。数据分析:数据分析是统计和概率,以确定数据集中的趋势

介绍
探索性数据分析是当今数据科学中使用的最佳实践之一。在开始从事数据科学职业时,人们通常不知道数据分析与探索性数据分析之间的区别。两者之间并没有太大的区别,但是两者的目的不同。

探索性数据分析(EDA):探索性数据分析是对推论统计的补充,推论统计通常倾向于使用规则和公式进行严格的处理。在高级方面,EDA涉及从不同角度查看和描述数据集,然后进行汇总。
数据分析:数据分析是统计和概率,以确定数据集中的趋势。它用于通过使用某些分析工具来显示历史数据。它有助于挖掘信息,将指标,事实和数据转化为改进计划。
探索性数据分析(EDA)
我们将探索一个数据集并进行探索性数据分析。涉及的主要主题如下:
–处理缺失值
–删除重复项
–离群值处理
–归一化和缩放(数字变量)
–编码分类变量(虚拟变量)
–双变量分析
#导入库

#加载数据集
我们将使用熊猫加载EDA汽车excel文件。为此,我们将使用read_excel文件。
#基础数据探索
在此步骤中,我们将执行以下操作以检查数据集所包含的内容。我们将检查以下内容:
–数据集的开头–数据集
的形状–数据集的
信息
– 数据集的摘要
- 头函数将告诉您数据集中的最高记录。默认情况下,python仅显示前5条记录。
- shape属性告诉我们数据集中的许多观测值和变量。用于检查数据的维数。汽车数据集包含303个观测值和13个变量。

- info()用于检查有关数据和每个属性的数据类型的信息。
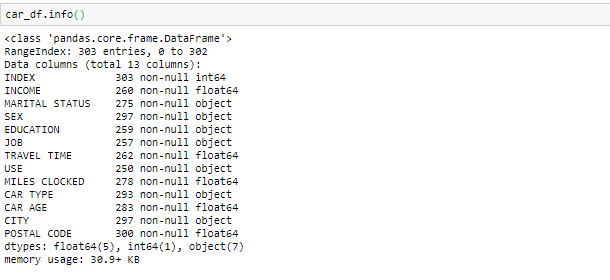
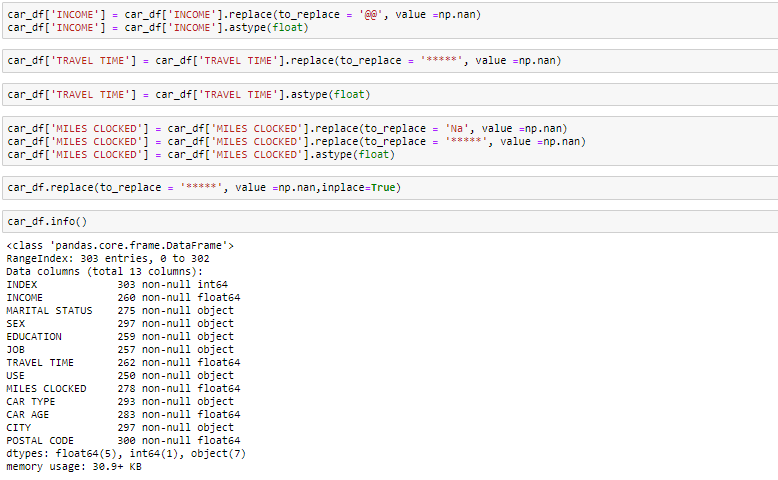
查看head函数和info中的数据,我们知道变量Income和travel time是float数据类型而不是object。因此,我们将其转换为浮点数。此外,数据中还有一些无效值,例如@@和' * ',我们将其视为缺失值。
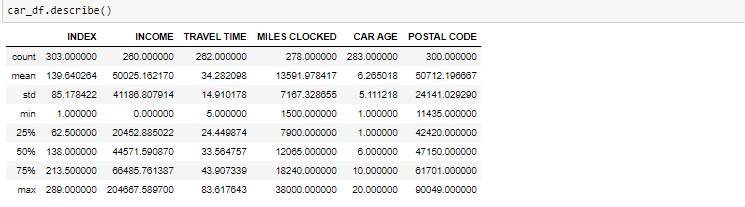
- 所描述的方法将有助于查看数据如何扩展为数值。我们可以清楚地看到最小值,平均值,不同的百分位数值和最大值。
处理缺失值
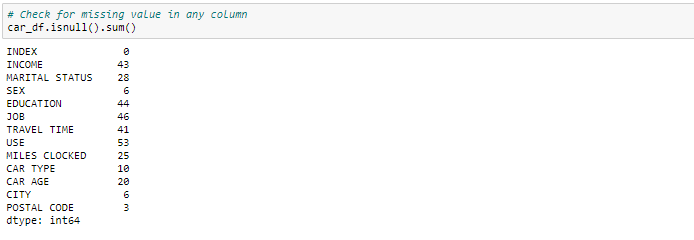
我们可以看到在相应的列中有各种缺失值。有多种方法可以处理数据集中的缺失值。而何时使用哪种技术实际上取决于您要处理的数据类型。
- 删除缺失值:在这种情况下,我们从那些变量中删除缺失值。如果缺少的值很少,则可以删除这些值。
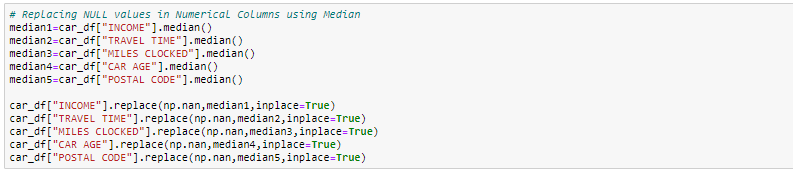
- 用平均值估算:对于数字列,您可以用平均值替换缺失值。在用平均值代替之前,建议检查变量不应具有极高的值,即离群值。
- 用中值估算:对于数字列,您也可以用中值替换缺失值。如果您有极端值(如离群值),建议使用中位数法。
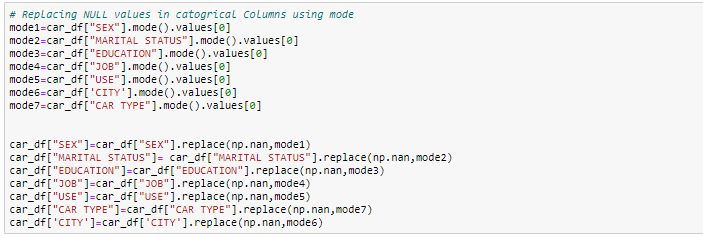
- 带模式值的插补:对于类别列,您可以将缺失值替换为模式值,即频繁的值。
在本练习中,我们将数字列替换为中值,对于分类列,我们将删除缺失值。

处理重复记录
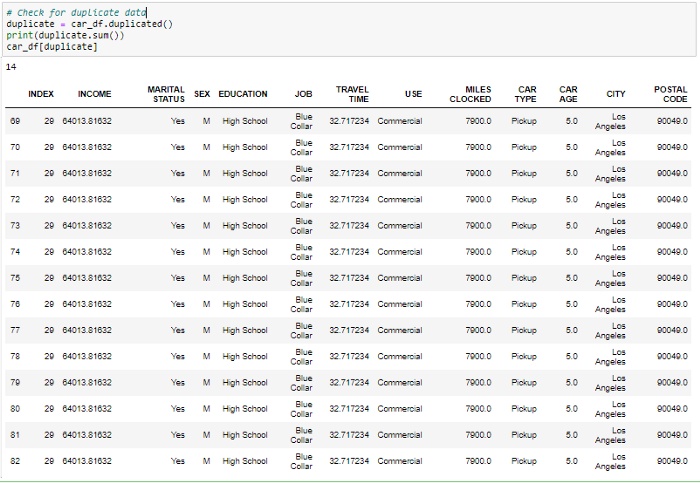
由于数据中有14条重复记录,因此我们将从数据集中删除该记录,以便仅获得不同的记录。删除重复项后,我们将检查重复项是否已从数据集中删除。


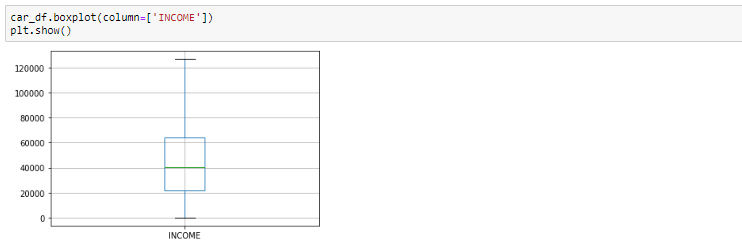
处理异常值
作为最极端观察值的异常值可能包括样本最大值或样本最小值,或两者都包括,这取决于它们是极高还是极低。但是,样本的最大值和最小值并不总是离群值,因为它们可能与其他观测值相距不远。
通常,我们借助boxplot识别异常值,因此此处的box plot显示了数据范围之外的一些数据点。
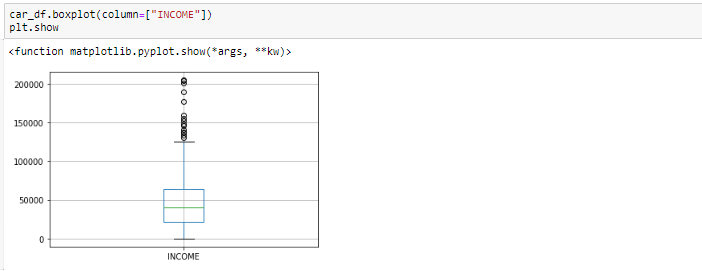
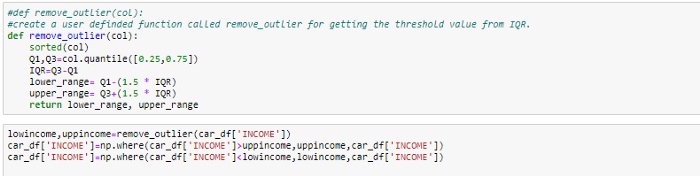
从箱形图中可以看出,变量INCOME似乎存在异常值。这些异常值需要加以了解,并且有几种处理方法:
- 降低离群值
- 使用IQR替换离群值
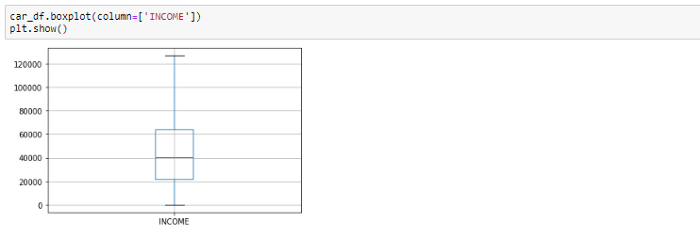
#Boxplot移除异常值后
双变量分析
当我们谈论双变量分析时,它意味着分析2个变量。由于我们知道存在数值和分类变量,因此有一种分析这些变量的方法,如下所示:
- 数值与数值
1.散点图
2.线图
3.相关的热
图4.联合图 - 分类与数值
1.条形图
2.小提琴图
3.分类箱图
4.群图 - 两个分类变量
1.条形图
2.分组条形图
3.点图
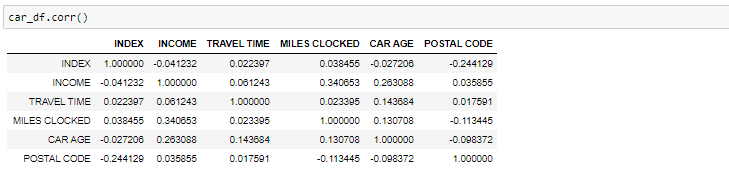
如果我们需要找到相关性,
规范化和缩放
通常,数据集的变量具有不同的标度,即一个变量以百万计,而其他变量仅以100为例。例如,在我们的数据集中,收入的成千上万的值和年龄只有两位数。由于这些变量中的数据具有不同的比例,因此很难比较这些变量。
特征缩放(也称为数据规范化)是用于标准化数据特征范围的方法。由于数据值的范围可能相差很大,因此它成为使用机器学习算法时数据预处理的必要步骤。
在这种方法中,我们将具有不同比例尺的变量转换为单个比例尺。StandardScaler使用公式(x-均值)/标准差对数据进行归一化。我们将仅对数字变量执行此操作。
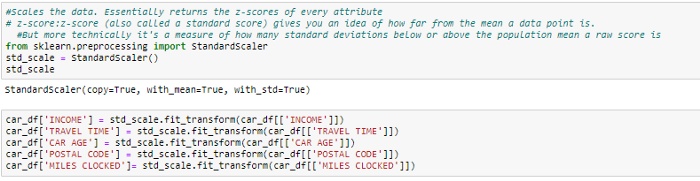
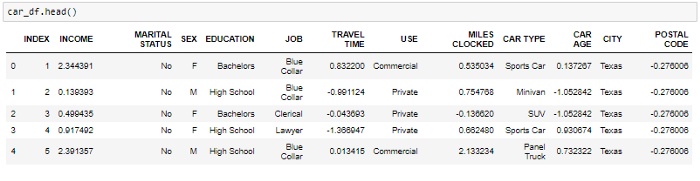
编码
“一键编码”用于创建伪变量,以将分类变量中的类别替换为每个类别的特征,并根据记录中是否存在分类值使用1或0表示它。
由于机器学习算法仅对数值数据起作用,因此需要这样做。这就是为什么需要将分类列转换为数字列的原因。
get_dummies是为每个分类变量创建一个虚拟变量的方法。

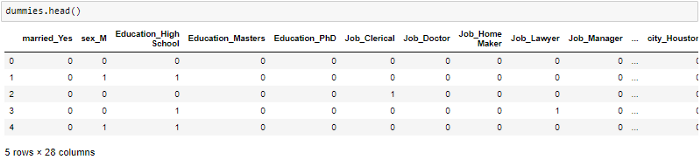
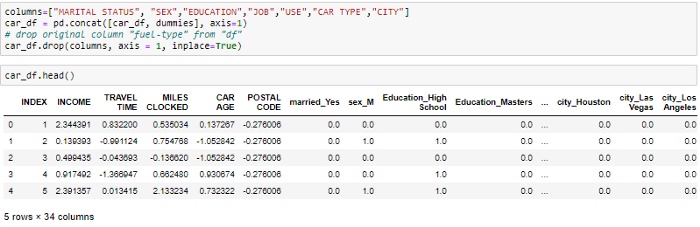

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)