【R语言】沈阳地铁数据处理及站间流量统计——R语言第五次实训
title: “R语言第五次实训”output: html_notebook题目一:1读数据df <-read.csv("D:\\张志浩\\大数据班\\R语言实验-徐娇\\R第5次实训\\数据\\SY-20150401.csv")2处理数据字段修改数据的字段名colnames(df)colnames(df) <- c('card.id','date','time...
·
title: “R语言第五次实训”
output: html_notebook
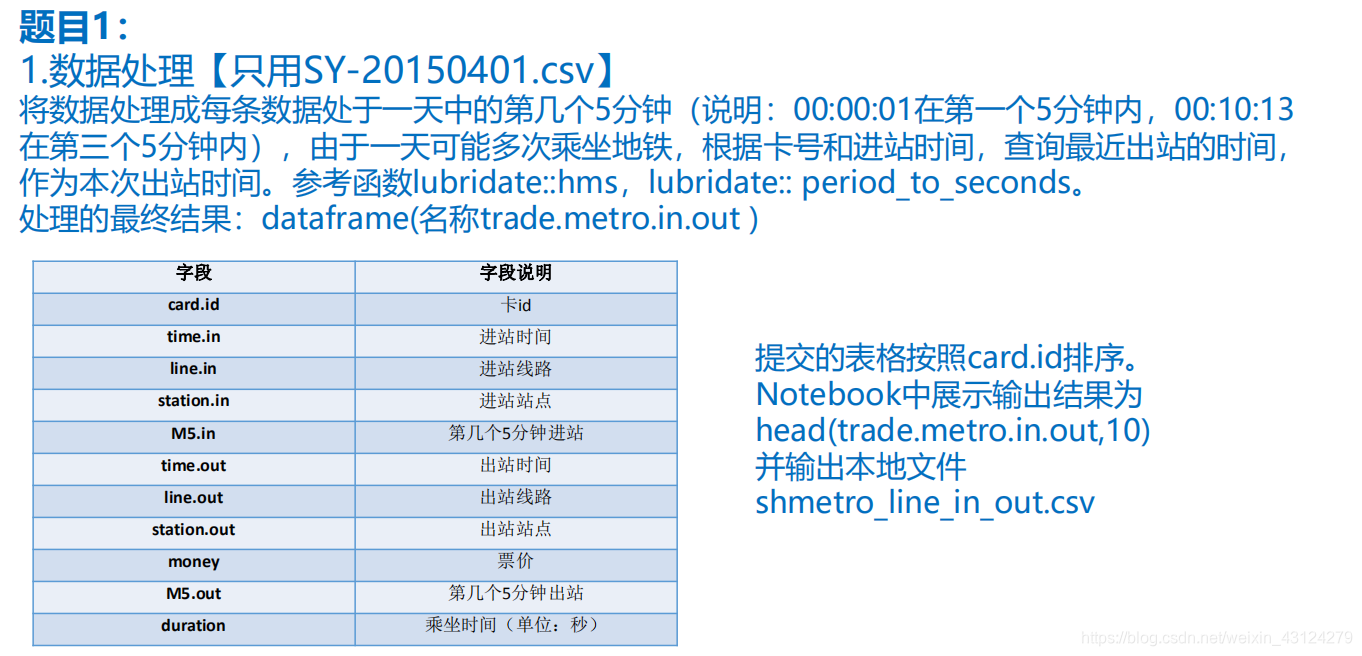

题目一:
1读数据
df <-read.csv("D:\\张志浩\\大数据班\\R语言实验-徐娇\\R第5次实训\\数据\\SY-20150401.csv")
2处理数据字段
修改数据的字段名
colnames(df)
colnames(df) <- c('card.id','date','time','station','vehicle','money','property')
colnames(df)
3取出数据中是地铁的刷卡数据
trade.metro<-df[df$vehicle=="地铁",]
4将station分成2个字段line和station,利用‘号线’来分割;处理每5分钟一段,并按M5排序
导入包
# install.packages("tidyr")
library(tidyr)
trade.metro<-separate(trade.metro ,station, c('line', 'station'), sep = '号线')
head(trade.metro)
library(dplyr)
library(lubridate)
按五分钟统计时间,向上取整
trade.metro <- trade.metro %>%mutate(M5=ceiling(period_to_seconds(hms(time))/300))
head(trade.metro)
5进站数据统计(进站时money==0)
trade.metro.in <- trade.metro %>%
filter(money==0) %>%
select(card.id,"time.in"=time,"line.in"=line,"station.in"=station,"M5.in"=M5)
head(trade.metro.in)
6出站数据统计(出站时money>0)
trade.metro.out <- trade.metro %>%
filter(money>0)%>%
select(card.id,"time.out"=time,"line.out"=line,"station.out"=station,money,"M5.out"=M5)
head(trade.metro.out)
7根据card.id将5和6合并;并计算乘车时长;将乘车时长大于0的取出来
trade.metro.in.out <-
merge(trade.metro.in, trade.metro.out, by = "card.id") %>%
mutate(duration = (period_to_seconds(hms(time.out)) - period_to_seconds(hms(time.in)))) %>%
filter(duration > 0)
head(trade.metro.in.out)
8通过card.id, M5.in来统计出某个card.id的最短的乘车时长然后通过duration==duration_min,将最近出站时间,找出来再将中间的统计量去掉
trade.metro.in.out <- data.table(trade.metro.in.out)
trade.metro.in.out[, duration_min := min(duration), by=list(card.id, M5.in)]
trade.metro.in.out <- trade.metro.in.out %>%
filter(duration==duration_min) %>%
select(-duration_min)
head(trade.metro.in.out)
9按照card.id来排序,并展示前10条
trade.metro.in.out<-trade.metro.in.out[order(trade.metro.in.out$card.id),]
# trade.metro.in.out <- arrange(trade.metro.in.out,card.id)
head(trade.metro.in.out,10)
10将处理后的数据输出
write.csv(trade.metro.in.out,"shmetro_line_in_out.csv",row.names = F)
题目2:
1利用1中的处理结果,按照station.in,station.out来分组,统计各组的数量
trade.metro.in.out <- data.table(trade.metro.in.out)
a <- trade.metro.in.out[,.(passenger.flow=.N), keyby=.(station.in,station.out)]
# aggregate(trade.metro.in.out, by=list(in1=trade.metro.in.out$station.in,out=trade.metro.in.out$station.out), nrow)
head(a,10)
2按照进出站的流量排序,取出前10个
a<-a[order(a$passenger.flow,decreasing = TRUE),]
b<-a[1:10,]
3展示前6个
head(b,6)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)