【数据结构】18.图(Graph)
图的基本概念、存储结构、遍历与常用算法
一、图的基本概念
1.1 图的定义
图是由顶点集V和边集E组成,记作G=(V, E) G:Graphic 图形 V:Vertex 顶点 E:Edge 边
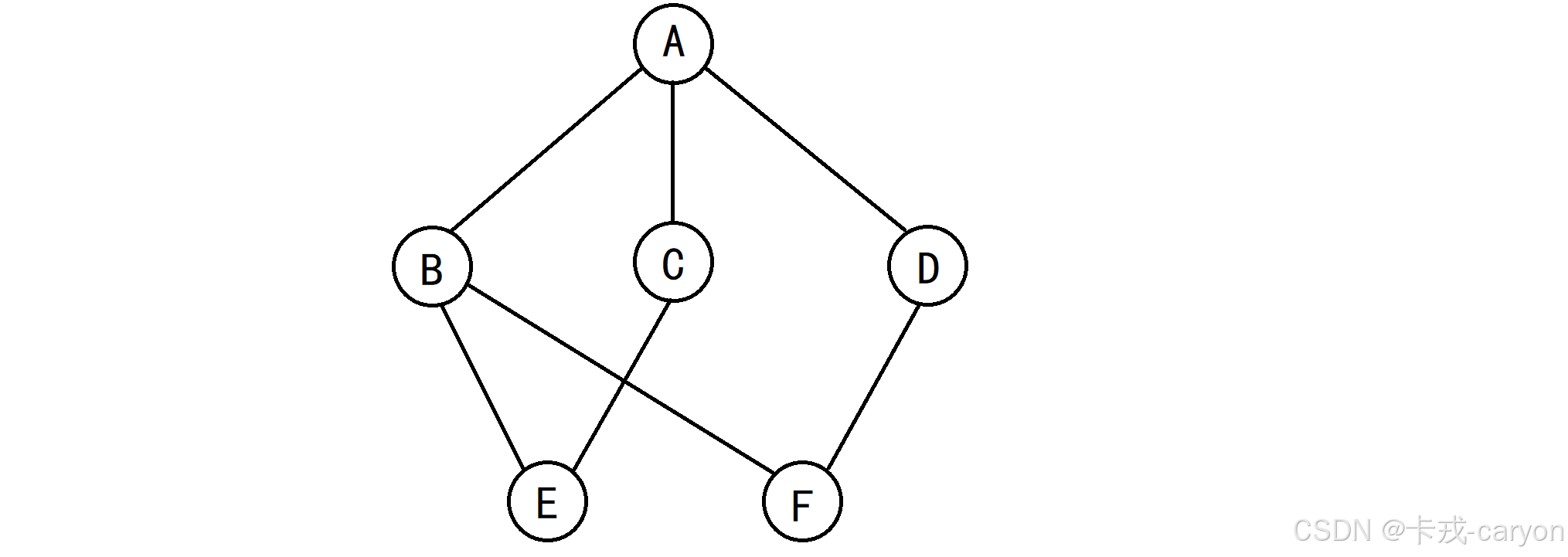
注意:线性表可以是空表,树可以是空树,但图不可以是空图。就是说,图中不能一个顶点也没有,图的顶点集V一定非空,但边集E可以为空,此时图中只有顶点而没有边。
1.2 有向图与无向图
如果边是有方向的则称为有向图,如果边没有方向则称为无向图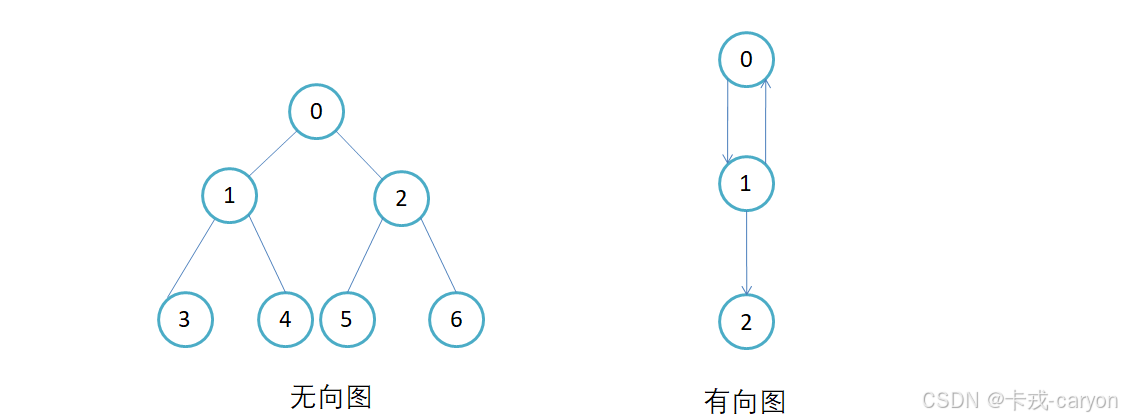
1.3 无权图和带权图
对图中的边赋予具有一定意义的数值(路程、费用等等)的图称为带权图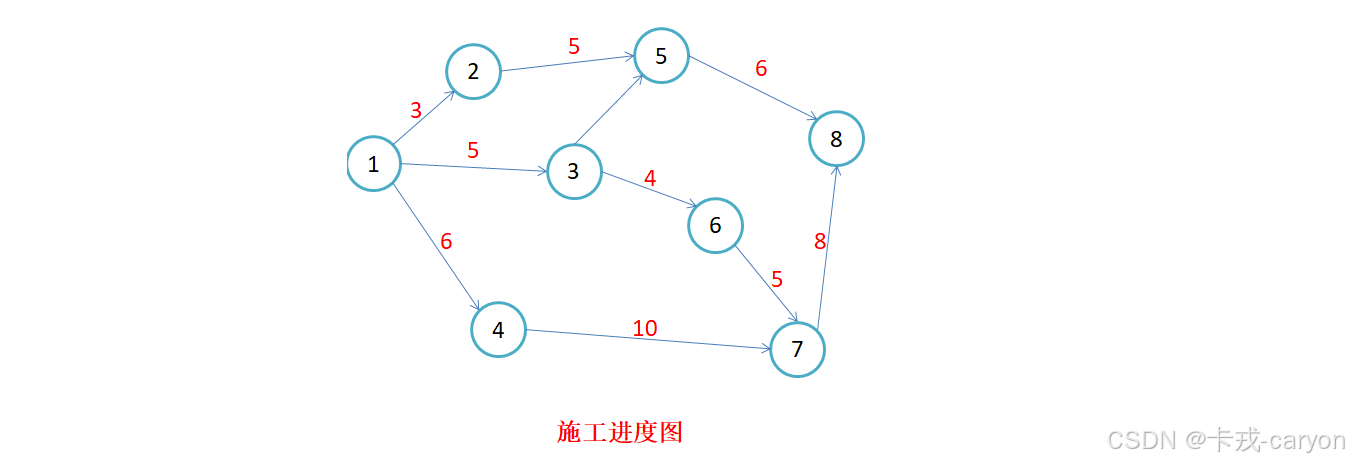
1.4 完全图
任意两个顶点之间都存在一条边。无向完全图的边数为n∗(n−1)/2n*(n-1)/2n∗(n−1)/2,有向完全图的边数为n∗(n−1)n*(n-1)n∗(n−1)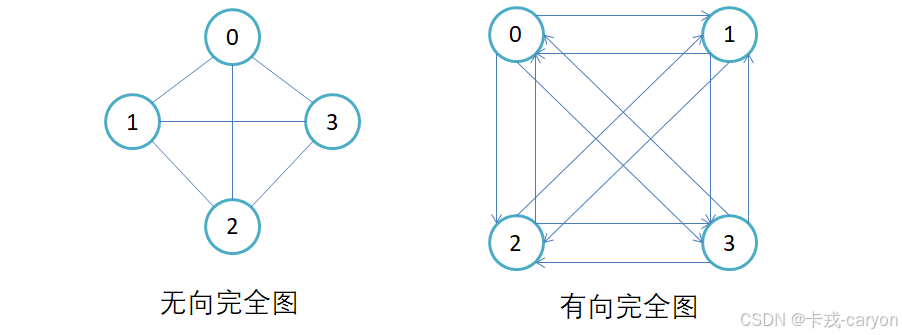
1.5 邻接顶点
如果顶点viv_ivi、vjv_jvj之间存在一条边,则称它们互为邻接顶点
1.6 结点的度
结点v的度是指与它相关联的边的条数,记作deg(v)deg(v)deg(v)。在有向图中,结点的度等于该结点的入度与出度之和,其中结点v的入度是以v为终点的有向边的条数,记作indev(v)indev(v)indev(v) ;顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)outdev(v)outdev(v)。因此:dev(v)=indev(v)+outdev(v)dev(v) = indev(v) + outdev(v)dev(v)=indev(v)+outdev(v)
1.7 路径
在图G = (V, E)中,若从顶点viv_ivi出发有一组边使其可到达顶点vjv_jvj,则称顶点viv_ivi到顶点vjv_jvj的顶点序列为从顶点viv_ivi到顶点vjv_jvj的路径。
对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。
若路径上各顶点v1v_1v1,v2v_2v2,v3v_3v3,…,vmv_mvm均不重复,则称这样的路径为简单路径。若路径上第一个顶点v1v_1v1和最后一个顶点vmv_mvm重合,则称这样的路径为回路或环。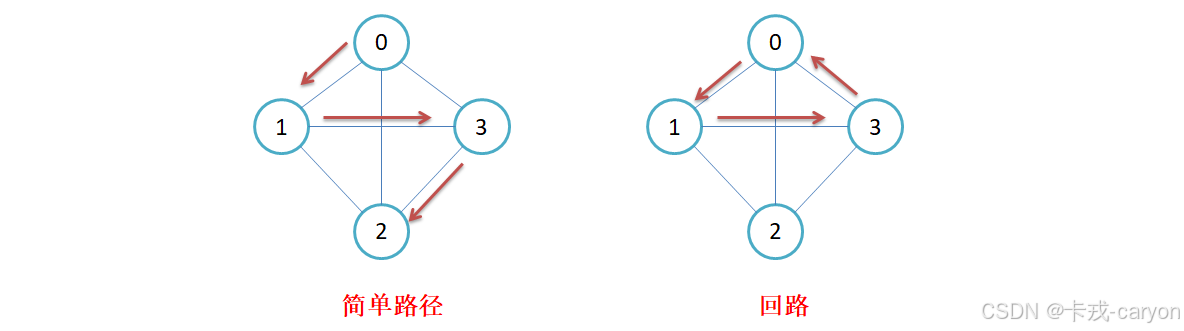
1.8 连通图
在无向图中,若从顶点v1v_1v1到顶点v2v_2v2有路径,则称顶点v1v_1v1与顶点v2v_2v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。在有向图中,若在每一对顶点viv_ivi和vjv_jvj之间都存在一条从viv_ivi到vjv_jvj的路径,也存在一条从vjv_jvj到viv_ivi的路径,则称此图是强连通图。
1.9 子图
图G={V,E}G = \{V, E\}G={V,E} 和图 G1={V1,E1}G_1 = \{V_1,E_1\}G1={V1,E1},若V1V_1V1属于VVV且E1E_1E1属于EEE,则称G1G_1G1是GGG的子图。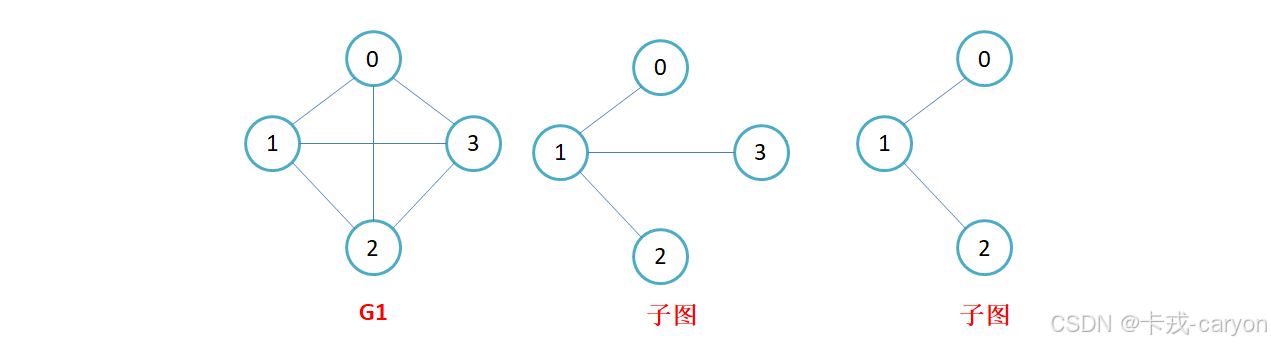
1.10 最小连通子图与生成树
一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。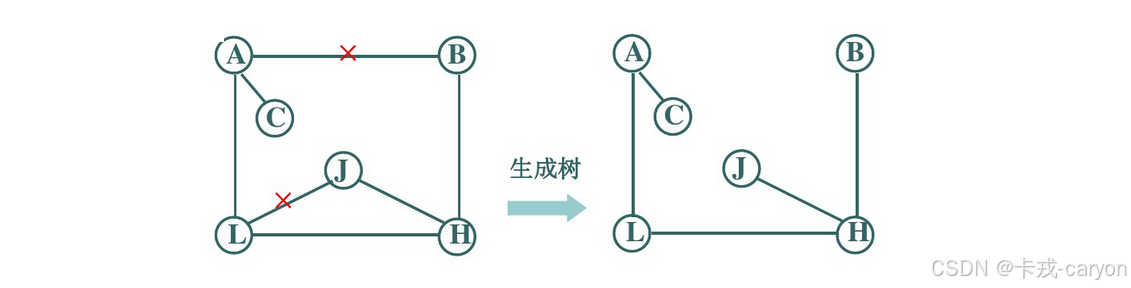
二、图的存储结构
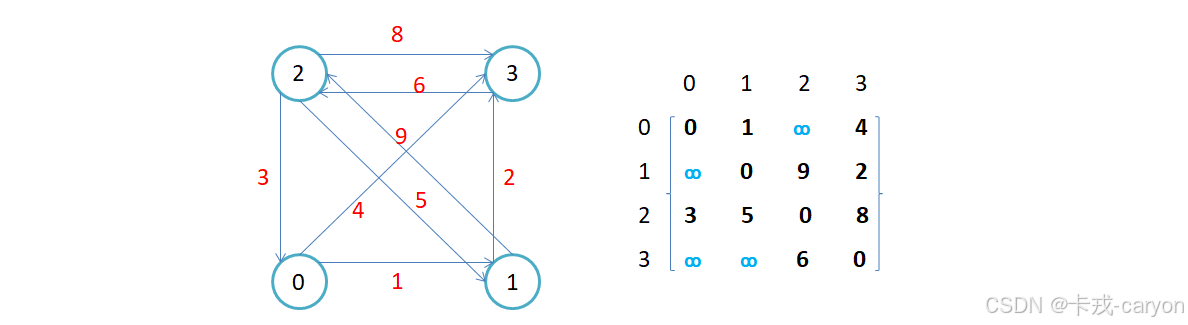
2.1 邻接矩阵
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵即用矩阵来表示节点与节点之间的关系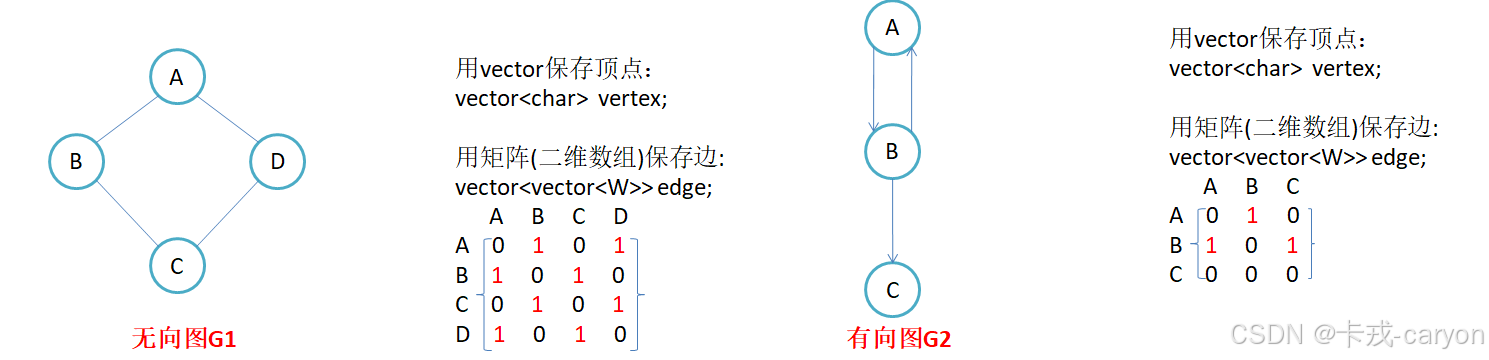
注意:
• 无向图的邻接矩阵是对称的,第i行(列)元素个数之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素个数之和就是顶点i 的出(入)度。
• 如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替。
• 用邻接矩阵存储图的有点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
// 顶点类型,权重类型 有无方向
template<class V,class W ,W W_MAX=INT_MAX,bool Direction=false>
class Graph
{
public:
//构造函数:使用顶点数组进行初始化
Graph(const V* arr,size_t n)
{
//初始化顶点集
_vertex.resize(n);
for (size_t i = 0; i < n; i++)
{
_vertex[i] = arr[i];//存储顶点信息
_Index[arr[i]] = i;//顶点映射的下标
}
//初始化权值矩阵
_matrix.resize(n);
for (size_t i = 0; i < n; i++)
_matrix[i].resize(n,W_MAX);
}
//获取对应下标
size_t GetIndex(const V& src)
{
//一般来说不太可能找不到
auto ret = _Index.find(src);
if (ret != _Index.end())
return ret->second;
else
return -1;
}
//添加边
void AddEdge(const V& src, const V& dst,const W& weight)
{
//换成下标
size_t srci = GetIndex(src);
size_t dsti = GetIndex(dst);
_matrix[srci][dsti] = weight;
if (!Direction)
{
_matrix[dsti][srci] = weight;
}
}
private:
vector<V> _vertex;//顶点集
map<V, size_t> _Index;//顶点所对应的下标
vector<vector<W>> _matrix;//权值矩阵(边矩阵)
};
2.1 邻接表
使用数组表示顶点的集合,使用链表表示边的关系。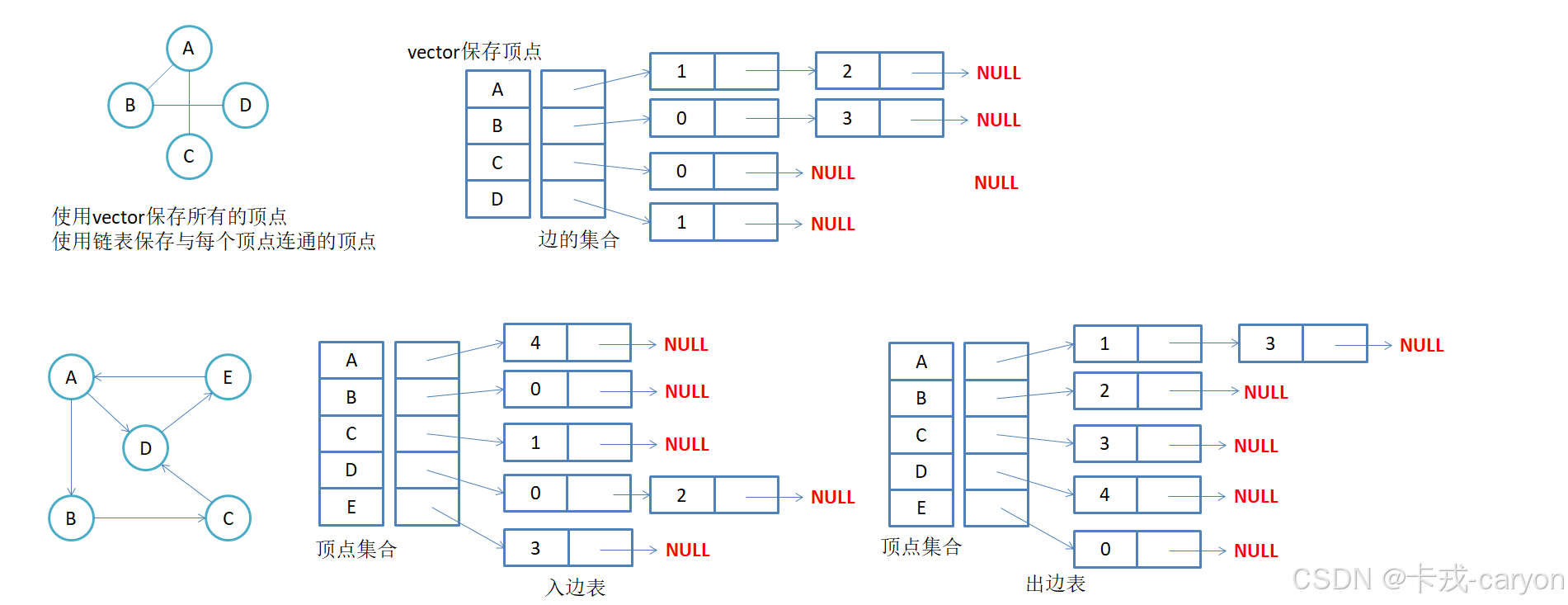
注意:
无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可。
有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。
template<class W>
struct Node
{
size_t _dsti;
W _weight;
Node* _next;
Node(size_t dsti,W weight):_dsti(dsti),_weight(weight),_next(nullptr)
{}
};
// 顶点类型,权重类型 有无方向
template<class V, class W, W W_MAX = INT_MAX, bool Direction = false>
class Graph
{
typedef Node<W> Node;
public:
//构造函数:使用顶点数组进行初始化
Graph(const V* arr, size_t n)
{
//初始化顶点集
_vertex.resize(n);
for (size_t i = 0; i < n; i++)
{
_vertex[i] = arr[i];//存储顶点信息
_Index[arr[i]] = i;//顶点映射的下标
}
_linkTable.resize(n, nullptr);
}
//获取对应下标
size_t GetIndex(const V& src)
{
//一般来说不太可能找不到
auto ret = _Index.find(src);
if (ret != _Index.end())
return ret->second;
else
return -1;
}
//添加边
void AddEdge(const V& src, const V& dst, const W& weight)
{
//换成下标
size_t srci = GetIndex(src);
size_t dsti = GetIndex(dst);
Node* newnode=new Node{dsti,weight };
newnode->_next = _linkTable[srci];
_linkTable[srci] = newnode;
if (Direction == false)
{
Node* newnode = new Node{ srci,weight };
newnode->_next = _linkTable[dsti];
_linkTable[dsti] = newnode;
}
}
private:
vector<V> _vertex;//顶点集
map<V, size_t> _Index;//顶点所对应的下标
vector<Node*> _linkTable;//邻接矩阵
};
三、图的遍历
3.1 图的广度优先遍历
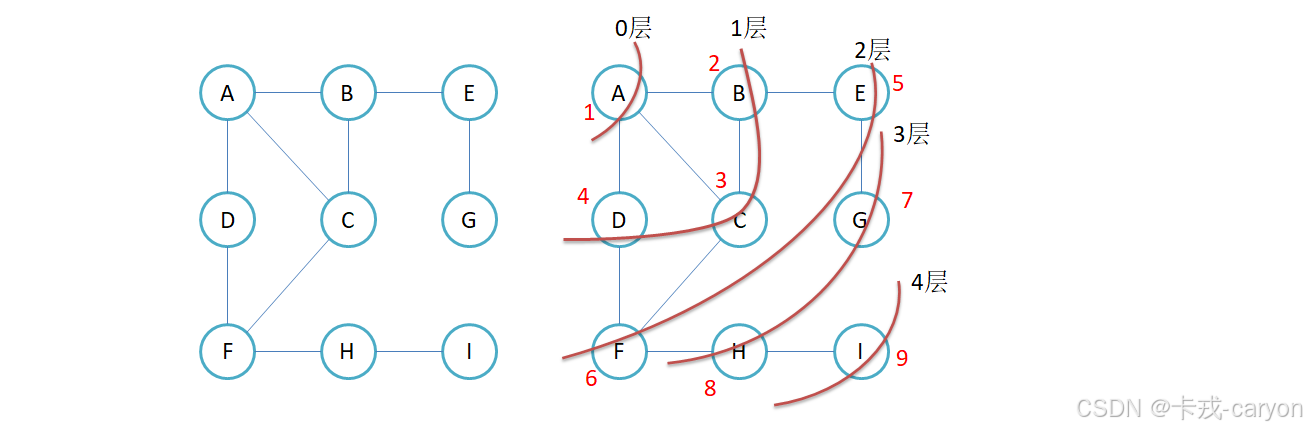
//广度优先遍历
void BFS(const V& src)
{
//获取下标
size_t srci = GetIndex(src);
//标记数组,标记访问过的元素
vector<bool> visited(_vertex.size(), false);
//利用队列实现
queue<size_t> q;
q.push(srci);
visited[srci] = true;
int LevelSize = q.size();
while (!q.empty())
{
//一层一层出
while (LevelSize--)
{
//取队头元素
size_t front = q.front();
q.pop();
//输出当前信息
cout << _vertex[front] << " ";
//把与它相邻的顶点入队列
for (size_t i = 0; i < _vertex.size(); i++)
{
if (_matrix[front][i] != W_MAX && visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
//获取下一层数据个数
LevelSize = q.size();
cout << endl;
}
cout << endl;
}
3.2 图的深度优先遍历
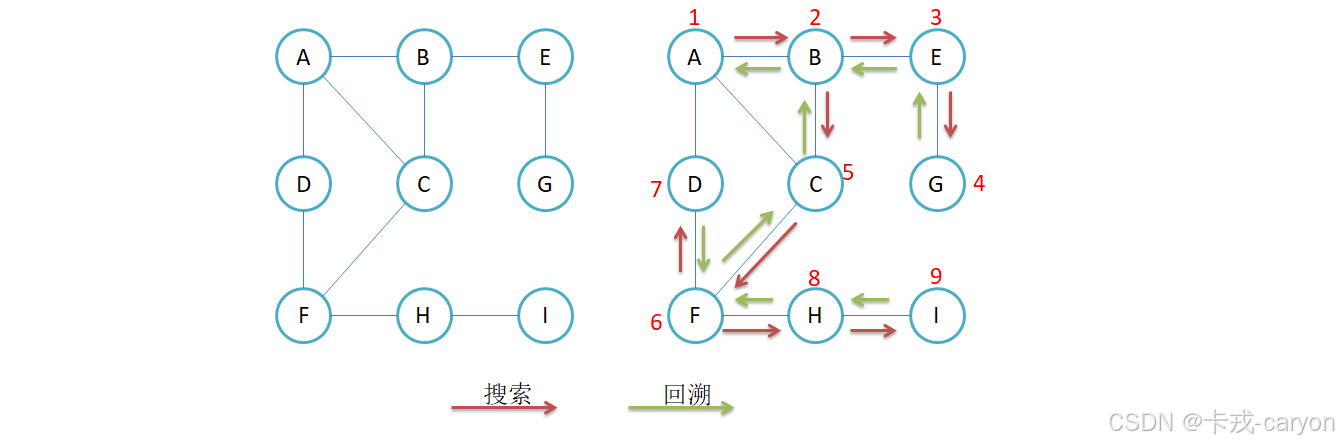
void _DFS(size_t srci, vector<bool>& visited)
{
cout << _vertex[srci] << " ";
visited[srci] = true;
for (size_t i = 0; i < _vertex.size(); i++)
{
if (_matrix[srci][i] != W_MAX && visited[i] == false)
_DFS(i, visited);
}
}
//DFS
void DFS(const V& src)
{
//获取下标
size_t srci = GetIndex(src);
//标记数组
vector<bool> visited(_vertex.size(), false);
//递归
_DFS(srci, visited);
//解决不连通的情况
for (size_t i = 0; i < _vertex.size(); i++)
{
if (visited[i] == false)
_DFS(i, visited);
}
}
四、最小生成树
一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。Kruskal算法和Prim算法是常见的求解最小生成树的算法,这两个算法都采用了逐步求解的贪心策略。
4.1 Kruskal 算法
首先构造一个含 n 个顶点、不含任何边的图作为最小生成树,对原图中的各个边按权值进行排序。每次从原图中选出一条最小权值的边,将其加入到最小生成树中,如果加入这条边会使得最小生成树中构成回路,则重新选择一条边。按照上述规则不断选边,当选出 n-1 条合法的边时,则说明最小生成树构造完毕,如果无法选出 n-1 条合法的边,则说明原图不存在最小生成树。
下图摘自《算法导论》
//边
struct Edge
{
size_t _srci;
size_t _dsti;
W _weight;
Edge(size_t srci, size_t dsti, W& weight):_srci(srci),_dsti(dsti),_weight(weight){}
bool operator>(const Edge& e) const
{
return _weight > e._weight;
}
};
//最小生成树:Kruskal算法
W Kruskal(Graph& minTree)
{
//初始化最小生成树
minTree._vertex = _vertex;
minTree._Index = _Index;
minTree._matrix.resize(_vertex.size());
for (size_t i = 0; i < _vertex.size(); i++)
minTree._matrix[i].resize(_vertex.size(), W_MAX);
//每次都选取权值最小的边
priority_queue<Edge, vector<Edge>, greater<Edge>> pqmin;
//建立小根堆
size_t size = _vertex.size();
for (size_t i = 0; i < size; i++)
{
for (size_t j = i; j < size; j++)
{
if (_matrix[i][j] != W_MAX)
pqmin.push(Edge(i, j, _matrix[i][j]));
}
}
size_t n = 0;
W total = W(); //总的权重
//使用并查集判断两个顶点是否在一个集合
UnionFindSet ufs(_vertex.size());
//找到n-1条边建立minTree
while (!pqmin.empty())
{
//取最小边建立联系
Edge min = pqmin.top();
pqmin.pop();
//不在同一个集合可以建边
if (!ufs.IsSameSet(min._srci, min._dsti))
{
//打印选边
cout << _vertex[min._srci] << "->" << _vertex[min._dsti] << ":" << min._weight << endl;
minTree._AddEdge(min._dsti, min._dsti, min._weight);
ufs.UnionSet(min._srci, min._dsti);
n++;
total += min._weight;
}
}
//建立了n-1条边就返回权重
if (n == _vertex.size() - 1)
return total;
else
return W();
}
4.2 Prim 算法

//最小生成树:Prim算法
W Prim(Graph& minTree,const V&src)
{
//获取下标
size_t srci = GetIndex(src);
//初始化最小生成树
minTree._vertex = _vertex;
minTree._Index = _Index;
minTree._matrix.resize(_vertex.size());
for (size_t i = 0; i < _vertex.size(); i++)
minTree._matrix[i].resize(_vertex.size(), W_MAX);
//判断是否在一个集合
UnionFindSet ufs(_vertex.size());
//建小堆
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
//把与srci相邻的顶点所构成的边都添加到小堆里
for (size_t i = 0; i < _vertex.size(); i++)
{
if (_matrix[srci][i] != W_MAX)
minque.push(Edge(srci, i, _matrix[srci][i]));
}
int n = 0;
W total = W();
//循环选边
while (!minque.empty())
{
//取出当前最小的边
Edge min = minque.top();
minque.pop();
//判断是否构成环
if (!ufs.IsSameSet(min._srci, min._dsti))
{
cout << _vertex[min._srci] << "->" << _vertex[min._dsti] << ":" << min._weight << endl;
minTree._AddEdge(min._srci, min._dsti, _matrix[min._srci][min._dsti]);
ufs.UnionSet(min._srci, min._dsti);
n++;
total += _matrix[min._srci][min._dsti];
//相邻的边进入小堆
for (size_t i = 0; i < _vertex.size(); i++)
{
if(_matrix[min._dsti][i] != W_MAX)
minque.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
//建立了n-1条边就返回权重
if (n == _vertex.size() - 1)
return total;
else
return W();
}
五、最短路径
最短路径问题:从带权有向图中的某一顶点出发,找出一条通往另一顶点的最短路径,最短指的是路径各边的权值总和达到最小,最短路径可分为单源最短路径和多源最短路径。单源最短路径指的是从图中某一顶点出发,找出通往其他所有顶点的最短路径,而多源最短路径指的是,找出图中任意两个顶点之间的最短路径。
5.1 单源最短路径 —— Dijkstra 算法

// 源点 权值数组 父路径数组
void Dijkstra(const V& src, vector<W>& dist, vector<int>& parentPath)
{
//获取下标
size_t srci = GetIndex(src);
//顶点个数
size_t n = _vertex.size();
//初始化距离数组,父路径数组
dist.resize(n, W_MAX);
parentPath.resize(n, -1);
//对源点记录,起始点记为0
dist[srci] = 0;
parentPath[srci] = srci;//这个自己怎么定义都可以,知道含义就行
//标记数组
vector<bool> visited(n, false);
//更新剩余点位
for (size_t j = 0; j < n; j++)
{
//找到当前
size_t minindex= 0;
//找距离srci最短的顶点,更新最短路径
W min = W_MAX;//最短距离
for (size_t i = 0; i < n; i++)
{
if (visited[i] == false && dist[i] < min)
{
min = dist[i];
minindex = i;
}
}
visited[minindex] = true;//标记
//松弛操作
for (size_t i = 0; i < n; i++)
{
if (visited[i]==false&&_matrix[minindex][i] != W_MAX && dist[minindex] + _matrix[minindex][i] < dist[i])
{
dist[i] = dist[minindex] + _matrix[minindex][i];
parentPath[i] = minindex;
}
}
}
}
5.2 单源最短路径 —— Bellman-Ford算法
Dijkstra算法只能用来解决正权图的单源最短路径问题,但有些题目会出现负权图。这时这个算法就不能帮助我们解决问题了,而bellman—ford算法可以解决负权图的单源最短路径问题。它的优点是可以解决有负权边的单源最短路径问题,而且可以用来判断是否有负权回路。它也有明显的缺点,它的时间复杂度 O(N*E) (N是点数,E是边数)普遍是要高于Dijkstra算法O(N²)的。像这里如果我们使用邻接矩阵实现,那么遍历所有边的数量的时间复杂度就是O(N^3),这里也可以看出来Bellman-Ford就是一种暴力求解更新。
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& parentPath)
{
//获取下标
size_t srci = GetIndex(src);
//顶点个数
size_t n = _vertex.size();
//初始化距离数组,父路径数组
dist.resize(n, W_MAX);
parentPath.resize(n, -1);
dist[srci] = W();
for(int k=0;k<n;k++)
{
for (size_t i = 0; i < n; ++i)
{
for (int j = 0; j < n; ++j)
{
if (_matrix[i][j] != W_MAX && dist[i] + _matrix[i][j] < dist[j])
{
dist[j] = dist[i] + _matrix[i][j];
parentPath[j] = i;
}
}
}
}
//更新完N轮还能更新就是有回路
for (size_t i = 0; i < n; ++i)
{
for (int j = 0; j < n; ++j)
{
if (_matrix[i][j] != W_MAX && dist[i] + _matrix[i][j] < dist[j])
{
return false;
}
}
}
return true;
}

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)