多模态预训练模型CLIP是什么?CLIP有什么用?
摘要:CLIP是由OpenAI开发的多模态预训练模型,通过对比学习将图像和文本映射到共享的嵌入空间,使语义相近的内容向量距离更近。它由图像编码器(ResNet/ViT)和文本编码器(Transformer)组成,使用InfoNCE损失优化图文匹配。CLIP可直接应用于图文检索、零样本分类,或作为特征提取器支持扩散模型(如Stable Diffusion)和多模态大模型(如LLaVA)。其训练基于4
1、什么是CLIP?
一句话解释 CLIP 是啥?
CLIP 是 OpenAl 开源的一种多模态预训练模型。
它能将图像和文字“翻译”成同一种语言: 一串数字(向量),并让描述同一事物的图像和文字在这个数字世界里靠得更近。
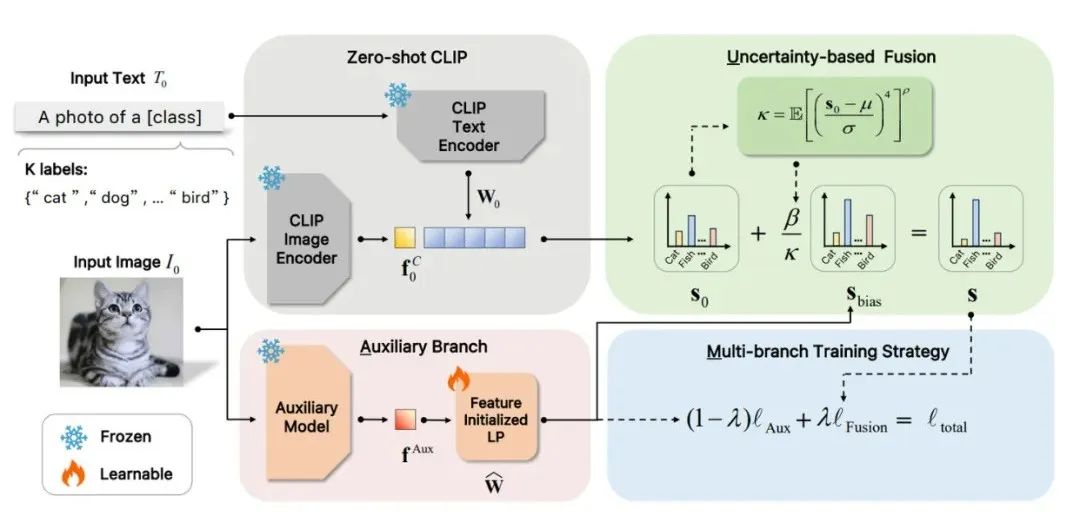
更专业一点的定义:
CLIP 的全称是 Contrastive Language-lmage Pretraining。
它通过对比学习的方法,学习图像与文本的共享嵌入空间,使语义相近的图像和文本在空间中靠近,而语义不相关的则彼此远离。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2、核心思想: 图文匹配游戏,让图和文互相理解
CLIP 的核心在于,它让图像和文字可以通过同一种方式表达它们的含义,这样 A1就能直接判断一张图和一句话是否在说同一件事。
你可以把它的训练过程理解为一个“图文匹配游戏”:每次给模型一组配对的图片和文字。
比如一只躺在地上的猫的图片和一句话“a photo of a cat”,这是一对正例,而这张图与不相关的句子,比如“a man riding a horse”,则构成负例。
每一对正负例中的图和文都会被分别编码成相同维度的“向量”,然后模型会比较它们之间的距离:
对于正例,目标是让它们距离更近
对于负例,目标是让距离更远
经过大量这样的训练,使 CLIP 学会判断一张图和一句话是否表达相同含义的能力。
OpenAl发布的 CLIP 模型就是基于互联网上收集的4亿组图文对进行训练的。
3、模型结构: 图像编码器+文本编码器,双剑合壁
CLIP 的模型结构非常直观:
图像编码器
常用 ResNet 或 Vision Transformer(ViT)
→把图片转为向量表示
文本编码器
采用 Transformer 架构
→把文字转为向量表示
投影头(Proiection Head)
在图像编码器和文本编码器之后,会接上一些线性层
→将图像或文本的嵌入向量投影到共享的、低维的嵌入空间,便于对比
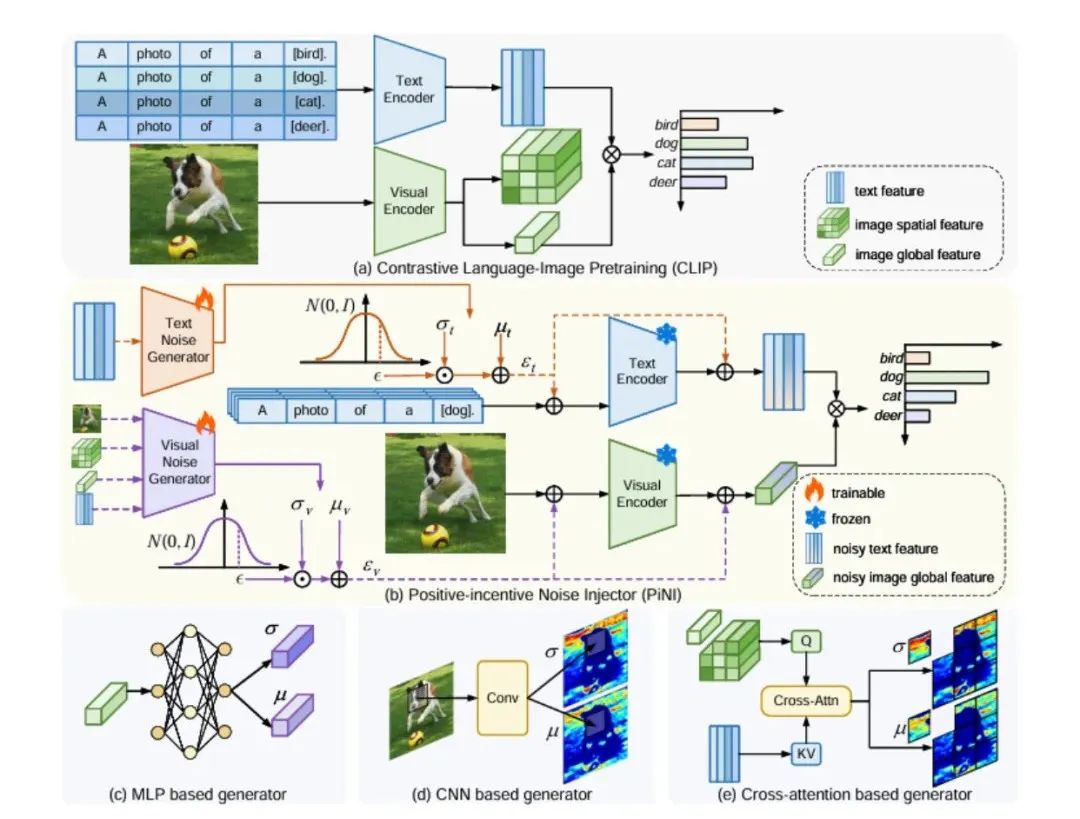
损失函数
CLIP 用的是一种叫 InfoNCE 的损失函数,目标是:
Maximize 配对图文的相似度
Minimize 错误配对的相似度
在训练过程中,基于该目标不断调整模型参数,使得语义匹配的图文在共享嵌入空间内的距离(例如:余弦相似度)越来越近。
4、CLIP有什么用?
直接应用
基于 CLIP 的图文对齐和编码能力,通过计算图像与文本向量之间的余弦相似度,可实现:
图文匹配: 判断一张图片与一句话是否语义对应
图文检索: 根据文字检索图片,或根据图片检索文字
零样本图像分类: 即使 CLIP 没见过某类图,只要提供文字类别标签,它也能判断图片属于哪个类别
作为特征提取器,支撑下游任务
CLIP 编码后的图像向量间接融合了语义信息,文本向量也带有视觉语义,可作为下游任务输入:
扩散模型(如 Stable Diffusion)
CLIP 将用户输入的提示词编码为向量,作为扩散模型的“条件输入”,指导图像朝着提示词语义方向生成。
多模态大语言模型(如 LLaVA)
CLIP 编码图像为向量后,与文本提示一同构成图文对齐的输入,送入语言模型。
通过这种方式,模型具备了同时理解图像和文字的能力,实现“看图说话”等多模态任务。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 8
8 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)