基于深度学习的农作物|植物病虫害检测系统(YOLO+数据集+模型+代码+训练过程+详细文档)
🌿 农作物虫害检测系统摘要 PDDI是一个基于YOLOv8深度学习模型的植物病虫害检测系统,提供Web界面支持实时检测、模型训练和评估功能。系统采用模块化设计,包含训练、测试和检测三大核心模块,支持可视化监控和性能分析。项目使用改进的PlantVillage数据集(54,000+图像),要求Python 3.8+环境,推荐GPU加速。主要功能包括:实时病虫害识别、训练过程可视化、模型性能评估及优
🌿 基于深度学习的农作物|植物病虫害检测系统 (PDDI - Plant Disease Detection and Identification)
项目简介
本项目是一个基于深度学习的植物病虫害检测系统,使用YOLOv8目标检测模型实现对植物病虫害的实时检测和识别。系统提供了友好的Web界面,支持模型训练、测试和实时检测等功能。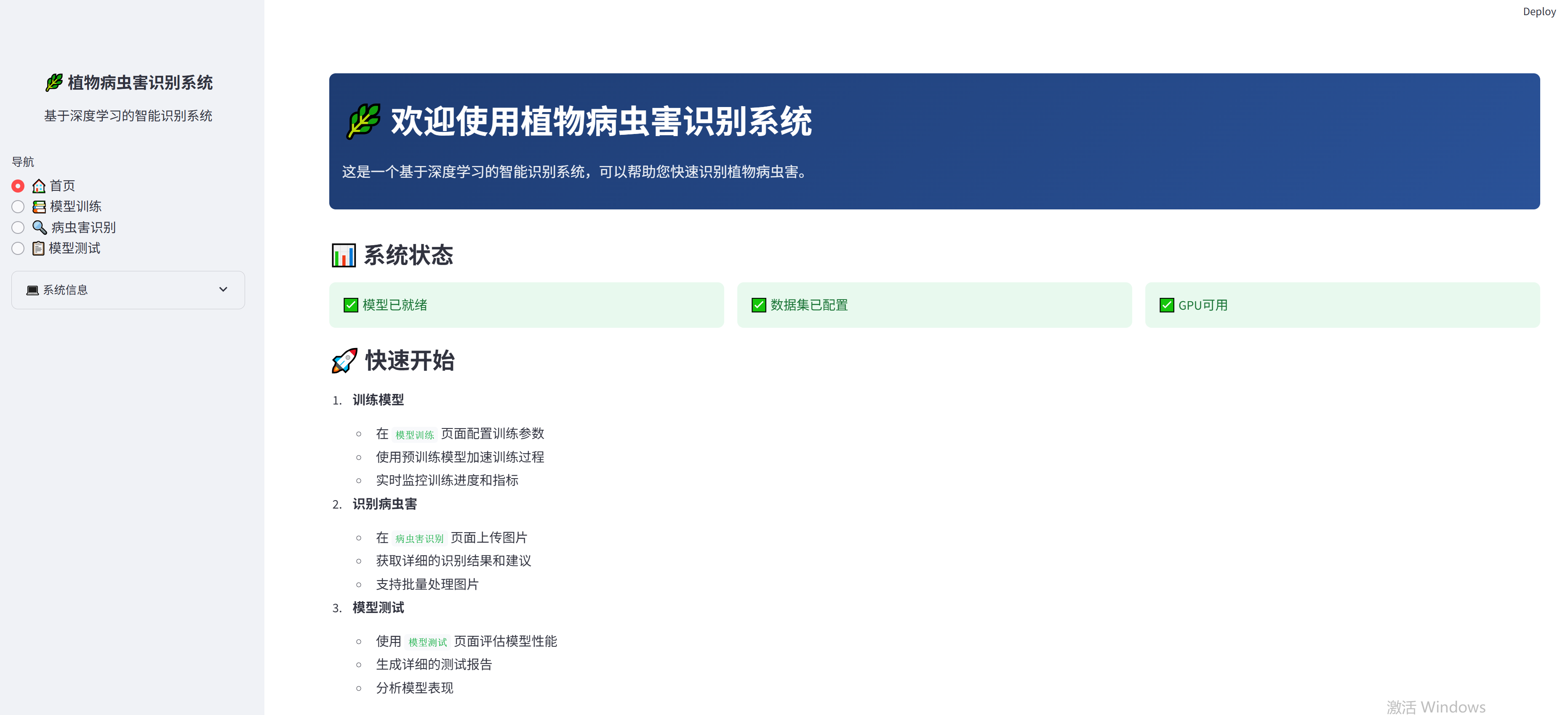
代码获取:https://mbd.pub/o/bread/mbd-YZWVlJ1qZw==
视频介绍:
基于深度学习的植物病虫害检测系统(含UI界面、YOLO模型、代码、数据集)
系统功能
- 🌟 实时病虫害检测与识别
- 📊 可视化训练过程监控
- 📈 详细的模型评估报告
- 🔄 支持模型微调和优化
- 💻 直观的Web操作界面
- 📱 响应式设计,支持多设备访问
环境要求
基本要求
- Python 3.8+
- CUDA 11.0+ (GPU训练可选)
- 8GB+ RAM
推荐配置
- NVIDIA GPU (8GB+ 显存)
- 16GB+ RAM
- SSD存储
快速开始
1. 环境配置
安装依赖
pip install -r requirements.txt
### 2. 环境检查
运行GPU环境检测工具确认系统状态:
```bash
python check_gpu.py
3. 数据准备
运行数据集准备工具:
python prepare_dataset.py
4. 启动系统
streamlit run app.py
项目结构
PDDI/
├── app.py # 主程序入口
├── modules/ # 核心功能模块
│ ├── training.py # 训练模块
│ ├── testing.py # 测试模块
│ └── detection.py # 检测模块
├── utils/ # 工具函数
│ ├── prepare_dataset.py # 数据集处理
│ ├── check_gpu.py # GPU检查
│ └── metrics.py # 评估指标
├── dataset/ # 数据集目录
├── models/ # 模型存储
└── configs/ # 配置文件
核心模块
主程序 (app.py)
主程序负责整个应用的初始化和页面路由,使用Streamlit构建Web界面。主要功能:
- 页面配置和初始化
- 导航菜单管理
- 功能模块集成
- 用户交互处理
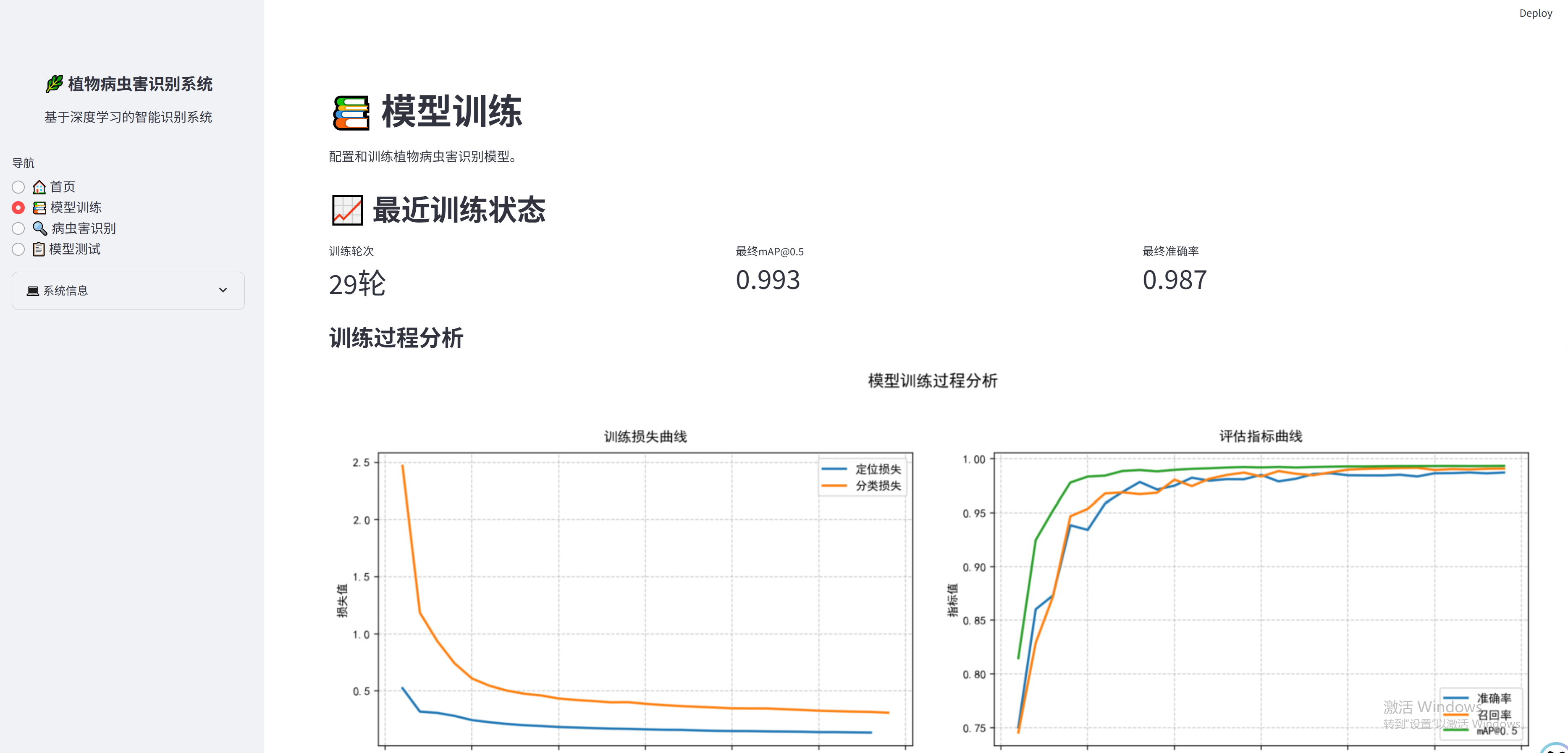
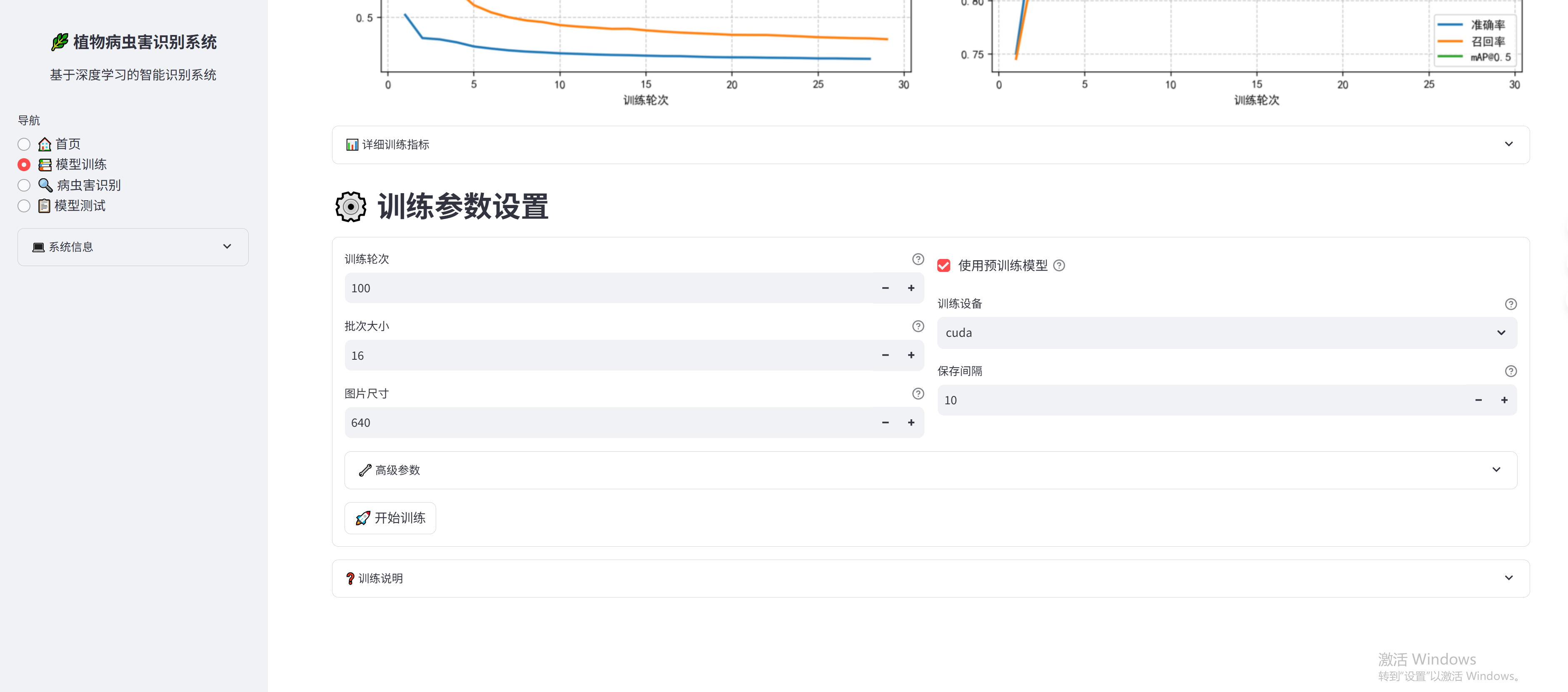
训练模块 (modules/training.py)
训练模块负责模型训练过程管理:
- 训练参数配置
- 训练过程监控
- 训练结果可视化
- 模型保存管理
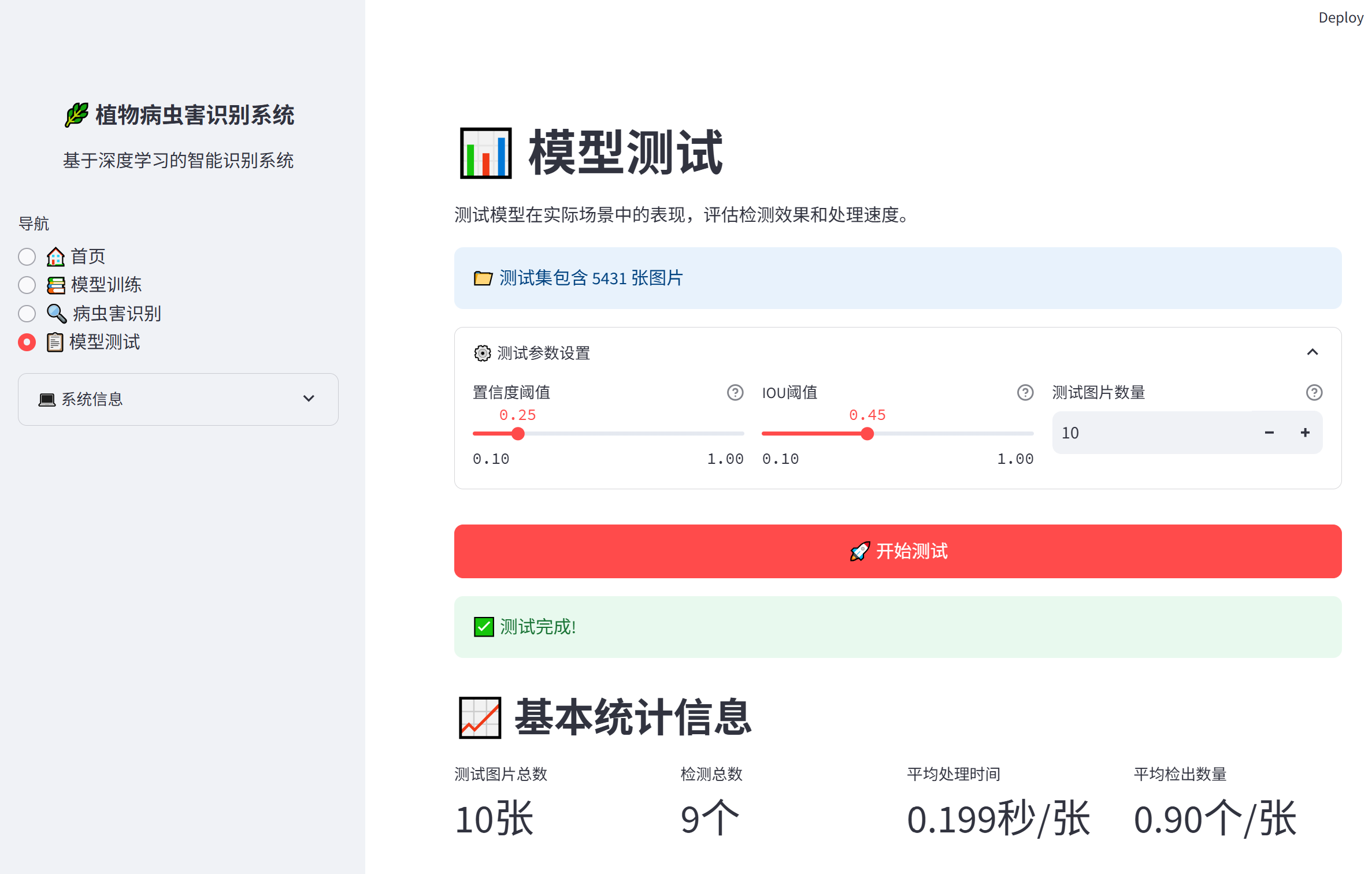
测试模块 (modules/testing.py)
测试模块负责模型性能评估:
- 准确率计算
- 混淆矩阵生成
- 测试报告输出
- 性能指标统计
检测模块 (modules/detection.py)
检测模块负责实际的病虫害检测:
- 图像预处理
- 模型推理
- 结果后处理
- 可视化展示
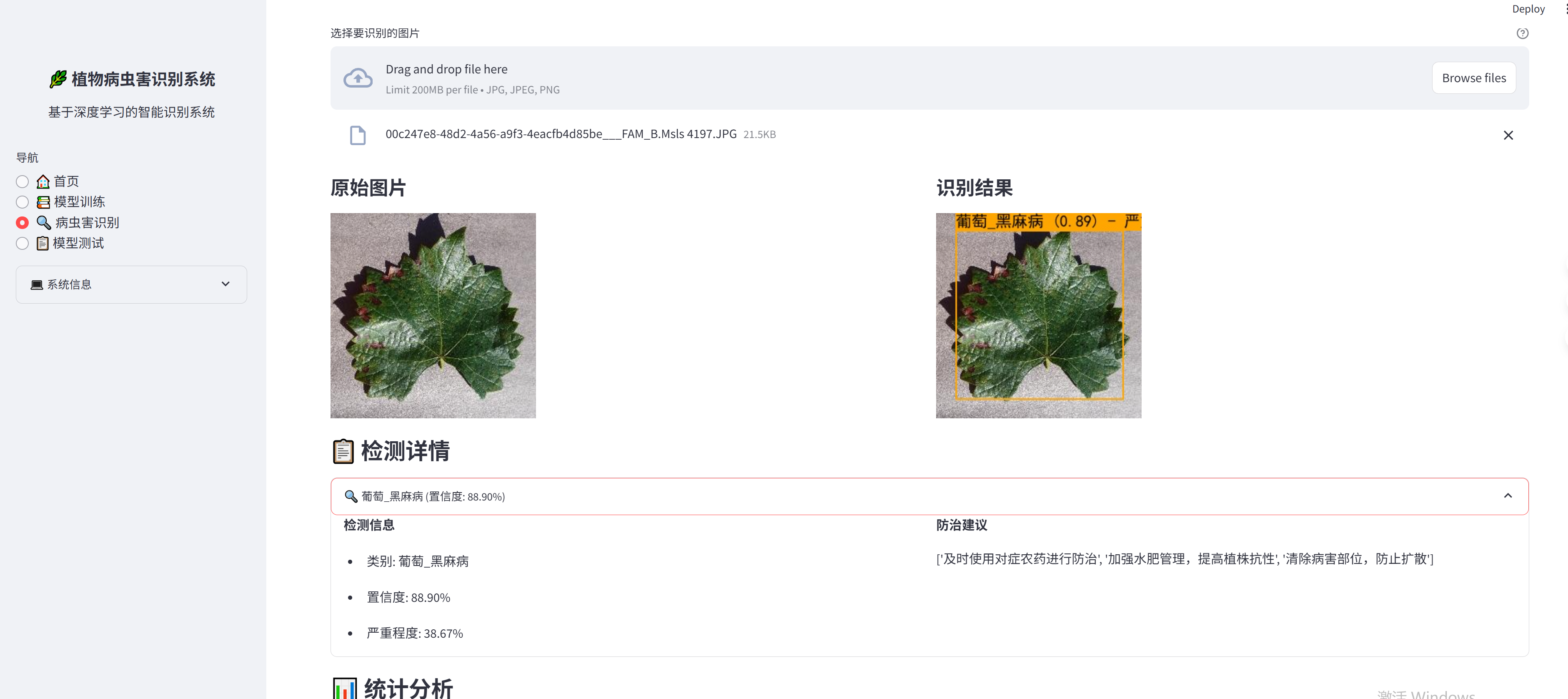
数据处理
数据集说明
本项目使用改进的PlantVillage数据集:
- 数据规模:54,000+ 图像
- 作物种类:14种
- 病害类别:38种
- 图像分辨率:256x256像素
数据处理工具 (prepare_dataset.py)
class DatasetPreparation:
def __init__(self, source_dir, target_dir):
self.source_dir = Path(source_dir)
self.target_dir = Path(target_dir)
self.train_ratio = 0.8
self.val_ratio = 0.1
self.test_ratio = 0.1
主要功能:
- 数据清洗和标准化
- 数据集划分
- 标注文件生成
- 配置文件生成
环境检测工具 (check_gpu.py)
class GPUChecker:
def __init__(self):
self.cuda_available = torch.cuda.is_available()
self.gpu_info = self.get_gpu_info()
主要功能:
- CUDA环境检查
- GPU信息获取
- 系统兼容性验证
- 性能评估
模型训练
训练配置
- 基础参数:
- 训练轮次:100
- 批次大小:16
- 图片尺寸:640
- 学习率:0.01
- 预热轮次:3
训练流程
- 准备数据集
- 配置训练参数
- 启动训练任务
- 监控训练进度
- 评估训练结果
训练监控
- 实时损失曲线
- 准确率指标
- 资源占用
- 训练日志
部署指南
本地部署
# 安装依赖
pip install -r requirements.txt
# 启动应用
streamlit run app.py
常见问题
GPU相关
-
GPU不可用?
- 检查CUDA安装
- 更新显卡驱动
- 确认CUDA版本兼容性
-
训练速度慢?
- 调整批次大小
- 使用GPU训练
- 优化数据加载
-
检测准确率低?
- 增加训练数据
- 调整模型参数
- 使用数据增强
核心代码说明
1. 模型训练核心代码
# modules/training.py
class TrainingPage:
def __init__(self):
self.setup_directories()
self.load_last_training()
def train_model(self, params):
"""模型训练主函数"""
try:
# 初始化模型
model = YOLO('yolov8n.pt' if params['pretrained'] else 'yolov8n.yaml')
# 配置训练参数
train_args = {
'data': 'dataset/data.yaml', # 数据集配置
'epochs': params['epochs'], # 训练轮次
'batch': params['batch_size'], # 批次大小
'imgsz': params['img_size'], # 图片尺寸
'device': params['device'], # 训练设备
'workers': params['num_workers'], # 数据加载线程
'lr0': params['learning_rate'], # 初始学习率
'momentum': params['momentum'], # 动量
'weight_decay': params['weight_decay'], # 权重衰减
'warmup_epochs': params['warmup_epochs'], # 预热轮次
'project': 'runs/train', # 输出目录
'name': f'exp_{datetime.now().strftime("%Y%m%d_%H%M%S")}' # 实验名称
}
# 开始训练
results = model.train(**train_args)
# 保存训练结果
self.save_training_results(results)
return True
except Exception as e:
st.error(f"训练错误: {str(e)}")
return False
def plot_training_metrics(self, results_file):
"""绘制训练指标图表"""
results_df = pd.read_csv(results_file)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 损失曲线
ax1.plot(results_df['epoch'], results_df['train/box_loss'], label='定位损失')
ax1.plot(results_df['epoch'], results_df['train/cls_loss'], label='分类损失')
ax1.set_title('训练损失曲线')
ax1.set_xlabel('训练轮次')
ax1.set_ylabel('损失值')
ax1.legend()
# 评估指标曲线
ax2.plot(results_df['epoch'], results_df['metrics/precision(B)'], label='准确率')
ax2.plot(results_df['epoch'], results_df['metrics/recall(B)'], label='召回率')
ax2.plot(results_df['epoch'], results_df['metrics/mAP50(B)'], label='mAP@0.5')
ax2.set_title('评估指标曲线')
ax2.set_xlabel('训练轮次')
ax2.set_ylabel('指标值')
ax2.legend()
return fig
2. 模型测试核心代码
# modules/testing.py
class TestingPage:
def __init__(self):
self.load_model()
self.setup_metrics()
def evaluate_model(self, test_loader):
"""模型评估函数"""
results = []
metrics = {
'precision': 0,
'recall': 0,
'mAP50': 0,
'mAP50-95': 0
}
# 批量测试
for batch in test_loader:
# 模型预测
pred = self.model(batch['images'])
# 计算批次指标
batch_metrics = self.calculate_metrics(pred, batch['labels'])
self.update_metrics(metrics, batch_metrics)
# 保存预测结果
results.extend(self.process_predictions(pred, batch))
# 生成评估报告
report = self.generate_report(results, metrics)
return report
def calculate_metrics(self, predictions, targets):
"""计算评估指标"""
# 计算IOU
iou = box_iou(predictions[:, :4], targets[:, :4])
# 计算TP, FP, FN
correct = iou > 0.5
tp = correct.sum().float()
fp = (~correct).sum().float()
fn = (targets.shape[0] - tp)
# 计算precision和recall
precision = tp / (tp + fp + 1e-16)
recall = tp / (tp + fn + 1e-16)
return {
'precision': precision.item(),
'recall': recall.item(),
'tp': tp.item(),
'fp': fp.item(),
'fn': fn.item()
}
3. 检测模块核心代码
# modules/detection.py
class DetectionPage:
def __init__(self):
self.load_model()
self.setup_interface()
def process_image(self, image):
"""图像处理和检测"""
try:
# 图像预处理
processed_img = self.preprocess_image(image)
# 执行检测
results = self.model(processed_img)
# 后处理结果
detections = self.postprocess_results(results)
return detections
except Exception as e:
st.error(f"检测错误: {str(e)}")
return None
def preprocess_image(self, image):
"""图像预处理"""
# 调整图像大小
resized = cv2.resize(image, (640, 640))
# 归一化
normalized = resized.astype(np.float32) / 255.0
# 转换为张量
tensor = torch.from_numpy(normalized).permute(2, 0, 1).unsqueeze(0)
return tensor
def postprocess_results(self, results):
"""检测结果后处理"""
detections = []
# 处理每个检测框
for det in results.pred[0]:
x1, y1, x2, y2, conf, cls = det
detection = {
'bbox': [x1.item(), y1.item(), x2.item(), y2.item()],
'confidence': conf.item(),
'class_id': int(cls.item()),
'class_name': self.class_names[int(cls.item())]
}
detections.append(detection)
return detections
def visualize_results(self, image, detections):
"""结果可视化"""
# 复制图像以避免修改原图
vis_image = image.copy()
# 绘制每个检测框
for det in detections:
# 获取边界框坐标
x1, y1, x2, y2 = det['bbox']
# 绘制边界框
cv2.rectangle(vis_image,
(int(x1), int(y1)),
(int(x2), int(y2)),
(0, 255, 0), 2)
# 添加标签
label = f"{det['class_name']} {det['confidence']:.2f}"
cv2.putText(vis_image, label,
(int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 255, 0), 2)
return vis_image
4. 数据处理工具核心代码
# utils/data_processing.py
class DataProcessor:
def __init__(self):
self.augmentation_config = self.load_config()
def preprocess_dataset(self, dataset_path):
"""数据集预处理"""
# 图像标准化
normalized_images = self.normalize_images(dataset_path)
# 数据增强
augmented_images = self.apply_augmentation(normalized_images)
# 生成标签
self.generate_labels(augmented_images)
def apply_augmentation(self, images):
"""应用数据增强"""
augmented = []
for img in images:
# 随机水平翻转
if random.random() > 0.5:
img = cv2.flip(img, 1)
# 随机亮度调整
if random.random() > 0.5:
factor = random.uniform(0.5, 1.5)
img = cv2.convertScaleAbs(img, alpha=factor, beta=0)
# 随机旋转
if random.random() > 0.5:
angle = random.uniform(-15, 15)
h, w = img.shape[:2]
M = cv2.getRotationMatrix2D((w/2, h/2), angle, 1.0)
img = cv2.warpAffine(img, M, (w, h))
augmented.append(img)
return augmented
这些核心代码展示了系统的主要功能实现,包括:
- 模型训练流程和参数配置
- 模型评估和指标计算
- 图像检测和结果可视化
- 数据预处理和增强方法
每个模块都包含了详细的注释,方便用户理解代码功能和实现逻辑。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)