【C++STL】之unordered_map与unordered_set系列容器的使用
这个类对象的前两个模板参数我们都很熟悉,Key值和Value值的元素类型。第三个是哈希函数:因为我们要将Key转化成一个索引(整数),但是这个key值的类型不一定是整数,就需要我们使用特定的哈希函数去转化为整数,这个整数可能不符合数组的下标范围,需要我们继续处理,这个我们后面具体谈到哈希再说。第三个模板参数是一个仿函数类,如果两个值相等,就返回true这个和map除了底层不一样,其它都很相似。un

📃博客主页: 小镇敲码人
💚代码仓库,欢迎访问
🚀 欢迎关注:👍点赞 👂🏽留言 😍收藏
🌏 任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。🍎🍎🍎
❤️ 什么?你问我答案,少年你看,下一个十年又来了 💞 💞 💞

【C++STL】之unordered_map与unordered_set系列容器的使用
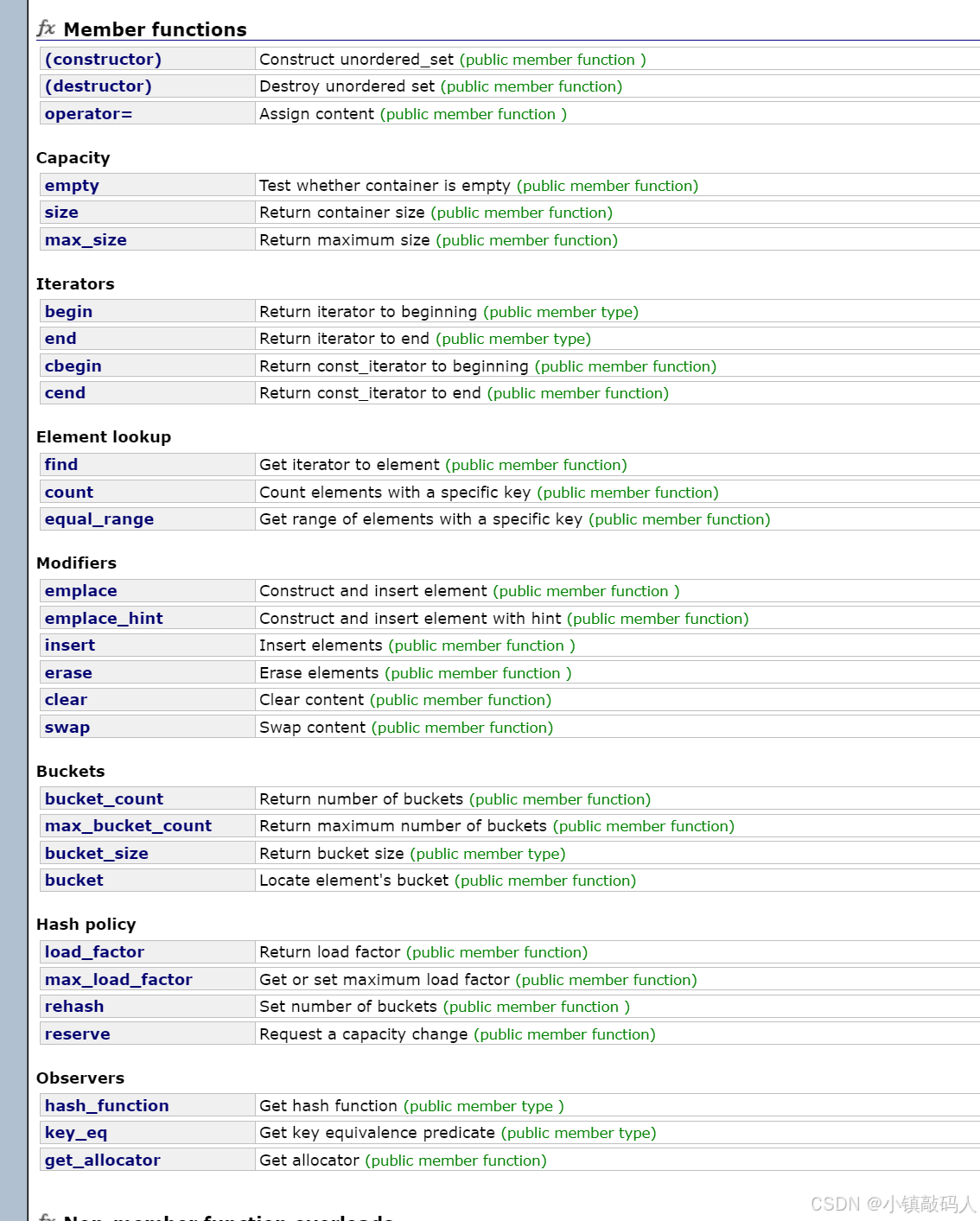
- unordered_map
-
- unordered_map的介绍
- unordered_map的方法接口
- unordered_map的使用
- unordered_set
-
- unordered_set的介绍
- unordered_set的方法接口
- unordered_set的使用
- unordered_set与set的效率比较
- OJ题
-
- 在长度 2N 的数组中找出重复 N 次的元素
- 两句话中的不常见单词
前言:在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,
当树中的节点非常多时(虽然有旋转可以让搜索二叉树近似平衡),但是查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本篇博客中只对unordered_map和unordered_set进行介绍。
unordered_map
unordered_map的介绍

这个类对象的前两个模板参数我们都很熟悉,Key值和Value值的元素类型。第三个是哈希函数:
因为我们要将Key转化成一个索引(整数),但是这个key值的类型不一定是整数,就需要我们使用特定的哈希函数去转化为整数,这个整数可能不符合数组的下标范围,需要我们继续处理,这个我们后面具体谈到哈希再说。
第三个模板参数是一个仿函数类,如果两个值相等,就返回true:
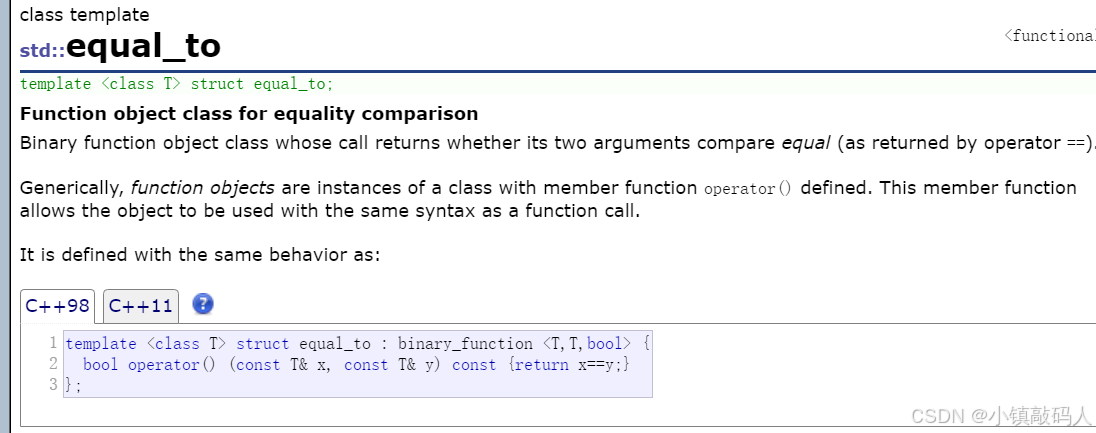
这个unordered_map和map除了底层不一样,其它都很相似。
unordered_map的方法接口
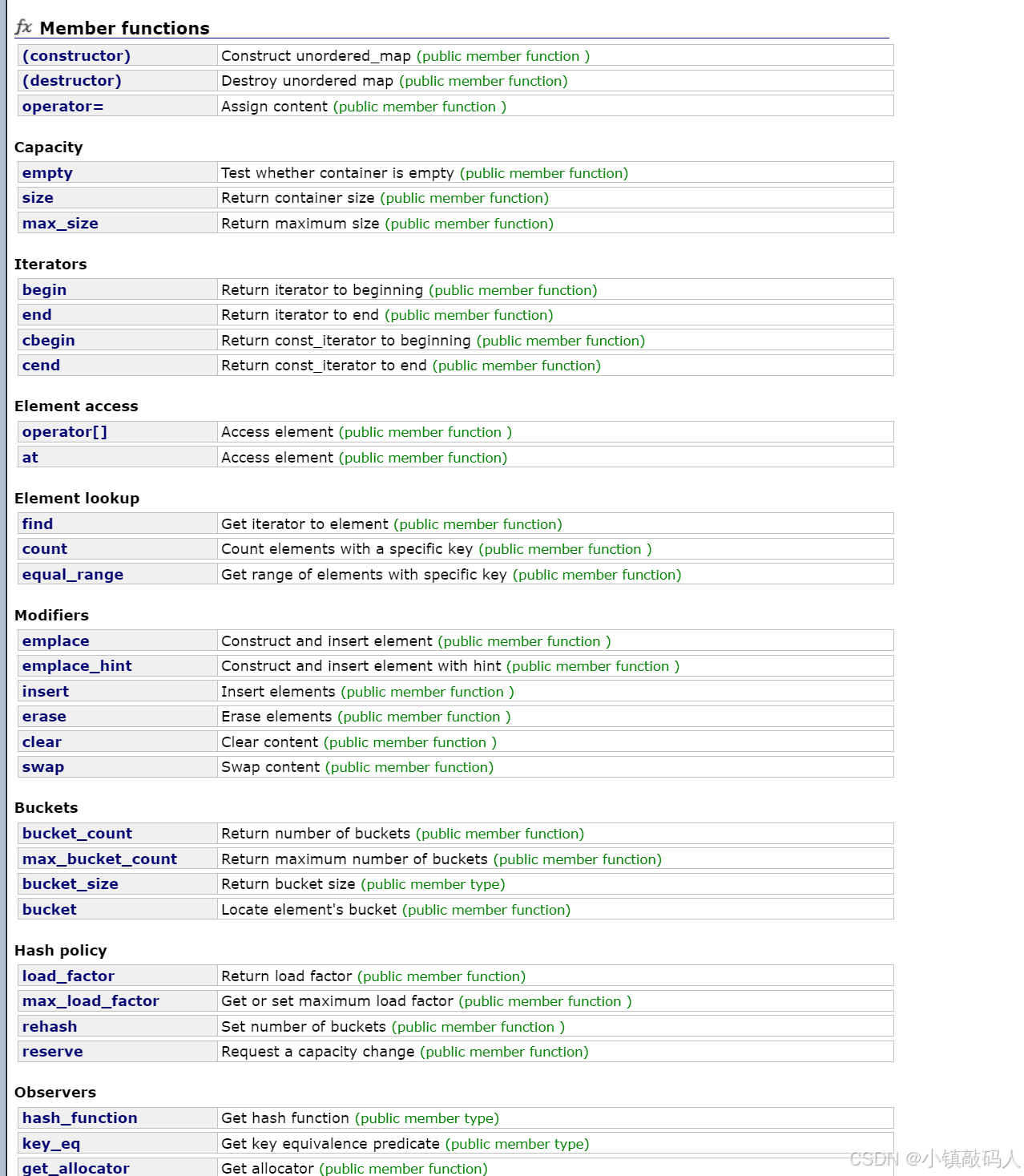
和我们之前介绍的STL容器接口类似,多了和哈希表的相关的函数。这些等我们介绍哈希表这个数据结构及其具体实现后,就很清晰了。
unordered_map的使用
#include<iostream>
#include<unordered_map>
#include<unordered_set>
#include<set>
#include<map>
using namespace std;
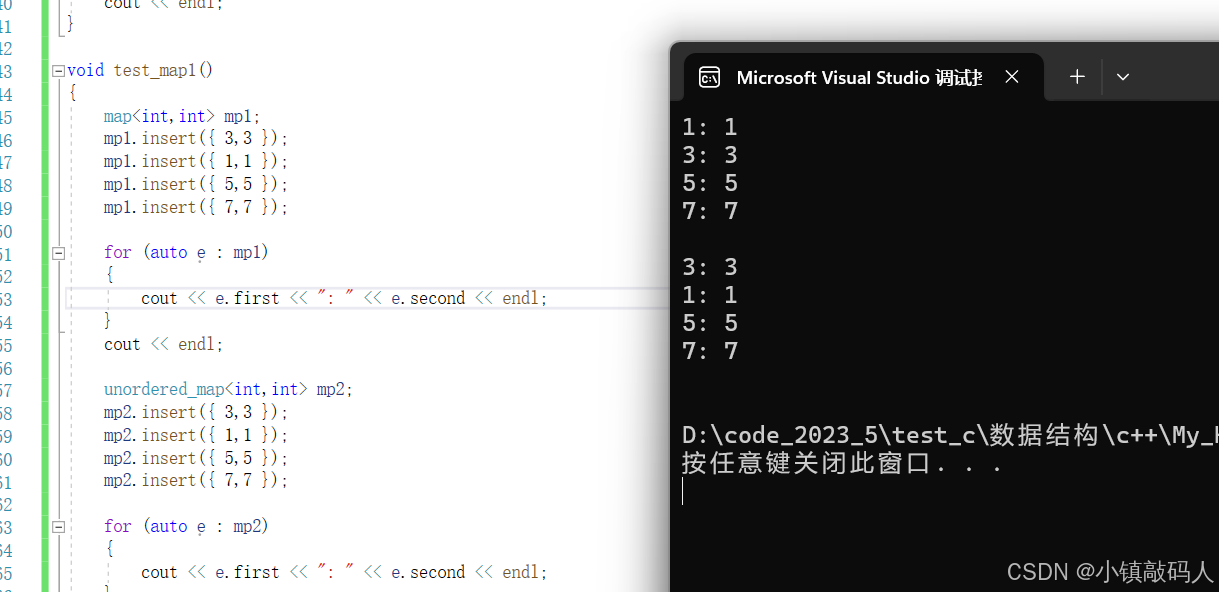
void test_map1()
{
map<int,int> mp1;
mp1.insert({ 3,3 });
mp1.insert({ 1,1 });
mp1.insert({ 5,5 });
mp1.insert({ 7,7 });
for (auto e : mp1)
{
cout << e.first << ": " << e.second << endl;
}
cout << endl;
unordered_map<int,int> mp2;
mp2.insert({ 3,3 });
mp2.insert({ 1,1 });
mp2.insert({ 5,5 });
mp2.insert({ 7,7 });
for (auto e : mp2)
{
cout << e.first << ": " << e.second << endl;
}
cout << endl;
}
int main()
{
test_map1();
return 0;
}
运行结果:
unordered_set
unordered_set的介绍
unordered_set和unordered_map的唯一区别就是前者只有
Key没有Value。是单纯的无序集合,而不是K-V映射。
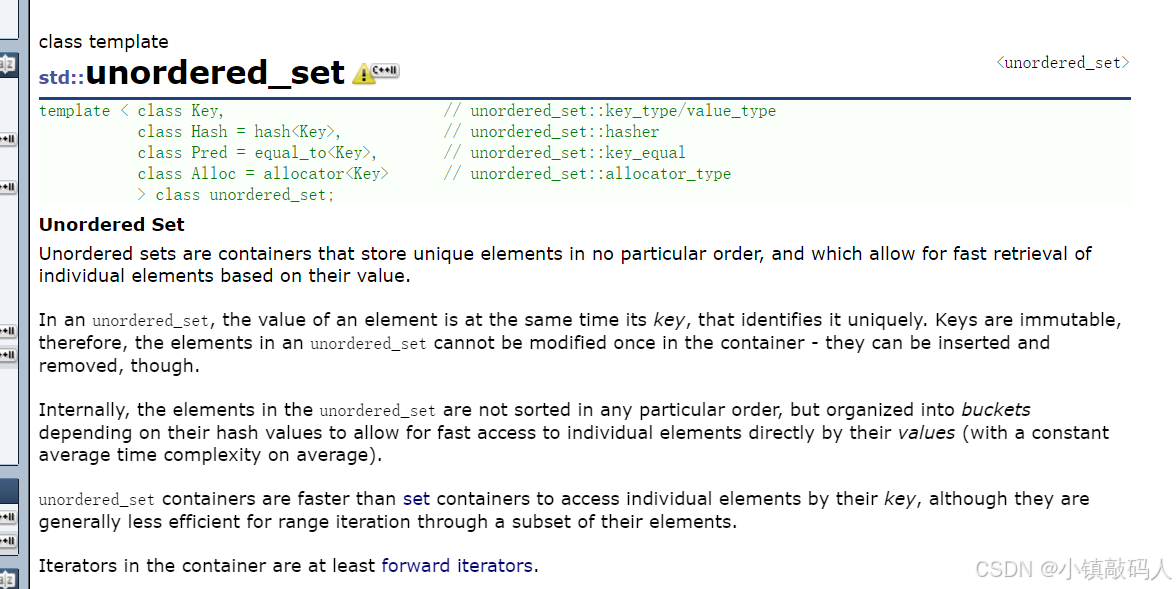
最后一行,迭代器在容器中至少是前进迭代器意思是:
unordered_set的方法接口
unordered_set的使用
#include<iostream>
#include<unordered_map>
#include<unordered_set>
#include<set>
#include<map>
using namespace std;
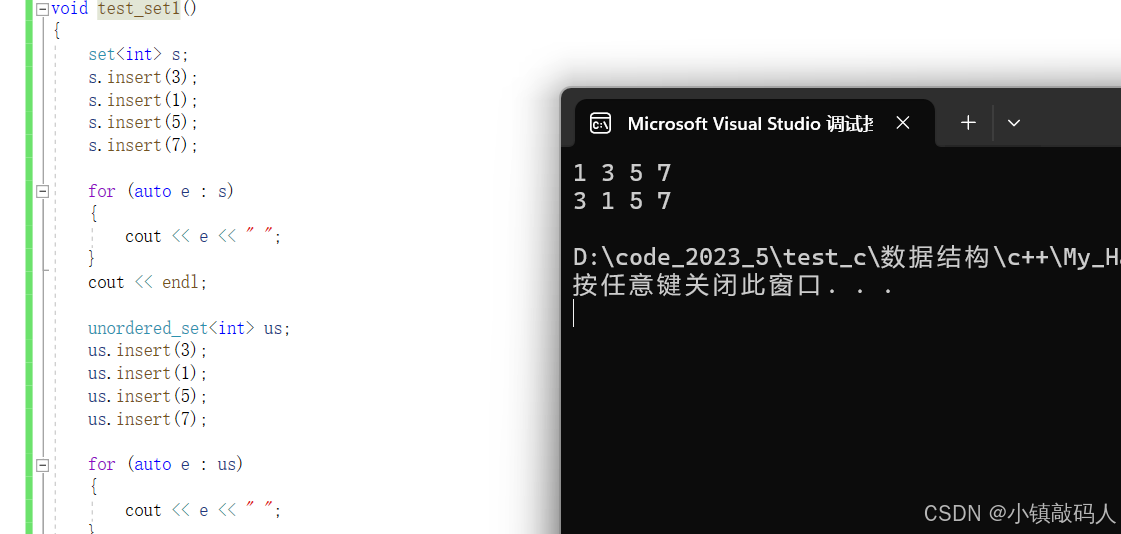
void test_set1()
{
set<int> s;
s.insert(3);
s.insert(1);
s.insert(5);
s.insert(7);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
unordered_set<int> us;
us.insert(3);
us.insert(1);
us.insert(5);
us.insert(7);
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test_set1();
return 0;
}
运行结果:
unordered_set与set的效率比较
#include<iostream>
#include<unordered_map>
#include<unordered_set>
#include<set>
#include<map>
using namespace std;
int main()
{
const size_t N = 10000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
//v.push_back(rand()); // N比较大时,重复值比较多
//v.push_back(rand()+i); // 重复值相对少
v.push_back(i); // 没有重复,有序
}
// 21:15
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : v)
{
s.find(e);
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << endl;
size_t begin4 = clock();
for (auto e : v)
{
us.find(e);
}
size_t end4 = clock();
cout << "unordered_set find:" << end4 - begin4 << endl << endl;
cout <<"插入数据个数:"<< s.size() << endl;
cout <<"插入数据个数:" << us.size() << endl << endl;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
return 0;
}
运行结果:
1.重复值较少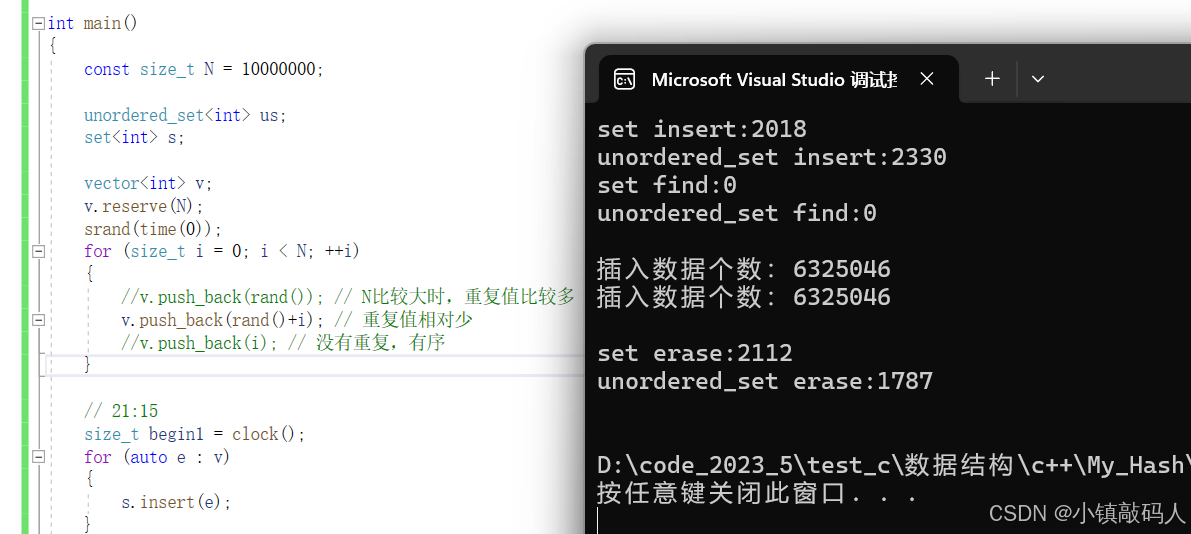
2.没有重复值,有序
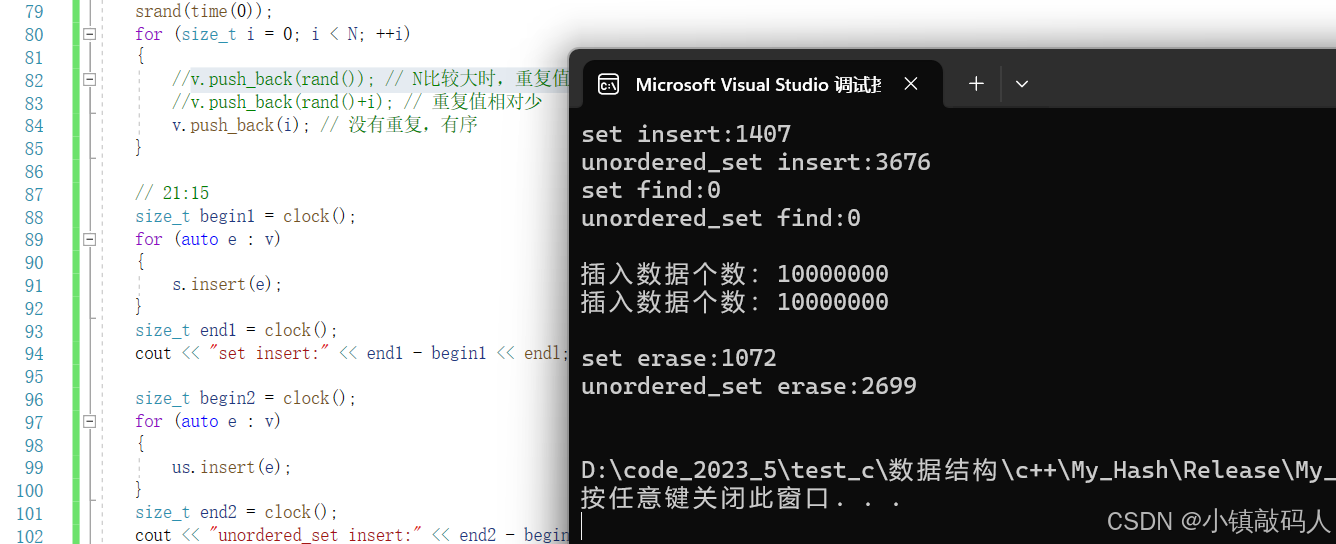
3.有大量重复值
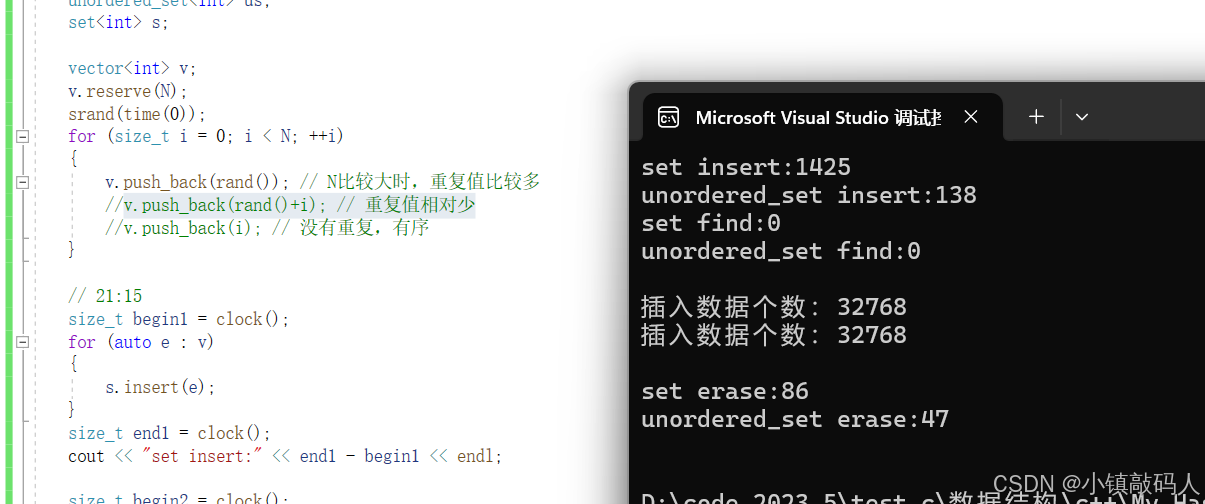
总结:没有重复值(或者重复值较少),unordered_set比set的插入、删除效率略逊。有大量重复值前者更快,查找效率在Release版本下看不出来,不过应该理想情况是哈希表的查找更具有优势。
OJ题
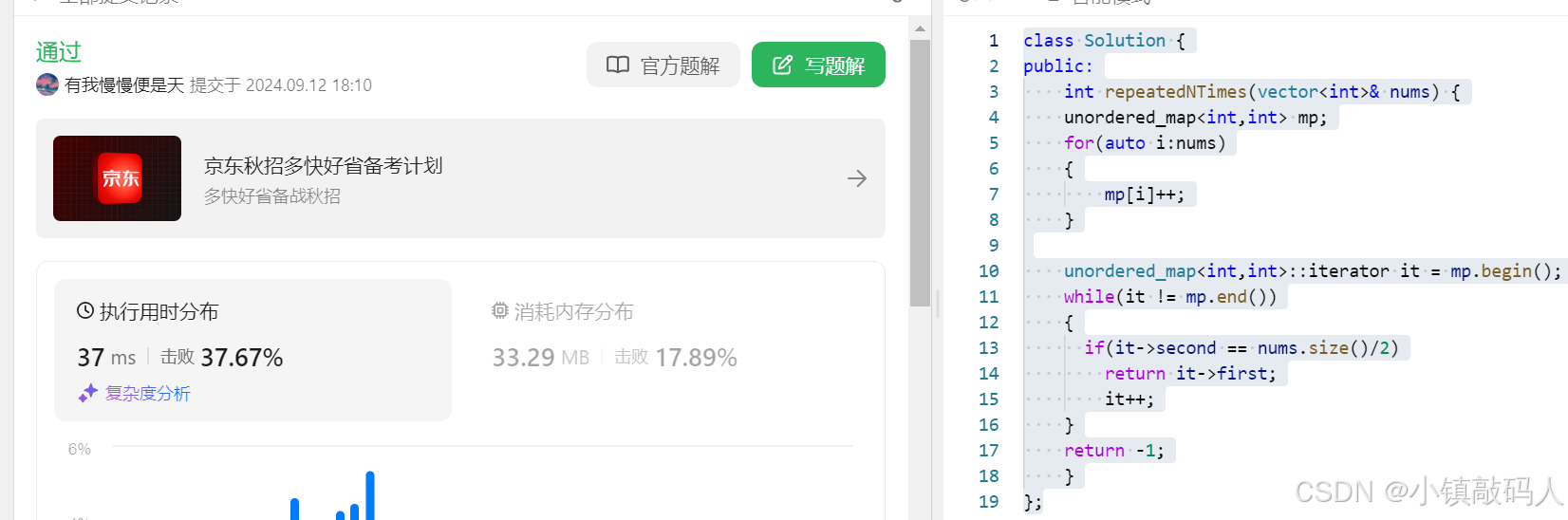
在长度 2N 的数组中找出重复 N 次的元素

ak代码:
class Solution {
public:
// 函数用于找出在nums数组中重复nums.size()/2次的元素
int repeatedNTimes(vector<int>& nums) {
// 使用unordered_map来统计每个元素的出现次数
unordered_map<int, int> mp;
// 遍历nums数组中的每个元素
for (auto i : nums) {
// 更新当前元素在哈希表中的计数
mp[i]++;
}
// 使用迭代器遍历哈希表
unordered_map<int, int>::iterator it = mp.begin();
// 遍历哈希表中的所有元素
while (it != mp.end()) {
// 如果当前元素的出现次数等于数组长度的一半
if (it->second == nums.size() / 2) {
// 返回当前元素
return it->first;
}
// 移动到哈希表中的下一个元素
it++;
}
// 如果没有找到满足条件的元素,则返回-1
return -1;
}
};
ak截图:
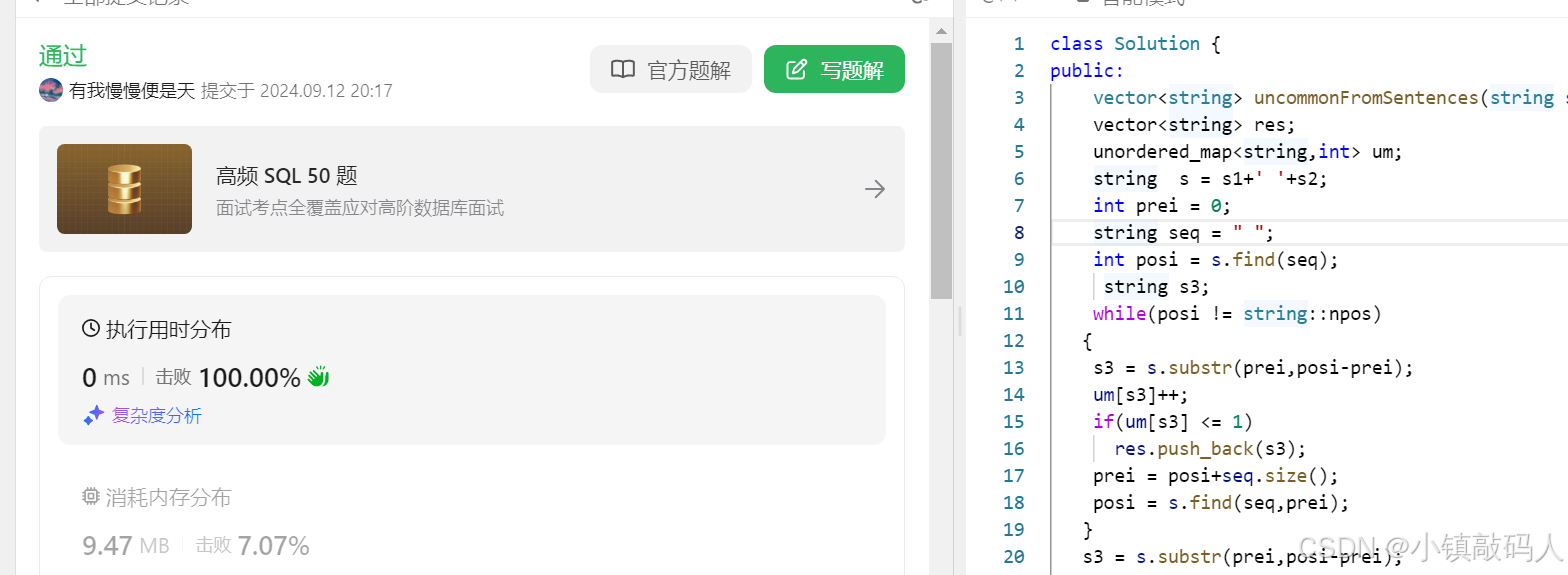
两句话中的不常见单词

ak代码:
class Solution {
public:
vector<string> uncommonFromSentences(string s1, string s2) {
vector<string> res; // 存储结果的向量
unordered_map<string, int> um; // 用于统计单词出现次数的哈希表
// 将两个句子连接成一个长字符串,用空格分隔
string s = s1 + ' ' + s2;
// 使用空格作为分隔符来遍历字符串
int prei = 0; // 上一个单词的结束位置
string seq = " "; // 分隔符
int posi = s.find(seq, prei); // 从当前位置开始查找分隔符的位置
// 循环直到字符串末尾
while (posi != string::npos) {
string s3 = s.substr(prei, posi - prei);
um[s3]++; // 更新单词出现次数
prei = posi + seq.size(); // 更新下一个单词的起始位置
posi = s.find(seq, prei); // 继续查找下一个分隔符
}
// 不要忘记添加最后一个单词
if (prei < s.size()) {
string s3 = s.substr(prei);
um[s3]++;
}
// 遍历哈希表,将只出现一次的单词加入结果向量
for (const auto& p : um) {
if (p.second == 1) {
res.push_back(p.first);
}
}
return res;
}
};
ak截图:
这个题目有几个坑点需要注意一下:
1.s1字符串和s2字符串合并的时候不要忘了加空格' '。
2. while循环结束后,可能还剩下最后一个单词没有处理。(两个字符串都为空的情况例外)
- 本人知识、能力有限,若有错漏,烦请指正,非常非常感谢!!!
- 转发或者引用需标明来源。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)