推荐大模型系列-NoteLLM-2: Multimodal Large Representation Models for Recommendation(一)
本文提出NoteLLM-2框架,旨在解决大语言模型(LLMs)在多模态商品推荐(I2I)中的视觉信息忽视问题。研究发现直接微调的LLMs存在文本偏向性,为此创新性地设计了两种方法:基于提示词的多模态上下文学习(mICL)分离视觉与文本内容,以及晚期融合技术直接整合视觉信息。实验表明,该框架显著提升了多模态表征性能,在召回任务中优于传统方法。研究首次探索了LLM辅助的多模态表征在推荐场景的应用,为跨
目录
上一篇文章:推荐大模型系列-NoteLLM: A Retrievable Large Language Model for Note Recommendation(三)
一、摘要
大语言模型(LLMs)在文本理解与嵌入任务中展现出卓越能力,但其在多模态表征(尤其是商品间推荐I2I)领域的潜力尚未充分挖掘。尽管利用现有多模态大语言模型(MLLMs)完成此类任务具有前景,但此类模型相较于对应LLMs的发布滞后性及表征任务中的低效性带来了挑战。
为解决这些问题,提出一种端到端微调方法,可灵活整合任意现有LLMs与视觉编码器以实现高效多模态表征。初步实验发现微调后的LLMs常忽略图像内容。为此提出NoteLLM-2框架,通过两种创新方法增强视觉信息:基于提示词的方法分离视觉与文本内容,采用多模态上下文学习策略平衡跨模态注意力;晚期融合技术直接将视觉信息整合至最终表征层。线上线下大规模实验验证了该方案的有效性。代码已开源:https://github.com/Applied-Machine-Learning-Lab/NoteLLM
二、介绍
随着互联网的发展,大多数在线平台通过多模态信息提升用户参与度[50,51,54]。多模态推荐成为这些平台的必要服务[31],其核心是基于用户对物品多模态信息的兴趣进行推荐。这类技术主要依赖多模态表征——将原始多模态内容提取为稠密嵌入[62],再通过这些嵌入衡量相似度。多模态表征的增强能从根本上改进下游任务,如检索[32]、聚类[34]和物品建模[51]。现有研究如CLIP[36]和METER[15]已探索多模态表征,尽管取得显著进展,但多数模型的参数量仍存在扩展空间[45,46]。现有工作[45,46]主要聚焦视觉模型的扩展,却忽视了文本分支。同时,由于缺乏纯文本导向的充分预训练[36,45,46,59],多模态模型中的文本分支常表现出次优的文本理解能力[6,60]。因此,增强多模态模型中的文本理解至关重要。
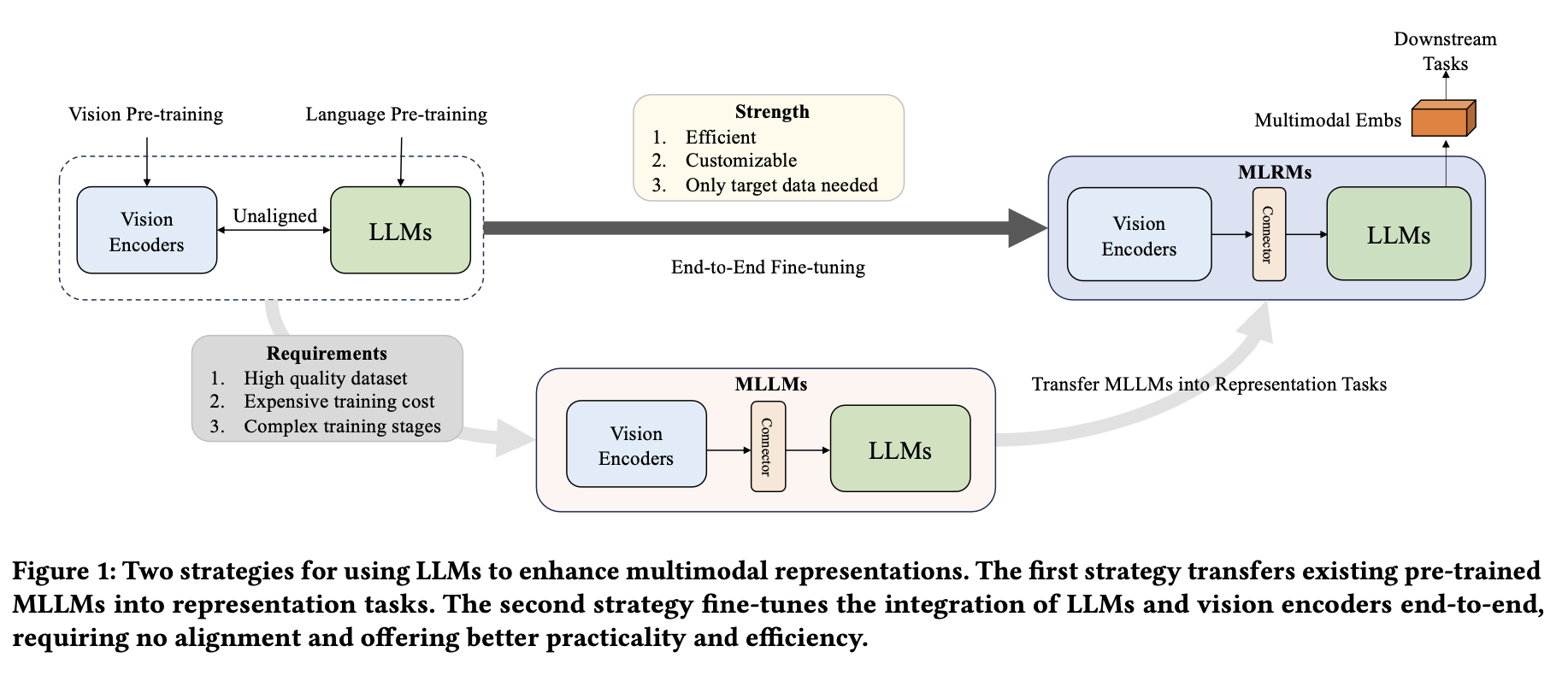
近期,大语言模型(LLMs)在文本理解与生成方面展现出卓越能力[2,7,20,47]。多项研究表明LLMs在生成文本嵌入上的优势[4,21,32,34,61]。然而,利用LLMs增强多模态表征中文本理解的研究仍不足。如图1所示,可行方案之一是适配开源多模态大语言模型(MLLMs)[2,24,27,30]用于表征任务。但开发MLLMs需大量高质量多模态数据和算力进行预训练[2,27],导致非多模态LLMs的发布早于其多模态版本[1,12,20]。这种时滞限制了采用最先进LLMs与视觉编码器进行定制化训练。此外,现有MLLMs因侧重多模态理解与生成[40],在表征场景中效率不足。
为此,设计了一种端到端微调方法,可灵活集成任意现有LLMs与视觉编码器,构建高效多模态表征模型。该方法的优势在于:当目标LLMs缺乏预训练视觉组件时[1,12,20],仅需目标领域数据即可实现定制,无需预训练数据收集。同时可针对表征任务优化模型结构,在保证性能的同时提升效率。这类通过LLMs增强多模态表征的模型称为多模态大表征模型(MLRMs)。
本研究探索了多模态大语言模型(MLRMs)在商品间(I2I)多模态推荐场景中的应用。通过初步微调实验发现,直接端到端微调的MLRMs存在文本偏向性,视觉内容被忽视。图像仅用于放大多模态内容中的关键元素,而非通过表征直接聚合。为解决这一问题,提出新型微调框架NoteLLM-2,包含两种缓解视觉忽视的方法:
多模态上下文学习(mICL)
将多模态内容拆分为视觉与文本组件,分别压缩为两种模态压缩词。各模态压缩词在批次内与对应模态的压缩词进行对比学习。
延迟融合机制
多数MLLMs采用早期融合,将视觉特征映射至LLM的文本特征空间,通过LLM实现视觉与文本嵌入交互。早期融合虽能加强多模态信息交互,但易导致LLM融合过程中丢失原始视觉信息。基于此,在早期融合基础上引入延迟融合:采用多模态门控融合机制,结合视觉编码器的表征与LLM生成的表征,最终输出多模态表征。
实验与贡献
大量实验验证了NoteLLM-2的有效性,主要贡献包括:
- 首次探索LLM辅助的多模态表征在推荐场景的应用,提出端到端微调方法,可灵活集成现有LLMs与视觉编码器构建高效MLRMs。
- 揭示未对齐MLRMs在表征任务中因忽视视觉信息导致模态失衡,针对性设计含mICL和延迟融合的NoteLLM-2框架。
- 线上线下实验验证该框架在多模态推荐表征中的优越性。
三、初步调查
3.1 问题陈述
在设定场景中,每个资源代表一条用户生成的笔记,记录其生活经历。假设笔记池为 ,其中
为笔记数量。
每条笔记包含文本信息(如标题、主题、内容)及图像。第条笔记表示为
,其中
、
、
、
分别对应标题、主题、内容和图像。
给定一条查询笔记 ,基于多模态内容相似度,图像到图像(I2I)推荐系统对笔记池
进行排序。该系统的目标是将相关的目标笔记优先排序。
3.2 MLRMs的基础表示方法
参考相关研究,采用带有明确单字限制的提示(prompt)将多模态内容压缩为单一嵌入向量。具体实现中,使用JSON格式呈现注释内容,提示词设计如下:

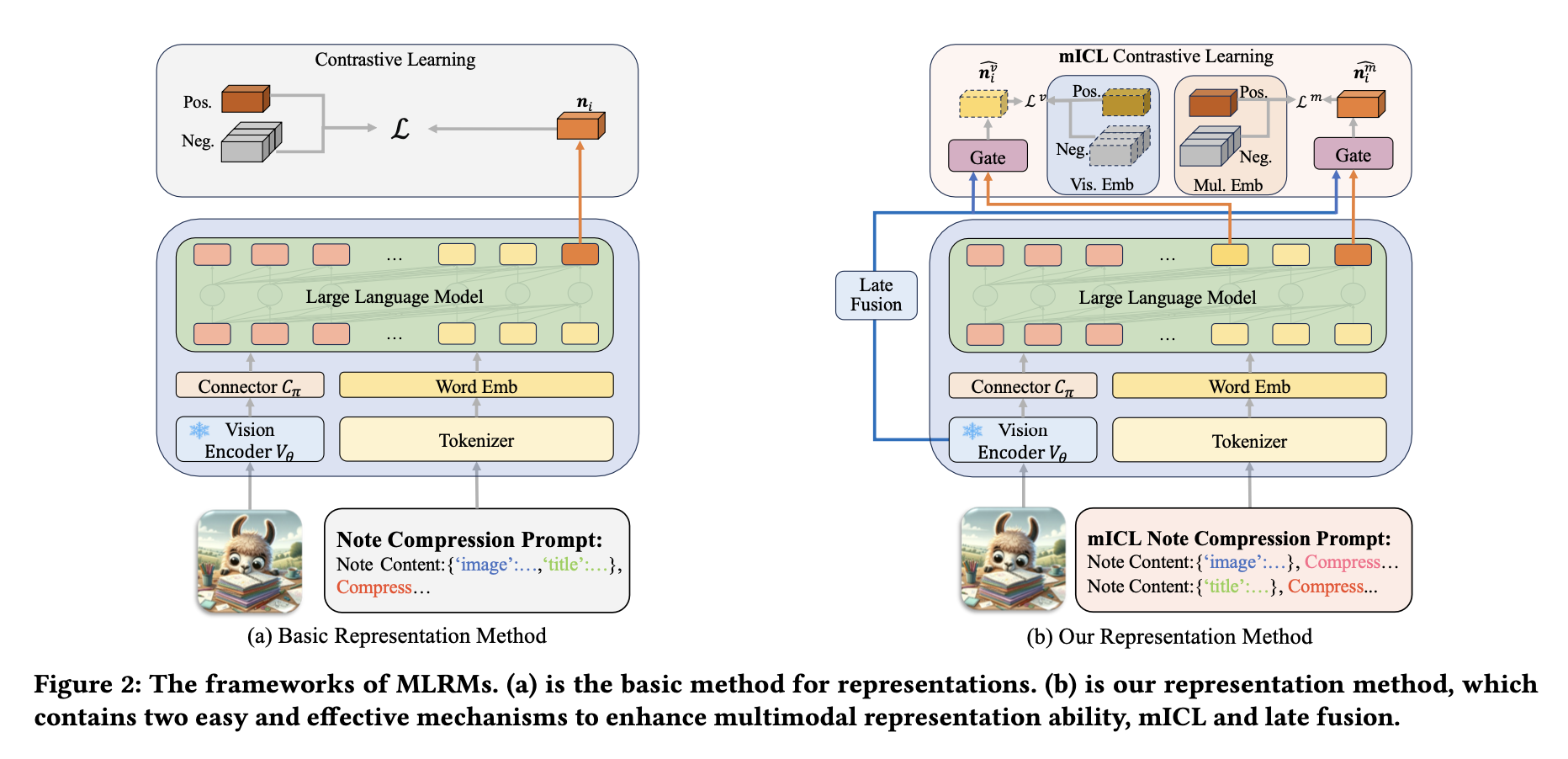
视觉嵌入处理框架
在该模板中,<IMG>是一个占位符,会被原始图像𝑣𝑖经过视觉嵌入处理后替换。整体框架如图2(a)所示。该框架首先利用视觉编码器𝑉𝜃将预处理后的图像𝑣𝑖提取为视觉特征(包含在笔记𝑛𝑖中),其中𝐿是视觉特征的长度,h𝑣是视觉特征的维度,且𝑍𝑣 = 𝑉𝜃(𝑣𝑖)。
连接器𝐶𝜋将视觉特征𝑍𝑣转换到LLM的词嵌入空间,形成视觉嵌入𝐸𝑣 ∈ R𝐿𝑐×h𝑡,其中𝐿𝑐是输入LLM的视觉嵌入长度,h𝑡是LLM隐藏状态的维度,且𝐸𝑣 = 𝐶𝜋(𝑍𝑣)。图像处理完成后,文本提示被分词为离散索引,并生成文本词嵌入𝐸𝑡 ∈ R𝑇×h𝑡,其中𝑇是文本令牌的长度。
为了将视觉嵌入插入文本嵌入的正确位置,用视觉嵌入𝐸𝑣替换<IMG>令牌位置的词嵌入,形成多模态嵌入𝐸𝑚 ∈ R(𝐿𝑐+𝑇−1)×h𝑡。最后,使用LLM 𝐿𝐿𝑀𝜇处理多模态嵌入,生成最后的隐藏状态𝐻 ∈ R(𝐿𝑐+𝑇−1)×h𝑡,其中𝐻 = 𝐿𝐿𝑀𝜇(𝐸𝑚)。取𝐻的最后一个嵌入作为笔记𝑛𝑖的表示𝒏𝑖。该方法通过下一令牌预测的形式约束LLM将多模态内容压缩为一个嵌入。
对比学习优化
由于LLM使用语言建模损失训练[3, 24, 27, 30],与表示任务差异显著,为此采用对比学习来弥合差距。每个小批量包含𝐵个相关笔记对,共2𝐵个笔记。对于小批量中的任意笔记𝑛𝑖(1 ≤ 𝑖 ≤ 2𝐵),其相关笔记记为𝑛𝑖+。参考[35],通过梯度下降最小化对比损失,具体公式如下:
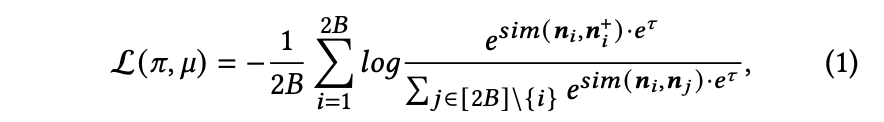
其中𝜏表示可学习的温度参数,𝑠𝑖𝑚(𝑎,𝑏) = 𝑎⊤𝑏/(∥𝑎∥∥𝑏∥) 为向量𝑎和𝑏的余弦相似度。
L(𝜋, 𝜇) 表示仅更新连接器𝐶𝜋和大语言模型𝐿𝐿𝑀𝜇,同时保持视觉编码器𝑉𝜃冻结,目的是实现更大的批处理规模和更好的性能[24]。
3.3 数据集与实验设置
数据集构建方法
为避免依赖人工标注构建相关笔记对,采用共现机制衡量笔记间的相关性(基于用户共同阅读频率)。具体计算方式如下:当用户先阅读笔记𝑛𝐴后点击笔记𝑛𝐵时,共现得分统计公式为:
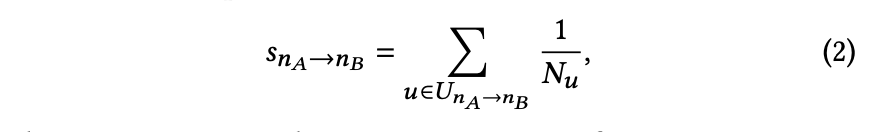
共现评分与相关笔记构建
𝑠𝑛𝐴→𝑛𝐵 表示从笔记𝑛𝐴到笔记𝑛𝐵的共现评分,𝑈𝑛𝐴→𝑛𝐵 是浏览过笔记𝑛𝐴后点击笔记𝑛𝐵的用户集合,𝑁𝑢 表示用户𝑢在行为数据中点击的不同笔记数量。计算每对笔记的共现评分后,构建集合S𝑛𝑖,包含从笔记𝑛𝑖到其他所有笔记的共现评分,即S𝑛𝑖 = {𝑠𝑛𝑖→𝑛𝑗 | 1 ≤ 𝑗 ≤ 𝑚, 𝑖 ≠ 𝑗}。剔除S𝑛𝑖中高于𝑢𝑝或低于𝑙𝑜𝑤的异常值后,筛选出共现评分最高的前𝑡个笔记作为𝑛𝑖的相关笔记。
数据集细节
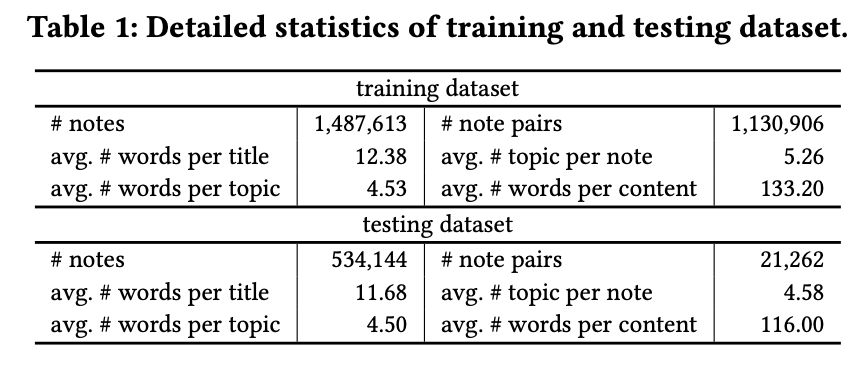
从平台获取真实多模态I2I数据集,训练集通过随机选取两周内用户行为数据中的相关笔记对构建,其中十分之一作为验证集。测试集从后续一周随机选取的笔记中生成,确保与训练集无重复。测试集中统计相关笔记对数量,具体数据见表1。
为评估ML-RMs的多模态表征能力而非依赖文本,测试集中包含短笔记对(token长度<50,约占测试笔记的10%)。短查询对指查询笔记为短笔记的对,短目标对指目标笔记为短笔记的对。测试集中短查询对数量为5,620,短目标对数量为5,582。
实验设置
构建相关笔记对时,共现评分上限𝑢𝑝设为30,下限𝑙𝑜𝑤为0.01,𝑡设为3。标题超过20词、内容超过80词时截断以符合推理长度限制。微调实验中,为公平比较,添加线性投影层将笔记嵌入降维至64维。批次大小𝐵为128,每批包含256笔记,初始温度系数𝜏设为3。其他训练细节见附录A。
训练配置说明
在8张80GB显存的Nvidia A100 GPU上进行训练,每张GPU的批处理大小为16。
关键参数解析
- 硬件规格:使用8张显存容量为80GB的Nvidia A100显卡
- 批处理设置:每张显卡每次训练处理的样本数量(batch size)设置为16
评估方法
针对召回任务,基于查询笔记内容生成测试池中其余笔记的相似度排序列表,根据目标笔记在列表中的位置计算召回率。在测试集的所有对、短查询对、短目标对上报告Recall@100、Recall@1k和Recall@10k。为鲁棒性,使用随机种子{42,43,44}测试三次并取平均结果。
3.4 微调MLRMs的多模态表征性能
在附录D中对现有多种MLLMs进行了零样本实验,发现零样本不足以使MLLMs适应表征任务,其表现甚至低于简单基线方法BM25[39]。这是由于预训练任务与表征任务之间的不对齐[21, 61]。因此,针对表征任务对MLLMs进行微调是必要的。
设计了三种端到端MLRM以验证表征微调方法的有效性:
- MTomato-Base:以Tomato(基于LLaMA 2[47]持续预训练的LLM,缺乏视觉感知能力,预训练细节见附录B)作为LLM,CLIP ViT-B[36]作为视觉编码器,随机初始化的Q-Former[27]作为连接器以提升效率。
- MQwen-Base:在MTomato-Base中用Qwen-Chat[2]替换Tomato。
- MQwen-bigG:在MQwen-Base中用ViT-bigG[19]替换CLIP ViT-B。为提升效率,这些模型的视觉嵌入长度均设为16。
对比基线包括两种预训练MLLM:BLIP-2和Qwen-VL-Chat[3]。所有模型的视觉编码器均冻结以支持更大批处理规模。端到端MLRMs的细节见附录B。
为评估MLRMs的有效性,与以下基线进行比较:
- CLIP ViT-B[36]:仅使用图像输入训练。
- BM25[39]:基于查询词频统计查询与文档相关性的基础基线。
- RoBERTa-wwm-ext[10]:纯文本输入的经典繁体中文BERT类[25]文本编码器。
- Tomato:基于LLaMA 2[47]持续预训练的LLM。
- NoteLLM[61]:将嵌入生成与主题生成统一为单一任务。
- METER Merge-attn与METER Co-attn[15]:采用最优训练策略训练视觉-语言Transformer,前者使用合并注意力融合模块,后者使用协同注意力。
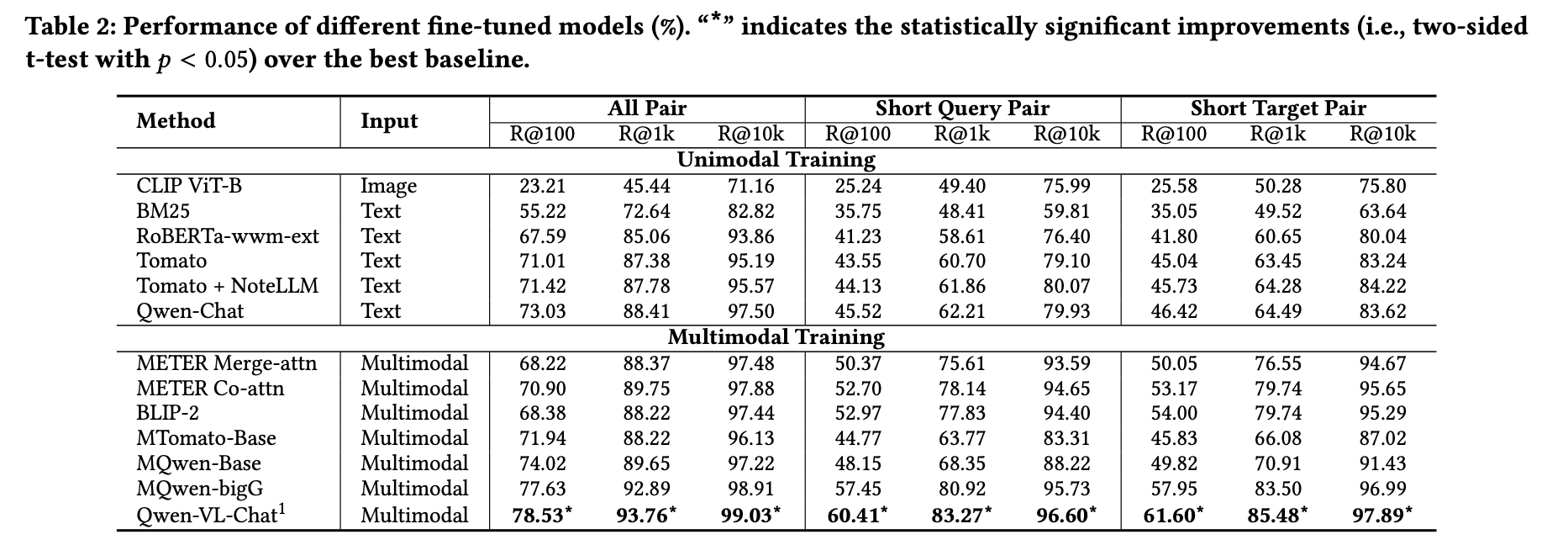
实验结果如表2所示,主要结论如下:
- MLRMs显著优于非LLM基线。Qwen-VL-Chat在R@100上较传统方法METER Co-attn提升10.78%。
- 端到端微调可增强多模态表征能力。MQwen-bigG较Qwen-Chat在R@100上提升6.31%。但若视觉编码器较小(如CLIP ViT-B),多模态感知提升有限:MTomato-Base较Tomato仅提升1.31%,MQwen-Base较Qwen-Chat仅提升1.36%。
- 尽管MQwen-bigG效率高于使用相同视觉编码器和LLM的Qwen-VL-Chat(见4.4节),性能差距仍存在。
备注:由于Qwen-VL-Chat模型每张图像需处理256个视觉嵌入向量,该模型的训练使用了32张80GB显存的NVIDIA A100 GPU,且每张GPU的批处理大小为4。
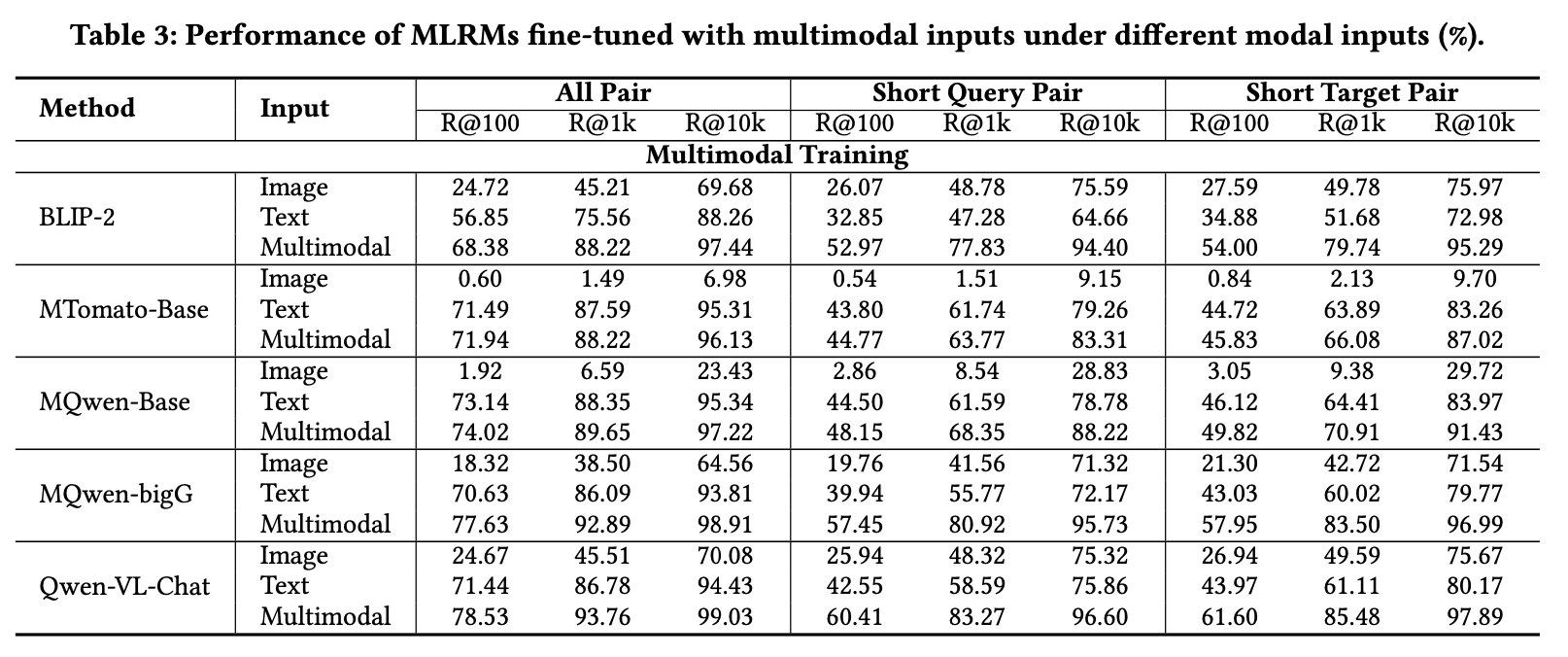
表3展示了不同模态输入下微调MLRMs的评估结果:
- MTomato-Base和MQwen-Base在纯图像输入时几乎无法表征图像内容,忽略了视觉信息。
- 因采用更强视觉编码器,MQwen-bigG展现出更优的视觉表征能力,但仍逊于经过多模态预训练的BLIP-2和Qwen-VL-Chat。
3.5 探究微调MLRMs的信息流
为深入分析端到端微调MLRMs忽略视觉信息的原因,从信息流角度研究了两种模态标记在不同LLM层中的注意力模式。采用显著性分数[48]分析注意力矩阵中压缩词与两种模态标记的交互作用。从训练数据集中随机批量选取10,000条笔记统计显著性分数,计算公式如下:
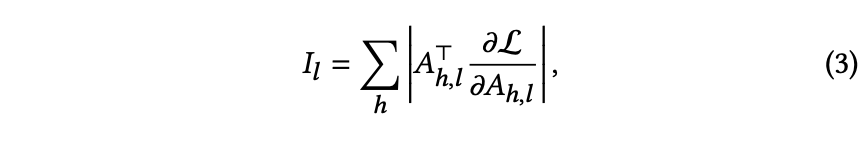
𝐴h,𝑙 表示第𝑙层中第h个注意力头的注意力矩阵值,L为对比损失。第𝑙层的显著矩阵𝐼𝑙通过对所有注意力头求和计算得出。𝐼𝑙(𝑖, 𝑗)表示从第𝑗个词到第𝑖个词的信息流重要性。为分析不同模态对压缩词的相对重要性,将𝐼𝑙拆分为以下三部分:𝑆𝑣表示从视觉嵌入𝐸𝑣到最终压缩位置𝑐的信息流平均显著性。
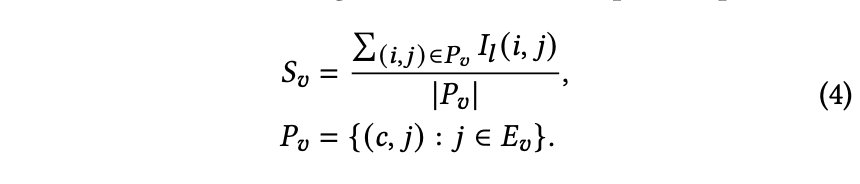
𝑆𝑡,表示从文本嵌入 𝐸𝑡 到最终压缩位置 𝑐 的信息流平均显著性。
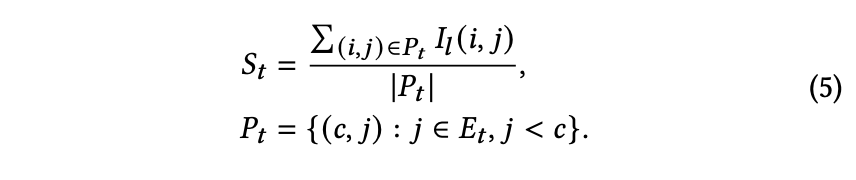
排除由𝑆𝑣和𝑆𝑡表示的影响后,所有词语间信息流的平均显著性。
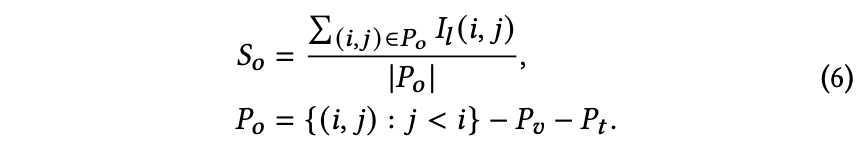
-
术语解析
- 注意力矩阵(Attention Matrix):用于衡量输入序列中不同位置间的关联强度。
- 显著矩阵(Saliency Matrix):通过聚合注意力头结果生成的综合重要性指标。
- 模态(Modalities):指不同类型的数据输入(如文本、视觉嵌入)。
- 文本嵌入(𝐸𝑡):指通过模型(如Transformer)生成的文本向量表示。
- 信息流:描述数据或特征在模型中的传递过程。
- 压缩位置(𝑐):可能指模型输出的聚合或压缩表示(如CLS token或池化结果)。
显著性矩阵三部分结果分析
-
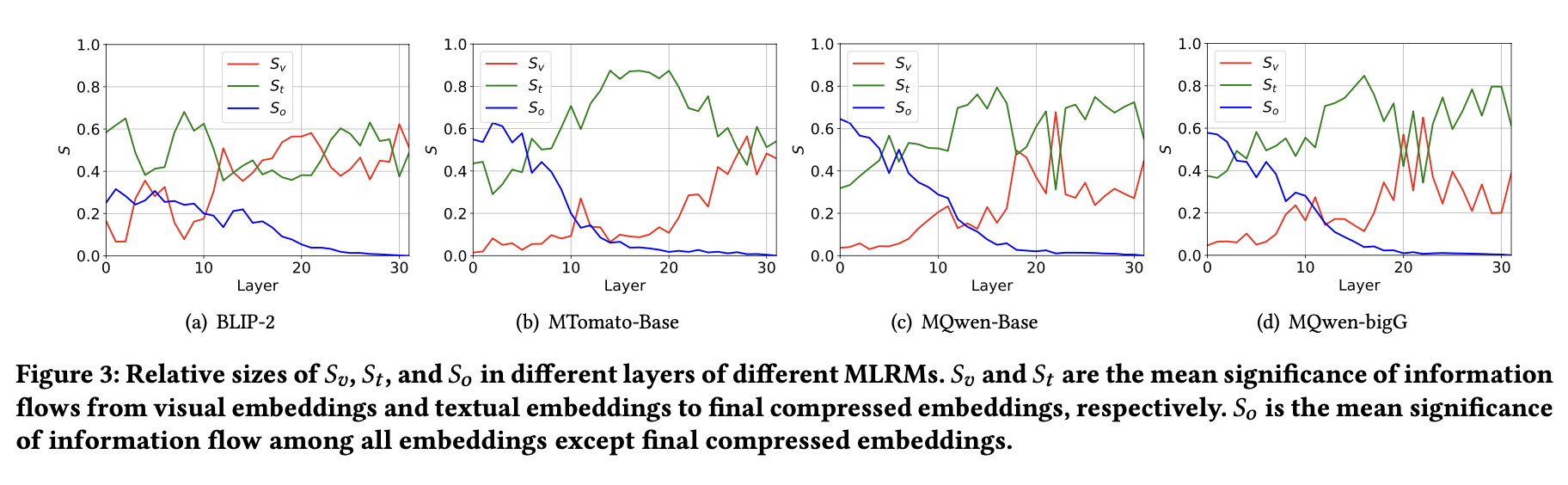 图3展示了显著性矩阵的三部分结果。研究发现,预训练多模态大语言模型(如BLIP-2和Qwen-VL-Chat,详见附录C)在浅层网络中视觉显著性(𝑆𝑣)与跨模态显著性(𝑆𝑜)保持平衡。然而,未经预训练、直接端到端微调的多模态检索模型(MLRMs)在浅层表现出低𝑆𝑣与高𝑆𝑜特性。低𝑆𝑣表明视觉信息到最终压缩嵌入的直接信息流有限,而高𝑆𝑜说明视觉与文本嵌入间的信息交互显著。这意味着图像引入带来的信息流增益更倾向于流向关键多模态嵌入,而非直接聚合至最终压缩嵌入中。
图3展示了显著性矩阵的三部分结果。研究发现,预训练多模态大语言模型(如BLIP-2和Qwen-VL-Chat,详见附录C)在浅层网络中视觉显著性(𝑆𝑣)与跨模态显著性(𝑆𝑜)保持平衡。然而,未经预训练、直接端到端微调的多模态检索模型(MLRMs)在浅层表现出低𝑆𝑣与高𝑆𝑜特性。低𝑆𝑣表明视觉信息到最终压缩嵌入的直接信息流有限,而高𝑆𝑜说明视觉与文本嵌入间的信息交互显著。这意味着图像引入带来的信息流增益更倾向于流向关键多模态嵌入,而非直接聚合至最终压缩嵌入中。深层网络行为变化
随着网络层数加深,𝑆𝑣逐渐上升而𝑆𝑜急剧下降。这是因为多模态嵌入在浅层捕获上下文信息(通过𝑆𝑜体现)后,模型转而聚焦于将相关信息直接聚合至最终压缩嵌入以完成表征任务。与预训练模型不同,端到端MLRMs的最终压缩嵌入在浅层几乎不含直接视觉信息,其早期视觉信息积累主要依赖文本嵌入中上下文信息的聚合。在深层网络中,最终压缩嵌入通过注意力机制逐步融合与已聚合文本信息相关的图像内容。
端到端模型的特性差异
端到端微调的MLRMs中,图像主要辅助信息流识别关键内容(参见文献[43,44]),而非直接被表征聚合。此外,文本信息流在端到端MLRMs中显著超越视觉信息流。
本篇关于一些初步调查就到这里,下一篇会详细介绍方法论~
-
下一篇传送门(尽快更新ing):

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)