计算机毕业设计之基于大数据的网站流量日志数据分析系统
本文基于爬虫技术构建网站流量分析系统,通过数据采集、预处理、分析和可视化四个步骤,实现流量日志的有效管理。系统采用Spark框架进行深度数据分析,挖掘访问趋势、用户分布等关键指标,并通过Vue.js实现可视化展示。实验证明,该系统能准确统计流量数据,为网站优化提供数据支持,同时具备数据导入功能,确保分析的全面性。
摘要
随着互联网技术的飞速发展和电子商务的日益普及,网站已成为企业展示形象、推广产品、提供服务的重要平台。在这个过程中,流量日志网站流量成为了衡量网站受欢迎程度和运营效果的关键指标。
首先,本文采用爬虫技术收集了景点流量日志网站上的大量流量日志信息。然后,利用爬虫优化算法对爬取到的数据进行预处理,包括去重、过滤掉不符合要求的流量日志等。接下来,对处理后的数据进行深入分析,挖掘出每日访问趋势,业务面访问量,状态码分布比例,响应大小分析,用户地理分布,浏览器分布,日志数据等信息。最后,将这些信息通过可视化技术展示出来,以便用户能够更直观地了解流量日志市场的现状。利用可视化技术将分析结果展示出来,使用户能够更直观地了解流量日志市场的现状,便于用户做出更好的出行规划。
实验结果表明,系统不仅能够准确统计网站流量,还能揭示用户访问模式和偏好。论文详细阐述了系统的架构设计、数据处理流程以及关键技术的实现。系统采用了一系列数据预处理、特征提取和模式识别算法,有效提高了数据分析的准确性和效率。该系统能够在大数据环境下稳定运行,为网站运营者提供了有力的数据支持,有助于优化网站结构和提升用户体验。
系统概述
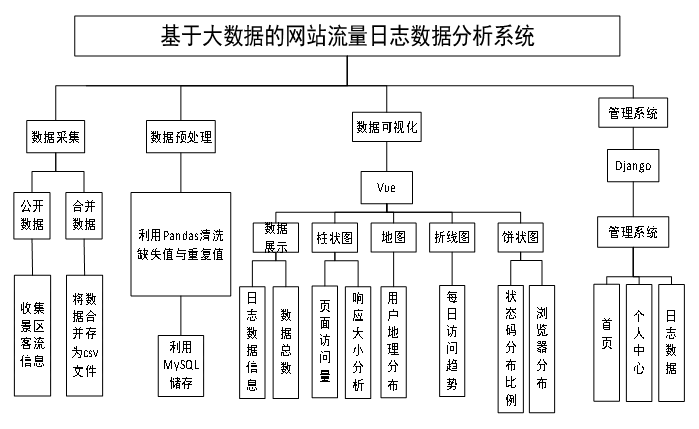
本研究的实施分为四个主要步骤:数据采集、数据预处理、数据分析和数据可视化。首先,进行了数据采集工作。从公开渠道收集了大量与网站流量日志相关的数据,包括每日访问趋势,业务面访问量,状态码分布比例,响应大小分析,用户地理分布,浏览器分布,日志数据等。为了确保数据的全面性和准确性,还对这些数据进行了合并和处理,将其整合为一个统一的CSV文件格式。接下来是数据预处理阶段。由于原始数据可能存在缺失值和不一致的地方,需要对其进行清洗和整理。使用了Pandas库来读取CSV文件,并对数据进行筛选、填充缺失值以及去除重复项等操作。经过这一系列的处理,的数据集变得更加干净和有序。然后进入数据分析环节。利用Spark框架对预处理后的数据进行深度挖掘和分析。通过编写自定义脚本,对不同网站的流量日志情况进行了比较,分析了页面访问、浏览器发布、状态码分布等因素对流量日志的影响,并得出了相应的结论和建议。最后是数据可视化部分。将分析得到的结果转化为图表形式,以便于理解和传播。使用了Vue.js框架来创建交互式的网页界面,管理员可以通过点击不同的按钮来查看各种统计信息和趋势图。此外,还制作了地图图和饼状图来展示某些特定的数据分布情况。
管理员登录界面
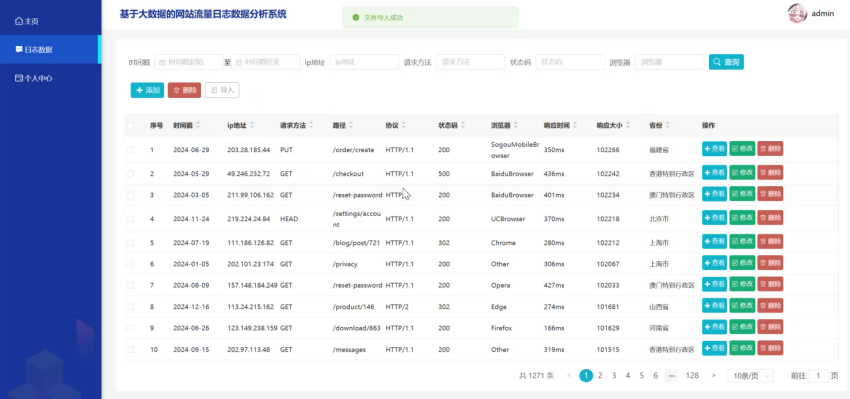
管理员在日志数据管理模块中,通过数据爬虫技术自动抓取流量日志信息,并进行数据清洗以保障信息准确性。模块允许管理员查看日志数据信息详情、修改信息、删除记录以及查询。系统提供了友好的操作界面,管理员可轻松编辑信息,而爬虫功能则后台自动运行,确保数据的实时更新和高质量,从而有效支持管理员的日常信息管理工作。在该模块设有数据导入模块,通过上传excel表格进行导入数据,即使原始数据量有限,也能扩充数据集以供分析和测试使用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)