【强化学习】[page11]随机梯度下降的收敛模式
本章节并未介绍新的强化学习算法,而是重点讲解了随机逼近的基础知识,如Robbins-Monro(RM)算法和随机梯度下降(SGD)算法。与许多其他求根算法相比,RM算法的独特优势在于。研究证明,SGD算法实质上是RM算法的一个特例。均值估计作为贯穿本章的核心议题,其算法(6.4)成为本书介绍的首个随机迭代算法。我们通过分析表明,该算法可视为特殊形式的SGD算法。后续第七章将揭示时序差分学习算法具有
本章节并未介绍新的强化学习算法,而是重点讲解了随机逼近的基础知识,如Robbins-Monro(RM)算法和随机梯度下降(SGD)算法。与许多其他求根算法相比,RM算法的独特优势在于无需目标函数或其导数的解析表达式。研究证明,SGD算法实质上是RM算法的一个特例。
均值估计作为贯穿本章的核心议题,其算法(6.4)成为本书介绍的首个随机迭代算法。我们通过分析表明,该算法可视为特殊形式的SGD算法。后续第七章将揭示时序差分学习算法具有与之相似的表征形式。
问:什么是随机近似?
答:随机近似是指一类广泛使用的随机迭代算法,用于求解寻根或优化问题。问:为什么我们需要研究随机近似?
答:这是因为第七章将要介绍的时序差分强化学习算法可以被视为随机近似算法。通过学习本章内容,我们可以更好地准备,初次接触这些算法时就不会感到突兀。问:为什么本章频繁讨论均值估计问题?
答:这是因为状态值和动作值被定义为随机变量的均值。第七章介绍的时序差分学习算法与用于均值估计的随机近似算法具有相似性。
目录:
- 随机梯度下降: 收敛模式
- 随机梯度下降: 收敛数学证明
- 随机梯度下降 例子
-
SGD确定性
- BGD, SGD, and mini-batch GD
一 随机梯度下降: 收敛模式
随机梯度下降(Stochastic Gradient Descent, SGD)是机器学习中最核心的优化算法之一。与传统的梯度下降不同,SGD使用随机梯度而非真实梯度,这引发了一个重要问题:SGD的收敛速度是否会因此变慢或变得不稳定?令人惊喜的是,SGD通常能够高效收敛,并且展现出一种有趣的收敛模式。
SGD收敛的独特模式
SGD的收敛过程展现出一种精妙的双重特性:
-
远离最优解时:SGD表现得像标准的梯度下降算法,快速稳定地向最优解靠近
-
接近最优解时:收敛过程展现出更多的随机性,在最优解附近震荡
这种模式既保证了收敛效率,又为逃离局部极小值提供了可能。
二 随机梯度下降: 收敛数学证明
stochastic and true gradients 之间的相对误差定义为(公式6.15)
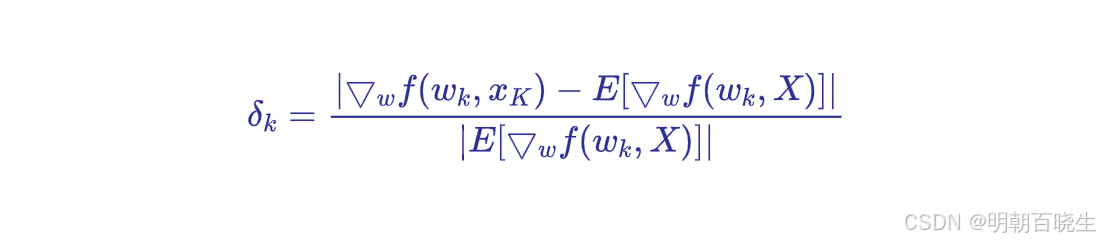
为简化起见,我们考虑 w 和 均为标量的情况。由于
是最优解,因此有
,于是
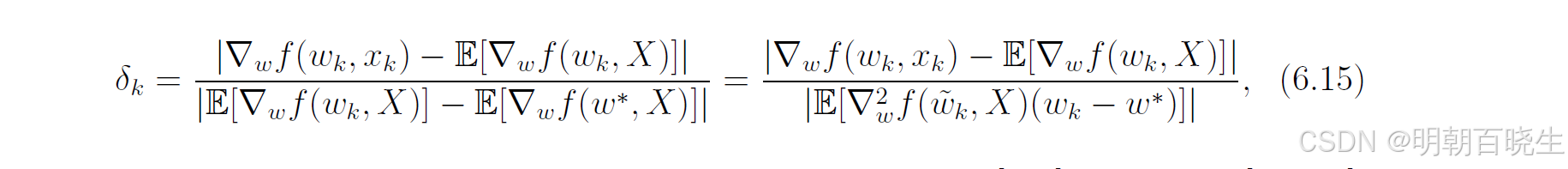
其中最后一个等式源于中值定理,且 ∈[
]。
假设函数 f 严格凸,使得对所有 w 和 X 均有 ,此时,式(6.15)的分母变为
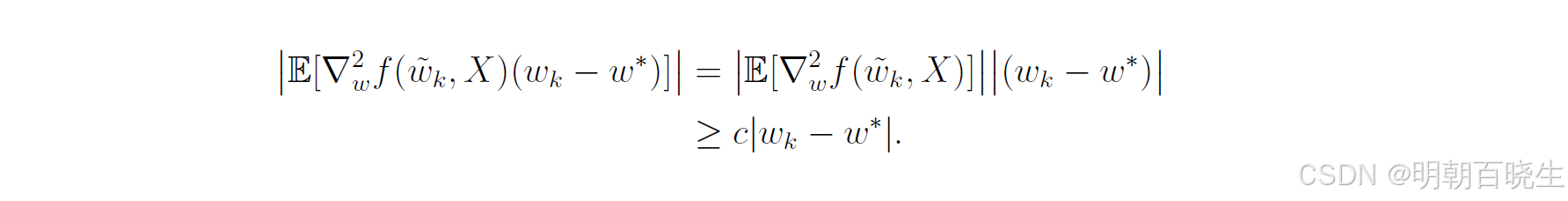
将上述不等式代入式(6.15)可得

上述不等式揭示了SGD一个有趣的收敛模式:
相对误差与|
|成反比。因此,当|
| 较大时,
较小。此时,SGD算法的行为类似于梯度下降算法,因此
会快速收敛到
。而当
接近
时,相对误差
可能会变大,收敛过程则表现出更多的随机性。
三 随机梯度下降 例子
示例:用于演示上述分析的典型案例是均值估计问题。考虑公式(6.14)中的均值估计问题。当w和X均为标量时,有目标函数 ,因此其梯度为:
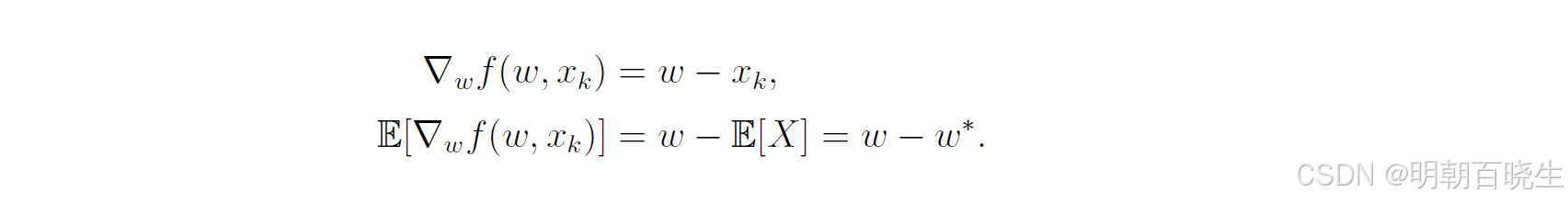
此时相对误差可表示为:
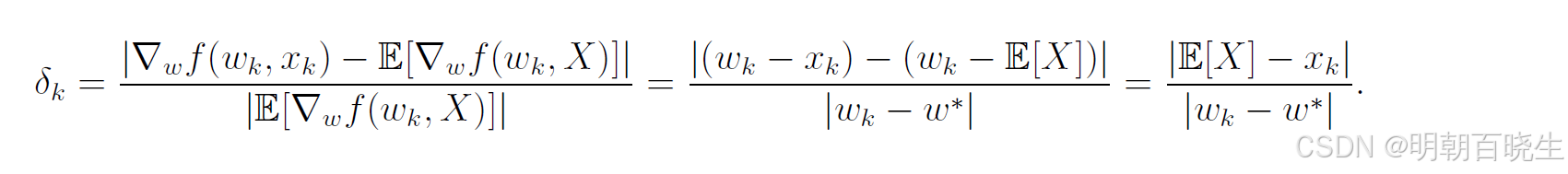
该相对误差表达式清晰表明:与 |
| 成反比。因此当 wₖ 远离最优值 w 时,相对误差较小,随机梯度下降(SGD)的表现类似于梯度下降法。同时由于
与 |E[X] - xₖ| 成正比,其期望值与随机变量 X 的方差成正比。
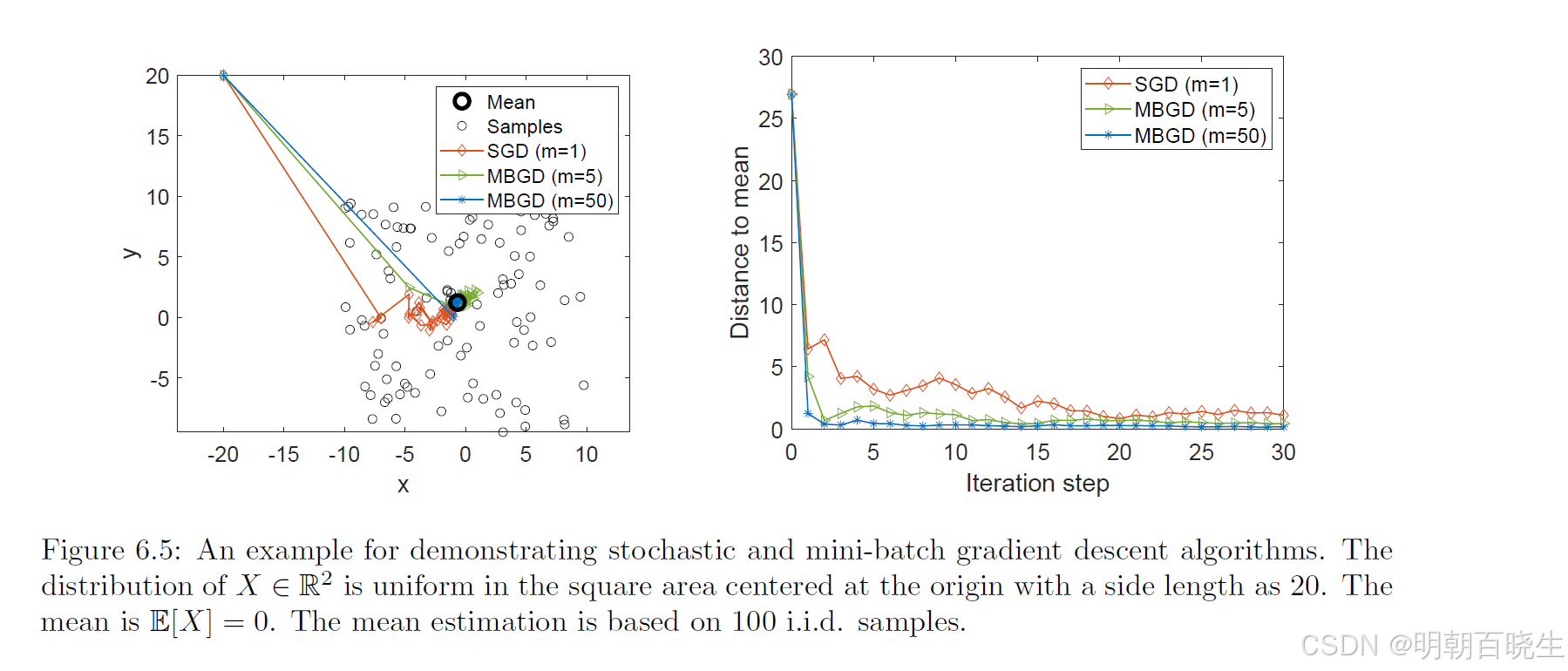
图6.5展示了仿真实验结果:假设平面中的随机位置 X ∈ R² 服从以原点为中心、边长为20的正方形区域内的均匀分布,其期望值 E[X] = 0。基于100个独立同分布样本进行均值估计可见,虽然初始猜测值远离真实均值,但SGD估计值能快速逼近原点邻域。当估计值接近原点时,收敛过程会呈现出一定的随机性特征。
四 SGD 确定性
在传统的随机梯度下降(SGD)的表述中,我们通常假设数据样本是从某个未知概率分布中独立同分布地采样得到的随机变量。然而,在机器学习和优化的理论与实践中,我们常常会遇到一种确定性的SGD表述,其中不涉及任何随机变量。
问题的确定性表述
假设我们拥有一个由确定数值构成的有限集合 {x₁, x₂, ..., xₙ}。这里的 xᵢ 本身不必是任何随机变量的样本。我们的目标是优化一个参数 w,以最小化在这个集合上的平均目标函数:
其中, 是以 w 为参数的函数。如果使用标准的梯度下降法,其更新规则为:
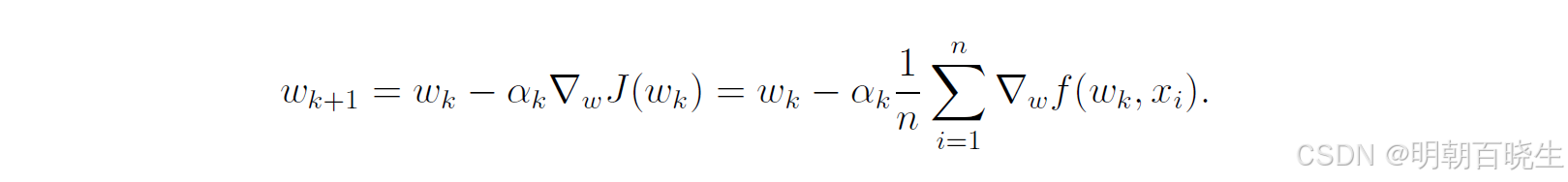
这个更新需要对整个数据集计算梯度,当 n 非常大时,计算成本极高。
增量更新:确定性SGD的核心
为了应对大数据集,我们采用一种增量更新的策略:每次迭代只使用集合中的一个数据点来计算梯度并更新参数:
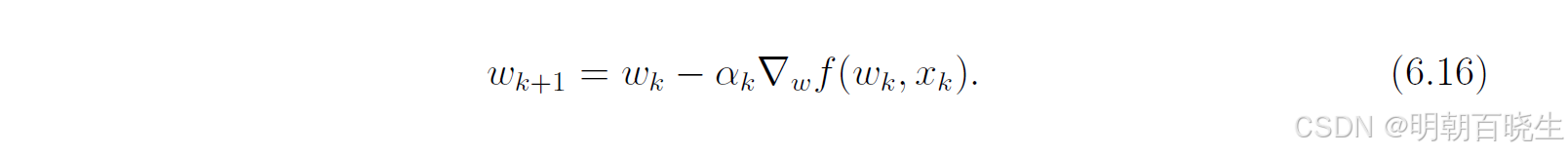
这里需要特别注意: 并非指集合中第 k 个元素,而是在第 k 次迭代时从集合中“取出”的那个数据点。
这个算法在形式上与经典的SGD几乎一模一样,但其问题背景有微妙而关键的不同:它完全构建在一个确定性的有限集合之上,并未引入任何随机性。
这自然引出了一系列问题:
-
1 这个算法还能被称为SGD吗?
-
2 我们应该如何利用这个有限集合 {
}?是按某种特定顺序(如原始顺序)逐个使用,还是应该随机地从中选取?
从确定性到随机性的桥梁
对于上述问题,一个简洁而深刻的答案是:尽管初始表述是确定性的,但我们可以通过引入一个随机变量,将其无缝地转化为经典的随机优化问题。
具体而言,我们定义一个在集合 {} 上服从均匀分布的随机变量 X,即
。于是,原来的确定性优化问题就等价于如下的随机优化问题:
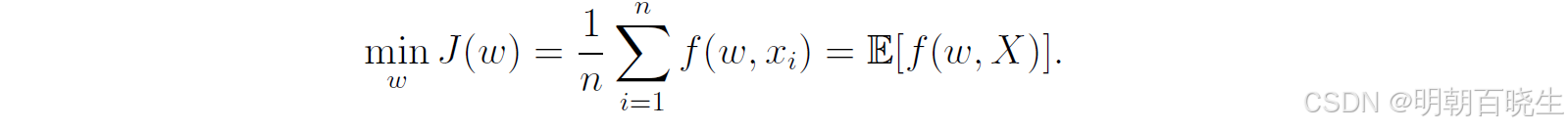
上述等式是严格的,而非近似。这一转换至关重要,它意味着:
-
算法身份:原先的确定性增量更新算法 (6.16) 现在可以被明确地定义为随机梯度下降(SGD)。
-
收敛保证:为了保证算法的收敛性,在每一步迭代中,数据点
必须是从集合 {xᵢ} 中独立且均匀随机采样的。这种随机性确保了梯度估计是无偏的,并且是理论收敛性分析的基础。
-
实践意义:正因为
结论
总而言之,确定性的SGD表述为我们理解优化算法提供了一个有价值的视角。它揭示了SGD的核心思想——通过小批量或单样本的增量更新来逼近真实梯度。通过引入一个简单的均匀分布随机变量,我们可以架起连通确定性世界与随机性世界的桥梁,
五 BGD, SGD, and mini-batch GD
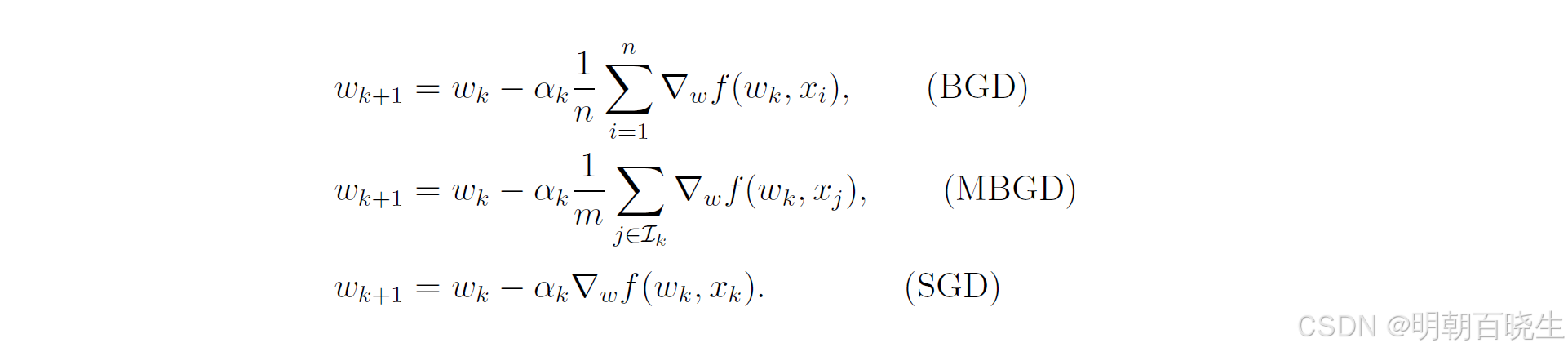
-
批量梯度下降(BGD):它每次迭代都会动用全部训练样本计算一个“精确”的梯度。虽然方向稳定,但每一步都计算沉重,尤其在数据海量时,它显得笨重而缓慢。
-
随机梯度下降(SGD):。它与BGD相反,每次迭代仅随机抽取一个样本来计算梯度。这种方式极其灵活快速,能迅速跳出局部最优,但付出的代价是梯度估计非常嘈杂,收敛过程波动剧烈。
-
小批量梯度下降(MBGD):它汲取了前两者的优点,每次迭代随机选取一小批(Mini-batch)样本。这种策略让它既能享受到SGD的快速迭代和一定的跳出局部最优能力,又因为对一小批样本求平均,使得梯度方向比SGD更稳定,收敛更快也更平滑。
例子: 均值估计的例子:我们可以清晰地看到三者的表现:

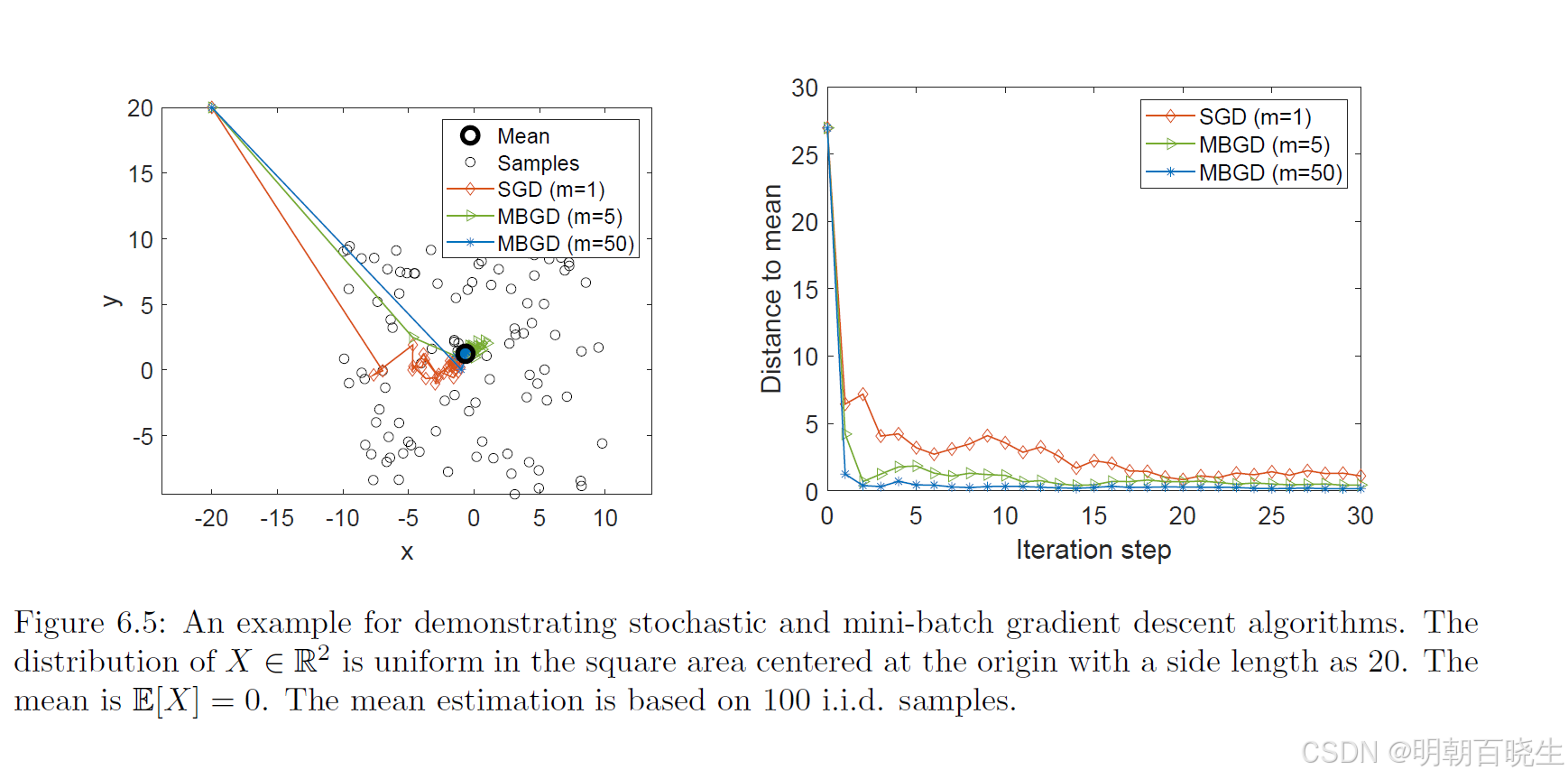
当学习率设置为 1/k 时,BGD 每一步都能给出精确的均值答案;SGD 的估计则是一条波动中缓慢逼近的曲线;而 MBGD,尤其是批次大小(m)适中的情况,能以远超SGD的速度稳定地收敛到真值,完美实现了效率与稳定性的平衡。
参考:
实战课程:
理论课程

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)