深度学习毕业设计基于卷积神经网络车牌识别系统
摘要:本文提出了一种基于YOLOv3和LPRNet的深度学习车牌识别方法,针对传统算法在复杂场景(如矿山车辆、车牌变形等)识别率低的问题。系统通过YOLOv3定位车牌,结合几何校正和LPRNet字符识别网络,实现端到端识别流程,综合识别率达95%。该方法在Python3.8环境下开发,具有处理倾斜、畸变车牌的能力,显著提升了无约束场景下的识别效果,为智能交通管理提供了高效解决方案。(149字)
一、项目介绍
传统中文车牌识别方法对场景约束较大,且算法实时性差,无法部署在边缘设备上。为解决这些问题,本文提出了一种基于YOLO的无约束场景中文车牌检测与识别方法。该方法利用YOLO目标检测算法进行车牌定位,并结合端到端的识别网络进行车牌字符识别。而车牌识别技术在车辆管理中扮演着至关重要的角色。传统的车牌识别算法通常包括三个步骤:首先利用像素信息确定车牌的位置,然后将车牌标记从位置中分离出来,最后在定位的基础上进一步识别单个字符。这种方法可以处理生活中相对简单的车牌识别场景,但对于复杂的场景,比如矿山车辆、被灰尘覆盖的车牌、车牌变形等,传统的车牌识别算法往往表现出较低的鲁棒性,并且容易出现识别错误。
相比传统的车牌检测方法,本文基于YOLOv3和LPRnet识别方法,利用几何校正原理改进了算法,以实现对车牌的精细化识别。实验结果充分展示了基于YOLOv3和LPRnet识别方法在复杂环境中识别车牌的优势,将车牌的综合识别率提高至95%。
这项研究的突破之处在于采用了YOLOv3和LPRnet识别方法,并结合几何校正原理,以应对复杂环境下的车牌识别挑战。通过这一方法,研究人员成功地提高了车牌识别的准确性和鲁棒性,为解决复杂环境下的车辆管理问题提供了有力的技术支持。这一成果对于提升车辆管理效率,保障交通安全具有重要意义,也为车牌识别技术在实际应用中的推广提供了有力的技术支撑。
二、开发环境
环境:Python3.8、OpenCV4.5、PyCharm2020
YOLOv3; LPRnet
三、功能介绍
我们的车牌识别技术的整合包括了图像采集、预处理、车牌定位、字符分割、字符识别和输出结果等步骤,利用深度学习技术来优化车牌检测和字符识别的过程。
具体的步骤及实现方法:
图像采集:
使用摄像头或者其他图像采集设备获取车辆的图像数据。这些图像可以是静态的照片,也可以是动态的视频流。
预处理:
对采集到的图像进行预处理,包括但不限于图像的尺寸调整、灰度化、去噪、增强对比度等操作,以便提高后续处理的准确性和效率。
车牌定位:
利用YOLOv3等目标检测模型,对预处理后的图像进行车牌定位。YOLOv3是一种端到端的目标检测模型,可以有效地检测出图像中的车辆和车牌区域。
字符分割:
在车牌定位的基础上,对车牌区域进行字符分割,将车牌上的字符分割成单个的字符区域。这一步可以采用传统的图像处理方法,也可以结合深度学习模型来实现。
字符识别:
利用LPRNet等字符识别模型,对分割后的单个字符区域进行识别。LPRNet是一种专门设计用于车牌字符识别的深度学习模型,能够准确地识别车牌上的字符信息。
输出结果:
将识别出的车牌字符信息与车辆信息等相关数据进行关联,并将最终的识别结果输出到用户界面或者存储到数据库中,以供后续的应用和管理使用。
————————————————
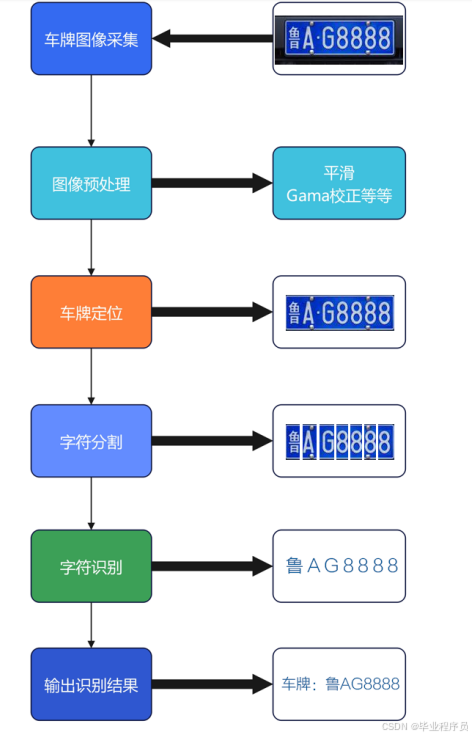
图3-1 车牌识别流程图
将训练后的车牌检测网络YOLOv3和字符识别网络LPRNet进行结合,前期在训练前将数据进行整合,针对LPRNet不需要过多的训练模型,对于单一的车型只需要进行单次的训练。如果训练模型较好,后期便不需要花时间训练,将训练后的车牌检测网络YOLOv3与字符识别网络 LPRNet连接,输入图像,并经过检测网络提取检测框,输出的候选框作为LPRNet网络的输入。通过简单的车牌二值化图像能够较易确定车牌四个角点的位置,再利用透视变换矫正车牌,将矫正的车牌输入LPRNet中。字符识别网络LPRNet首先对检测到的候选框利用主干网络提取字符信息,利用CTC和集束搜索输出最终的车牌号。由于在实际应用场景中,车牌倾角一直发生变化,而且摄像头绝大部分捕捉到的车牌图像都有畸变,本文的车牌识别系统能够增加检测时间,获得更好的识别效果。
五、效果图




魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 6
6 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)