基于随机森林的表面肌电图信号对手势与前臂姿态分类分析
本文提出了一种基于表面肌电信号(sEMG)的手势识别方法,针对动态姿态变化导致的识别性能下降问题展开研究。研究采用包含19名受试者在3种前臂姿态下执行12种手势动作的sEMG数据集,通过预处理、时域特征提取和相关系数筛选后,利用随机森林算法进行分类。实验结果表明:手势识别准确率达78%,优于姿态分类的63%;特征分析显示"通道5极差"是最重要特征,而姿态信息在信号中分布较分散。
0 引言
表面肌电图(sEMG)信号作为肌肉活动的一种非侵入性、高精度记录手段,在手势识别、人机交互以及先进义肢手系统等前沿研究领域已展现出极大的应用潜力。sEMG信号通过捕捉皮肤表面微弱的生物电信号,能够有效解码用户的运动意图,从而为义肢控制、虚拟现实交互及康复医疗等领域提供关键技术支撑。然而,尽管sEMG技术在这些应用中取得了进展,其在实际使用中仍面临一系列挑战:sEMG信号易受前臂姿态、电极位移、肢体位置动态变化以及个体生理差异等多种因素的影响,这些因素常导致信号特征的变异性和不稳定性,进而降低手势识别系统的鲁棒性与泛化能力。目前,大多数在sEMG数据集在构建过程中多侧重于静态或受限环境下的数据采集,往往忽略了前臂方向、姿势等关键动态因素的系统性控制。这种局限性使得基于此类数据集训练的模型在实际复杂场景中的应用效果大打折扣,难以适应真实世界中用户姿态的自然变化与操作习惯的多样性。
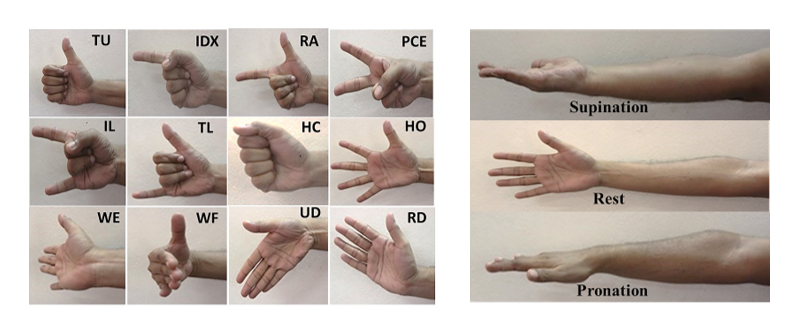
为应对上述挑战,本文引入了一个新颖的sEMG数据集,该数据集系统收录了十九名健全受试者在三种不同前臂方向(放松静息姿势、中立位姿势和半握拳预备姿势)下执行十二种手指与手腕动作时的肌电信号。 基于该数据集,研究首先对信号进行预处理,随后提取统计时域特征,并通过相关系数法进行特征筛选,最终利用随机森林(RF)分类算法对三种前臂方向及十二类手势动作进行识别与预测。通过这一系统性探索,本文旨在探究动态姿态变化下手势识别的可行性与稳定性,为开发适应性更强、鲁棒性更高的义肢控制与人机交互系统提供新思路与方法支持。
目录
本文完整代码参考:基于随机森林和EEGNet对肌电信号对手势与前臂姿态分类的探索研究资源-CSDN下载
1 数据
1.1 数据来源及介绍
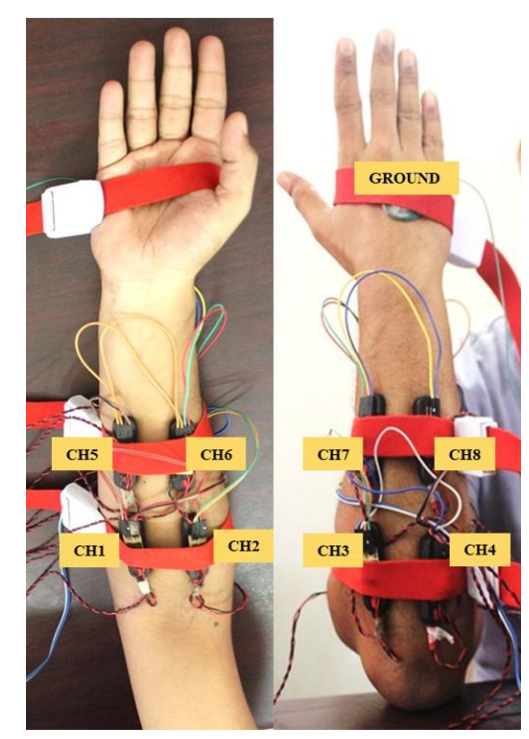
该数据来源于Kaggle平台[1],首先,数据集采集自 19 名健康受试者,受试者在三种前臂姿态(放松静息姿势、中立位姿势和半握拳预备姿势)下完成 12 种不同的手指及腕部手势,每种手势重复 5 次;此外,sEMG记录过程中采用了两种电极布置位置:肘部附近与前臂区域,不同前臂姿态下所有手部手势的表面肌电数据均以 8 秒为一个记录区间,通过 8 个通道采集(4 个通道位于肘部附近,4 个通道位于前臂中部),采样频率为 985 Hz。如图1所示,肘部区域电极 4 个电极沿肘部呈环形布置,按前后侧划分目标肌肉,前臂前侧:靠近肘关节处,CH1 对应附着于指浅屈肌,CH2 对应桡侧腕屈肌,这两块肌肉主要参与手指弯曲和手腕桡侧屈曲动作;前臂后侧:CH3 对应指伸肌,CH4 对应尺侧腕屈肌,前者负责手指伸展,后者参与手腕尺侧屈曲动作;前臂中部电极 有4 个电极围绕前臂中部布置,且与肘部区域电极呈一一对应对齐关系,确保对相同肌肉群的持续监测,前臂前侧:CH5 与 CH1 对齐,CH6 与 CH2 对齐,均靶向前臂前侧的指浅屈肌和桡侧腕屈肌,补充肘部区域电极的信号采集范围,提升肌肉活动监测的连续性;前臂后侧:CH7 与 CH3 对齐,CH8 与 CH4 对齐,聚焦前臂后侧的指伸肌和尺侧腕屈肌,与肘部区域电极形成协同,全面捕捉肌肉在不同位置的电活动特征。最后,数据集按 19 个文件夹分类组织,每个文件夹对应一名受试者,每名受试者的文件夹包含 3 个子文件夹,分别对应三种前臂姿态(放松静息姿势、中立位姿势和半握拳预备姿势),所有手势各次试验的原始数据文件均存储在对应前臂姿态命名的子文件夹中。特定手势原始表面肌电数据的命名规则为 “手势名称 - 试验次数.mat”,例如 “Thumb_UP-4.mat” 对应第四次试验中竖大拇指手势的数据。具体见图2-3。
数据链接如下:FORS-EMG: A Novel sEMG Dataset
1.2 数据预处理
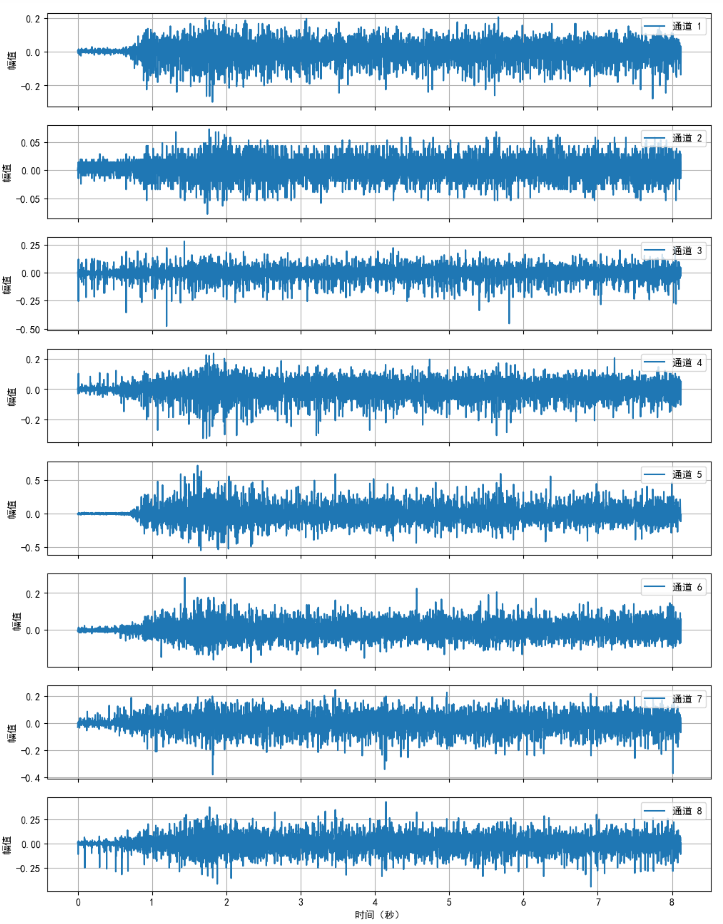
首先,从 FORS-EMG 数据集的 sEMG 信号 MAT 文件中,提取单名受试者某一手势的1秒 8 通道 sEMG 数据(采样频率 985 Hz),完成信号波形的可视化呈现与初步查看。具体图4所示。
代码如下:
file_path = 'FORS-EMG/FORS-EMG Dataset/FORS-EMG Dataset/FORS-EMG/Subject1/pronation/Index-2.mat'
if os.path.exists(file_path):
mat = sio.loadmat(file_path)
keys = list(mat.keys())
print("MAT文件中的键:", keys)
data_key = keys[-1]
emg_data = mat[data_key]
print("EMG数据的形状:", emg_data.shape)
if emg_data.shape[0] == 8000:
emg_data = emg_data.T
sample_rate = 985
num_channels = emg_data.shape[0]
num_samples = emg_data.shape[1]
time = np.arange(num_samples) / sample_rate
fig, axs = plt.subplots(num_channels, 1, figsize=(12, 2*num_channels), sharex=True)
fig.suptitle('表面肌电信号')
# 遍历每个通道绘制信号
for ch in range(num_channels):
axs[ch].plot(time, emg_data[ch], label=f'通道 {ch+1}')
axs[ch].set_ylabel('幅值')
axs[ch].legend(loc='upper right')
axs[ch].grid(True)
axs[-1].set_xlabel('时间(秒)')
plt.savefig('emg_plot.png')
else:
print("文件未找到:", file_path)其次,我们计算信号前 2 秒静息段的均方根均值与标准差,以此设定阈值;接着对 8 通道信号的 RMS 值进行滑动窗口(50ms)平均处理,通过阈值交叉检测初步定位有效段边界;随后根据预设的有效段时长范围(5~7 秒)对边界进行调整:若检测到的有效段过短(小于 5 秒),则延长至 5 秒;若过长(大于 7 秒),则截断至 7 秒,确保不同试验的有效信号时长保持相对一致,减少数据异质性,最后,通过线性插值方法实现了不同长度 sEMG 信号的标准化,固定在7 秒,即长度为:6895,总样本数为: 3420 ( 19 受试者 ×3 姿态 ×12 手势 ×5 次试验 = 3420 次)、手势标签和姿态标签的个数: 3420,并对手势标签和姿态标签,进行了量化处理。为后续提取特征和预测分析奠定了数据基础。数据整理为:(3420,8,6895),标签为:(3420,)。
2 特征工程
2.1 特征提取
通过构造 sEMG 信号的时域统计量,可定量刻画 sEMG 信号的生理信息,因此,本文基于如下11种统计特征,共提取8×11=88种特征。其原理如下[2-3]:
(1)均值(反映信号幅值的平均水平):
其中,n表示信号长度。
(2)方差(表征概率分布的离散程度):
(3)偏度(表征概率分布密度曲线相对于均值不对称程度的特征量):
(4)峰度(衡量实数随机变量概率分布的的峰态;表示样本的函数图形顶峰的凸平度):
(5)均方根(常用来表征有效值):
(6)方根幅值:
(7)整流平均值(信号绝对值的平均值):
(8)峰峰值 (信号变化的范围):
(9)波形因子:
(10)峰值因子 (峰值在波形中的极端程度):
(11)裕度因子(检测信号中的冲击信号,与峰值因子相似):
2.2 特征筛选
为有效降低各通道特征内部的共线性干扰,提升建模的精准度,本文采用相关系数分析法开展特征筛选工作。其逻辑为:计算任意两个特征间的相关系数,若该系数绝对值大于0.5,判定两特征存在较强共线性,此时保留其中一个特征,删除另一个特征,以此实现特征维度的优化与共线性的消除。特征间相关系数的计算采用皮尔逊(Pearson)相关系数,其公式如下:
其中,表示特征x与特征 y 之间的皮尔逊相关系数,取值范围为 [-1, 1];n 为样本数量;
和
分别为特征 x、特征 y的第 i 个样本值;
、
分别为特征 x、特征 y的样本均值。共线性筛选判定说明:相关系数绝对值越接近1,表明两特征间线性相关程度越强;当
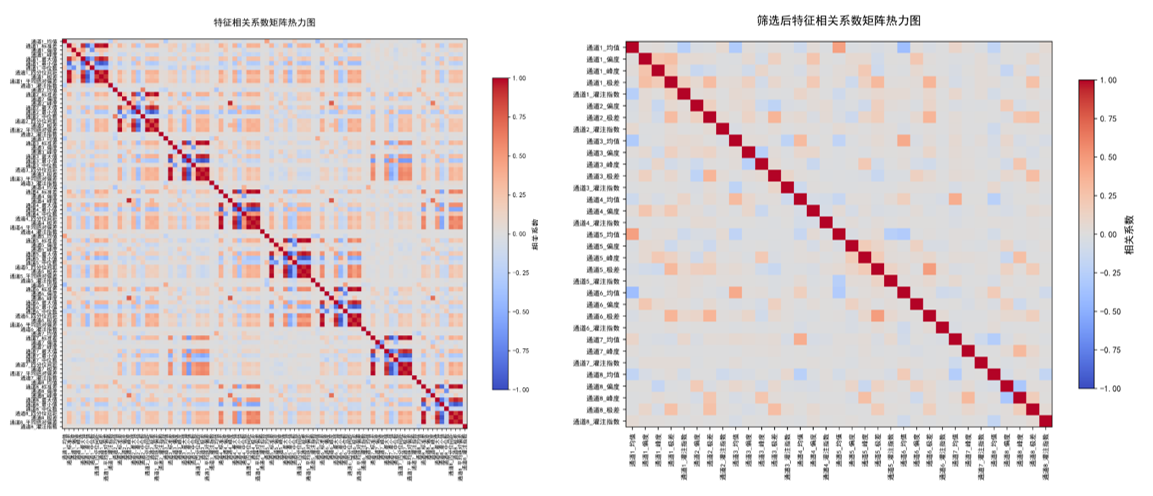
时,认为两特征存在中等及以上强度的共线性,若直接纳入模型易导致参数估计偏差、模型泛化能力下降等问题,因此需通过删除其中一个特征的方式解除该共线性干扰。故本文通过相关系数筛选,从88个特征筛选到33个特征,如下图5所示,经过筛选后的特征的热力图,没有明显的颜色加深。最后,准备分析的数据格式为:3420 ×(33+2),即为3420个样本,33个特征,2个标签。
代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import (
train_test_split, KFold, GridSearchCV
)
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv("FORS_EMG_时域特征集.csv")
X = df.drop(['手势标签', '姿态标签'], axis=1)
y_gesture = df['手势标签'] # 手势标签
y_posture = df['姿态标签'] # 姿态标签
corr_matrix = X.corr()
# 绘制相关系数矩阵热力图
plt.figure(figsize=(12, 10))
im = plt.imshow(corr_matrix, cmap='coolwarm', aspect='auto', vmin=-1, vmax=1)
cbar = plt.colorbar(im, shrink=0.8)
cbar.set_label('相关系数', fontsize=12)
plt.title('特征相关系数矩阵热力图', fontsize=14, pad=20)
plt.xticks(range(len(corr_matrix.columns)), corr_matrix.columns, rotation=90, fontsize=8)
plt.yticks(range(len(corr_matrix.columns)), corr_matrix.columns, fontsize=8)
plt.tight_layout()
plt.savefig('correlation_matrix.png', dpi=300, bbox_inches='tight')
# 显示图片
plt.show()
# 找出高相关性特征对(相关系数绝对值 > 0.5)
high_corr_pairs = []
threshold = 0.5
for i in range(len(corr_matrix.columns)):
for j in range(i + 1, len(corr_matrix.columns)):
corr_value = corr_matrix.iloc[i, j]
if abs(corr_value) > threshold:
high_corr_pairs.append({
'feature1': corr_matrix.columns[i],
'feature2': corr_matrix.columns[j],
'correlation': corr_value
})
high_corr_df = pd.DataFrame(high_corr_pairs)
def remove_high_correlation_features(X, threshold=0.5):
corr_matrix = X.corr()
columns = corr_matrix.columns
to_drop = set()
for i in range(len(columns)):
for j in range(i + 1, len(columns)):
if abs(corr_matrix.iloc[i, j]) > threshold:
# 计算两个特征的方差,保留方差较大的特征
var1 = X[columns[i]].var()
var2 = X[columns[j]].var()
if var1 < var2:
to_drop.add(columns[i])
else:
to_drop.add(columns[j])
X_filtered = X.drop(list(to_drop), axis=1)
return X_filtered, list(to_drop)
X_filtered, dropped_features = remove_high_correlation_features(X, threshold=0.5)
if X_filtered.shape[1] > 1:
corr_matrix_filtered = X_filtered.corr()
plt.figure(figsize=(10, 8))
im = plt.imshow(corr_matrix_filtered, cmap='coolwarm', aspect='auto', vmin=-1, vmax=1)
cbar = plt.colorbar(im, shrink=0.8)
cbar.set_label('相关系数', fontsize=12)
plt.title('筛选后特征相关系数矩阵热力图', fontsize=14, pad=20)
plt.xticks(range(len(corr_matrix_filtered.columns)), corr_matrix_filtered.columns, rotation=90, fontsize=8)
plt.yticks(range(len(corr_matrix_filtered.columns)), corr_matrix_filtered.columns, fontsize=8)
plt.tight_layout()
plt.savefig('correlation_matrix_filtered.png', dpi=300, bbox_inches='tight')
plt.show()3 随机森林与评价指标
3.1随机森林
首先,基于上述筛选流程得到优化后的特征集后,为保障机器学习模型的训练效果与泛化能力评估的可靠性,首先按照7:3的比例划分训练集与测试集。机器学习模型的构建与验证核心涵盖训练和测试两个关键阶段,二者的合理区分是模型性能评估的基础:训练阶段的核心目标是让模型通过学习训练数据中的特征与标签关联规律,完成自身参数的迭代优化;测试阶段则是将训练好的模型应用于全新的测试数据,通过模型对该部分数据标签的预测结果,评估其在未见过的数据上的泛化能力,该阶段的评估结果即为模型的测试性能。需特别注意的是,训练数据与测试数据必须严格互斥,训练集中的任何样本都不得参与测试阶段,否则会导致测试性能被高估,无法反映模型的真实泛化水平[4]。
其次,文使用的机器学习模型是随机森林,它是一种集成学习模型,基于重抽样自举法的样本创建多个子集,用于构建每个决 策树,将多个决策树整合一起,最终构成整片森林。其核心思想是 “集体智慧优于个体”,它通过集成学习策略,先利用重抽样自举法从原始数据中随机生成多个不同的样本子集,再为每个子集独立构建一棵决策树,最后让所有决策树共同参与预测,通过投票(分类任务)或取平均(回归任务)的方式输出最终结果,以此降低单棵决策树的过拟合风险,提升模型的稳定性和预测精度。此外,为进一步筛选出随机森林模型的最优训练参数(如决策树数量、最大树深度、最小样本分割数等),提升模型的预测精度与稳定性,本研究采用五折交叉验证法进行参数寻优。具体实施流程为:将划分好的训练集随机拆分为5个规模大致相等的子集,每次选取其中1个子集作为验证集,剩余4个子集作为训练子集用于模型训练,完成一次训练后通过验证集评估模型性能;重复该过程5次,确保每个子集都有一次机会作为验证集,最终以5次验证性能的平均值作为该组参数下模型的交叉验证性能;通过遍历预设的参数组合,选取交叉验证性能最优的参数组合作为随机森林模型的最终训练参数。
最后,为深入解释模型的决策机制、明确各特征对预测结果的影响程度,本文进一步输出了各特征的贡献度。特征贡献度的计算核心是衡量每个特征在所有决策树构建过程中的重要性,常用计算方式包括两种:一是基于Gini系数减少量,即特征在决策树节点分裂时所带来的不纯度降低程度,不纯度降低越多,表明该特征对决策树分裂的贡献越大,其特征贡献度越高;二是基于特征排列重要性,通过随机打乱某一特征的所有样本值后重新计算模型的预测误差,若误差显著增大,说明该特征对模型预测结果的影响较大,其贡献度越高。本文通过输出各通道特征的贡献度排序结果,可明确关键影响特征,为后续的模型解释提供重要依据。
3.2 评价指标
本文是针对不同手势或者姿势进行判断,则是多分类问题,故多分类指标如下[5]:
1. 精确率(Precision):某类预测为正的样本中实际为正的比例。
其中,表示第
类的真正例(预测为
且实际为
),
表示第
类的假正例(预测为
但实际非
)。
2. 召回率(Recall):某类实际为正的样本中被正确预测的比例。
其中,表示第
类的假负例(实际为
但预测非
)。
3. F1分数(F1-score):精确率与召回率的调和平均。
4. 支持度(Support):某类的实际样本总数。
5. 准确率(Accuracy):所有样本中预测正确的比例。
其中, 表示第 $i$ 类的真负例(实际非
且预测非
),
为总类别数,分母为全部样本总数。
6. 宏平均(Macro avg):各类指标的算术平均(不考虑样本量差异)。
7. 加权平均(Weighted avg):各类指标按支持度加权平均(重视样本量多的类别)。
代码如下:
def tune_hyperparameters(X, y, model, param_grid, target_type):
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1,
verbose=1
)
grid_search.fit(X, y)
print(f"最优参数组合: {grid_search.best_params_}")
print(f"最优交叉验证准确率: {grid_search.best_score_:.4f}")
return grid_search.best_estimator_, grid_search.best_params_, grid_search.best_score_
def train_and_evaluate_model(X, y, base_model, param_grid, model_name, target_type):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
best_model, best_params, best_cv_score = tune_hyperparameters(
X_train_scaled, y_train, base_model, param_grid, target_type
)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
cv_scores = []
print("-" * 50)
for fold, (train_idx, val_idx) in enumerate(kf.split(X_train_scaled)):
X_fold_train, X_fold_val = X_train_scaled[train_idx], X_train_scaled[val_idx]
y_fold_train, y_fold_val = y_train.iloc[train_idx], y_train.iloc[val_idx]
fold_model = RandomForestClassifier(**best_params, random_state=42, n_jobs=-1)
fold_model.fit(X_fold_train, y_fold_train)
fold_score = accuracy_score(y_fold_val, fold_model.predict(X_fold_val))
cv_scores.append(fold_score)
print(f"第{fold+1}折 - 训练样本数: {len(X_fold_train)}, 验证样本数: {len(X_fold_val)}, 准确率: {fold_score:.4f}")
cv_mean_score = np.mean(cv_scores)
cv_std_score = np.std(cv_scores)
print(f"5折交叉验证 - 平均准确率: {cv_mean_score:.4f}, 标准差: {cv_std_score:.4f}")
# 用最优参数训练完整训练集
best_model.fit(X_train_scaled, y_train)
# 评估训练集和测试集
y_train_pred = best_model.predict(X_train_scaled)
y_test_pred = best_model.predict(X_test_scaled)
train_acc = accuracy_score(y_train, y_train_pred)
test_acc = accuracy_score(y_test, y_test_pred)
print(f"\n{target_type} - {model_name} 最终评估结果:")
print(f"训练集准确率: {train_acc:.4f}")
print(f"测试集准确率: {test_acc:.4f}")
print(f"\n测试集分类报告:")
print(classification_report(y_test, y_test_pred, zero_division=0))
if hasattr(best_model, 'feature_importances_'):
print(f"\n{target_type} - {model_name} 特征重要性分析(Top 10):")
feature_importance = pd.DataFrame({
'feature': X.columns,
'importance': best_model.feature_importances_
}).sort_values('importance', ascending=False).head(10)
print(feature_importance)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'][::-1], feature_importance['importance'][::-1])
plt.xlabel('重要性得分')
plt.ylabel('特征名称')
plt.title(f'{target_type} - {model_name} 特征重要性(Top 10)')
plt.tight_layout()
plt.show()
return best_model, best_params, {
'train_acc': train_acc,
'test_acc': test_acc,
'cv_scores': cv_scores,
'cv_mean': cv_mean_score,
'cv_std': cv_std_score,
'tune_cv_score': best_cv_score,
'scaler': scaler,
'X_test': X_test,
'y_test': y_test
}
rf_param_grid = {
'n_estimators': [50, 100, 200], # 决策树数量
'max_depth': [None, 10, 20, 30], # 树的最大深度
'min_samples_split': [2, 5, 10], # 分割内部节点所需的最小样本数
'min_samples_leaf': [1, 2, 4] # 叶节点所需的最小样本数
}4 结果
4.1 基于随机森林对手势的预测分析
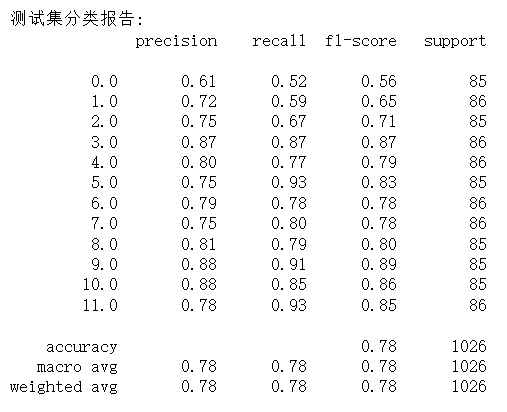
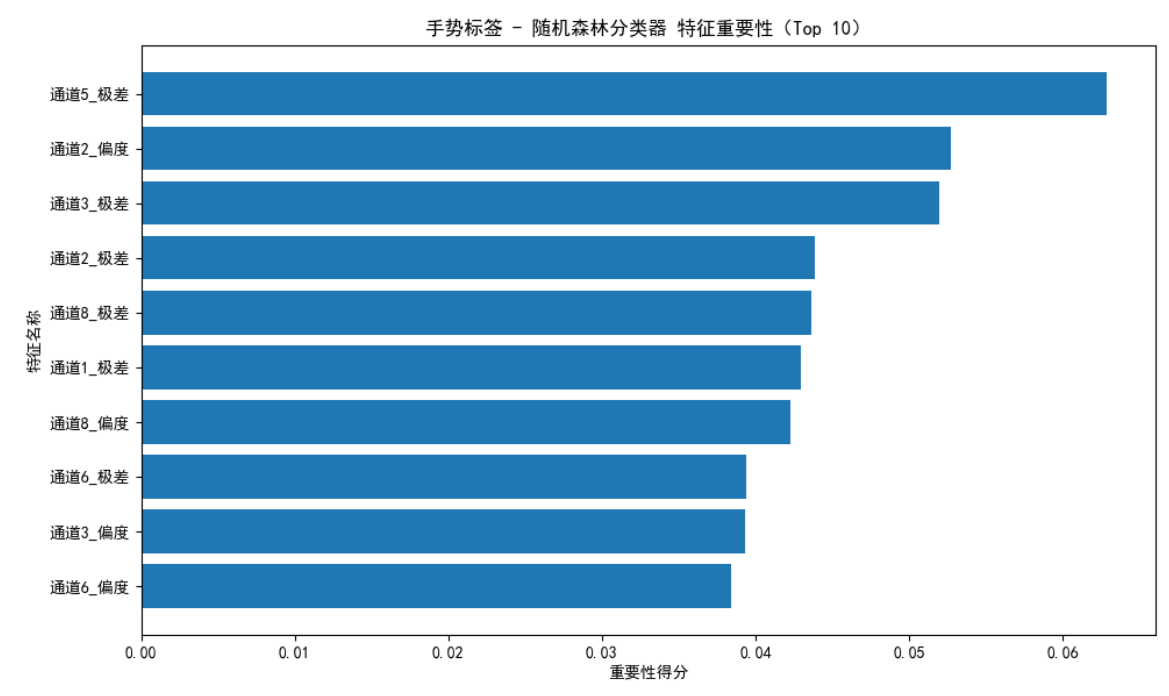
如图6所示,在 1026 个样本(12 类手势,每类样本量 85-86 个)的测试集上,模型整体准确率为 0.78,各类别 precision、recall 及 f1-score 的宏观与加权均值也均为 0.78,说明模型分类效果较均衡且无明显样本偏向,但综合性能仅处于中等偏上水平;从各类别表现看,标签 5.0、11.0 的 f1-score(0.83、0.85)及 recall(均为 0.93)相对突出,而标签 0.0 的 f1-score 仅 0.56(precision=0.61、recall=0.52),是识别效果最差的类别,存在明显的分类混淆风险,其余多数类别 f1-score 集中在 0.77-0.81 之间,表现稳定但未达高精度;如图7所示,特征重要性分析则显示,“通道 5_极差” 的重要性得分最高(接近 0.06),是分类的核心驱动特征,前 5 个重要特征得分均超 0.05,而 “通道 6_偏度” 得分最低,对分类影响较弱,且前 10 个特征均为数据统计量(极差、维度、偏度等),说明模型主要依赖手势数据的统计特征完成分类。整体而言,模型分类表现稳定但存在部分类别识别短板,后续可针对标签 0(TU)优化样本或特征。
4.2 基于随机森林对姿势的预测分析
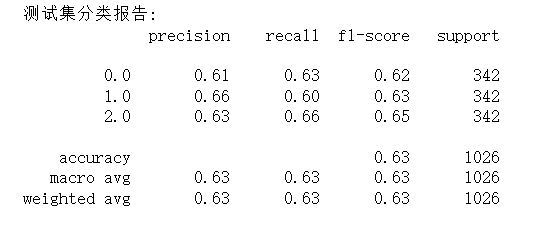
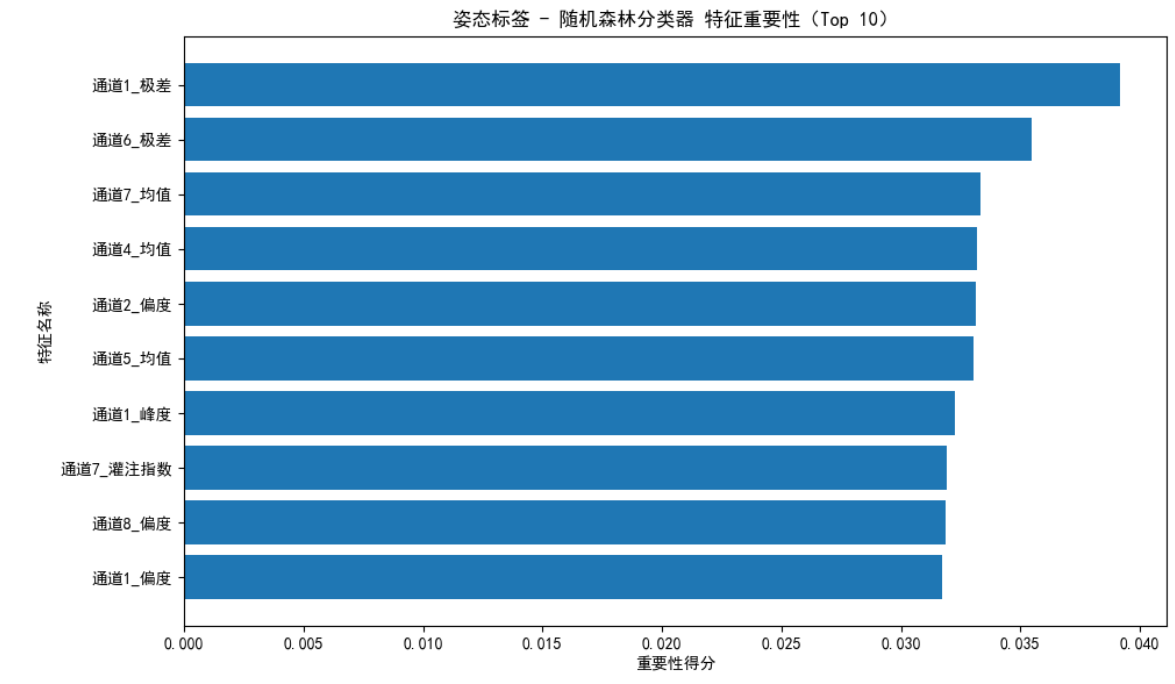
如图8所示,在涵盖 1026 个样本(3 类姿态,每类样本量均为 342 个)的测试集上,模型整体准确率为 0.63,macro avg 与 weighted avg 维度下的 precision、recall、f1-score 也均为 0.63,说明模型对 3 类姿态的分类效果虽均衡,但综合性能偏弱;从具体类别表现看,3 类姿态的 f1-score 集中在 0.62-0.65 之间,差异较小,其中标签 2.0 的 f1-score(0.65)略占优势,标签 0.0 的 f1-score(0.62)稍显不足,但整体未出现像手势分类中那样明显的 “识别短板类别”;如图9所示,特征重要性方面,“通道 1_极差” 的重要性得分最高(接近 0.04),是驱动分类的核心特征,但前 10 个特征的重要性得分集中在 0.025-0.04 之间,分布相对平缓,并未出现某一特征的绝对主导性。
最后将其与之前的手势分类模型对比可见:性能上,手势分类模型的整体准确率(0.78)显著高于姿态模型(0.63),综合分类能力更优;类别表现上,手势模型存在明显的 “弱类别”(如标签 0.0 的 f1-score 仅 0.56),而姿态模型各类别间的表现差异更小、更趋同;特征层面,手势模型的核心特征(通道 5_极差)主导性更强,得分与其他特征拉开了明显差距,而姿态模型的特征重要性分布更均匀,没有形成绝对的核心特征。
5 讨论
本文聚焦于表面肌电信号的手势识别领域中“动态姿态干扰导致模型泛化性能不足”的痛点,以3种前臂方向、12类手势的多姿态sEMG数据集,并基于随机森林算法开展分类实验。实验结果不仅验证了该数据集的应用价值,更揭示了sEMG手势识别在动态场景下的关键特性。从分类性能来看,手势识别模型(准确率0.78)表现优于姿态分类模型(准确率0.63),这一结果表明sEMG信号对“手势动作”的区分能力显著高于对“前臂姿态”的区分能力。但需注意的是,两类模型的综合性能仍存在较大提升空间:其中,手势识别模型中标签0.0类别的F1值仅为0.56,姿态分类模型整体准确率亦仅达0.63。该现象与sEMG信号本身易受姿态干扰的固有特性度吻合,特征重要性分析结果显示,“通道5_极差”等统计时域特征成为分类核心变量。这一发现既符合sEMG信号由时域信息主导的本质属性,也证实了通过相关系数法筛选的特征能够有效捕捉动作与姿态的差异。值得关注的是,特征重要性呈现明显分布差异:手势识别模型中核心特征的主导性更强,而姿态分类模型的特征重要性分布则更为平缓。该差异暗示“姿态信息在sEMG信号中分布更分散,且更易受动作信号的干扰”,这也从特征层面解释了姿态分类性能偏弱的核心原因。
尽管本文取得了上述阶段性成果,但仍存在三方面明显局限:其一,特征工程环节存在不足,仅采用了统计时域特征,未引入频域特征、时频联合特征及主成分特征等其他类型特征,可能遗漏关键鉴别信息;其二,未针对电极位置开展系统性研究,既未筛选出对分类贡献度最高的电极位置,也未尝试多位置信号融合策略,未能充分挖掘空间维度的信息价值;其三,模型与特征筛选方法的选型较为单一,仅采用随机森林算法与相关系数法,未对比测试其他机器学习模型、深度学习模型及更高效的特征筛选算法,难以验证现有方案的最优性。后续可从三方面针对性改进:一是拓展特征维度,在统计时域特征基础上,引入频域特征(如功率谱密度、频谱熵)、时频联合特征(如小波包变换系数)及主成分特征等,通过特征融合丰富鉴别信息;二是开展电极位置系统性研究,采用特征重要性分析筛选核心电极,探索多位置信号融合策略,挖掘空间维度价值;三是丰富模型与特征筛选方法选型,对比测试 SVM、神经网络等机器学习模型、CNN/LSTM 等深度学习模型,以及、递归特征消除等筛选算法,验证并优化现有方案。
参考
[1] FORS-EMG: A Novel sEMG Dataset
[2] 基于统计信息融合的PPG时域特征在心肌梗死预测的研究-CSDN博客
[3] 信号中的特征 - 知乎
[4] 基于 PPG 信号与机器学习算法的心肌梗死预测研究_ppg 数据 计算 经络能量-CSDN博客
[5] 基于EEGNet网络的脑电信号对阿尔茨海默与额颞叶痴呆的辅助诊断研究-CSDN博客
注:若有侵权部分,请留言将会删除。
个人观点,仅供参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)