元模型开发工具怎么选?元模型VS数据模型
本文探讨了元模型开发工具的选择、应用受限原因及规范制定。主要开源工具有OpenMetadata(一体化数据治理)、DataHub(丰富连接器)和ApacheAtlas(大数据治理),选择需综合功能、易用性等要素。元模型应用受限源于三方面:知识体系庞杂、技术复杂度高和人才短缺。元模型规范需定义术语(如类、属性)、结构(命名规则等)和约束条件。元模型与数据模型的关系是抽象与具体实现的区别,前者定义结构
一、元模型适配开发工具有哪些?我们如何选择?
元模型开发工具,有开源工具和商业工具两种。相比于商业工具,开源工具中的Open Metadata、Data Hub,应用场景更为广泛,Apache Atlas主要适用于大数据生态系统中的元数据管理和治理场景,如Hive、HBASE、Kafka等。
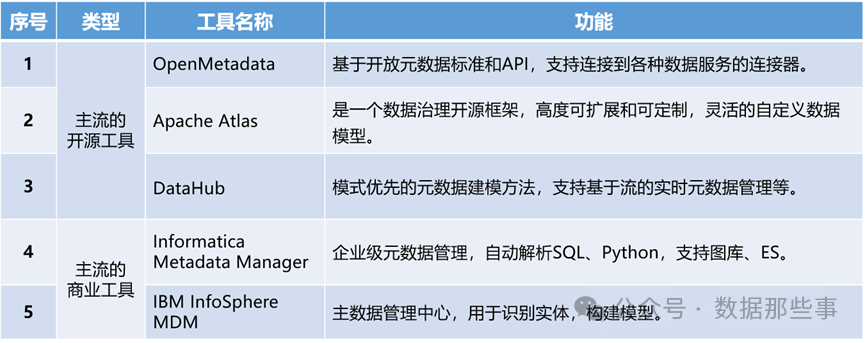
简单介绍一下Open Metadata、Data Hub和Apache Atlas。
Open Metadata:在数据治理、数据质量分析评估、元数据管理等领域具有较强的能力,同时支持协作模式进行开发。虽然其在数据采集方面的灵活性不如Data Hub,但其一体化数据治理解决方案(覆盖数据发现、数据血缘、数据质量、数据探查到数据治理和团队协作)、强大的数据发现与血缘跟踪以及灵活的定制能力和扩展性成为诸多企业的选择。
Data Hub:能提供丰富的连接器,与多种数据源集成,且支持图库,能够处理复杂元数据关系和数据血缘,此外在元数据管理层面,能提供数据发现、数据血缘、数据质量管理等全面的功能支持,并与企业自身的数据治理产品无缝集成,且成本低。
Apache Atlas:是个高度可扩展、可定制的数据治理解决方案,尤其是针对大数据生态中数据治理的场景,是个不错的选择。
选择元模型开发工具时,需要综合考虑工具的功能、易用性、灵活性、社区支持力度、生态系统、自身技术及产品能力、是否满足特定的项目需求等,进行综合性选择。
二、为什么元模型的应用受限?
元数据管理和元模型构建的重要性不言而喻,但实际项目中听到的却很少。究其原因,主要体现在三个方面:
1、知识体系庞杂,理解难度大
元模型和元数据管理的概念都相对抽象,尤其是元模型,需要不仅了解MOF这类框架的理念,还需要能够使用诸如UML建模工具完成建模,且还需要对业务本身所涉及的实体、属性以及关系等业务知识有相对的了解,才能理解其重要性,构建出来的元模型才更有扩展性。目前国内数据治理团队的能力几乎还不具备从业务、技术、理论框架三方面均能深刻掌握。且该类型的项目往往属于“幕后工作”,更加偏重于数据结构设计层面,现有甲方追求“速成”的思想,不利于该类项目的规划实施。
2、技术复杂度高
元数据管理和元模型建设所涉及的技术复杂度巨大,从数据发现、数据血缘、数据质量、数据探查到数据治理和团队协作,涉及数据采集集成、数据结构设计、数据模型设计、图库构建、数据质量分析与评估、数据治理组织和流程设计,甚至数据查询分析等,对于技术能力娇弱的团队,实施工作将面临巨大的挑战。
3、人才困境
前面已经提到,元模型构建和元数据治理涉及到多方面的技术、业务和理论知识,全面掌握又能熟练使用的人员相对较少;此外,该类项目往往需要从架构的角度,通盘考虑,尤其是制定技术解决方案时,往往要结合业务场景选择合适的技术,企业中这类人才也相对缺乏。且企业中也没有足够的经验来实施该类项目,由于缺乏知识、经验等会导致项目难以有效推进。
基于以上几个主要的原因,所以我们在现实中往往比较少接触、甚至听到元数据管理的项目,更不用说元模型的构建。
三、什么是元模型的规范?
元模型的定义和使用规范是确保元模型设计、实现和使用过程中一致性和可维护性的关键。通过定义元模型的结构、语法和语义规则,确保元模型的设计、实现和使用具有一致性和可维护性。
要完成元模型规范的编制,基于项目需求和目标的基础上,主要是完成三个重要的动作,分别是术语定义、元模型结构定义、制定规范和规则。
1、术语定义
主要编制完成元模型、类、属性、关系、数据类型、约束和常数等核心概念(包括核心元素)的定义。同时对扩展机制,如继承、组合、自定义等进行定义。即告诉阅读者这几个名词在本文语境中约定的意义。
1)核心概念
元模型(Meta-Model):用于定义模型的结构和语法规则的模型。
类(Class):元模型中的基本单元,用于定义模型中的实体。
属性(Attribute):类的组成部分,用于描述类的实例的特征或状态。
关系(Association):类之间的连接和交互。
数据类型(Data Type):属性可以取的值的类型。
约束(Constraint):定义模型中元素的语义规则。
常数(Constant):模型中不变的值。
2)扩展机制
继承:支持类和属性的继承机制。
组合:支持类和属性的组合机制。
自定义扩展:允许用户通过扩展机制定义新的类、属性、关系等。
2、元模型结构定义
完成核心元素的结构定义,识别不同元素的关系和约束。
1)类的定义
名称:类的名称必须是唯一的,使用驼峰命名法(如 Person)。
属性:每个类可以包含多个属性,每个属性必须定义名称、数据类型、是否可选(Optional)、是否多值(Multi-valued)等。
关系:类之间可以通过关系连接,关系必须定义名称、方向、多重性(如一对一、一对多、多对多)等。
约束:类可以包含约束,约束必须定义类型(如范围约束、唯一性约束)和表达式。
2)属性的定义
名称:属性的名称必须是唯一的,使用小驼峰命名法(如 name)。
数据类型:属性的数据类型必须是预定义的数据类型之一(如 String、Integer、Date)。
可选性:属性可以定义为可选(Optional)或必填(Mandatory)。
多值性:属性可以定义为单值(Single-valued)或多值(Multi-valued)。
3)关系的定义
名称:关系的名称必须是唯一的,使用小驼峰命名法(如 belongsTo)。
方向:关系必须定义方向(如从 Person到 Order)。
多重性:关系必须定义多重性(如一对一、一对多、多对多)。
4)数据类型的定义
预定义数据类型:元模型支持以下预定义数据类型:String、Integer、Double、Boolean、Date。
自定义数据类型:可以通过继承或组合预定义数据类型定义新的数据类型。
5)约束的定义
类型:约束可以是范围约束(如 age >= 18)、唯一性约束(如 name必须唯一)等。
表达式:约束的表达式必须符合预定义的语法和语义规则。
3、制定规范和规则
做过数据库开发的人,都知道数据库命名规范的编制要求,那么元模型规范也是一样的,需要明确命名规范、规则以及约束条件。
1)命名规范
类命名:类的名称必须是唯一的,使用驼峰命名法(如Person)。
属性命名:属性的名称必须是唯一的,使用小驼峰命名法(如name)。
关系命名:关系的名称必须是唯一的,使用小驼峰命名法(如belongs to)。
【补充阅读:驼峰命名法(Camel Case)是一种常见的命名规则,主要用于编程语言中标识符(如变量名、函数名、类名等)的命名。它通过将多个单词组合在一起,并在每个单词的首字母大写(除了第一个单词)来形成一个可读性强的标识符。驼峰命名法有两种主要形式:小驼峰命名法(lower camel case)和大驼峰命名法(upper camel case)。】
2)语法和语义规则
语法规则:定义元模型的语法规则,确保模型的定义符合预定义的结构。
语义规则:定义元模型的语义规则,确保模型的定义符合业务逻辑和约束条件。
3)约束定义
范围约束:定义属性值的范围,如 age >= 18。
唯一性约束:定义属性值的唯一性,如 name 必须唯一。
存在性约束:定义属性或关系的存在性,如 Person 必须有 name。
四、浅析:元模型VS数据模型
元模型是数据模型的“模型”,通过元模型可以定义数据模型中的实体类型、属性类型、关系类型等,而数据模型则根据这些定义具体实现数据的存储和管理。
1、数据模型是根据元模型的定义而具体实现的模型。每个数据模型都是元模型的一个实例,遵循元模型的规则和结构。
例如,一个企业可能定义了一个元模型来规范其数据模型的设计,然后根据这个元模型设计了多个具体的数据模型,用于不同的业务系统。
(实际中,我们从原业务系统中,提取元数据,提取元模型,而不进行单独的元模型的设计,基于此元模型,构建数据治理领域中的数据模型)
2、元模型的定义和使用主要来源数据治理领域中,其设计和实现的目的是用于定义数据架构的高层结构,从而指导数据模型的设计和实现。
3、数据模型则用于定义表结构、字段类型、关系等,用于设计各类数据库、数据仓库架构的设计等,以支持数据抽取实现对数据应用开发的支持。
从以上内容,我们也能窥见为何数据治理领域中,元模型和数据模型会脱节。究其原因,是因为两者涉及到数据的层面不同,一个更加抽象,一个更加落地,有点像从战略设计到落地实施的感觉,中间还缺少相关的规范、管理、框架亦或标准。
结尾的话
通过元模型工具的恰当使用,结合元模型规范,组织可以开发出可以使用的元模型,并不断的继承下去。这个过程是个持续的过程,需要不断维护,并严格遵循,对组织文化的严谨性要求很高。
本文来自公众号:数据那些事
更多数据治理相关的文章数据治理博客园 | 巨人肩膀

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)