AI视觉:使用YOLO11训练图像识别模型
如果看到 MPS (GPU) available: True,说明你的Mac已经可以启用GPU加速了。系统自动保存了 best.pt(第9个epoch的模型)训练在 epoch 9 达到最佳性能。随后10个epoch没有进一步改进。
·
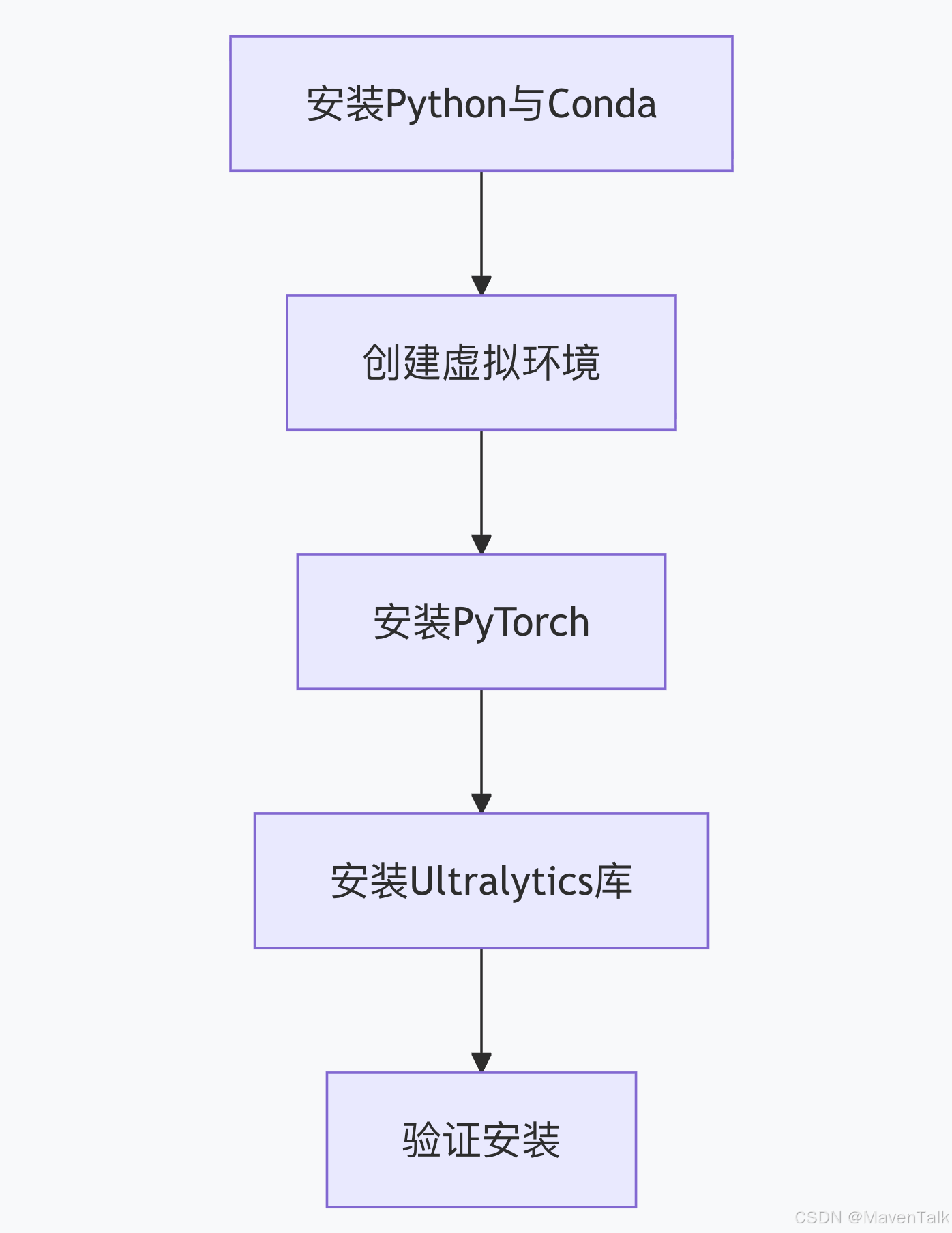
环境配置
- 安装conda,官网下载安装即可。
- 创建环境
conda create -n yolov11 python=3.9 -y
conda activate yolov11
- 安装PyTorch(MacBook Pro环境,使用MPS模式)
pip install torch torchvision torchaudio
- 安装Ultralytics库,这是YOLOv11的核心库。
pip install ultralytics
- 验证环境
安装完成后,需要确认MPS加速是否可用。启动Python,运行以下代码:
python
import torch
import ultralytics
print(f"PyTorch version: {torch.__version__}")
print(f"MPS (GPU) available: {torch.backends.mps.is_available()}")
print(f"Ultralytics version: {ultralytics.__version__}")
如果看到 MPS (GPU) available: True,说明你的Mac已经可以启用GPU加速了。
训练模型
from ultralytics import YOLO
import os
def train_yolo():
# 初始化模型(使用预训练权重)
model = YOLO('yolo11n.pt') # 可选: yolo11n.pt, yolo11s.pt, yolo11m.pt, yolo11l.pt, yolo11x.pt
# 训练模型
results = model.train(
data='../configs/my_dataset.yaml', # 数据集配置路径
epochs=100, # 训练轮数
patience=10, # 早停耐心值
batch=16, # 批次大小
imgsz=640, # 输入图像尺寸
device='mps', # 使用Mac GPU加速
workers=0, # Mac上建议设为0
lr0=0.01, # 初始学习率
weight_decay=0.0005, # 权重衰减
save=True, # 保存训练结果
exist_ok=True, # 覆盖现有训练结果
name='my_yolo11_model' # 训练运行名称
)
return results
if __name__ == '__main__':
train_yolo()
开始训练:
/Users/hogworts/miniconda3/envs/yolo11/bin/python /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/training.py
Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt to 'yolo11n.pt': 100% ━━━━━━━━━━━━ 5.4MB 10.0MB/s 0.5s
Ultralytics 8.3.217 🚀 Python-3.9.24 torch-2.8.0 MPS (Apple M2)
engine/trainer: agnostic_nms=False, amp=True, augment=False, auto_augment=randaugment, batch=16, bgr=0.0, box=7.5, cache=False, cfg=None, classes=None, close_mosaic=10, cls=0.5, compile=False, conf=None, copy_paste=0.0, copy_paste_mode=flip, cos_lr=False, cutmix=0.0, data=../configs/my_dataset.yaml, degrees=0.0, deterministic=True, device=mps, dfl=1.5, dnn=False, dropout=0.0, dynamic=False, embed=None, epochs=100, erasing=0.4, exist_ok=True, fliplr=0.5, flipud=0.0, format=torchscript, fraction=1.0, freeze=None, half=False, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, imgsz=640, int8=False, iou=0.7, keras=False, kobj=1.0, line_width=None, lr0=0.01, lrf=0.01, mask_ratio=4, max_det=300, mixup=0.0, mode=train, model=yolo11n.pt, momentum=0.937, mosaic=1.0, multi_scale=False, name=my_yolo11_model, nbs=64, nms=False, opset=None, optimize=False, optimizer=auto, overlap_mask=True, patience=10, perspective=0.0, plots=True, pose=12.0, pretrained=True, profile=False, project=None, rect=False, resume=False, retina_masks=False, save=True, save_conf=False, save_crop=False, save_dir=/Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model, save_frames=False, save_json=False, save_period=-1, save_txt=False, scale=0.5, seed=0, shear=0.0, show=False, show_boxes=True, show_conf=True, show_labels=True, simplify=True, single_cls=False, source=None, split=val, stream_buffer=False, task=detect, time=None, tracker=botsort.yaml, translate=0.1, val=True, verbose=True, vid_stride=1, visualize=False, warmup_bias_lr=0.1, warmup_epochs=3.0, warmup_momentum=0.8, weight_decay=0.0005, workers=0, workspace=None
Matplotlib is building the font cache; this may take a moment.
Overriding model.yaml nc=80 with nc=3
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]
23 [16, 19, 22] 1 431257 ultralytics.nn.modules.head.Detect [3, [64, 128, 256]]
YOLO11n summary: 181 layers, 2,590,425 parameters, 2,590,409 gradients, 6.4 GFLOPs
Transferred 448/499 items from pretrained weights
Freezing layer 'model.23.dfl.conv.weight'
train: Fast image access ✅ (ping: 0.0±0.0 ms, read: 416.0±152.6 MB/s, size: 148.1 KB)
train: Scanning /Users/hogworts/PycharmProjects/my-yolo-proj/datasets/my_dataset/labels/train... 8 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 8/8 636.9it/s 0.0s
train: New cache created: /Users/hogworts/PycharmProjects/my-yolo-proj/datasets/my_dataset/labels/train.cache
val: Fast image access ✅ (ping: 0.0±0.0 ms, read: 322.6±177.7 MB/s, size: 75.0 KB)
val: Scanning /Users/hogworts/PycharmProjects/my-yolo-proj/datasets/my_dataset/labels/val... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 4.0Kit/s 0.0s
val: New cache created: /Users/hogworts/PycharmProjects/my-yolo-proj/datasets/my_dataset/labels/val.cache
Plotting labels to /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.001429, momentum=0.9) with parameter groups 81 weight(decay=0.0), 88 weight(decay=0.0005), 87 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 2.3G 1.267 3.303 1.548 23 640: 100% ━━━━━━━━━━━━ 1/1 0.1it/s 19.3s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 0.1it/s 9.1s
all 4 4 0.00513 1 0.643 0.554
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/100 2.22G 1.365 3.264 1.613 28 640: 100% ━━━━━━━━━━━━ 1/1 0.6it/s 1.6s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.3it/s 0.4s
all 4 4 0.0055 1 0.631 0.543
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/100 2.21G 1.211 3.237 1.427 26 640: 100% ━━━━━━━━━━━━ 1/1 0.9it/s 1.1s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.8it/s 0.4s
all 4 4 0.00584 1 0.63 0.558
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/100 2.21G 1.104 3.221 1.456 26 640: 100% ━━━━━━━━━━━━ 1/1 0.7it/s 1.5s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.0it/s 0.5s
all 4 4 0.0062 1 0.64 0.568
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/100 2.22G 1.22 3.172 1.468 21 640: 100% ━━━━━━━━━━━━ 1/1 1.1it/s 0.9s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.1it/s 0.3s
all 4 4 0.00677 1 0.652 0.588
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/100 2.21G 1.213 3.256 1.574 21 640: 100% ━━━━━━━━━━━━ 1/1 1.3it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.1it/s 0.3s
all 4 4 0.00721 1 0.693 0.627
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/100 2.21G 1.234 3.462 1.649 18 640: 100% ━━━━━━━━━━━━ 1/1 1.1it/s 0.9s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.4it/s 0.3s
all 4 4 0.00836 1 0.76 0.69
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/100 2.21G 0.8984 2.921 1.335 26 640: 100% ━━━━━━━━━━━━ 1/1 1.4it/s 0.7s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 4.1it/s 0.2s
all 4 4 0.0105 1 0.76 0.686
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/100 2.21G 0.8167 3.057 1.274 17 640: 100% ━━━━━━━━━━━━ 1/1 1.0it/s 1.0s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.7it/s 0.4s
all 4 4 0.013 1 0.818 0.735
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/100 2.22G 0.7742 2.837 1.084 22 640: 100% ━━━━━━━━━━━━ 1/1 0.9it/s 1.1s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.0it/s 1.1s
all 4 4 0.0191 1 0.569 0.493
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
11/100 2.21G 0.7602 2.938 1.153 21 640: 100% ━━━━━━━━━━━━ 1/1 0.7it/s 1.4s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.1it/s 0.5s
all 4 4 0.0219 1 0.569 0.503
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
12/100 2.22G 0.6936 2.788 1.072 18 640: 100% ━━━━━━━━━━━━ 1/1 1.2it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.1it/s 0.3s
all 4 4 0.0257 1 0.487 0.444
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
13/100 2.21G 0.7928 2.902 1.186 26 640: 100% ━━━━━━━━━━━━ 1/1 1.2it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.1it/s 0.5s
all 4 4 0.0377 1 0.597 0.553
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
14/100 2.21G 0.86 3.125 1.24 21 640: 100% ━━━━━━━━━━━━ 1/1 1.3it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 2.1it/s 0.5s
all 4 4 0.0496 1 0.581 0.548
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
15/100 2.22G 0.8086 2.718 1.277 16 640: 100% ━━━━━━━━━━━━ 1/1 0.7it/s 1.4s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.7it/s 0.6s
all 4 4 0.0637 1 0.664 0.613
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
16/100 2.21G 0.8007 2.935 1.216 21 640: 100% ━━━━━━━━━━━━ 1/1 1.1it/s 0.9s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.3it/s 0.8s
all 4 4 0.0694 1 0.622 0.541
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
17/100 2.21G 0.7634 2.737 1.141 28 640: 100% ━━━━━━━━━━━━ 1/1 0.3it/s 3.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.5it/s 0.7s
all 4 4 0.0665 1 0.581 0.48
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
18/100 2.21G 0.7265 2.721 1.259 20 640: 100% ━━━━━━━━━━━━ 1/1 0.9it/s 1.1s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 3.2it/s 0.3s
all 4 4 0.0665 1 0.581 0.48
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
19/100 2.27G 0.8433 2.568 1.112 23 640: 100% ━━━━━━━━━━━━ 1/1 1.2it/s 0.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 1.4it/s 0.7s
all 4 4 0.0846 1 0.539 0.468
EarlyStopping: Training stopped early as no improvement observed in last 10 epochs. Best results observed at epoch 9, best model saved as best.pt.
To update EarlyStopping(patience=10) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
19 epochs completed in 0.022 hours.
Optimizer stripped from /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model/weights/last.pt, 5.5MB
Optimizer stripped from /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model/weights/best.pt, 5.5MB
Validating /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model/weights/best.pt...
Ultralytics 8.3.217 🚀 Python-3.9.24 torch-2.8.0 MPS (Apple M2)
YOLO11n summary (fused): 100 layers, 2,582,737 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 0.6it/s 1.6s
all 4 4 0.0133 1 0.802 0.722
cat 3 3 0.0244 1 0.608 0.548
bird 1 1 0.00216 1 0.995 0.895
Speed: 0.4ms preprocess, 283.6ms inference, 0.0ms loss, 51.0ms postprocess per image
Results saved to /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/my_yolo11_model
进程已结束,退出代码为 0
为什么 会出现EarlyStopping警告?
当前情况解读:
训练在 epoch 9 达到最佳性能随后10个epoch没有进一步改进
系统自动保存了 best.pt(第9个epoch的模型)
检查模型是否已经收敛
相关代码:
from ultralytics import YOLO
def evaluate_training():
# 加载最佳模型
model = YOLO('runs/train/my_yolo11_model/weights/best.pt')
# 在验证集上评估模型
results = model.val(
data='../configs/my_dataset.yaml', # 注意路径调整
device='mps'
)
print("=== 模型评估结果 ===")
print(f"mAP50: {results.box.map50:.4f}")
print(f"mAP50-95: {results.box.map:.4f}")
print(f"精确度 (Precision): {results.box.p[0]:.4f}") # 修正这里
print(f"召回率 (Recall): {results.box.r[0]:.4f}") # 修正这里
print(f"F1分数: {results.box.f1[0]:.4f}")
# 各类别详细结果
print("\n=== 各类别性能 ===")
for i, class_name in enumerate(['cat', 'bird']): # 根据你的类别修改
print(f"{class_name}: mAP50={results.box.ap50[i]:.4f}, mAP50-95={results.box.ap[i]:.4f}")
# 性能评估
print("\n=== 性能分析 ===")
if results.box.map50 > 0.8:
print("✅ 优秀!模型性能非常好!")
print("💡 建议:训练已经充分,可以直接使用模型")
elif results.box.map50 > 0.6:
print("✅ 良好!模型性能不错")
print("💡 建议:可以继续训练或直接使用")
elif results.box.map50 > 0.4:
print("⚠️ 一般!模型有改进空间")
print("💡 建议:继续训练或调整参数")
else:
print("❌ 较差!需要优化")
print("💡 建议:检查数据质量或重新训练")
return results
if __name__ == '__main__':
evaluate_training()
结果是好是坏呢?
/Users/hogworts/miniconda3/envs/yolo11/bin/python /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/evaluate_model.py
Ultralytics 8.3.217 🚀 Python-3.9.24 torch-2.8.0 MPS (Apple M2)
YOLO11n summary (fused): 100 layers, 2,582,737 parameters, 0 gradients, 6.3 GFLOPs
val: Fast image access ✅ (ping: 0.0±0.0 ms, read: 273.1±174.0 MB/s, size: 75.0 KB)
val: Scanning /Users/hogworts/PycharmProjects/my-yolo-proj/datasets/my_dataset/labels/val.cache... 4 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 4/4 124.3Kit/s 0.0s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 1/1 0.9it/s 1.1s
all 4 4 0.0133 1 0.802 0.722
cat 3 3 0.0244 1 0.608 0.548
bird 1 1 0.00216 1 0.995 0.895
Speed: 1.8ms preprocess, 193.0ms inference, 0.0ms loss, 22.4ms postprocess per image
Results saved to /Users/hogworts/PycharmProjects/my-yolo-proj/scripts/runs/detect/val2
=== 模型评估结果 ===
mAP50: 0.8017
mAP50-95: 0.7219
精确度 (Precision): 0.0244
召回率 (Recall): 1.0000
F1分数: 0.0476
=== 各类别性能 ===
cat: mAP50=0.6083, mAP50-95=0.5483
bird: mAP50=0.9950, mAP50-95=0.8955
=== 性能分析 ===
✅ 优秀!模型性能非常好!
💡 建议:训练已经充分,可以直接使用模型
进程已结束,退出代码为 0
性能是不错,但是可用性很差,下面来根据这几个指标得分分析一下。
模型评估
好的模型(理想情况):
精确度 > 0.7 ✅
召回率 > 0.8 ✅
F1分数 > 0.75 ✅
mAP50 > 0.8 ✅
你的模型:
精确度 = 0.0244 ❌(严重问题)
召回率 = 1.0000 ✅(优秀)
F1分数 = 0.0476 ❌(严重问题)
mAP50 = 0.8017 ⚠️(表面好看)
- 精确度 (Precision) = 0.0244 ❌
通俗理解:模型说"我找到了目标",这个说法有多可靠?
情况:模型每说100次"我找到了目标",只有2.44次是真的
比喻:像是一个保安,看到100个人就说"这些都是小偷",结果只有2个是真的小偷
结论:非常差,模型产生了大量误报
- 召回率 (Recall) = 1.0000 ✅
通俗理解:真实的目标中,模型找到了多少?
情况:所有真实目标都被找到了,一个不漏
比喻:保安抓住了所有真正的小偷,但把很多好人也当成了小偷
结论:完美,但代价是很多误检
- F1分数 = 0.0476 ❌
通俗理解:精确度和召回率的综合评分
范围:0-1,越接近1越好
情况:0.0476非常低
结论:很差,整体检测质量不好
- mAP50 = 0.8017 ⚠️
通俗理解:在宽松标准下的整体检测准确度
情况:0.80看起来不错
但要注意:这个指标可能被高召回率拉高,掩盖了精确度问题

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)