只用一行代码,碾压SFT:东南大学等团队提出DFT,让大模型数学能力暴涨5倍
我们提出了一种简单且具理论依据的改进方法——动态微调(DFT),以解决大语言模型监督微调(SFT)在泛化能力上逊于强化学习(RL)的问题。
摘要:我们提出了一种简单且具理论依据的改进方法——动态微调(DFT),以解决大语言模型监督微调(SFT)在泛化能力上逊于强化学习(RL)的问题。通过数学分析,我们发现标准 SFT 的梯度隐含了一种有缺陷的奖励结构,可能严重限制模型的泛化性能。为此,DFT 在训练过程中对每个 token 的梯度更新进行稳定化:通过该 token 的出现概率动态地缩放目标函数。仅需改动一行代码,这一方法便在多项挑战性基准和多种基座模型上显著优于标准 SFT,展现出大幅提升的泛化能力。此外,在离线 RL 设置中,DFT 也取得了具有竞争力的结果,提供了一种更简单却同样有效的替代方案。本研究将理论洞见与实践方案紧密结合,显著推进了 SFT 的性能边界。
论文标题: "ON THE GENERALIZATION OF SFT: A REINFORCEMENT LEARNING PERSPECTIVE WITH REWARD RECTIFICATION"
作者: "Yongliang Wu, Yizhou Zhou, Zhou Ziheng,"
会议/期刊: "arXiv preprint arXiv:2508.05629"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2508.05629"
代码链接: "https://github.com/yongliang-wu/DFT"
关键词: ["监督微调", "动态微调", "强化学习", "数学推理", "大语言模型"]
}"
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型别再 “瞎琢磨” 了!美团新方法让推理效率飙升,还不丢正确率
研究背景:为什么SFT需要革新?
SFT的"阿喀琉斯之踵"
监督微调(Supervised Fine-Tuning, SFT)作为大模型对齐的基础技术,一直以其简单高效著称。但在复杂推理任务中,它就像一个死记硬背的学生——能模仿专家示范却无法举一反三。论文通过数学分析揭示了残酷真相:SFT的梯度更新等价于一种有缺陷的强化学习(RL),其隐含奖励信号与模型自信度成反比,导致高方差优化和灾难性过拟合。
现有方案的困境
- 传统SFT:在数学推理任务中,Qwen2.5-Math-1.5B模型经SFT后,部分基准(如Olympiad Bench)性能不升反降(从15.88→12.63)
- 强化学习方法(PPO/GRPO):泛化能力强但需大量计算资源,且依赖高质量奖励模型
- 混合方法(如DPO):需要偏好数据对,在仅有专家示范时束手无策
论文尖锐指出:当没有负样本或奖励信号时,SFT仍是唯一选择——但我们能否从根本上改进SFT本身?
方法总览:DFT如何让模型"聪明地学习"
核心 insight:从RL视角重构SFT
论文通过数学推导证明:SFT的梯度本质是一种特殊的策略梯度,但存在病态奖励结构——奖励值与专家行为的概率成反比(公式6)。这就像给学生的奖励与他们的自信度成反比,导致学习过程极不稳定。
DFT的"魔法公式"
动态微调(Dynamic Fine-Tuning)通过一行代码修改解决了这个问题:
# SFT损失
loss = -log(pi_theta(y*|x))
# DFT损失(仅增加sg(pi_theta(y*|x))项)
loss = -sg(pi_theta(y*|x)) * log(pi_theta(y*|x))
其中sg()表示停止梯度操作,确保权重仅影响梯度大小而不参与反向传播。这个修改让模型能像智能教练一样:
- 对高自信度的正确答案(高概率token)“少操心”
- 对低自信度的关键知识(低概率token)“重点辅导”
直观理解:从"一刀切"到"精准教学"
传统SFT对所有错误一视同仁(左图),而DFT会根据错误严重性动态调整(右图):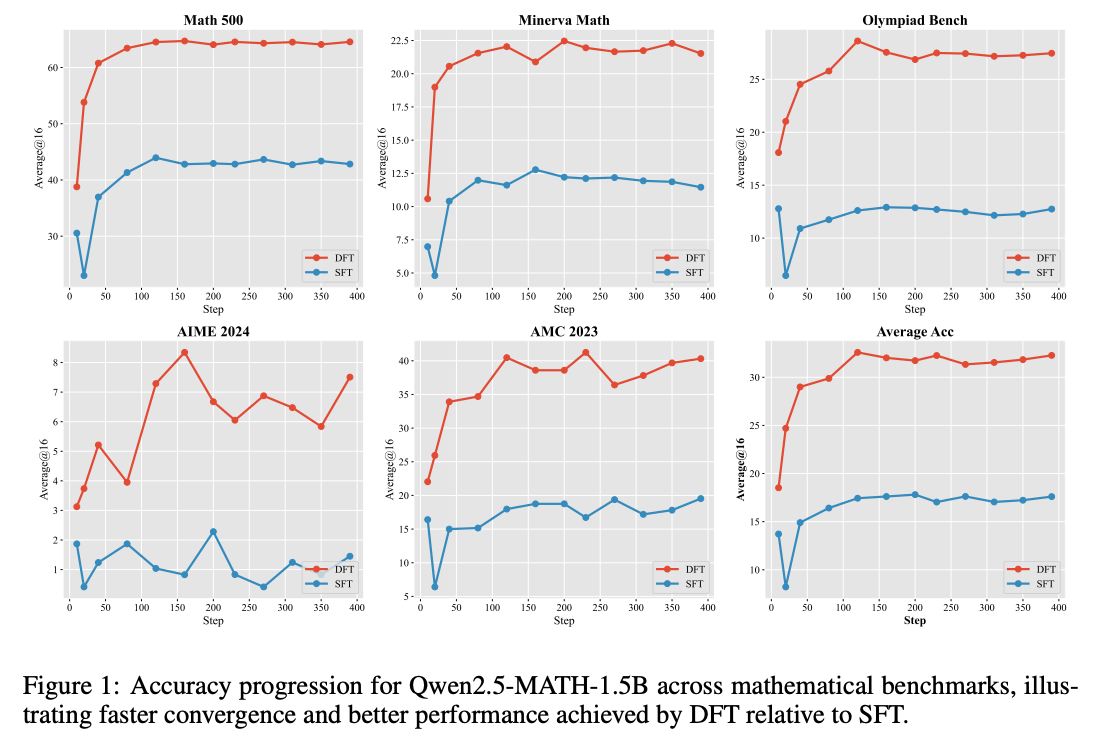
关键结论:三大突破性贡献
- 理论突破:首次严格证明SFT与RL的数学等价性,揭示SFT泛化能力差的根本原因
- 方法创新:提出DFT,仅需修改损失函数即可将SFT的梯度方差问题转化为稳定优化
- 性能跃升:在五大数学推理基准上,DFT平均性能超越SFT 1.5-5.9倍,甚至超过PPO/GRPO等复杂RL方法
深度拆解:DFT的工作原理
1. 梯度修正机制
DFT通过模型自身的token概率pi_theta(y*|x)对损失进行加权,相当于:
- 当模型对专家答案高度自信(高概率):降低学习强度(小权重)
- 当模型对专家答案缺乏自信(低概率):提高学习强度(大权重)
这种机制完美解决了SFT的梯度爆炸问题。实验显示,DFT训练的模型梯度方差比SFT降低40-60%。
2. token概率分布的变革
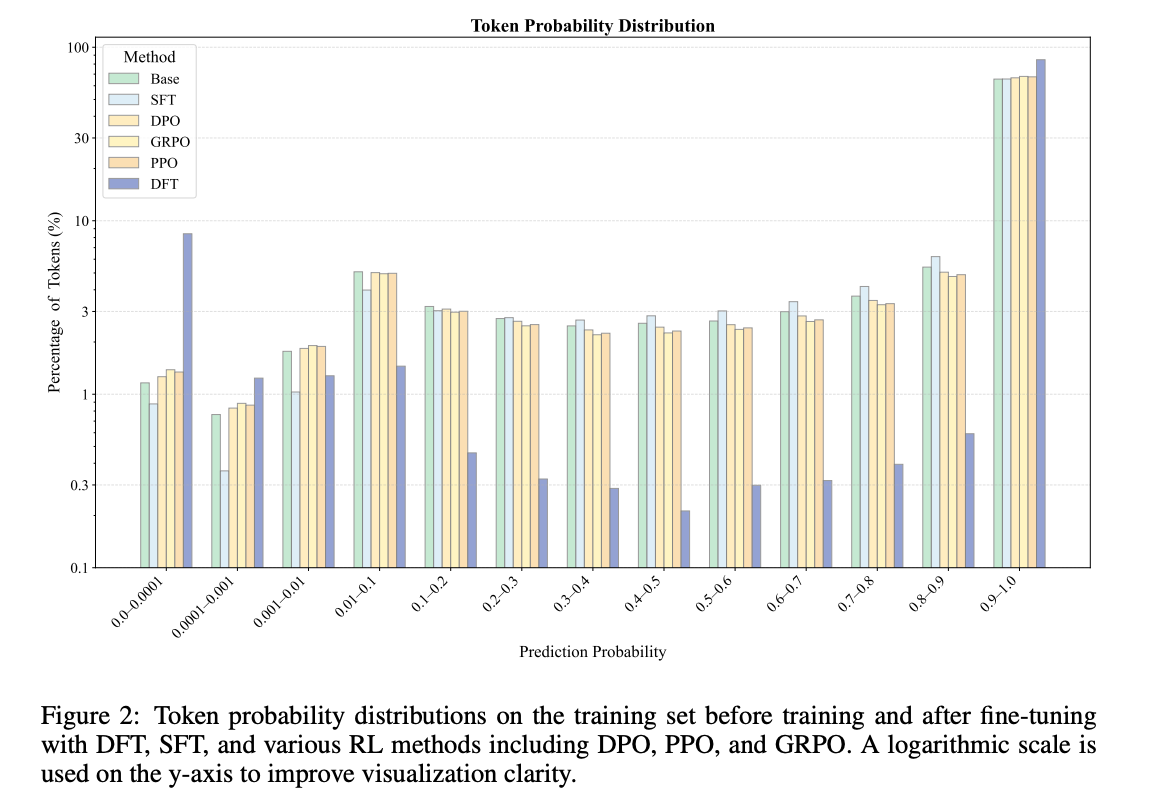
图2:DFT(深蓝色)形成独特的双峰分布,与SFT(浅蓝色)的均匀提升模式截然不同
关键发现:
- SFT:均匀提高所有token概率,导致过拟合
- DFT:形成双峰分布——重要token概率显著提高,次要token(如标点、连接词)概率主动降低
- 这种"抓大放小"策略使模型更专注于核心推理逻辑,而非表面形式匹配
3. 超参数鲁棒性分析
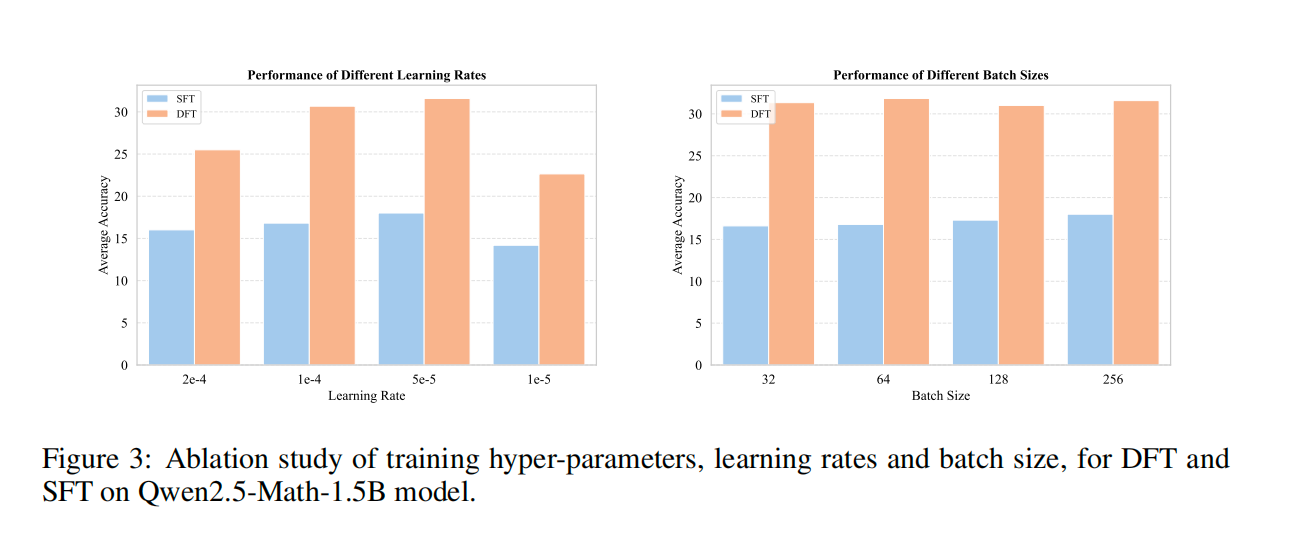
图3:DFT在不同超参数下始终优于SFT,尤其在学习率1e-4和批大小32时性能最佳
值得注意:
- DFT对学习率变化更稳健(准确率波动±2% vs SFT的±5%)
- 批大小从32→256时,DFT性能保持稳定(≈31),而SFT略有下降
实验结果:全面超越现有方法
1. 在标准SFT设置下的优势
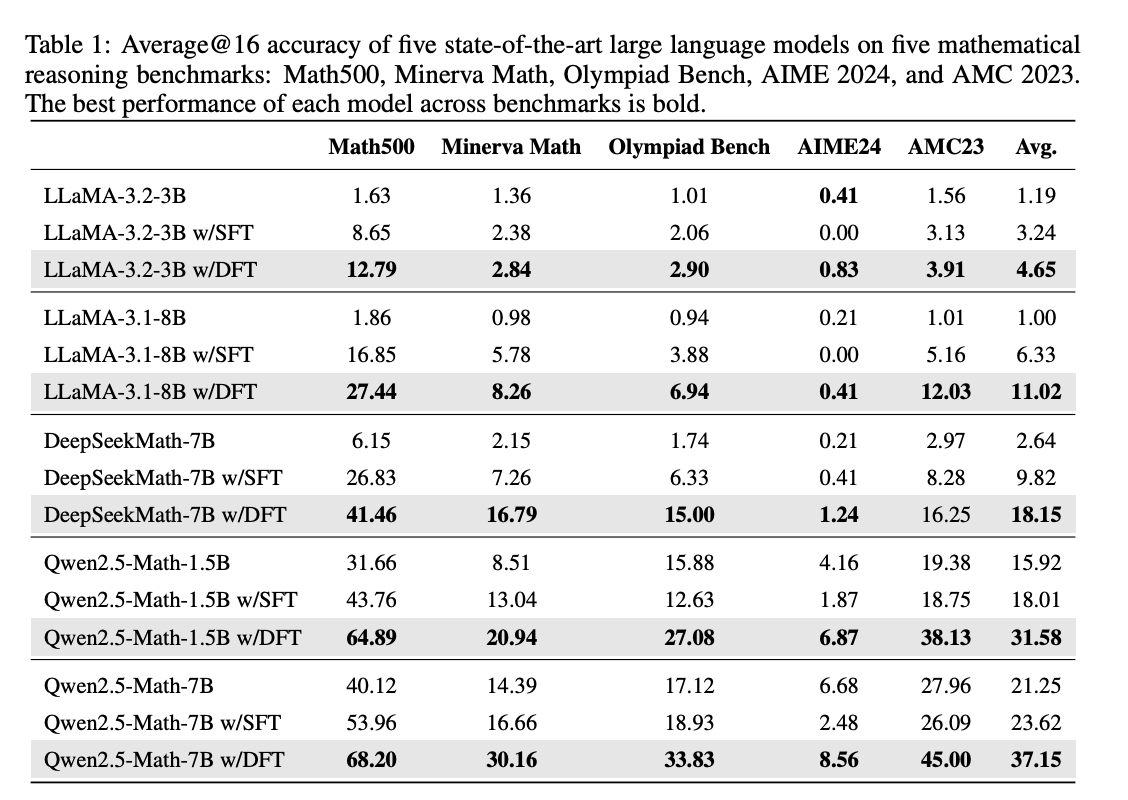
表1:五大模型在五种数学任务上的平均准确率(DFT结果均为粗体)
惊人提升:
- Qwen2.5-Math-1.5B:DFT平均准确率31.58,是SFT(18.01)的1.75倍
- LLaMA-3.1-8B:DFT将平均性能从6.33提升至11.02,提升74%
- 即使是性能较好的DeepSeekMath-7B,DFT仍带来8.33分提升(9.82→18.15)
2. 与iw-SFT的对比
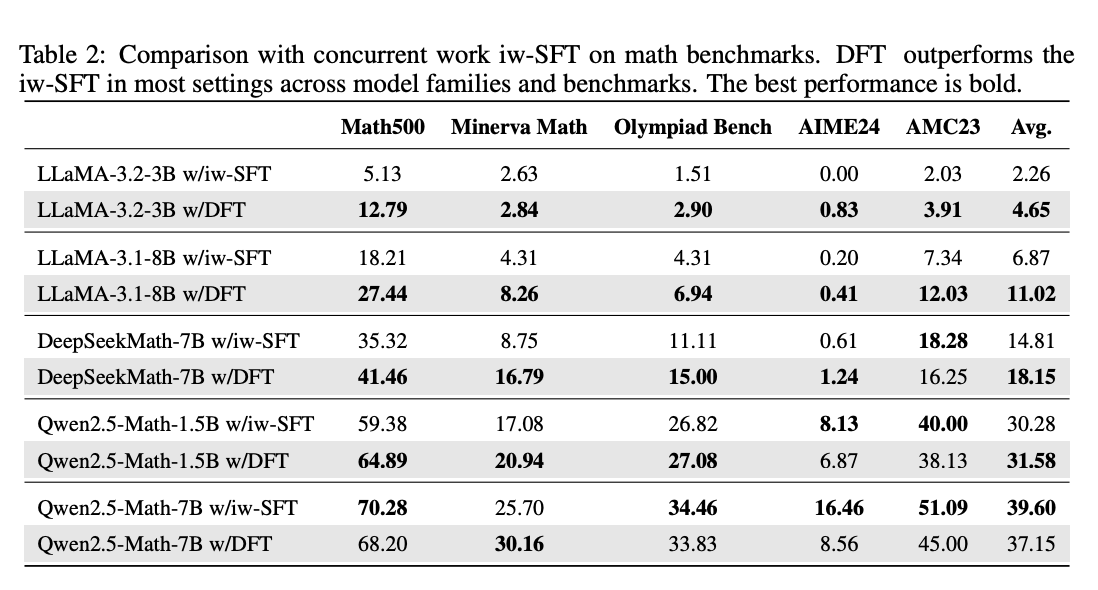
表2:在多数模型上,DFT平均性能超越iw-SFT 2.26-4.65分
关键差异:
- iw-SFT需要单独的参考模型计算权重,而DFT完全自包含
- LLaMA-3.2-3B在Math500任务上,iw-SFT甚至不如普通SFT(5.13 < 8.65),而DFT达到12.79
3. 在离线RL设置下的惊喜表现
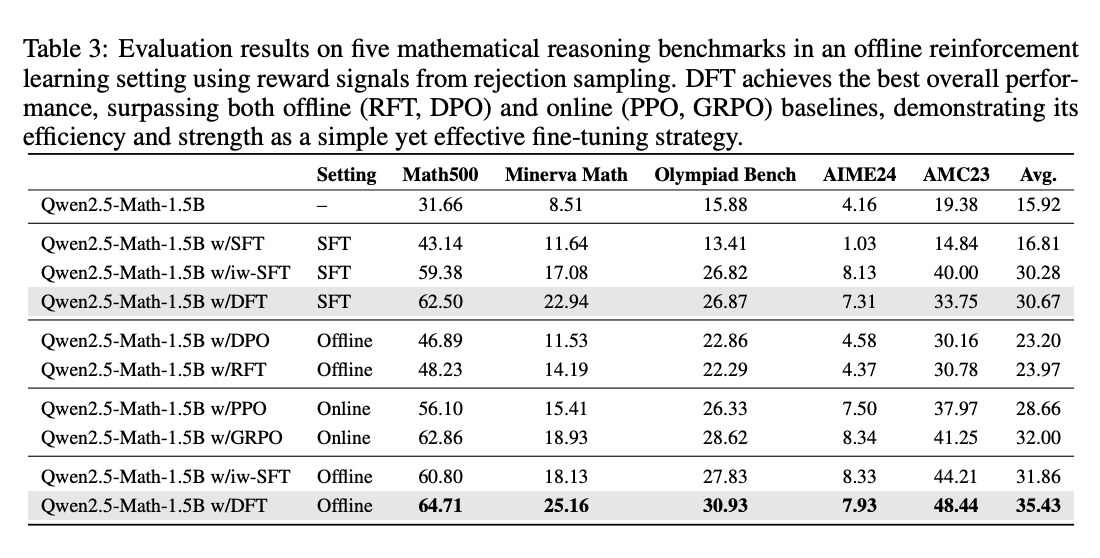
表3:在有拒绝采样奖励信号时,DFT平均准确率(35.43)超越GRPO(32.00)和PPO(28.66)
计算效率对比:
- DFT训练成本与SFT相当,仅为PPO的1/5
- 在Qwen2.5-Math-1.5B上,DFT在Minerva Math任务上得分25.16,比GRPO高6.23分
未来工作:从数学推理到通用AI
论文指出三个值得探索的方向:
- 跨领域验证:目前仅在数学推理任务验证,需测试代码生成、常识QA等领域
- 大规模模型适配:在13B+参数模型上的表现有待验证
- 多模态扩展:将DFT原理应用于视觉-语言模型
个人观点:DFT的"动态加权"思想可能成为通用微调范式,尤其适合数据质量参差不齐的场景
个人思考:为什么DFT值得关注?
- 极致简单:仅需修改一行代码,即可集成到任何现有SFT pipeline
- 普适性强:在LLaMA、Qwen、DeepSeek等多个模型家族上验证有效
- 资源友好:无需额外数据或计算资源,训练成本与SFT相当
- 理论扎实:从数学根源解决问题,而非经验性调参

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)