好用的开源日志输出工具:SEGGER_RTT实现机制解析
SEGGER RTT是一种基于内存共享的实时调试技术,通过控制块结构管理数据传输。其核心机制包括:1)使用环形缓冲区和生产-消费者模型实现无锁通信;2)支持多通道配置,可区分上下行数据;3)采用原子操作保证指针更新的线程安全;4)同时支持阻塞和非阻塞模式,满足不同实时性需求。该技术无需专用调试接口,能在保持原有代码结构的同时实现高效调试,适用于嵌入式系统开发。
目录
RTT实现机制
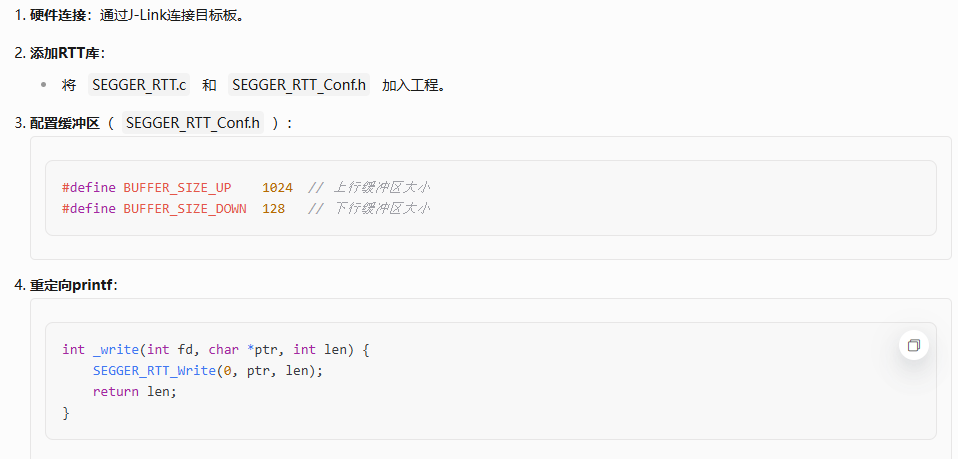
RTT 工作原理介绍
RTT 在芯片内存中使用 控制块结构 来管理数据的读取和写入。控制块包含一个 ID,以便通过连接的
JLINK 在内存中找到它,并为每个可用通道提供一个结构体,用于描述缓冲区及其状态。
可用通道的最大数量可以在编译时进行配置,并且每个缓冲区都可以在运行时由应用程序进行配置和
添加。上行和下行缓冲区可以分开处理。
每个通道可以配置为阻塞或非阻塞:
在阻塞模式下,当缓冲区已满时,应用程序将等待,直到有空间可以写入数据,虽然应用程序状态被阻止,但可以防止数据丢失。
在非阻塞模式下,只有不超过缓冲区大小的数据被写入,其余的数据将被丢弃。即使没有连接调试器,也可以实时运行。
而且开发人员不必创建特殊的调试版本,代码可以保留在以后发布的项目工程中。
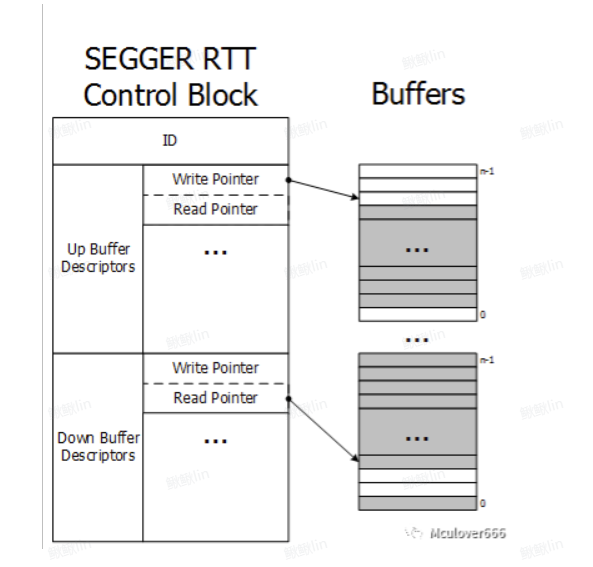
SEGGER RTT(Real-Time Transfer)是一种基于内存共享的实时调试技术,通过控制块+双缓冲队列实现主机(如J-Link调试器)与目标设备之间的高效通信。
一、核心组件解析(基于图中结构)
-
控制块(Control Block)
作用:管理所有缓冲区的元数据,是RTT通信的核心枢纽。
关键字段:
ID:标识控制块(用于多实例场景)。
Up Buffer Descriptors:上行缓冲区描述符数组(设备→主机)。
Down Buffer Descriptors:下行缓冲区描述符数组(主机→设备)。
每个描述符包含:
Write Pointer:写指针(生产者更新)。
Read Pointer:读指针(消费者更新)。
Buffer Size:缓冲区大小。
-
缓冲区(Buffers)
上行缓冲区(Up Buffer):
用于设备向主机发送数据(如日志输出、调试信息)。
可配置多个通道(如通道0用于标准输出,通道1用于错误信息)。
下行缓冲区(Down Buffer):
用于主机向设备发送数据(如命令输入、控制信号)。
同样支持多通道。
二、工作机制详解
1.双指针无锁队列
数据结构:每个缓冲区是一个环形队列。
生产者-消费者模型:
设备端(生产者):向缓冲区写入数据时,仅修改写指针。
主机端(消费者):从缓冲区读取数据时,仅修改读指针。
同步机制:
通过内存原子操作保证指针操作的原子性,无需锁。
示例:设备写入数据后,通过SEGGER_RTT_Write()自动更新写指针。
2.实时数据传输流程
// 设备端发送日志(上行缓冲区)
SEGGER_RTT_Write(0, "Hello RTT!", 10); // 写入通道0
// 主机端读取数据(通过J-Link RTT Viewer)
while (1) {
char buf[128];
int num_read = SEGGER_RTT_Read(0, buf, sizeof(buf));
if (num_read > 0) {
printf("%.*s", num_read, buf);
}
}3. 多通道支持

// 在SEGGER_RTT_Conf.h中定义
#define SEGGER_RTT_MAX_NUM_UP_BUFFERS 3 // 上行3个通道
#define SEGGER_RTT_MAX_NUM_DOWN_BUFFERS 2 // 下行2个通道4. 中断安全设计
低中断延迟:缓冲区操作仅需几个时钟周期。
中断服务程序(ISR)中使用:
void UART_ISR() {
SEGGER_RTT_Write(0, "ISR triggered!\n", 15);
}配置:
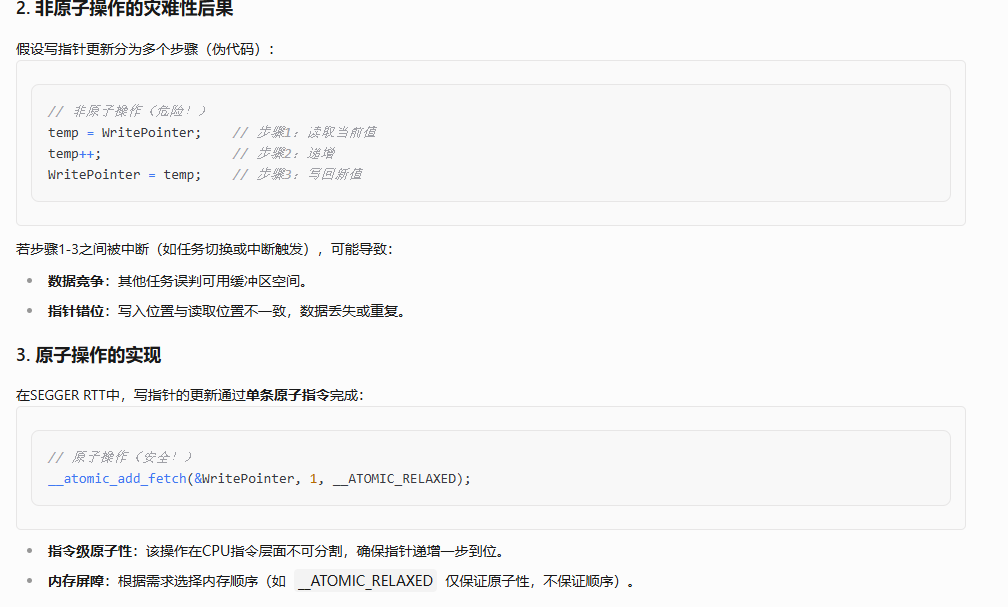
RTT控制块原子操作
SEGGER RTT控制块中的写指针和读指针通过内存原子操作保证原子性,无需锁。
在嵌入式系统或并发编程中,原子操作(Atomic Operation) 是指不可分割的单个指令级操作,它在执行过程中不会被中断或干扰,从而确保数据操作的完整性和一致性。
一、原子操作的核心特性
不可分割性:
原子操作要么完整执行,要么完全不执行,不会出现“执行到一半被中断”的情况。
例如,写指针的更新(Write Pointer++)在一条原子指令中完成,不会被其他任务或中断打断。
内存可见性:
原子操作的结果立即对所有线程/核心可见,避免缓存不一致性问题。
无锁同步:
原子操作本身具有同步能力,无需依赖锁(Mutex/Semaphore)等传统同步机制。
无锁环形缓冲区:
生产者(设备)和消费者(主机)通过原子指针操作共享缓冲区,无需锁。
示例:设备写入数据时原子更新写指针,主机读取后原子更新读指针。
什么是锁?
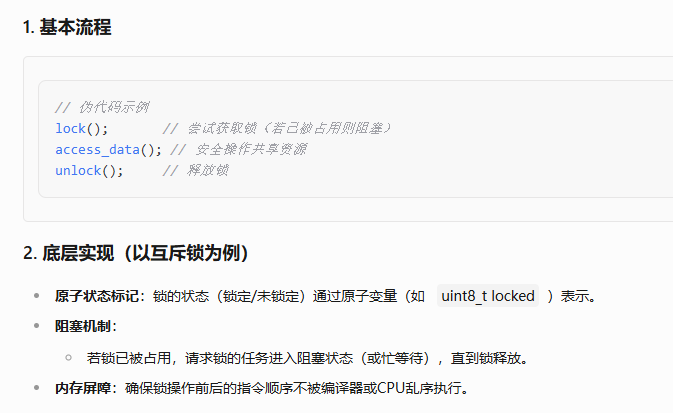
锁(Lock) 是一种用于协调多任务/多线程访问共享资源的同步机制。它的核心目的是防止多个执行单元(如线程、任务、中断等)同时操作同一资源时导致的数据不一致、竞态条件(Race Condition)或其他不可预测的错误。
锁的核心作用
锁通过强制串行化访问来解决以下问题:
a.数据竞争:多个任务同时修改共享变量(如全局变量、硬件寄存器)。
b.操作原子性:确保复杂操作(如链表插入)的不可分割性。
c.资源互斥:保证同一时刻仅有一个任务使用资源(如外设、文件)
锁的分类与常见类型
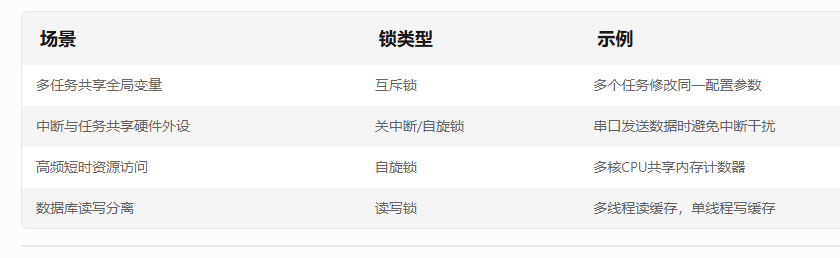
互斥锁(Mutex)
用途:确保同一时刻只有一个任务访问资源。
特点:
支持优先级继承(防止优先级反转)。
不可递归(同一任务重复加锁会导致死锁)。
SemaphoreHandle_t mutex = xSemaphoreCreateMutex();
xSemaphoreTake(mutex, portMAX_DELAY); // 加锁
xSemaphoreGive(mutex); // 解锁自旋锁(Spinlock)
用途:多核系统中短期资源保护。
特点:
忙等待(不释放CPU,循环检测锁状态)。
无上下文切换开销,但浪费CPU周期。
读写锁(Read-Write Lock)
用途:区分读操作和写操作。
多个读操作可并发执行。
写操作需独占访问。
// 读锁定
rwlock_read_lock(lock);
// 读数据...
rwlock_read_unlock(lock);
// 写锁定
rwlock_write_lock(lock);
// 写数据...
rwlock_write_unlock(lock);递归锁(Recursive Lock)
用途:允许同一任务多次加锁。
特点:需匹配相同次数的解锁操作。
应用场景:递归函数访问共享资源。

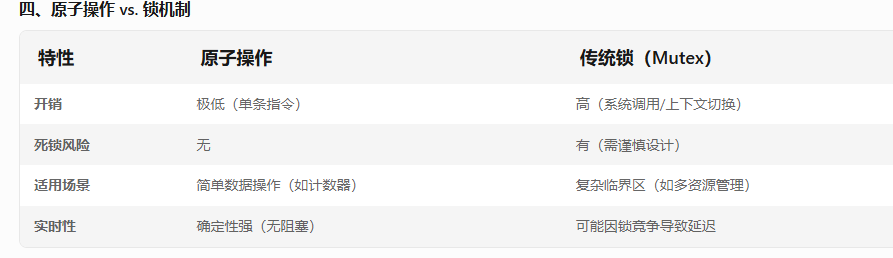
选择建议:
简单变量 → 原子操作。
复杂操作 → 互斥锁。
高频短时操作 → 自旋锁。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)