《大数据技术原理与应用》实验报告四 MapReduce初级编程实践
本实验报告记录了基于Hadoop的MapReduce编程实践,涵盖三个任务:1) 文件合并与去重;2) 多文件整数排序;3) 表格数据挖掘(父子辈转祖孙辈关系)。实验使用VMware虚拟机,配置Hadoop-3.1.3等工具,通过Eclipse开发实现。报告描述了各实验的编程实现、代码结构及运行结果,并总结了22个常见问题的解决方法,如Hadoop启动失败、数据倾斜处理、文件格式转换等。通过实验,
目 录
一、实验目的
1. 通过实验掌握基本的 MapReduce 编程方法。
2. 掌握用 MapReduce 解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
二、实验环境
1. 硬件要求:笔记本电脑一台
2. 软件要求:VMWare虚拟机、Ubuntu 18.04 64、JDK1.8、Hadoop-3.1.3、HBase-2.2.2、Windows11操作系统、Eclipse
三、实验内容与完成情况
3.1 编程实现文件合并和去重操作
1. 打开VMware虚拟机后在终端内输入Eclipse的启动语句进行Eclipse的启动:
./eclipse
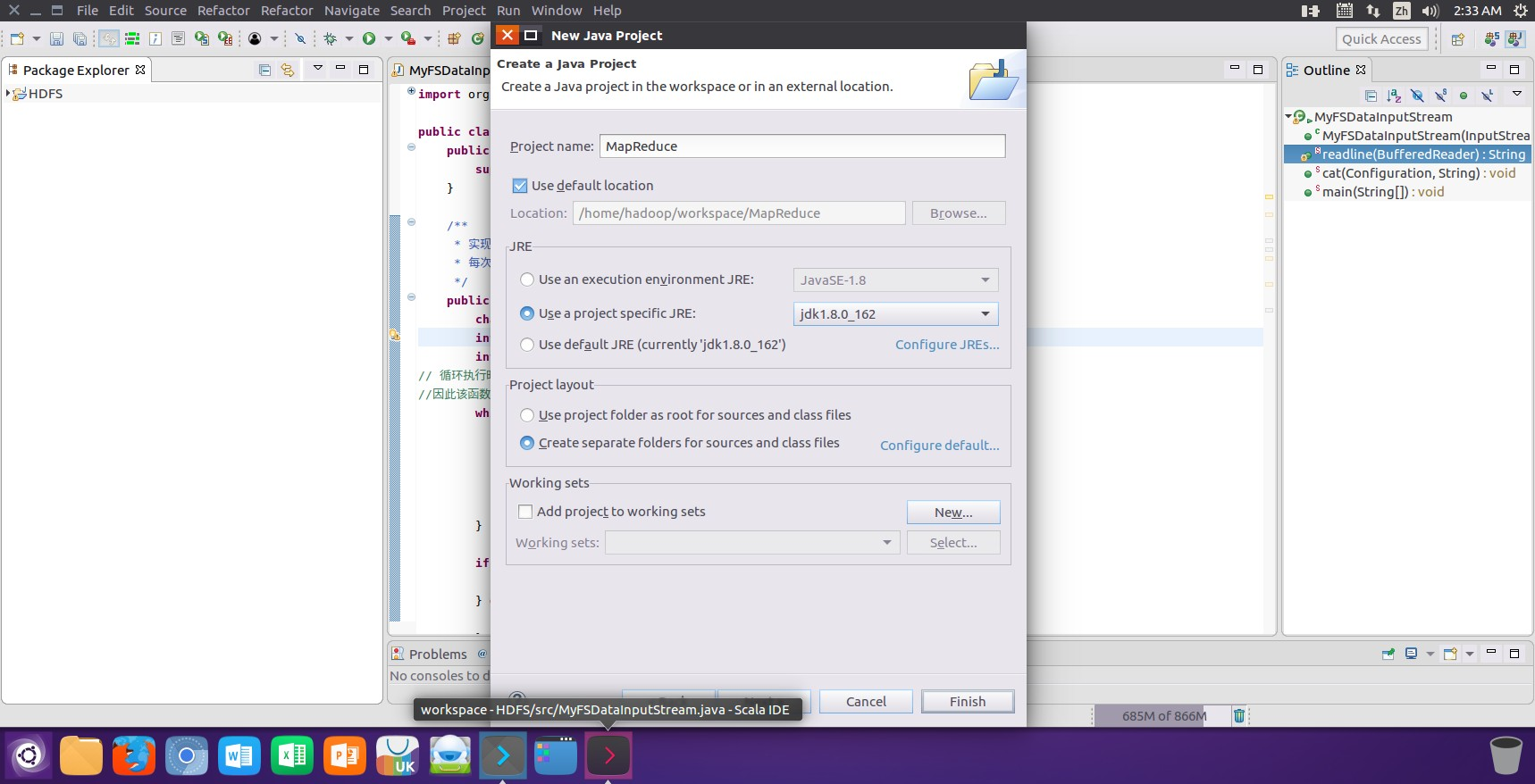
2. 启动Eclipse后进入到Eclipse主页面,然后点击新建进行Mapreduce项目的创建:
Mapreduce
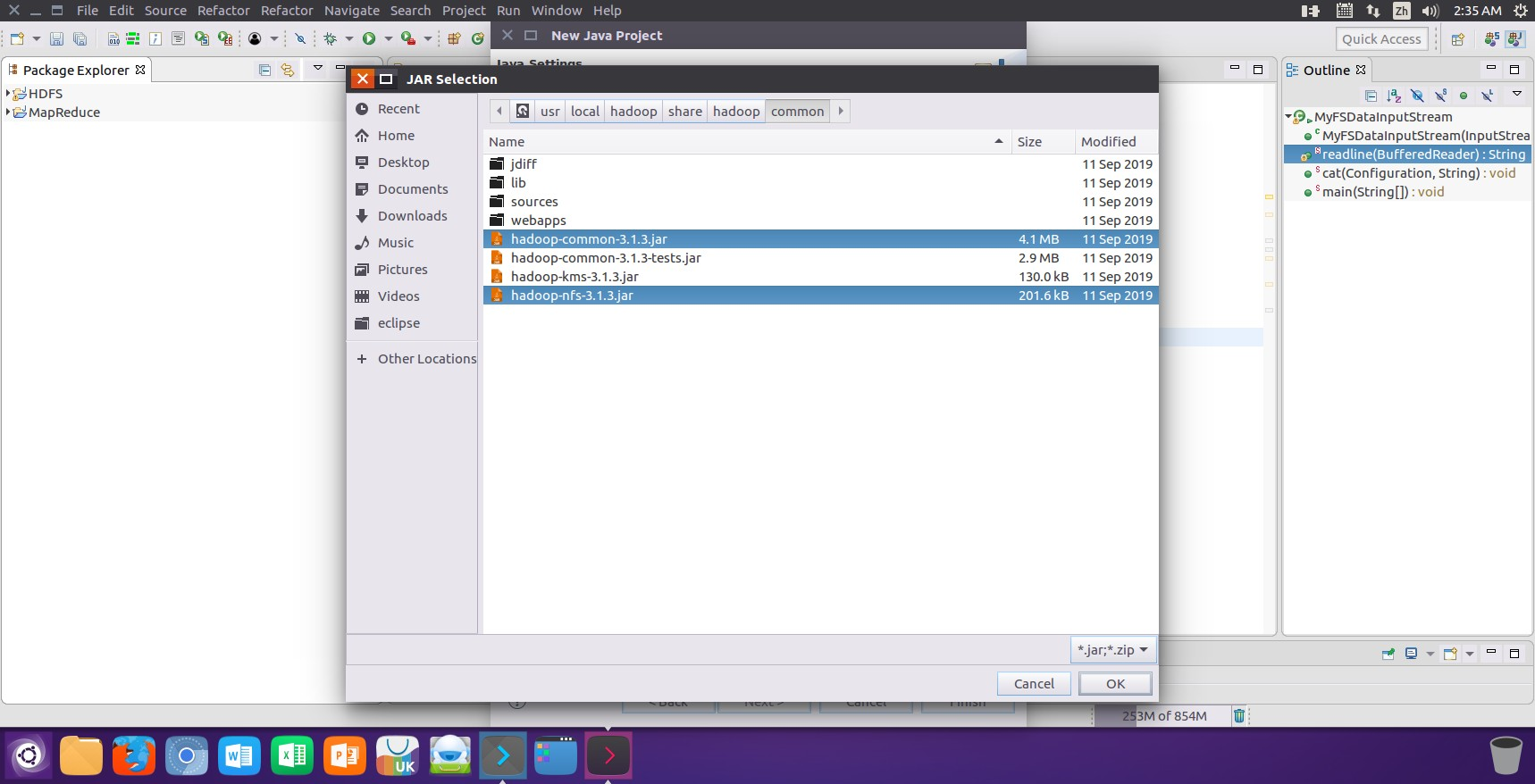
3. 在创建项目时点击界面中的“Libraries”选项卡,然后点击界面右侧的“Add External JARs…”按钮进行项目运行所需jar包的添加:
4. 将相关项目运行所需要的jar添加后进行添加jar包结果的查看:
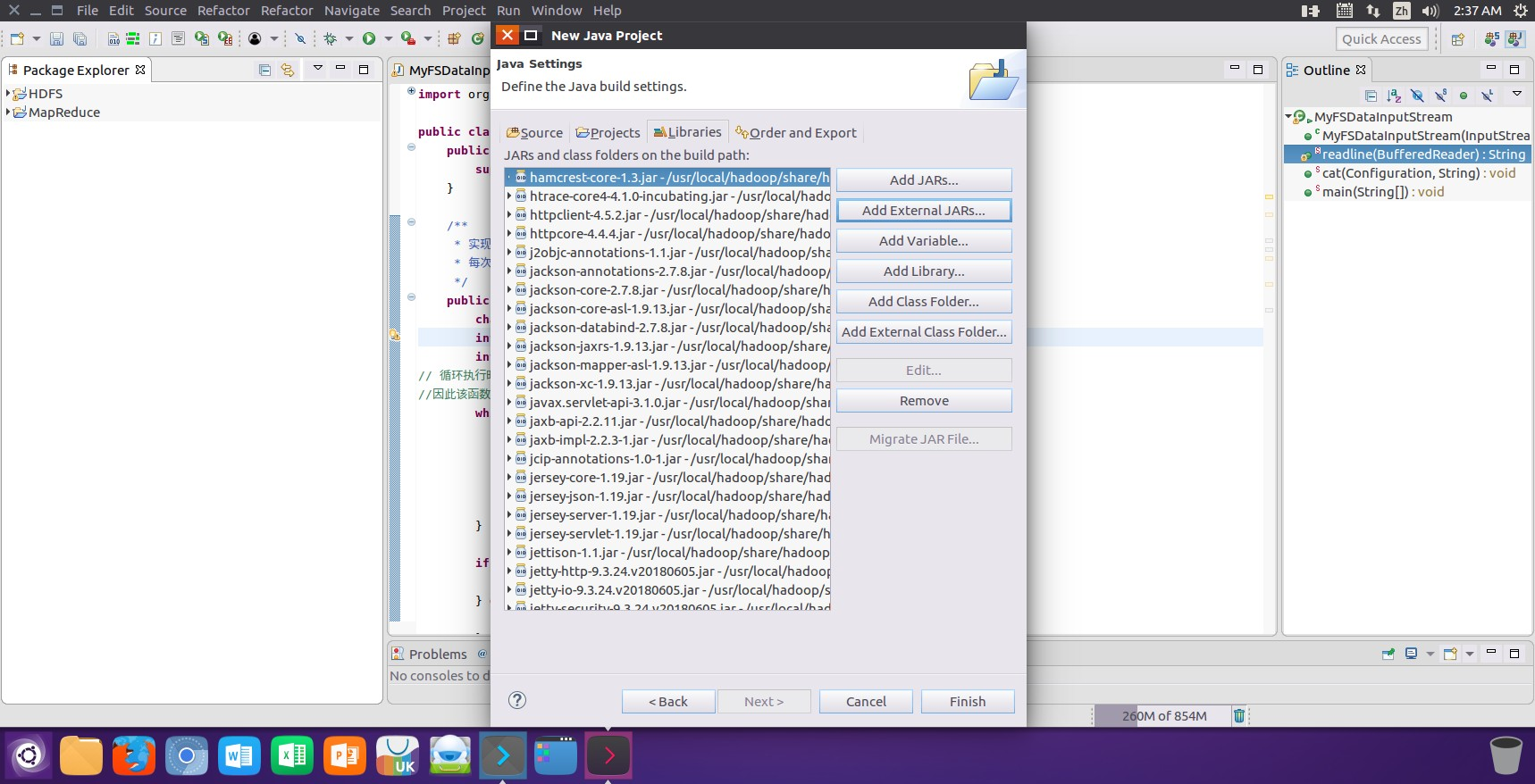
5. 确保jar全部添加完毕后点击finsh按钮进行最终项目的创建,项目创建完毕后依据对应的需求新建相关的java类文件进行相关的操作:
Merge
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件 C。
(1)在Mapreduce中创建Merge类对文件A和文件B两个文件进行合并去重操作:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Merge {
/**
* 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
*/
public static class Map extends Mapper<Object, Text, Text, Text> {
private Text text = new Text(); // 在成员变量中初始化
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
text.set(value); // 直接设置输入的value作为key
context.write(text, new Text("")); // 直接写入,不需要其他处理
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text("")); // 直接输出key,去重已经完成
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
// 输入和输出路径
String[] otherArgs = new String[]{"input", "output"}; // 直接设置输入输出参数
// 检查参数数量
if (otherArgs.length != 2) {
System.err.println("Usage: Merge <in> <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "Merge and duplicate removal");
job.setJarByClass(Merge.class);
// 设置Mapper和Reducer类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交任务并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}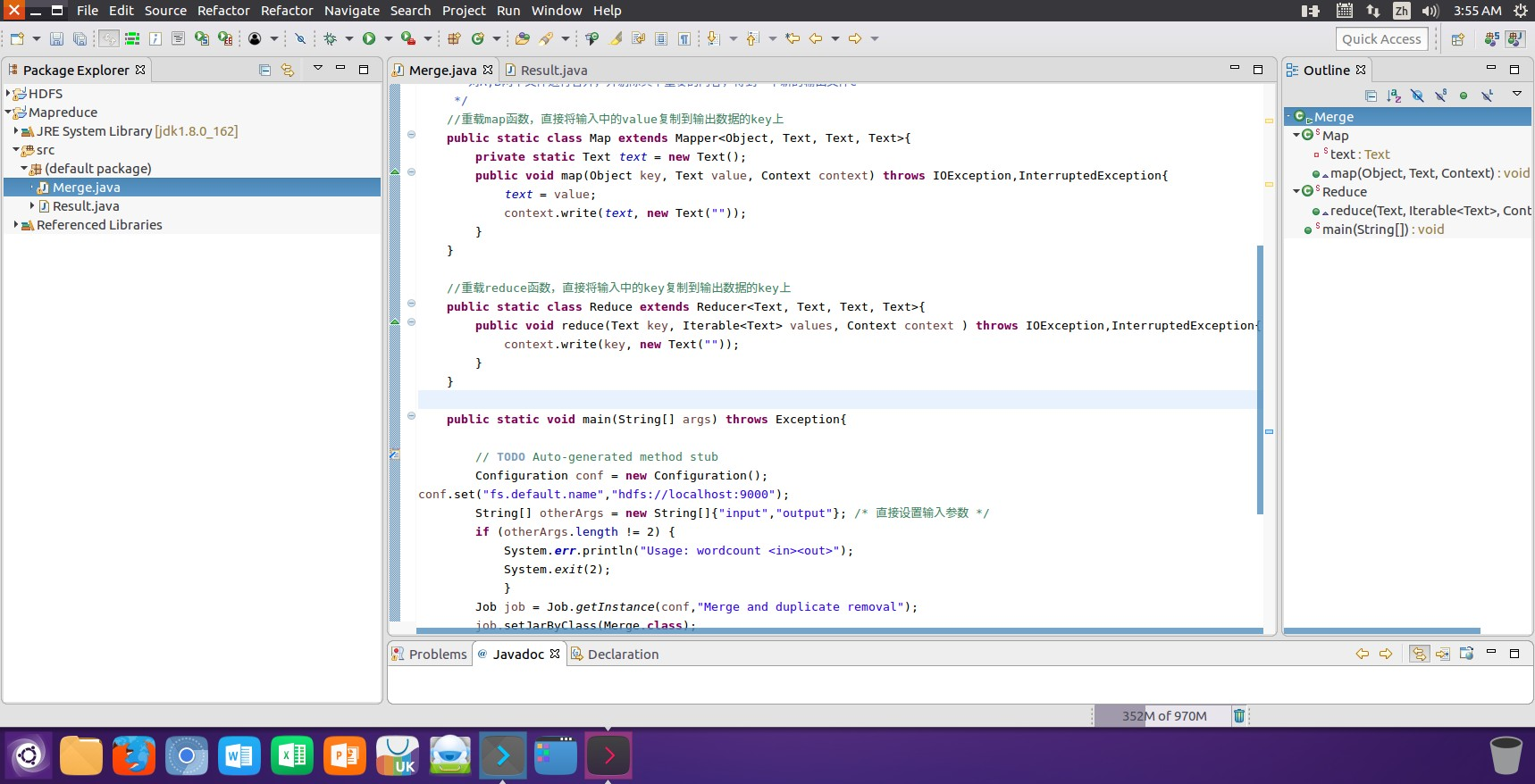
(2)运行创建的Merge类后得到一个对文件A和文件B两个文件进行合并去重操作后的输出文件C,并将文件的内容在控制台进行输出显示:
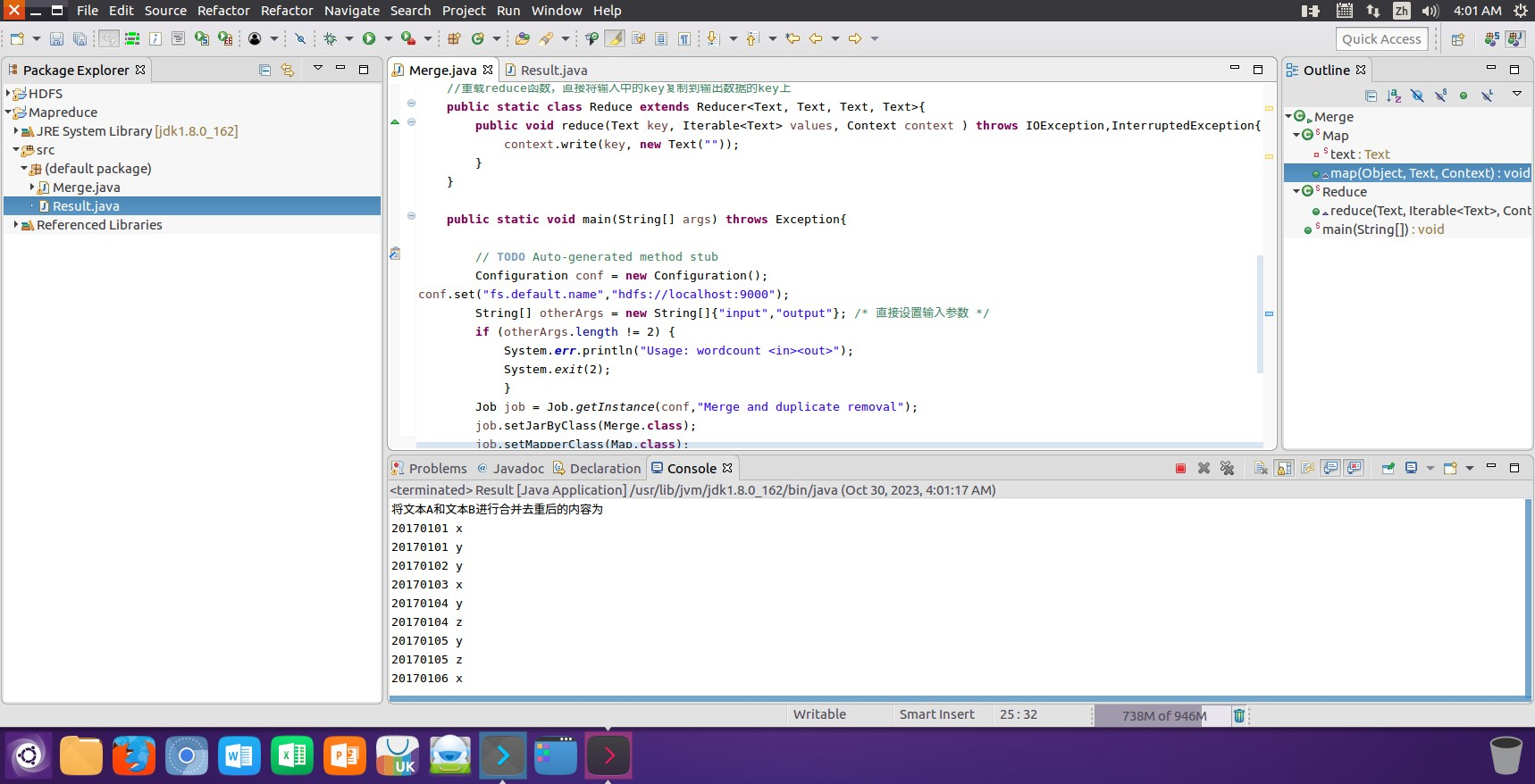
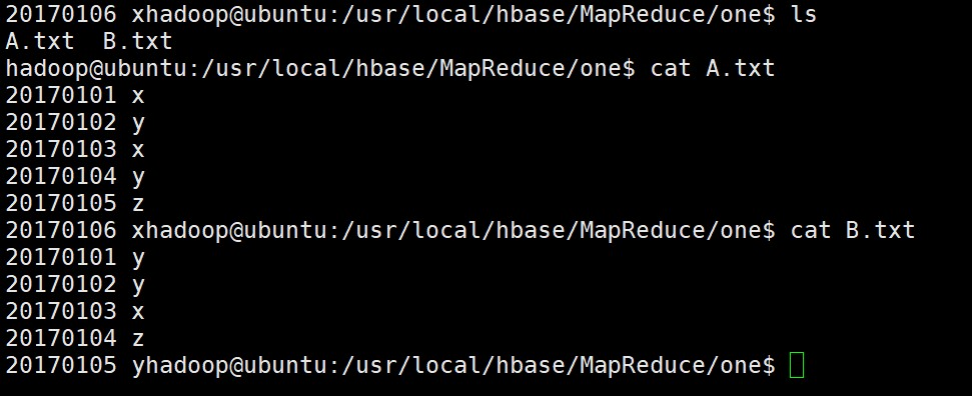
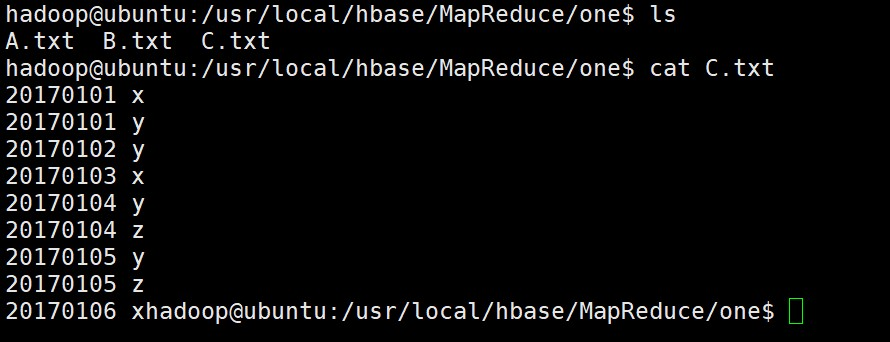
(3)使用以下Shell命令查看原文件A和原文件B中存储的内容数据信息:
lscat A.txtcat B.txt
(4)使用以下Shell命令查看对文件A和文件B两个文件进行合并去重操作后得到一个新的输出文件为C的内容数据信息:
lscat C.txt
3.2 编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整 数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。
(1)在Mapreduce中创建MergeSort类对文件1、文件2和文件3三个文件进行升序排序操作。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MergeSort {
// Map函数,读取输入中的value,并将其作为key,值不重要
public static class Map extends Mapper<Object, Text, IntWritable, Text> {
private IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String text = value.toString();
data.set(Integer.parseInt(text));
context.write(data, new Text(""));
}
}
// Reduce函数,排序并输出每个值的排序位次
public static class Reduce extends Reducer<IntWritable, Text, IntWritable, IntWritable> {
private int line_num = 1; // 记录排序的位次
public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 对于每个key,直接输出排序位次和key值
context.write(new IntWritable(line_num), key);
line_num++; // 排序位次递增
}
}
// 自定义Partition函数
public static class Partition extends Partitioner<IntWritable, Text> {
public int getPartition(IntWritable key, Text value, int numPartitions) {
// 动态分区,不使用硬编码的最大值
int maxValue = Integer.MAX_VALUE;
int bound = maxValue / numPartitions + 1;
int keyNumber = key.get();
for (int i = 0; i < numPartitions; i++) {
if (keyNumber < bound * (i + 1) && keyNumber >= bound * i) {
return i;
}
}
return 0; // 默认分区
}
}
public static void main(String[] args) throws Exception {
// 配置文件
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input", "output"}; // 直接设置输入输出路径
if (otherArgs.length != 2) {
System.err.println("Usage: MergeSort <in> <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "Merge and Sort");
job.setJarByClass(MergeSort.class);
// 设置Mapper和Reducer
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置Partitioner
job.setPartitionerClass(Partition.class);
// 设置输出的key和value类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交Job并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
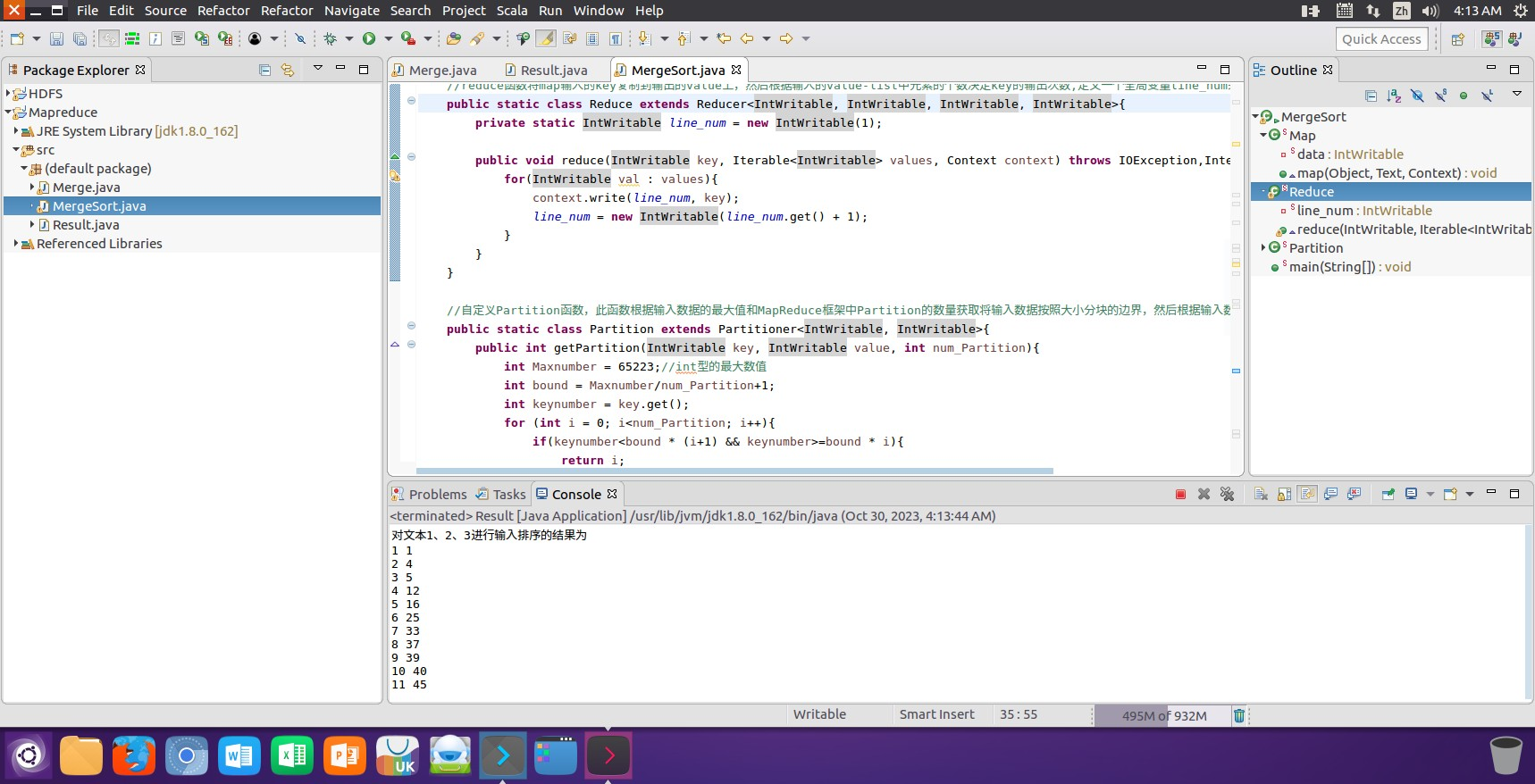
(2)运行创建的MergeSort类后得到一个对文件1、文件2和文件3三个文件进行升序排序后的输出文件4,并将文件的内容在控制台进行输出显示。
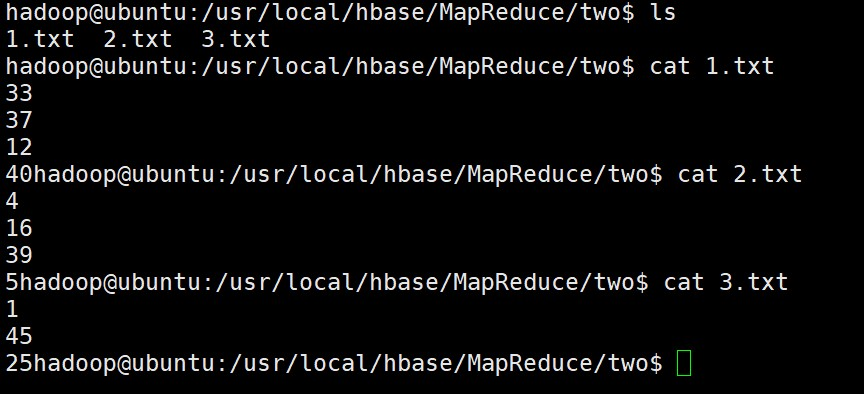
(3)使用以下Shell命令查看原文件1、原文件2和原文件3中存储的内容数据信息。
lscat 1.txtcat 2.txtcat 3.txt
(4)使用以下Shell命令查看对文件1、文件2和文件3三个文件进行升序排序后得到一个新的输出文件为4的内容数据信息。
lscat 4.txt
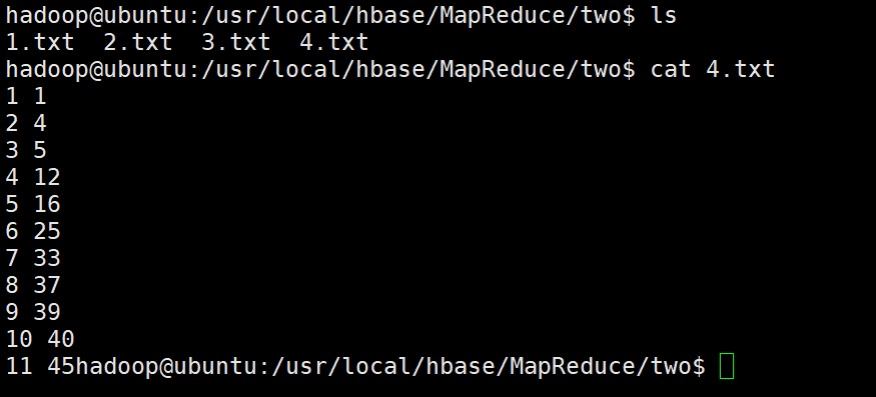
3.3 对给定的表格进行信息挖掘
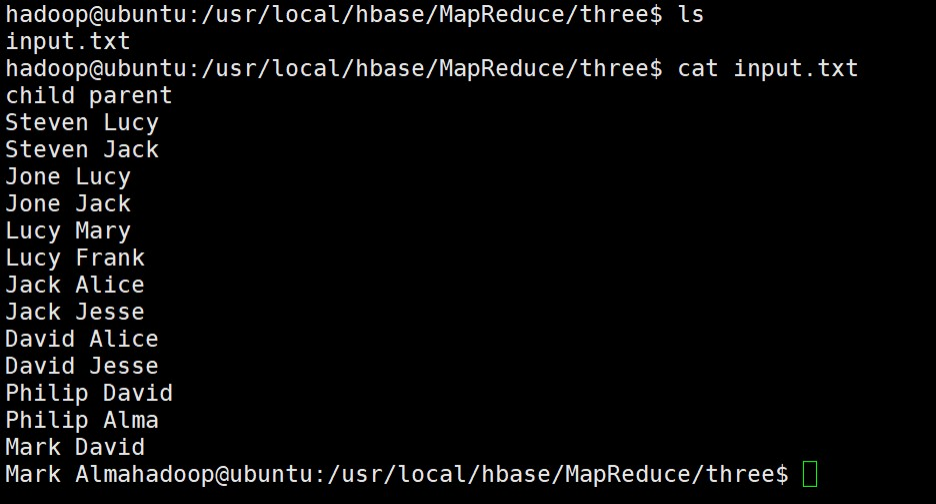
下面给出一个 child-parent 的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
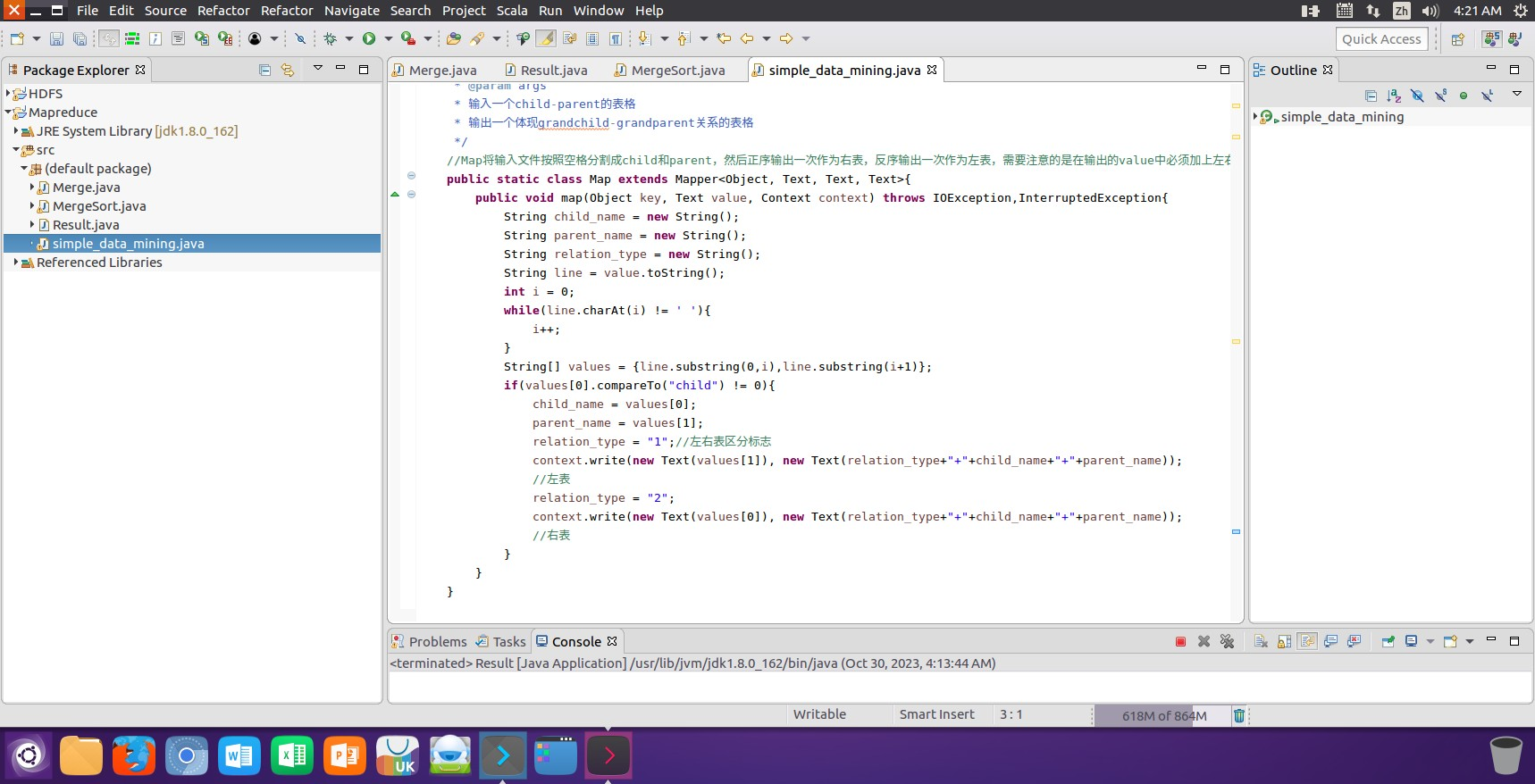
(1)在Mapreduce中创建simple_data_mining类对文件input中的表格进行信息挖掘操作。
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SimpleDataMining {
private static int time = 0;
/**
* 输入一个child-parent的表格,输出一个体现grandchild-grandparent关系的表格
*/
public static class Map extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String child_name = "";
String parent_name = "";
String relation_type = "";
String line = value.toString();
// 分割每行数据
int i = line.indexOf(" ");
if (i == -1) return;
String[] values = {line.substring(0, i), line.substring(i + 1)};
if (!values[0].equals("child")) {
child_name = values[0];
parent_name = values[1];
// 输出左右表记录
relation_type = "1"; // 左表
context.write(new Text(parent_name), new Text(relation_type + "+" + child_name + "+" + parent_name));
relation_type = "2"; // 右表
context.write(new Text(child_name), new Text(relation_type + "+" + child_name + "+" + parent_name));
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
if (time == 0) { // 输出表头
context.write(new Text("grand_child"), new Text("grand_parent"));
time++;
}
// 使用List替代数组,避免数据量过大时数组越界
List<String> grand_child = new ArrayList<>();
List<String> grand_parent = new ArrayList<>();
// 处理Map输出的值
for (Text value : values) {
String record = value.toString();
char relation_type = record.charAt(0);
String[] parts = record.substring(2).split("\\+");
String child_name = parts[0];
String parent_name = parts[1];
// 根据relation_type区分左右表
if (relation_type == '1') {
grand_child.add(child_name); // 左表,记录grandchild
} else {
grand_parent.add(parent_name); // 右表,记录grandparent
}
}
// 输出grandchild-grandparent关系
for (String child : grand_child) {
for (String parent : grand_parent) {
context.write(new Text(child), new Text(parent));
}
}
}
}
public static void main(String[] args) throws Exception {
// 配置文件
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input", "output"}; // 直接设置输入输出路径
if (otherArgs.length != 2) {
System.err.println("Usage: SimpleDataMining <in> <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "Simple Data Mining");
job.setJarByClass(SimpleDataMining.class);
// 设置Mapper和Reducer
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交Job并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
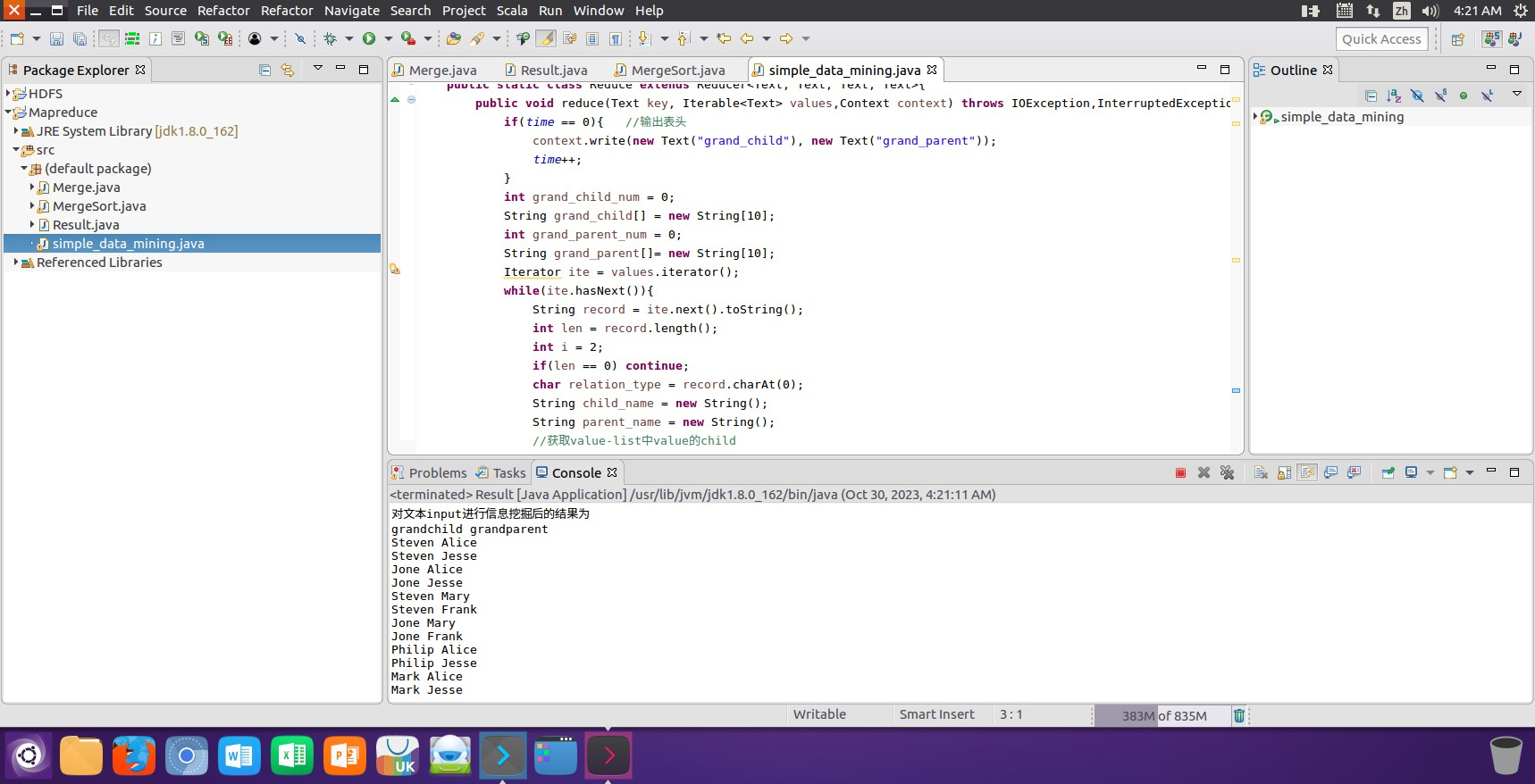
(2)运行创建的simple_data_mining类后得到一个对文件input中的表格进行信息挖掘后的输出文件output,并将文件的内容在控制台进行输出显示。
(3)使用以下Shell命令查看原文件input中存储的内容数据信息。
lscat input.txt
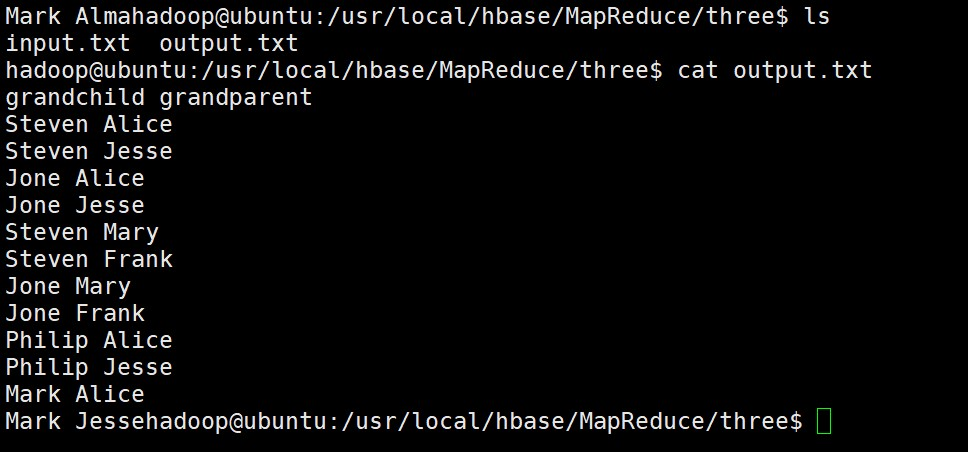
(4)使用以下Shell命令查看对文件input中的表格进行信息挖掘后得到一个新的输出文件为output的内容数据信息。
lscat output.txt
四、问题和解决方法
1. 实验问题:Hadoop无法启动或启动失败。
解决方法:检查Hadoop配置文件中的路径和参数设置,确保正确设置以及文件的可访问性,对配置文件进行修改后对应问题得到解决。
2. 实验问题:Hadoop的任务无法运行或失败。
解决方法:检查任务配置文件中的输入输出路径是否正确,并确保输入数据存在,更改输入输出路径后问题得到解决。
3. 实验问题:执行命令时提示"命令未找到"。
解决方法:确保命令拼写正确,并检查命令是否安装在系统路径中。可以使用which命令来确定命令的路径,并将其添加到系统路径中。
4. 实验问题:没有足够的权限执行某个命令。
解决方法:尝试使用sudo命令以管理员权限运行命令,或者联系系统管理员赋予所需的权限。
5. 实验问题:在连接 HBase 时,出现连接异常。
解决方法:检查 HBase 的配置文件是否正确,并确保 HBase 服务已启动。
6. 实验问题:如何有效地合并两个文件。
解决方法:使用MapReduce的map阶段读取文件A和文件B的内容,并将其发送给reduce阶段。在reduce阶段,可以比较每行的内容,剔除重复的行,并将结果写入输出文件C。
7. 实验问题:如何处理大量数据。
解决方法:使用分片技术将数据分成多个部分,并在多个节点上并行处理。此外,可以使用缓存技术来减少磁盘IO操作。
8. 实验问题:如何处理不同格式的文件。
解决方法:在MapReduce程序中添加一些逻辑来处理不同格式的文件。例如,可以使用正则表达式来解析不同格式的文件,并将其转换为统一格式。
9. 实验问题:如何处理缺失值。
解决方法:在数据预处理阶段处理缺失值,可以使用平均值或中位数填充缺失值,或者将缺失值列删除。
10. 实验问题:如何处理大量整数数据。
解决方法:将整数数据转换为字符串数据进行处理,可以减少内存占用,并提高处理速度。
11. 实验问题:如何处理多个输入文件。
解决方法:在MapReduce程序中添加一个map阶段,用于读取每个输入文件的内容并将其发送给reduce阶段。在reduce阶段,可以合并所有输入文件的内容,并剔除重复的行。
12. 实验问题:如何处理表格中的父子辈关系。
解决方法:在MapReduce程序中添加一个map阶段,用于解析表格中的父子辈关系,并将其转换为祖孙辈关系的格式。然后在reduce阶段,可以汇总每个祖孙辈关系的计数结果。
13. 实验问题:如何处理大规模数据集的排序。
解决方法:使用分布式计算框架如Hadoop或Spark来实现大规模数据的排序,这些框架可以利用集群中的多个节点并行处理数据,从而加快排序速度。
14. 实验问题:如何处理非结构化数据。
解决方法:对于非结构化数据,使用自然语言处理技术进行数据清洗和预处理,提取出有用的信息,并将其转换为结构化数据格式。
15. 实验问题:如何进行实时数据分析。
解决方法:采用实时计算框架如Spark Streaming或Flink来实现实时数据分析,这些框架处理实时生成的数据流,并快速返回分析结果。
16. 实验问题:压缩或解压缩文件。
解决方法:使用tar命令进行文件压缩和解压缩。例如,使用tar -czvf archive.tar.gz directory可以将一个目录压缩为.tar.gz文件。
17. 实验问题:快速访问最近使用的命令。
解决方法:使用命令历史和快捷键。按下上箭头键可以在命令历史中向上导航,并按下回车键执行选中的命令。使用Ctrl + R可以进行反向搜索并执行最近使用的命令。
18. 实验问题:应用程序崩溃或卡死。
解决方法:由于库依赖错误、磁盘空间不足、损坏的配置文件导致的。重装应用程序后问题得到解决。
19. 实验问题:在Eclipse集成开发环境中编写代码时字体太小不利于观察。
解决方法:点击Window->Preferences->在搜索栏中输入font->General-> Appearance->Colorsand Fonts->Basic->Text Font->点击Edit进行字体的设置->点击确认即完成了字体大小的设置。
20. 实验问题:编写Java代码进行中文输出时出现了乱码现象。
解决方法:鼠标右击->Run As->Run Configurations->Common->在Other后填写gbk然后点击Run进行运行后中文可以正常输出。
21. 实验问题:建立类后无法运行,显示没有主程序。
解决方法:填写主类运行信息语句public static void main(String[] args)或者继续在包内新建一个主类,通过类组合的形式进行类的运行。
22. 实验问题:在调用一些类的成员变量的时候显示错误。
解决方法:所调用的类成员变量为私有类型,私有类型只能在类内访问,类外无法对其直接进行访问,在类内构造公有函数形成一个对外接口,在其他类内直接通过调用这个函数来访问其类内部的私有成员即可。
五、心得体会
1、通过这些实验,我深入了解了编程和数据处理方面的知识,掌握了一些实用的技术和工具,同时也遇到了许多挑战和问题。在实现文件合并和去重操作的实验中,我学习了MapReduce编程模型,并使用Java编写了一个简单的MapReduce程序。通过这个程序,我明白了如何处理大规模数据集,如何利用并行计算提高程序的效率,以及如何处理分布式系统中的数据倾斜等问题。这些经验让我更加深刻地认识到编程在数据处理和数据分析中的重要作用。
2、在这个实验中,使用了多个输入文件,每个文件中的每行内容均为一个整数。学习了如何使用归并排序算法对整数数据进行排序,并使用Java编写了一个简单的排序程序。通过这个程序,明白了如何处理大量整数数据,如何优化程序的性能,以及如何处理分布式系统中的数据倾斜等问题。
3、在这个实验中,给出了一个child-parent表格,要求挖掘其中的父子辈关系,并给出祖孙辈关系的表格。使用Java编写了一个简单的程序,用于解析表格中的数据,并提取出父子辈关系。通过这个程序明白了如何处理表格数据,如何提取有用的信息,以及如何将数据转换为不同的格式。
4、在处理大规模数据集时,程序可能会出现数据倾斜的问题,导致某些节点上的计算任务无法完成。为了解决这个问题,学习了数据倾斜的原因和解决方法,并尝试调整程序的参数和算法来优化程序的性能。此外,在处理表格数据时,程序可能会出现格式不一致的问题,导致数据无法正确提取。为了解决这个问题,学习了正则表达式和字符串处理技术,用于解析不同格式的表格数据。
5、通过完成这些实验报告,不仅深入了解了编程和数据处理方面的知识,还掌握了一些实用的技术和工具。同时,也意识到了在编程和数据处理中需要注意的一些问题,如数据的质量和完整性、算法的复杂度和效率等。这些经验和知识将对的未来学习和工作产生积极的影响。
6、通过实践和应用所学知识,不仅提高了自己的编程能力和数据处理能力,还培养了自己的问题解决能力和创新精神。同时,也认识到在未来的学习和工作中,需要不断学习和更新知识,以适应不断变化的市场需求和技术环境,不断提高自己的综合素质和能力水平。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)