NeurIPS 2025 | 大视觉模型做时序预测,总被“周期”带跑偏?这篇论文让它看清趋势了!
本文从理论和实验上证明,通过一个精心设计的分解框架,可以有效结合数值和视觉两种模态的优势,显著提升长时序预测的性能。其提出的DMMV-A模型通过新颖的自适应分解机制,成功克服了现有LVM方法中的周期性偏置问题,在多个基准测试中刷新了记录。这项研究不仅为时序预测任务提供了一个强大的新工具,也为未来如何将不同模态的大模型(如视觉、语言模型)应用于时序分析领域,开辟了富有前景的研究方向。
在气象、能源、金融等众多领域,对未来数据趋势进行长期准确的预测至关重要。传统的预测方法通常只处理数值序列,但我们也可以将这些序列转换成图像或文本,从不同“视角”来观察数据。近期,一些研究开始尝试利用强大的大视觉模型 (Large Vision Models, LVMs) 来处理这些“图像化”的时间序列。然而,这些模型在预测时天然地带有一种归纳偏置,即它们过分关注数据中的周期性规律,而可能忽略了整体的长期变化趋势,导致预测不准。
为了解决这个问题,本文提出了一种名为DMMV的分解式多模态视图增强预测框架。该框架巧妙地将原始时间序列分解为趋势和季节性两个部分,并分别交给为它们“量身定做”的预测器来处理,最后再将两部分的预测结果智能地融合起来。实验证明,这种方法显著提升了预测的准确性,在8个公开数据集中有6个都取得了当前最优的成绩。
另外我整理了NeurIPS 2025时间序列相关论文+源码合集,感兴趣的可以自取,希望能帮到你!
一、论文基本信息

论文标题: Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
作者姓名: ChengAo Shen, Wenchao Yu, Ziming Zhao, Dongjin Song, Wei Cheng, Haifeng Chen, Jingchao Ni
作者单位/机构: University of Houston, NEC Laboratories America, University of Connecticut
论文代码: https://github.com/D2I-Group/dmmv
论文代码: https://arxiv.org/pdf/2505.24003
二、主要贡献与创新
- 首次识别并系统研究了LVM在时序预测中存在的“周期性归纳偏置”问题。
- 提出了DMMV框架,创新性地使用分解思想,将数值和视觉两种模态的优势互补。
- 设计了DMMV-A,通过一种新颖的“回溯-残差”机制,实现对序列的自适应分解。
- 实验证明模型性能卓越,在多个基准上超越14个先进模型,为多模态时序研究提供了新思路。
三、研究方法与原理
该论文提出的模型核心思路是:将时间序列分解为趋势和季节性两个部分,分别交给擅长捕捉全局趋势的数值预测器和精于识别周期性模式的视觉预测器处理,最终融合二者预测结果。
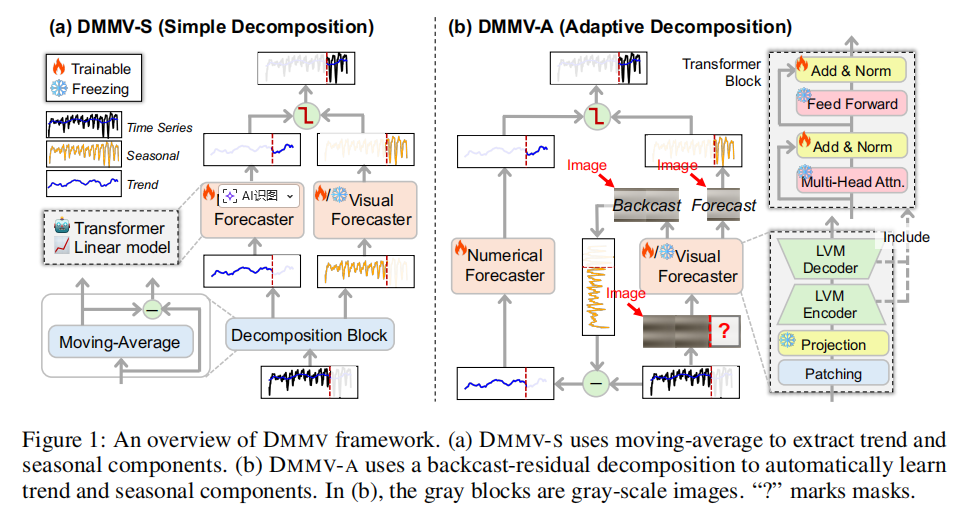
论文提出的DMMV框架包含两种具体的实现方式:一种是基于简单分解的DMMV-S,另一种是基于自适应分解的DMMV-A。
DMMV-S:基于简单分解的实现
DMMV-S采用了一种经典的时间序列分解方法——移动平均(MOV)。对于一个输入的多元时间序列 (multivariate time series, MTS) X X X,它首先采用通道独立 (channel-independence) 的策略,即分别处理每一个维度(或通道)的单变量时间序列 x i x_i xi。
分解过程通过一个滑动窗口来平滑数据,从而提取出低频的趋势部分( x i t r e n d x_i^{trend} xitrend),而原始序列减去趋势部分后,剩下的高频波动则被视为季节性部分( x i s e a s o n x_i^{season} xiseason)。这个过程可以用以下公式表示:
x i t r e n d = Moving-Average ( Padding ( x i ) ) , x i s e a s o n = x i − x i t r e n d x_i^{trend} = \text{Moving-Average}(\text{Padding}(x_i)), \quad x_i^{season} = x_i - x_i^{trend} xitrend=Moving-Average(Padding(xi)),xiseason=xi−xitrend
分解之后,这两个部分被送往不同的“专家”预测器:
- 数值预测器 ( f n u m ( ⋅ ) f_{num}(\cdot) fnum(⋅)):负责处理趋势部分 x i t r e n d x_i^{trend} xitrend。由于趋势通常变化平缓,具有较强的线性特征,论文在这里采用了一个简单的线性模型进行预测。这不仅高效,也符合先前研究证明线性模型在预测趋势上的有效性。
- 视觉预测器 ( f v i s ( ⋅ ) f_{vis}(\cdot) fvis(⋅)):负责处理季节性部分 x i s e a s o n x_i^{season} xiseason。它首先将这个一维的季节性序列,通过一种名为周期性成像的技术转换成二维图像。具体来说,它根据序列的主要周期 P P P 将其切分成多段,然后堆叠成一个矩阵(图像)。接着,这个图像被送入一个预训练好的LVM(论文中主要使用MAE模型)中。LVM凭借其强大的图像模式识别能力,能够精准捕捉季节性序列中的周期性规律,并预测未来的季节性变化。
最后,两个预测器分别得到的趋势预测值 y ^ i t r e n d \hat{y}_i^{trend} y^itrend 和季节性预测值 y ^ i s e a s o n \hat{y}_i^{season} y^iseason,通过一个可学习的门控机制(gating mechanism)进行加权融合,得到最终的预测结果 y ^ i \hat{y}_i y^i。这个门控参数 g g g 会在模型训练中自动学习,以决定在不同数据上应该更相信哪个预测器的结果。
y ^ i = g ∘ y ^ i s e a s o n + ( 1 − g ) ∘ y ^ i t r e n d \hat{y}_i = g \circ \hat{y}_i^{season} + (1-g) \circ \hat{y}_i^{trend} y^i=g∘y^iseason+(1−g)∘y^itrend
然而,DMMV-S的分解方式是固定的,依赖于移动平均的窗口大小,这缺乏灵活性。为了让分解过程更智能、更贴合数据本身的特性,论文进一步提出了DMMV-A。
DMMV-A:基于自适应分解的实现
与DMMV-S的“先分解,后预测”不同,DMMV-A巧妙地利用了视觉预测器本身的特性,来自动学习如何分解序列。它的核心是一种回溯-残差(backcast-residual)机制。
具体步骤如下:
-
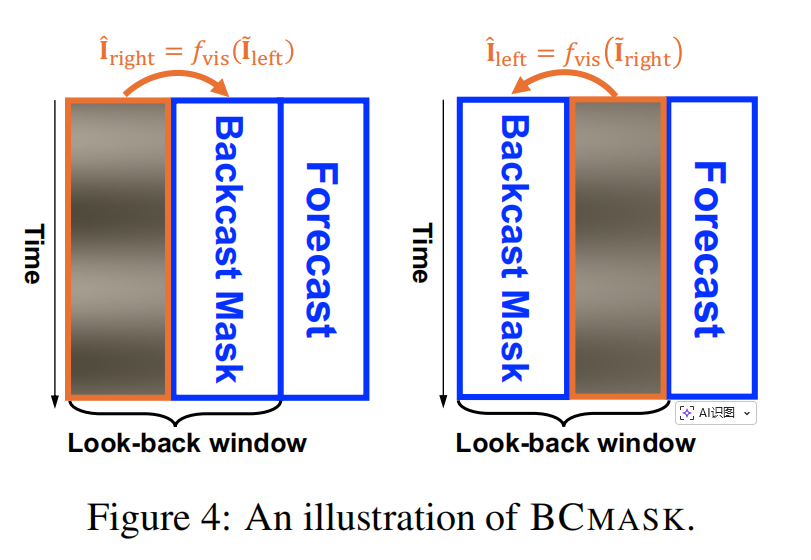
生成回溯序列:DMMV-A不再对输入序列 x i x_i xi 进行预先分解。而是直接将原始的 x i x_i xi 图像化后送入视觉预测器 f v i s ( ⋅ ) f_{vis}(\cdot) fvis(⋅)。但此时,模型的任务不是预测未来,而是“回溯”历史,即重建输入序列自身。为了高效地完成这个任务,论文设计了一种名为BCMASK的掩码策略。
如上图所示,BCMASK分两步完成回溯:首先遮住图像的左半部分,用右半部分来预测(重建)左半部分;然后反过来,遮住右半部分,用左半部分来预测它。通过拼接这两次重建的结果,就得到了一个完整的对输入图像的回溯 I ^ i \hat{I}_i I^i。公式如下:
I ^ i l e f t = f v i s ( I ~ i r i g h t ) , I ^ i r i g h t = f v i s ( I ~ i l e f t ) \hat{I}_i^{left} = f_{vis}(\tilde{I}_i^{right}), \quad \hat{I}_i^{right} = f_{vis}(\tilde{I}_i^{left}) I^ileft=fvis(I~iright),I^iright=fvis(I~ileft)
-
自适应分解:由于视觉预测器 f v i s ( ⋅ ) f_{vis}(\cdot) fvis(⋅) 存在周期性归纳偏置,它重建出的回溯序列 x ^ i \hat{x}_i x^i(由图像 I ^ i \hat{I}_i I^i 逆转换得到)会天然地保留原始序列中最主要的周期性成分,而过滤掉那些非周期的趋势信息。因此, x ^ i \hat{x}_i x^i 可以被看作是模型自动提取出的季节性部分。而原始序列 x i x_i xi 与这个回溯序列的残差 Δ x i = x i − x ^ i \Delta x_i = x_i - \hat{x}_i Δxi=xi−x^i,则恰好代表了被剥离周期性后的趋势部分。
-
分工预测与融合:分解完成后,流程就和DMMV-S类似了。趋势部分 Δ x i \Delta x_i Δxi 被送入数值预测器 f n u m ( ⋅ ) f_{num}(\cdot) fnum(⋅) 得到 y ^ i t r e n d \hat{y}_i^{trend} y^itrend。而视觉预测器 f v i s ( ⋅ ) f_{vis}(\cdot) fvis(⋅) 则在送入原始图像化序列 I ~ i \tilde{I}_i I~i 的同时,直接进行未来预测,得到季节性预测 y ^ i s e a s o n \hat{y}_i^{season} y^iseason。最后同样通过门控机制融合,得到最终结果。
y ^ i = g ∘ y ^ i s e a s o n + ( 1 − g ) ∘ y ^ i t r e n d , 其中 y ^ i t r e n d = f n u m ( Δ x i ) \hat{y}_i = g \circ \hat{y}_i^{season} + (1-g) \circ \hat{y}_i^{trend}, \quad \text{其中 } \hat{y}_i^{trend} = f_{num}(\Delta x_i) y^i=g∘y^iseason+(1−g)∘y^itrend,其中 y^itrend=fnum(Δxi)
这种自适应分解方法完全由数据和模型驱动,能够为不同的时间序列找到最适合其自身特点的分解方式,从而更充分地发挥数值和视觉两个预测器的长处。
四、实验设计与结果分析
论文在一系列广泛使用的长时序预测基准数据集上进行了详尽的实验,包括ETT(电力变压器温度)、Weather、Illness、Traffic和Electricity。评估指标主要采用均方误差 (Mean Squared Error, MSE) 和平均绝对误差 (Mean Absolute Error, MAE),这两个指标都是越低越好。
对比实验
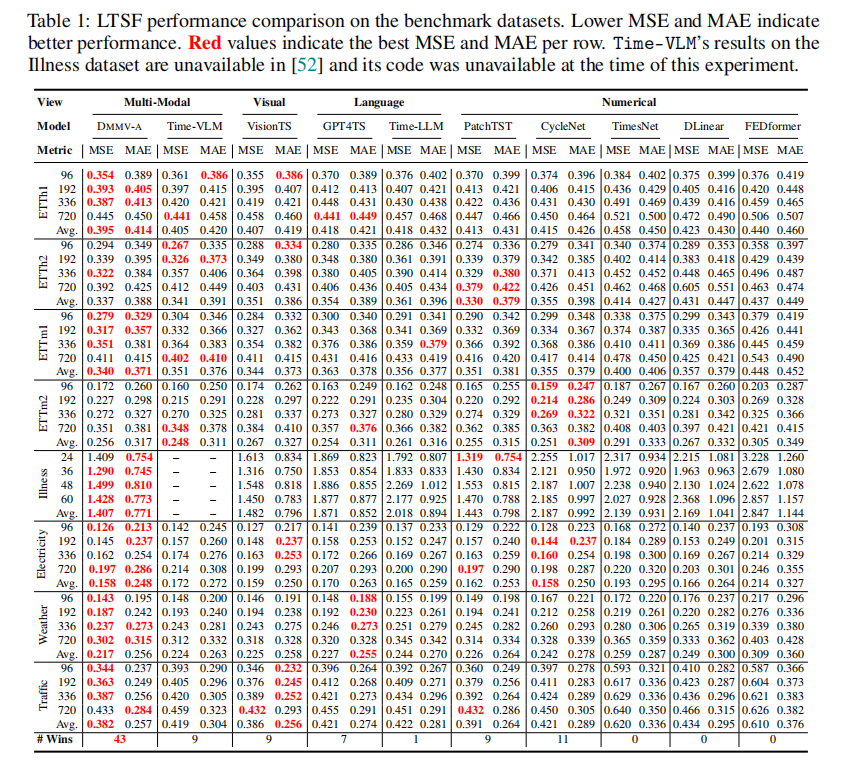
在和14个当前最先进(SOTA)模型的对比中,DMMV-A展现了强大的竞争力。表1列出了部分代表性模型的对比结果。可以清晰地看到:
- DMMV-A性能全面领先:在8个数据集中,DMMV-A在大部分预测长度上都取得了最低的MSE和MAE,总共获得了43项第一,远超其他模型。这证明了其框架的有效性和泛化能力。
- 优于其他多模态方法:与同样使用多模态信息的Time-VLM相比,DMMV-A的性能更优越,尤其是在ETTm2等数据集上。这说明DMMV精心设计的分解与融合策略,比简单的信息拼接更有效。
- 优于纯视觉方法:与纯视觉模型VisionTS相比,DMMV-A在多个数据集上都取得了更好的效果。例如,在周期性不那么强的ETTh2和Electricity数据集上,VisionTS表现不佳,而DMMV-A通过数值预测器对趋势的有效建模,弥补了这一短板,表现更为稳健。
- 优于数值方法:与PatchTST、DLinear等强大的纯数值方法相比,DMMV-A通过引入视觉视角,更好地捕捉了复杂的周期性模式,从而在ETTh1、Traffic等周期性强的任务上优势明显。

图5的CD图中,模型的平均排名越靠左越好。可以看到,DMMV-A在MSE和MAE两项指标上都稳居第一梯队,综合排名第一,进一步印证了其卓越的性能。
可视化对比
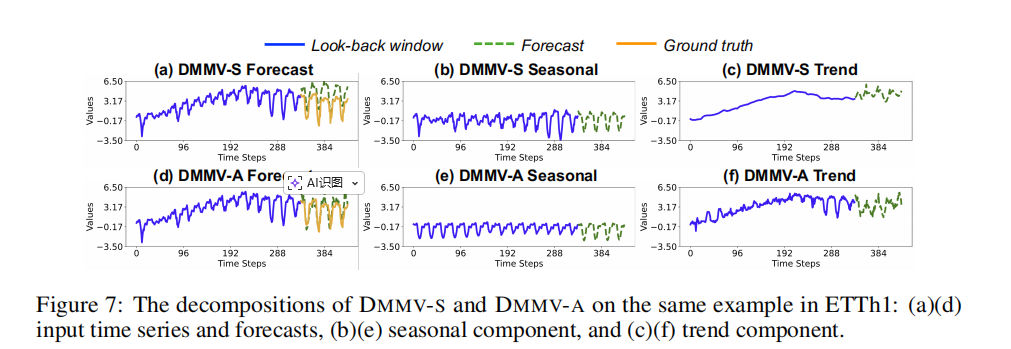
为了更直观地理解DMMV-S和DMMV-A的差异,论文对它们的分解结果进行了可视化。从图7中可以看出,对于同一个输入序列,DMMV-A(下图)分解出的季节性成分(e)非常平滑且周期性清晰,其趋势成分(f)则包含了主要的长期走向。相比之下,DMMV-S(上图)的分解结果则不够“干净”,季节性成分(b)中混杂了许多噪声,这无疑增加了视觉预测器的学习难度。这直观地解释了为何DMMV-A的自适应分解更为优越。
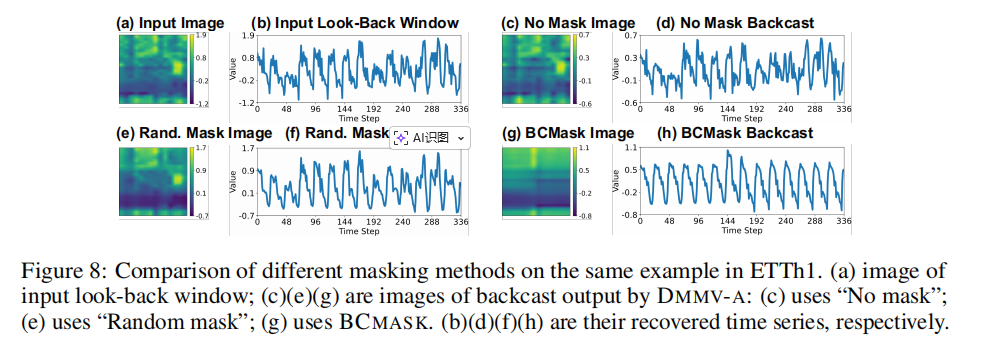
图8展示了DMMV-A中不同掩码策略对回溯(即分解出的季节性成分)效果的影响。可以看到,(d) “无掩码”策略产生的回溯几乎就是输入的复制,无法实现分解。 (f) “随机掩码”产生的结果有较多毛刺,不够平滑。而 (h) BCMASK 策略得到的回溯序列则非常平滑,清晰地提取了周期模式,证明了这一策略的有效性。
消融实验
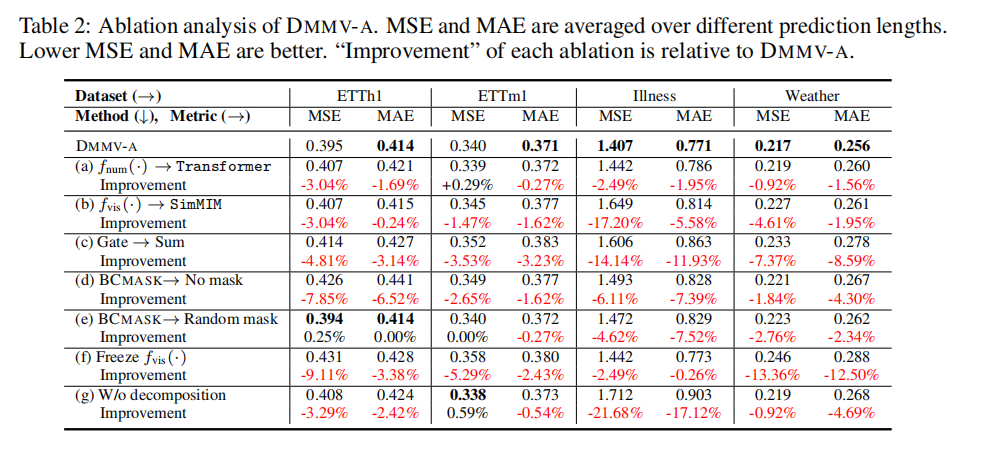
消融实验的目的是验证模型中每个组件的必要性。表2展示了对DMMV-A进行的“控制变量”实验:
- (a) 和 (b):将数值预测器换成更复杂的变换器 (Transformer) 或者将视觉预测器MAE换成SimMIM,性能都有所下降,说明当前线性模型+MAE的组合是高效且适配的。
- © Gate → Sum:将门控融合换成简单的相加,性能显著下降,证明了自适应加权融合的重要性。
- (d) 和 (e) :分别用“无掩码”和“随机掩码”替代BCMASK,性能都变差了,再次凸显了BCMASK策略在实现有效分解中的关键作用。
- (g) W/o decomposition:这是最重要的消融项。如果去掉整个回溯-残差分解机制,让两个预测器都处理原始输入,性能会大幅度滑坡。这强有力地证明了**“分解-分治”的核心思想是DMMV成功的基石**。
五、论文结论与评价
总结
本文从理论和实验上证明,通过一个精心设计的分解框架,可以有效结合数值和视觉两种模态的优势,显著提升长时序预测的性能。其提出的DMMV-A模型通过新颖的自适应分解机制,成功克服了现有LVM方法中的周期性偏置问题,在多个基准测试中刷新了记录。这项研究不仅为时序预测任务提供了一个强大的新工具,也为未来如何将不同模态的大模型(如视觉、语言模型)应用于时序分析领域,开辟了富有前景的研究方向。
优点
- 问题洞察深刻:论文准确地指出了当前LVM用于时序预测时存在的“周期性归纳偏置”这一核心痛点,并针对性地提出了解决方案,具有很强的创新性。
- 方法设计巧妙:DMMV-A的自适应分解机制非常精巧,它没有引入额外的复杂模块,而是“借力打力”,利用LVM自身的特性来完成分解任务,体现了优雅的设计思想。
- 实验验证扎实:论文进行了全面且详尽的对比实验和消融研究,不仅证明了模型的优越性,也清晰地揭示了每一个设计组件的价值,论证过程严谨、有说服力。
缺点
- 计算成本较高:DMMV-A在训练和推理时,需要调用视觉模型三次(两次用于回溯,一次用于预测),这相比于只调用一次的模型,计算开销显著增加,可能不适用于对实时性要求极高的场景。
- 对周期的先验知识仍有依赖:尽管模型能够自适应分解,但在最初将时间序列图像化的步骤中,仍然需要一个预设的周期长度 P P P。从论文的附录分析可知,模型对这个超参数的选择仍有一定敏感性。
- 图像转换的潜在信息损失:将一维时间序列转换为二维图像并进行上采样以匹配LVM输入尺寸的过程,可能会引入一些本不存在的伪影或平滑掉一些微小的细节,从而造成原始时序信息的失真。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)