AI学习笔记整理(17)—— AI核心技术(深度学习1)
偏导数是指在多元函数中,对其中一个变量求导,而将其余变量视为常数的导数。在神经网络中,偏导数用于量化损失函数相对于模型参数(如权重和偏置)的变化率。
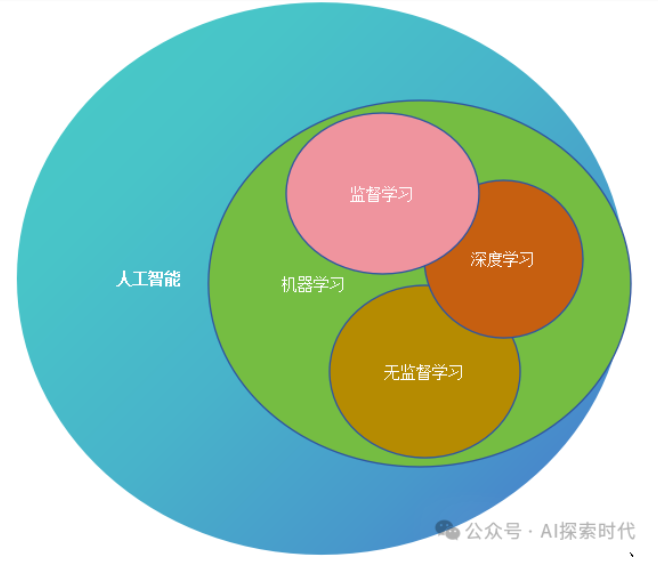
深度学习算法分类
深度学习算法主要包括神经网络类算法、生成式算法、强化学习算法及其他重要算法。
神经网络类算法
-
前馈神经网络(FFNN):基础结构,信息单向流动,适用于简单任务如手写数字识别 。
-
卷积神经网络(CNN):专为网格数据设计,通过卷积核和池化操作处理图像、音频等数据,广泛应用于图像分类、目标检测 。
-
循环神经网络(RNN):处理序列数据,但存在梯度消失问题,变体如LSTM和GRU改进了长期依赖处理能力 。
生成式算法
-
生成对抗网络(GAN):由生成器和判别器组成,用于生成逼真数据 。
-
变分自编码器(VAE):通过概率建模生成数据,常用于数据增强 。
强化学习算法
-
深度强化学习(DRL):结合强化学习与深度学习,应用于自动驾驶、游戏AI等场景 。
其他重要算法
-
注意力机制:提升模型对关键信息的聚焦能力,广泛应用于自然语言处理 。
-
自编码器(AE):用于特征学习和去噪 。
深度学习与监督学习
深度学习也属于机器学习,是机器学习的一个分支,只不过其是通过模仿人类神经元构造的神经网络模型,因为神经网络模型可以具有多层神经网络,因此又叫深度学习。而监督学习是机器学习的一种主要方法。
举例来说,监督学习相当于有老师教,老师会告诉你怎么学,什么是对的,什么是错的。而无监督学习相当于自学,没人告诉你应该怎么学,学成什么样。而深度学习就相当于是看书学习,还是看视频学习,还是讨论学习。因此,深度学习即可以是监督学习,也可以是无监督学习;同样,监督学习和无监督学习即可以是深度学习,也可以不是深度学习。
深度学习,如果把监督学习和神经网络结合就可以训练出一个具有明确目标的神经网络模型;而如果把无监督学习和神经网络结合,那么就会训练出一个处理未知数据能力的模型。
深度学习与监督学习两者的核心区别在于数据利用方式和模型复杂度。
数据利用方式
-
监督学习:依赖带标签的数据(输入特征+输出标签),通过学习特征与标签的映射关系进行预测。例如,线性回归、逻辑回归等算法均需明确标注的训练数据 。
-
深度学习:可使用带标签或无标签数据。在监督学习中,深度学习(如卷积神经网络CNN)仍需标签数据;在无监督学习中,深度学习可自动学习数据特征(如自编码器) 。
模型复杂度
-
监督学习:通常使用简单模型(如决策树、支持向量机),参数较少,适合小规模数据 。
-
深度学习:基于多层神经网络,参数量巨大,能自动提取复杂特征(如图像边缘→纹理→物体),适合大规模数据 。
应用场景
-
监督学习:直接用于分类(垃圾邮件检测)、回归(房价预测)等任务 。
-
深度学习:在图像识别、自然语言处理等复杂任务中表现更优,例如ResNet在CIFAR-10数据集上的分类准确率远超传统监督学习模型 。
神经网络基础
参考链接:https://blog.csdn.net/si_ying/article/details/138463143
神经网络也称为人工神经网络(ANN)或模拟神经网络(SNN),是机器学习的子集,也是深度学习的算法支柱;被称为“神经”, 是因为它模仿大脑中神经元相互发出信号;很多科学发明都是从大自然中获得了想法,比如飞机的发明是受鸟类的启发,神经网络是一种受人脑启发的机器学习算法,它是一个由互连节点或人工神经元组成的网络,可以学习识别数据中的模式。
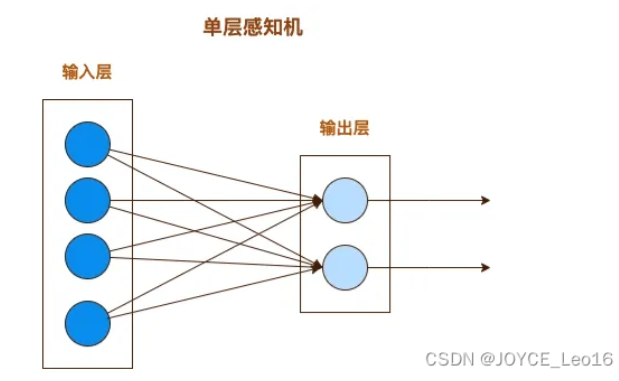
感知机、单层神经网络
感知机是一种使神经元从给定信息中学习算法,它有两种类型,单层感知机不包含隐藏层;而多层感知机包含一个或多个隐藏层;单层感知机是人工神经网络(ANN)最简单的形式。解决简单的问题;单层神经网络是只有一层神经元的神经网络,这种类型的网络也称为感知机;
多层神经网络、多层感知机
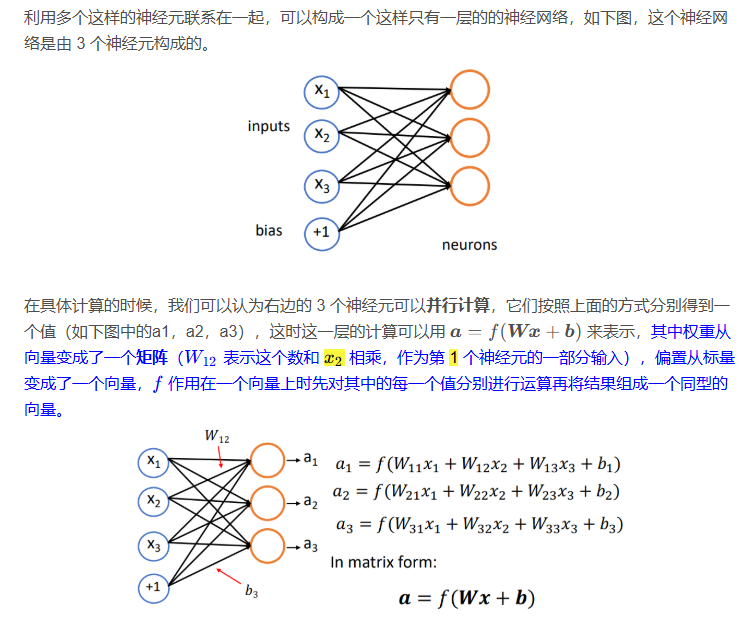
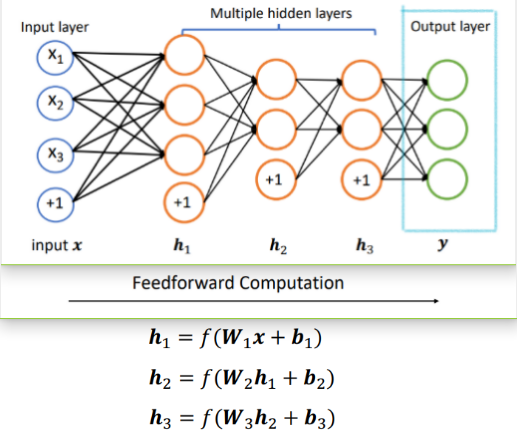
在单层神经网络之后,还可以继续叠加类似的层,变成一个多层的神经网络,其中每层都有若干个神经元。计算的时候从最左边的输入开始,依次计算每一层的结果,其中每一层的输出结果会作为下一层的输入,这就是前向计算。
通常把在输入之上添加的多层网络称之为隐层(hidden layers),然后输入部分称之为输入层(input layer)。隐层的输出通常使用h 来表示,如下图中的h1,h2,h3,为了得到输出结果,我们需要在神经网络最右边再加网络的最后一层,即输出层(output layer)。
非线性激活函数(activation functions)
非线性激活函数是神经网络中用于引入非线性特性的关键组件,使模型能够学习和表示复杂的非线性关系。以下是核心要点:
基本作用
-
解决线性局限性:若神经网络中仅使用线性激活函数,无论层数多少,整体仍为线性模型,无法处理非线性问题 。
-
增强表达能力:通过非线性变换,神经网络可拟合更复杂的函数,例如图像识别、自然语言处理等任务 。
常见类型
-
ReLU(修正线性单元):
定义:x > 0时输出x,x ≤ 0时输出0 。 -
优点:计算简单、缓解梯度消失,适合大规模应用 。
-
缺点:可能“杀死”神经元(输出恒为0) 。
-
-
Sigmoid:
-
定义:输出范围(0,1),常用于二分类 。
-
缺点:梯度消失问题严重(饱和区导数趋近于0) 。
-
-
Tanh:
-
定义:输出范围(-1,1),比Sigmoid对称 。
-
缺点:同样存在梯度消失问题 。
-
-
Leaky ReLU:
-
改进版ReLU,在x < 0时输出小斜率(如0.01x),避免神经元“死亡” 。
-
-
ELU、SELU、Swish、GELU:
-
变体:针对ReLU的不足(如饱和性、非单调性)进行优化,部分支持自归一化或非单调特性 。
-
选择依据
-
任务需求:如二分类常用Sigmoid,多层网络常用ReLU 。
-
训练稳定性:需权衡饱和性、可微性等特性 。
典型应用场景
-
图像处理:ReLU因计算效率高被广泛采用 。
-
语言模型:GELU因非单调特性在Transformer中应用 。
反向传播
参考链接:https://cloud.tencent.com/developer/article/2398347
前向传播(Forward Propagation)
前向传播是神经网络通过层级结构和参数,将输入数据逐步转换为预测结果的过程,实现输入与输出之间的复杂映射。
- 输入层:
输入层接收训练集中的样本数据。
每个样本数据包含多个特征,这些特征被传递给输入层的神经元。
通常,还会添加一个偏置单元来辅助计算。
- 隐藏层:
隐藏层的每个神经元接收来自输入层神经元的信号。
这些信号与对应的权重相乘后求和,并加上偏置。
然后,通过激活函数(如sigmoid)处理这个求和结果,得到隐藏层的输出。
- 输出层:
输出层从隐藏层接收信号,并进行类似的加权求和与偏置操作。
根据问题的类型,输出层可以直接输出这些值(回归问题),或者通过激活函数(如softmax)转换为概率分布(分类问题)。
反向传播(Back Propagation)
反向传播算法利用链式法则,通过从输出层向输入层逐层计算误差梯度,高效求解神经网络参数的偏导数,以实现网络参数的优化和损失函数的最小化。
- 利用链式法则:
反向传播算法基于微积分中的链式法则,通过逐层计算梯度来求解神经网络中参数的偏导数。
- 从输出层向输入层传播:
算法从输出层开始,根据损失函数计算输出层的误差,然后将误差信息反向传播到隐藏层,逐层计算每个神经元的误差梯度。
- 计算权重和偏置的梯度:
利用计算得到的误差梯度,可以进一步计算每个权重和偏置参数对于损失函数的梯度。
- 参数更新:
根据计算得到的梯度信息,使用梯度下降或其他优化算法来更新网络中的权重和偏置参数,以最小化损失函数。
链式法则(Chain Rule)
链式法则是微积分中的一个基本定理,用于计算复合函数的导数。如果一个函数是由多个函数复合而成,那么该复合函数的导数可以通过各个简单函数导数的乘积来计算。
- 简化梯度计算:
在神经网络中,损失函数通常是一个复合函数,由多个层的输出和激活函数组合而成。链式法则允许我们将这个复杂的复合函数的梯度计算分解为一系列简单的局部梯度计算,从而简化了梯度计算的过程。
- 高效梯度计算:
通过链式法则,我们可以从输出层开始,逐层向前计算每个参数的梯度,这种逐层计算的方式避免了重复计算,提高了梯度计算的效率。
- 支持多层网络结构:
链式法则不仅适用于简单的两层神经网络,还可以扩展到具有任意多层结构的深度神经网络。这使得我们能够训练和优化更加复杂的模型。
偏导数
偏导数是多元函数中对单一变量求导的结果,它在神经网络反向传播中用于量化损失函数随参数变化的敏感度,从而指导参数优化。
- 偏导数的定义:
偏导数是指在多元函数中,对其中一个变量求导,而将其余变量视为常数的导数。
在神经网络中,偏导数用于量化损失函数相对于模型参数(如权重和偏置)的变化率。
- 反向传播的目标:
反向传播的目标是计算损失函数相对于每个参数的偏导数,以便使用优化算法(如梯度下降)来更新参数。
这些偏导数构成了梯度,指导了参数更新的方向和幅度。
- 计算过程:
输出层偏导数:首先计算损失函数相对于输出层神经元输出的偏导数。这通常直接依赖于所选的损失函数。
隐藏层偏导数:使用链式法则,将输出层的偏导数向后传播到隐藏层。对于隐藏层中的每个神经元,计算其输出相对于下一层神经元输入的偏导数,并与下一层传回的偏导数相乘,累积得到该神经元对损失函数的总偏导数。
参数偏导数:在计算了输出层和隐藏层的偏导数之后,我们需要进一步计算损失函数相对于网络参数的偏导数,即权重和偏置的偏导数。
梯度下降法
为了达到训练目标,希望将损失函数最小化。那如何最小化损失函数呢?在神经网络中通常使用梯度下降法。
首先,我们需要求出损失函数关于每个模型参数的梯度 。从数学定义来讲,这个梯度代表:对参数进行单位大小改动时,损失函数增长最快的方向 。由于我们期望损失函数不断降低,所以要沿着梯度的反方向调整参数——通过让模型参数产生微小变化,实现损失函数值的逐步下降。
这个过程类似下山:梯度方向是最陡峭的 “上坡路”(对应损失增大最快),我们选其反方向,就像挑最陡的下坡路迈一步,能更快朝着 “山脚”(损失最小化)靠近 。
梯度下降法是一种通过迭代寻找函数最小值的优化算法,核心原理如下:
通过计算函数在当前点的梯度(导数),沿负梯度方向更新参数,逐步减小函数值。梯度下降法基于梯度(函数在某点变化最快的方向)的反方向进行迭代。具体步骤为:
- 计算当前点的梯度(导数或偏导数);
- 沿梯度反方向移动(步长由学习率α控制);
- 重复上述过程直至收敛到局部最小值。
关键公式
参数更新公式: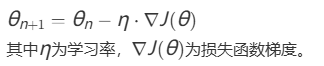
关键要素
- 学习率:步长过小收敛慢,过大可能震荡
- 梯度方向:函数值变化最快的方向
- 凸函数:保证存在全局最小值
变体
- 批量梯度下降(BGD):用全部数据计算梯度
- 随机梯度下降(SGD):每次用单个数据点
- 小批量梯度下降(MBGD):折中方案

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)