【Stable Diffusion】ComfyUI 自定义工作流:从零搭建文生图流程
## 【Stable Diffusion】ComfyUI 自定义工作流:从零搭建文生图流程厌倦了千篇一律的AI绘画流程?想要更自由地掌控图像生成?本教程将带你从零开始,使用ComfyUI搭建专属文生图工作流,释放你的创意,玩转Stable Diffusion!
前言:
厌倦了千篇一律的AI绘画流程?想要更自由地掌控图像生成?本教程将带你从零开始,使用ComfyUI搭建专属文生图工作流,释放你的创意,玩转Stable Diffusion!
开始基础工作流拆解之前,先介绍下SD基础的转化流程
【输入】—(转换)—【潜在空间】—(转换)—【输出】
无论是文生图还是图生图,提示词/图片作为输入基础信息传递给AI,AI并不认识这些,这里需要转化成计算机认识的内容到潜在空间中
所有的运算和生成过程也都是在潜在空间,当完成图片后,需要再从潜在空间次转化出来,转化成我们看得懂的像素图像
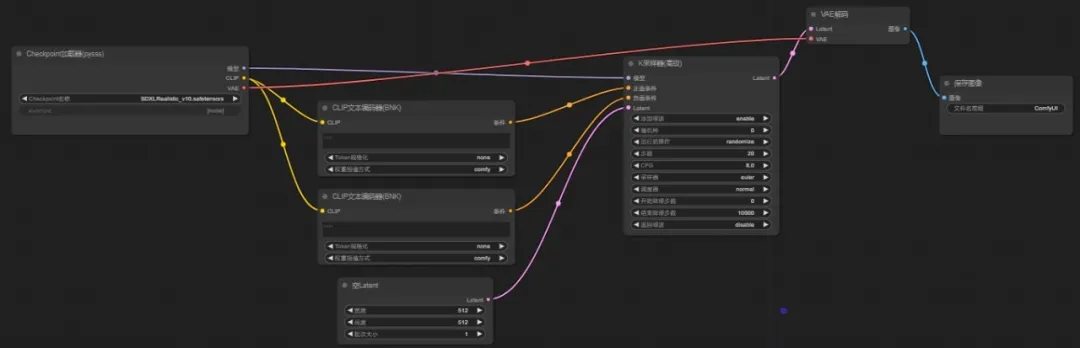
从零搭建文生图
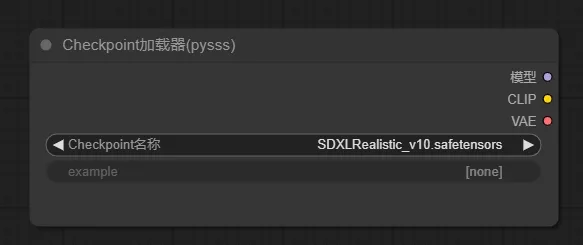
1、加载器
首先添加大模型的加载器,通过加载器这一个节点来延伸出整个工作流的节点
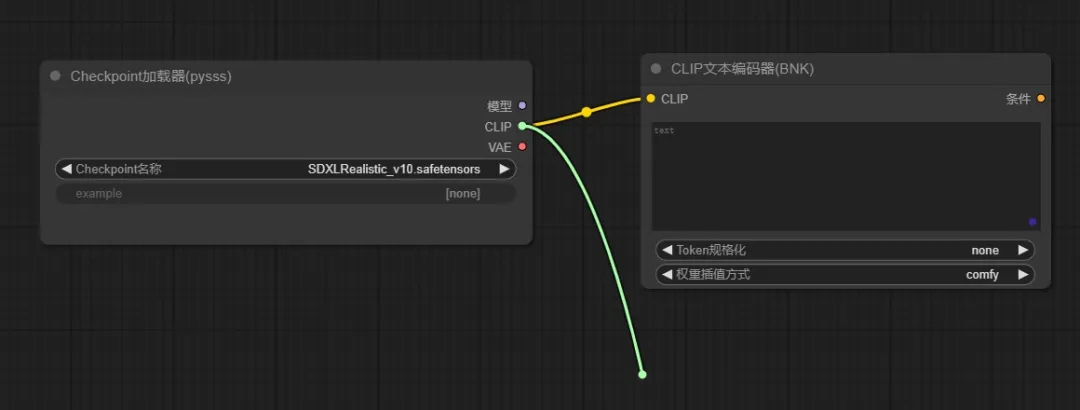
2、正反向提示词节点
可以看到这里有三个延伸点,首先是CLIP文本编码器,将节点延伸就可以看到常用的基本节点,也可以【搜索】插件节点,延伸出的CLIP节点会自动连上(再连接一个负向提示词文本编码器)
这里对应的是文本部分的【输入】—(转换)—【潜在空间】
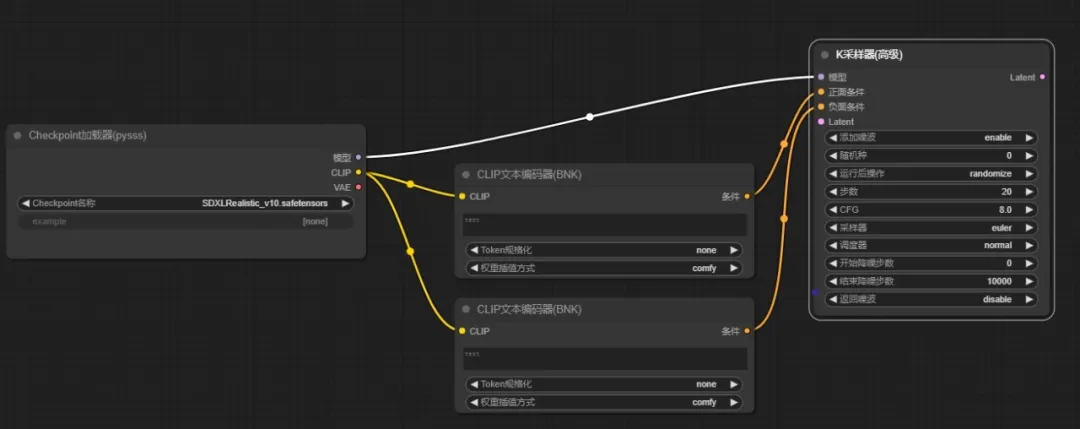
3、模型
同样的,从模型节点拖出一个K采样器,可以看到,K采样器上正负提示词与CLIP文本节点上的颜色是相同的,将相对应的节点相连即可
模型的【输入】—(转换)—【潜在空间】
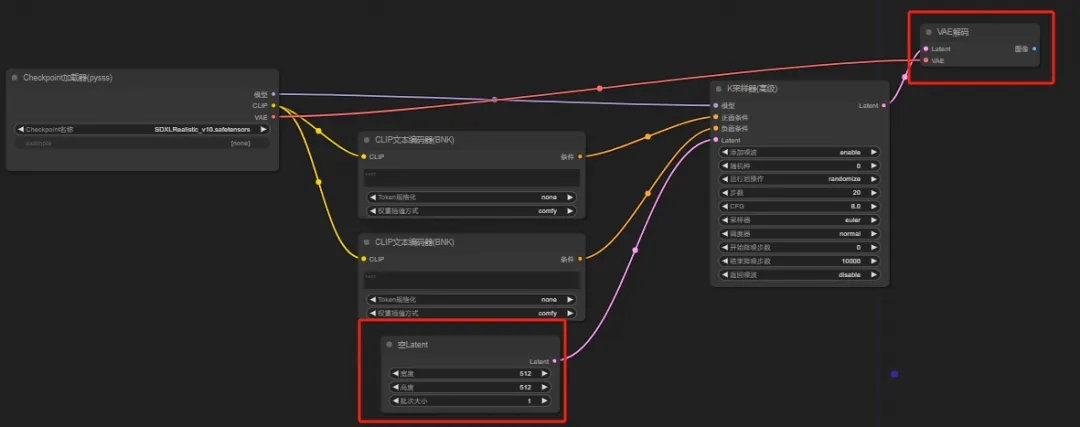
4、Latent
可以看到,这时采样器左边缺少一个Latent节点,延伸出来是个空Latent,这个空Latent就是分辨率的输入
(分辨率的【输入】—(转换)—【潜在空间】)
右边的Laten延伸出来,就是VAE的解码,就是从潜在空间的内容通过VAE的解码转化成像素
(这里不要忘记VAE和大模型的VAE相连,或者单独连接一个VAE加载器,VAE解码没有对应大模型是无法完成的)
【潜在空间】—(转换)—【输出】
5、保存图像
从VAE延伸出保存图像节点,这样文生图的基本工作流就搭建完成了
正因为每个节点所连接的节点不是唯一的,这使得ComfyUI的自由度比WebUI高得多,在理解
【输入】—(转换)—【潜在空间】—(转换)—【输出】
这个基本逻辑下,知道每个节点可以链接什么,对发散自定义工作流就非常有帮助了
资源分享
为了帮助大家更好地掌握
ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

这里直接将该软件分享出来给大家吧~
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 14
14 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)