NVLink与NVLink-C2C——从系统级互联到芯片级革命
摘要:NVLink技术从系统级高速互联演进至芯片级集成,NVLink-C2C实现了革命性突破。传统NVLink通过专用布线或PCIe物理层连接GPU,解决多GPU系统通信瓶颈;而NVLink-C2C采用先进封装技术,在毫米级距离实现芯片间超高带宽(900GB/s)和内存一致性,形成统一地址空间。这项技术支撑了GraceHopper超级芯片等产品,使CPU/GPU深度融合,为AI大模型训练提供超大内
在计算领域,尤其是在人工智能和高性能计算的狂飙突进中,一个永恒的命题是:如何让计算单元之间更快、更高效地“对话”?数据洪流之下,通信瓶颈往往比计算本身更能决定系统的最终性能。英伟达深谙此道,其NVLink技术便是为解决这一问题而生的利器。而NVLink-C2C,则是这项技术演进道路上的一次革命性飞跃,它从根本上重新定义了“芯片”的形态与边界。
本文将深入剖析NVLink与NVLink-C2C的区别与关联,揭示其技术本质、演进逻辑与战略野心。
一、 NVLink:为打破瓶颈而生的高速互联架构
在NVLink出现之前,GPU之间以及GPU与CPU之间的通信主要依赖于PCIe总线。随着GPU计算能力的爆炸式增长,PCIe的带宽和延迟逐渐成为整个系统的“阿喀琉斯之踵”。
1 核心概念与初衷
NVLink是一种高速点对点互连协议与架构。其最初的设计目标非常明确:替代或补充PCIe,为多GPU系统提供远超PCIe的互联带宽和更低的通信延迟。
您可以将其想象为:在一条多车道的城市主干道(PCIe)之外,为特定的重要车辆(GPU)修建了专用的双向高速跑道(NVLink)。这些跑道直接连接关键节点,让数据能够直达,避免红绿灯和拥堵。
2 传统NVLink的演进与形态
-
形态一:板载GPU间互联(SXM架构)
这是NVLink最经典的应用形态,主要用于英伟达的DGX/HGX等AI服务器。通过服务器主板上的高密度布线,直接将多个GPU连接起来。-
NVSwitch的引入:当GPU数量超过4个时,简单的点对点或环状连接会带来瓶颈。于是,英伟达推出了NVSwitch——一个基于NVLink协议的交换芯片。它像一个超级交通枢纽,允许所有接入的GPU实现全互联,即任意两个GPU之间都能以最高速直接通信,构成一个无阻塞的网络。
-
典型产品:NVIDIA DGX A100(基于Ampere架构)、DGX H100(基于Hopper架构)。在DGX H100中,8个H100 GPU通过多个NVSwitch芯片互联,GPU间带宽高达900 GB/s。
-
-
形态二:基于PCIe物理层的NVLink
为了在更通用的x86服务器平台上提供增强的互联能力,英伟达开发了一种独特的模式:NVLink over PCIe。-
工作原理:它利用了PCIe的物理通道(电线),但传输的不是标准的PCIe协议,而是NVLink协议。这好比在普通的铁路轨道上,运行特制的高速磁悬浮列车。
-
价值与局限:
-
价值:在为SXM架构设计的服务器之外,为PCIe插槽形态的GPU提供了优于纯PCIe的互联性能,是一种灵活性折衷方案。
-
局限:其性能和拓扑灵活性均低于原生的SXM+NVSwitch方案。带宽和延迟介于PCIe和原生NVLink之间,且通常无法实现所有GPU间的全互联,可能存在通信瓶颈。
-
-
下面的表格总结了传统NVLink两种形态的特点:
| 特性维度 | 传统NVLink (SXM + NVSwitch) | NVLink over PCIe |
|---|---|---|
| 物理介质 | 专用PCB板载布线 | PCIe物理通道(铜缆) |
| 连接对象 | GPU <-> GPU (通过NVSwitch) | GPU <-> GPU (点对点) |
| 拓扑结构 | 全互联(通过NVSwitch) | 受限的点对点(如仅相邻GPU相连) |
| 带宽 | 极高(如H100达900 GB/s) | 较高,但低于原生NVLink |
| 延迟 | 极低 | 较低,但高于原生NVLink |
| 系统依赖 | 专用服务器(如DGX/HGX) | 标准x86服务器(需兼容的CPU和主板) |
| 典型场景 | 极致性能的AI/HPC集群 | 通用服务器中的AI加速 |
二、 NVLink-C2C:芯片级集成的革命性突破
如果说传统NVLink是在“系统级”修路,那么NVLink-C2C则是在“芯片级”进行“纳米级雕刻”。它是英伟达构建其“超级芯片”愿景的基石技术。
1 核心概念与诞生背景
NVLink-C2C 中的“C2C”即“Chip-to-Chip”。它特指一种基于NVLink协议的、用于芯片到芯片 极近距离高速互连的物理封装和连接技术。
其诞生源于两个关键驱动力:
-
超越系统级限制:即使是最快的板级布线,其信号传输距离、功耗和延迟也已接近物理极限。要实现下一次飞跃,必须将互连距离从“厘米级”缩短到“毫米级”甚至更短。
-
拥抱CPU,实现真正融合:随着英伟达自研Arm架构Grace CPU的出现,他们需要一种能将自家CPU和GPU“无缝粘合”成一体的技术,而不仅仅是让它们“快速对话”。这要求实现内存一致性——让CPU和GPU共享一个统一的内存地址空间,彼此能像访问自家内存一样直接访问对方的内存。
2 NVLink-C2C的核心特性
下面的表格详细阐述了NVLink-C2C的颠覆性特性:
| 特性维度 | 具体描述与解读 |
|---|---|
| 超高带宽 | 提供高达900 GB/s 的总带宽(双向)。这大约是PCIe 5.0 x16带宽(约128 GB/s)的7倍。数据洪流得以在“芯片内部”畅通无阻。 |
| 内存一致性 | 这是与传统NVLink最本质的区别。它使CPU和GPU的内存形成一个统一的内存空间。程序员无需再显式地在CPU和GPU之间拷贝数据,线程可以并行且透明地访问所有内存,极大简化了编程模型,提升了效率。 |
| 极低延迟与高效率 | 由于走线极短(通过硅中介层或晶圆级封装),信号传输延迟大幅降低。同时支持原子操作,实现快速的芯片间同步。其能效和面积效率相比PCIe 5.0分别提升25倍和90倍。 |
| 先进封装 | 依赖硅中介层 或晶圆级封装 等2.5D/3D先进封装技术。这些技术允许在芯片之间铺设数千根极细、极密的连接线,是实现上述高性能的物理基础。 |
| 开放性与生态 | 英伟达已开放NVLink-C2C技术授权,并支持CXL等行业标准。这意味着其他厂商(如CPU、DPU、NIC厂商)可以设计能与英伟达GPU高速、一致性互联的芯片,旨在构建以其为中心的更广泛的生态系统。 |
3 NVLink-C2C的核心价值与生态战略
-
解决根本瓶颈:将CPU与GPU间的数据交换瓶颈从“系统级”提升到“芯片级”,传输开销降至最低,使CPU和GPU能够像单一实体般协同工作。
-
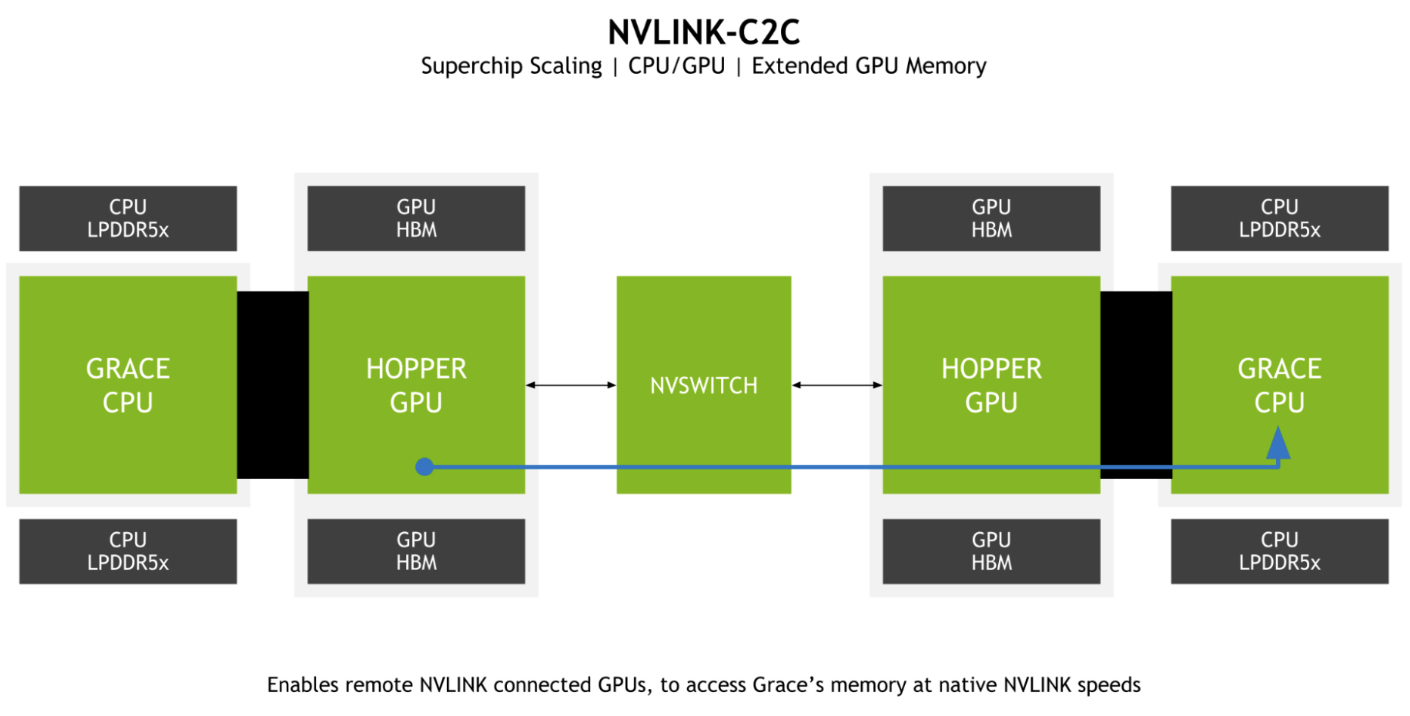
创造“巨量内存”池:以Grace Hopper超级芯片为例,Hopper GPU除了自身的80-144GB HBM3e高速内存外,还能通过NVLink-C2C以高带宽直接访问Grace CPU最高512GB的LPDDR5X内存。这相当于为GPU提供了一个近600GB的“扩展内存池”,对于训练超大型AI模型(如万亿参数模型)至关重要。
-
构建“芯片即系统”:NVLink-C2C是制造“超级芯片”的粘合剂。它将原本独立的、功能各异的芯片(CPU, GPU, DPU)紧密集成在一个封装内,形成一个功能完备的、性能极致的新型计算单元。
-
延伸生态护城河:通过选择性开放授权,英伟达一方面吸引合作伙伴壮大其阵营,另一方面应对由AMD、英特尔等支持的UALink等开放标准的竞争,巩固其在高速互连领域的领导地位。
三、 NVLink与NVLink-C2C的关系与区别:演进与革命
理解了上述基础,我们便可以清晰地梳理二者的关系。它们并非简单的替代,而是架构与实现、继承与发展的关系。
1 核心区别对比
| 特性维度 | NVLink (泛指架构与协议) | NVLink-C2C (特指实现方式) |
|---|---|---|
| 本质 | 一种高速互连的通信协议与架构(定义了“语言”的语法)。 | 一种基于NVLink协议的、芯片到芯片的物理封装和连接技术(定义了“脸贴脸”对话的方式)。 |
| 连接对象与尺度 | 系统级:GPU到GPU;通过PCIe的GPU到x86 CPU。 | 芯片级/封装级:在单个封装内部或基板上,CPU、GPU或其他SoC之间的极近距离连接。 |
| 物理形态 | 通过PCB板上的铜缆或光缆(厘米级)。 | 利用硅中介层或晶圆级封装上的超高密度布线(毫米级及以下)。 |
| 内存一致性 | 不直接提供。GPU间通信需要显式管理,GPU与x86 CPU间通过PCIe协议,也无一致性。 | 核心特性。天然实现连接芯片间的内存一致性,形成统一地址空间。 |
| 带宽与延迟 | 带宽极高,但受限于板卡级布线,延迟相对较高。 | 带宽极致,延迟极低,因走线极短,集成度极高。 |
| 关键目标 | 构建多GPU计算系统,突破PCIe瓶颈。 | 构建超级芯片,实现异构计算单元的深度融合。 |
2 关联与演进:从系统级到芯片级的战略路径
下图清晰地展示了NVLink技术的演进脉络:
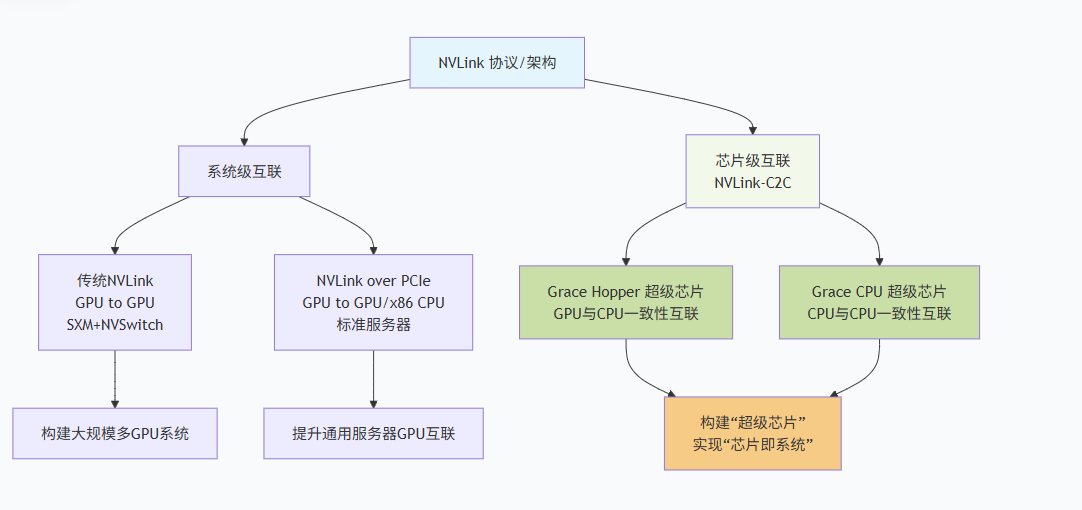
解读此演进图:
-
起源:系统级的GPU互连 (传统NVLink)
-
目标是“多GPU系统”,通过专用线缆和NVSwitch,在服务器内打造高速GPU网络,是数据中心Scale-Up(纵向扩展)的基石。
-
-
扩展:拥抱异构CPU (NVLink over PCIe)
-
这是在x86生态中的一种灵活策略。它让英伟达GPU在更广阔的标准服务器市场也能获得优于纯PCIe的互联能力,可以看作是NVLink协议在物理层上的一次“兼容性”适配。
-
-
革命:芯片级的紧密集成 (NVLink-C2C)
-
这是英伟达掌握全栈技术(从CPU到GPU到网络)后发动的“降维打击”。它跳出了系统布线的物理限制,直接在最底层的芯片封装层面做文章。
-
物理上的根本性改变:从PCB板上的“公路”变为硅中介层上的“纳米级导线”。
-
逻辑上的质的飞跃:从“快速通信”升级为“内存一致性融合”。
-
产品形态的革新:催生了“超级芯片”这一新品类,如Grace Hopper和Blackwell平台。
-
总结来说,NVLink是英伟达互连技术的“灵魂”——一套高效的通信协议。而NVLink-C2C则是这个灵魂在新时代、新载体(超级芯片)上的“肉身”显现。它不仅是技术的升级,更是英伟达从“显卡供应商”向“全栈计算公司”战略转型的核心体现。
四、 实际应用与未来展望
1 当前产品应用
NVLink-C2C技术已不再是蓝图,而是广泛应用于英伟达最新的数据中心产品中:
-
Grace Hopper 超级芯片:最典型的代表,通过NVLink-C2C将Grace CPU与Hopper GPU合二为一,为大模型训练和推理提供巨大内存带宽和容量。

-
Grace CPU 超级芯片:将两个Grace CPU通过NVLink-C2C相连,提供极高的CPU-to-CPU带宽和内存一致性,适用于数据密集型HPC应用。.

-
Blackwell 平台:GB200 NVL72机架级系统,其内部的核心互联技术正是NVLink-C2C的演进与扩展,将36个Grace CPU和72个Blackwell GPU连接成一个整体,像一个巨型GPU一样运作,性能骇人。

2 未来展望
随着计算需求持续向更大规模、更高效率发展,芯片级互连将成为必然趋势。NVLink-C2C技术将继续演进,预计会在以下方面发展:
-
更高带宽与更低功耗:随着封装技术的进步,互连密度和能效将进一步提升。
-
更广泛的异构集成:未来可能看到更多类型的处理单元(如专用AI加速器、FPGA芯粒)通过类似C2C的技术与GPU/CPU集成。
-
生态竞争与融合:NVLink-C2C将与CXL、UALink等开放标准既竞争又融合。英伟达的开放授权策略能吸引多少合作伙伴,将直接影响其生态的广度。
结语
从NVLink到NVLink-C2C,英伟达走过了一条从“优化系统”到“重定义芯片”的技术之路。NVLink解决了“如何让多个计算单元快速对话”的问题,而NVLink-C2C则回答了“如何让多个计算单元融合成一个更强大的单一实体”。这不仅是技术的迭代,更是计算范式的一次深刻变革,它正在塑造着AI与高性能计算的未来图景。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)