python的import用法(相对导入,在一个文件夹的python文件导入另外一个文件夹的python文件)
最近在写一个foxglove可视化的东西,使用python。但是遇到了需要再一个文件夹中的.py文件导入另外一个文件夹中的.py文件的问题,一直无法导入成功,这里记录一下。我的最初的需求是,我想在a.py中导入b.py的内容,并执行a.py的文件,使用相对导入的办法,但是这个实际上是无法做到的,他总是给我提示找不到父包。通过查阅资料得到,如果当前的文件作为一个执行的文件,那么他就是没有父包的,那么
目录
最近在写一个foxglove可视化的东西,使用python。但是遇到了需要再一个文件夹中的.py文件导入另外一个文件夹中的.py文件的问题,一直无法导入成功,这里记录一下。
我的最初的需求是,我想在a.py中导入b.py的内容,并执行a.py的文件,使用相对导入的办法,但是这个实际上是无法做到的,他总是给我提示找不到父包。通过查阅资料得到,如果当前的文件作为一个执行的文件,那么他就是没有父包的,那么相对导入的..没有办法被解析,就会报错。
如果非要这样做,不使用相对导入的方式,一种解决办法是通过sys.path.append()添加B的路径,那么就可以找到B了,python导入包默认的搜索空间的环境变量是
echo $PYTHONPATH
一、相对导入的一般用法
在实际的相对导入的场景中,一般都是有一个主文件,这个是程序执行的入口,还有一个包文件夹,包文件夹中放着各种各样的功能包,一个简单的文件目录结构如下。主文件是main.py,功能包的集合文件夹是E,E中有A,B两个功能包,功能包里面有各种功能模块。下面进行测试。
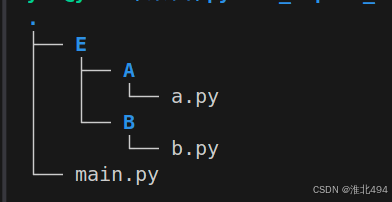
# a.py
from ..B import b
def hello():
b.hello()# b.py
def hello():
print("Hello World")
# main.py
from E.A.a import *
hello()
之后直接执行main.py,输出结果为
![]()
注意:这个E的文件夹是必须得,如果没有E,main.py和A,B直接在同一目录下,他在相对路径转化绝对路径的时候提示已经是最顶层了,找不到B。
二、原理解释
1.直接使用import的路径
直接使用import导入包的路径是
sys.path环境变量里面的路径。
2.带.的相对路径导入方式
每个文件都有一个__package__,如果当前py文件是执行程序的入口,那么他的__package__是None。
对于下面的这个例子,如果从start.py作为程序的入口,那么moduleA的__package__说就是省略/pkg/subPkg1。如果以moduleA.py为程序的入口,那么moduleA的__package__就是None。
你想想,如果直接以moduleA.py为程序的入口,由于__package__是None,他就没办法解析.,..这种相对路径啊,肯定提示找不到包。
如果以start.py为程序入口呢,由于__package__ = 省略/pkg/subPkg1。那么他对.的解释就是subPkg1, 对..的解释就是pkg,那麽肯定就能找到模块了。
这个故事告诉我们,把所有的包方到一个文件夹里面,这个文件夹里面可以组织一些子包。把可执行文件放到最外面, 采用绝对导入的方法。
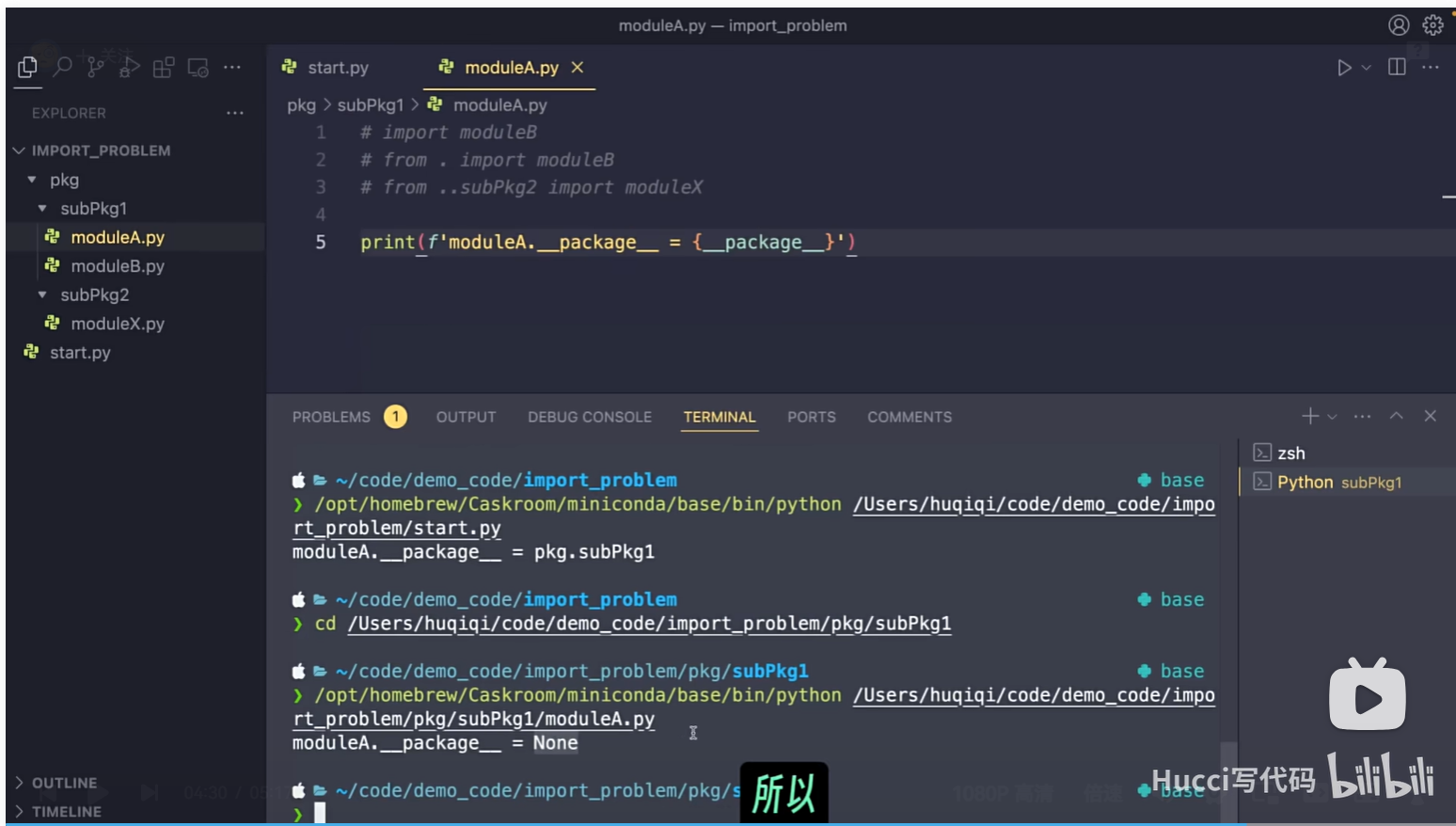
ok,如果非要使用sys.append那么应该如何处理呢?
比如还是上面截图这个例子。那么在A中,直接
import moduleB, import moduleX。
之后再start.py 中直接,
sys.append("省略/pkg/subPkg1"),
sys.append("省略/pkg/subPkg2"),
三、其他事项
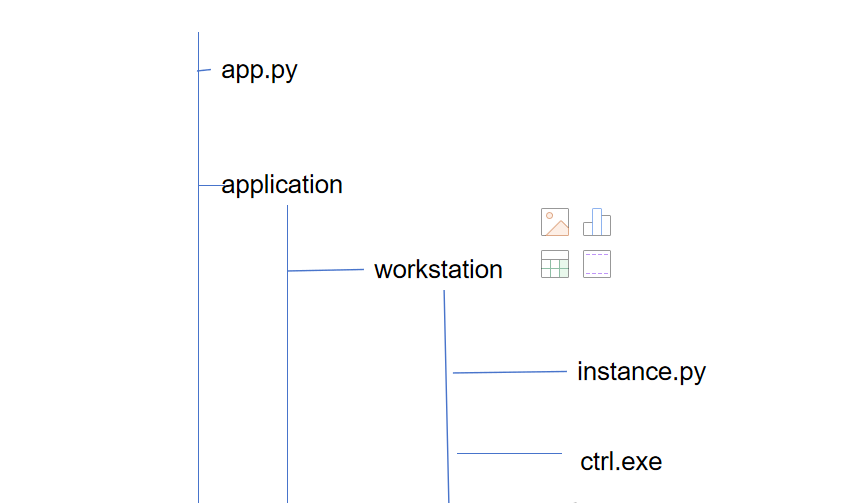
对于一些除了包的导入,就是文件的路径这种。下面是文件树。我的程序的入口是app.py。但是在instance.py中调用了ctrl.exe。那么由于是在app.py启动的,那么他的路径就是默认从app.py开始,所以如果想要在instance.py中找到ctrl.exe。
那么路径应该写为application/workstation/ctrl.exe。这个和包导入是不同的,包导入是从启动文件的路径出发,不断地通过相对导入来更改当前的路径,而查找文件的相对路径永远是启动文件的路径。
四、 全局导入
其实相对导入还是很麻烦,你需要捋清楚各个包之间的关系什么的。但是全局导入就直接一力降十会。
1. 写setup.py文件
这个直接在工作空间下建立一个setup.py,包名称写成自己工作空间的名称就可以了,其他不用管。
如果你想这个项目拿给别人用的话,可以直接在install_requires下写各个包的版本。之后人家建立一个虚拟环境,一个 pip install -e . 就可以全部配置好了。
from setuptools import setup, find_packages
setup(
name='python_test', # 包名称
version='0.1.0', # 版本号
description='A sample Python package', # 简短描述
author='jiangcui.jiang', # 作者
author_email='yangzhihua@qq.com', # 作者邮箱
packages=find_packages(), # 自动查找所有包
include_package_data=True, # 如果有非代码资源(如数据文件),设为 True
install_requires=[ # 定义依赖项
# 'requests>=2.25.1',
],
)
2. 写包文件
新建一个目录coder,在这个目录下建立__init__.py,是一个空文件就可以。之后再再这个目录下建立一个fun.py。在这个目录下建立一个tool子目录,在这个字目录下建立string_bro, string_sis这两个py文件。文件树如下。
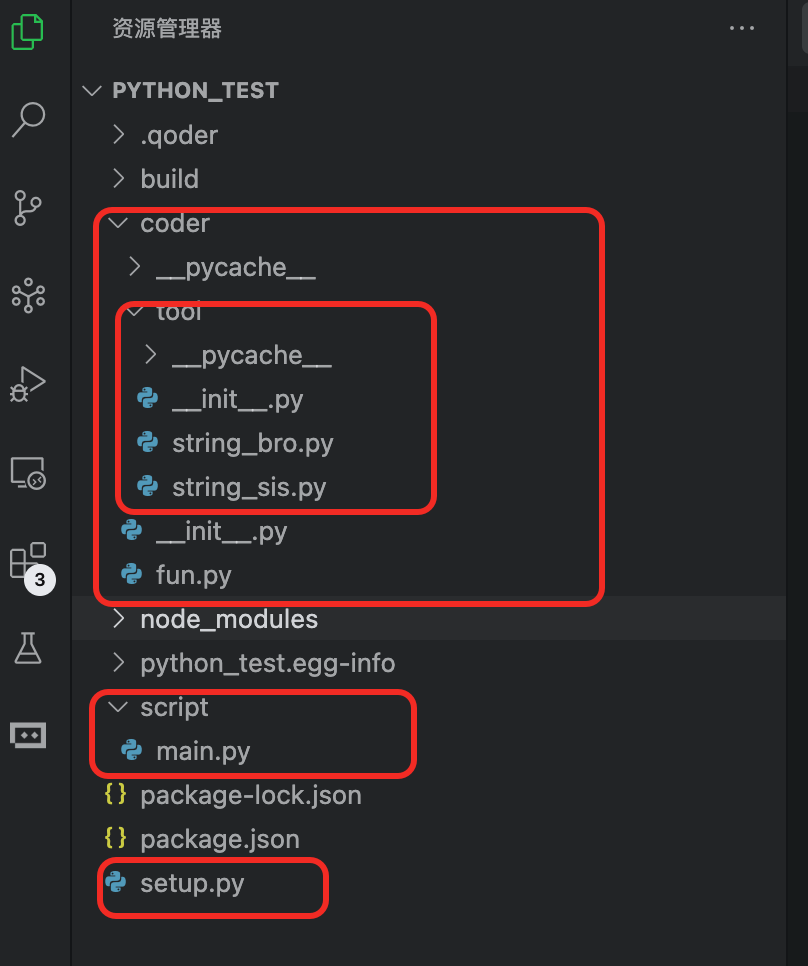
之后就可以在main.py中全局导入各个包的文件。
import coder.fun as f
import coder.tool as tool
if __name__ == '__main__':
f.hello()
tool.print_bro()
tool.print_sis()
3. 把py文件方法整理成包的方法
一个包里面有很多py文件,py文件里面有很多函数或者类。导入这些函数的时候还需要从包到文件再到函数。有一个办法是直接从包到函数。在包的__init__.py里面这样写。
from .string_bro import print_bro
from .string_sis import print_sis这样这个函数就是包的一部分,可以通过包直接找到这些函数。
import coder.tool as tool4. 安装
各个文件全部写好之后,使用
pip install -e .就可以全局安装了。这个全局安装由于是pip,所以是全局安装到某个环境里面,如果切换了环境就不能用了。
五、另外一种全局导入
1. pyproject.toml
下面是pyproject.toml,他基本上和setup.py的功能一样,但是更加细致。因为setup里面依赖就是依赖,pyproject把依赖分为很多种,安装的时候可以选择性安装。
setup.py(传统方式)
- 用 Python 代码描述包的元数据/依赖/打包逻辑:
setuptools.setup(...)- 灵活但容易写出执行代码的构建逻辑,配置分散。
pyproject.toml(现代标准,PEP 518/621)
- 用 TOML 配置声明:项目元数据、依赖、可选依赖、构建后端等
- 更标准化,工具(pip、build、poetry、uv 等)更容易解析
- 你这个项目用的是
setuptools.build_meta,说明依然用 setuptools 作为构建后端,只是配置放到pyproject.toml里。
[build-system]
requires = ["setuptools>=61.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "agent-autolabel"
version = "0.1.0"
description = "AgentAutolabel - 基于 MCP 架构的自动标注系统"
readme = "README.md"
license = {text = "MIT"}
requires-python = ">=3.9"
authors = [
{name = "huaibin"}
]
keywords = ["mcp", "autolabel", "llm", "agent"]
classifiers = [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
]
dependencies = [
"fastapi==0.128.0",
"fastmcp==2.14.2",
"sqlmodel==0.0.16",
"redis==5.0.1",
"aiofiles==23.2.1",
"asyncio==3.4.3",
"aiohttp==3.13.3",
"oss2==2.19.1",
"urllib3==2.6.3",
"tqdm==4.67.1",
"requests==2.31.0",
"sqlalchemy==2.0.23",
"duckdb>=0.10.0",
"duckdb-engine>=0.13.0",
"datasette==0.65.2",
"datasette-insert==0.8",
"datasette-parquet==0.6.1",
"greenlet==3.3.0",
"aiosqlite==0.22.1",
"pillow==12.1.0",
"openai==2.15.0",
"wget==3.2",
"psutil==7.2.2",
"tenacity==9.1.4",
]
[project.optional-dependencies]
viz = [
"streamlit>=1.31.0",
"streamlit-agraph>=0.0.45",
"opencv-python>=4.8.0",
"matplotlib>=3.7.0",
"open3d>=0.17.0",
"scipy>=1.11.0",
]
dev = [
"pytest>=7.0.0",
"pytest-asyncio>=0.21.0",
"pytest-cov>=4.0.0",
]
docs = [
"sphinx>=7.0.0",
"sphinx-rtd-theme>=2.0.0",
]
search = [
"pandas==2.3.3",
"streamlit>=1.31.0",
"streamlit-agraph>=0.0.45",
]
all = [
"fastapi==0.128.0",
"fastmcp==2.14.2",
"sqlmodel==0.0.16",
"redis==5.0.1",
"aiofiles==23.2.1",
"asyncio==3.4.3",
"aiohttp==3.13.3",
"oss2==2.19.1",
"urllib3==2.6.3",
"tqdm==4.67.1",
"requests==2.31.0",
"sqlalchemy==2.0.23",
"datasette==0.65.2",
"datasette-insert==0.8",
"greenlet==3.3.0",
"aiosqlite==0.22.1",
"pillow==12.1.0",
"openai==2.15.0",
"wget==3.2",
"streamlit>=1.31.0",
"streamlit-agraph>=0.0.45",
"opencv-python>=4.8.0",
"matplotlib>=3.7.0",
"open3d>=0.17.0",
"scipy>=1.11.0",
"psutil==7.2.2",
"pandas==2.3.3",
"datasette-parquet==0.6.1",
"datasette-vega==0.6.2",
"tenacity==9.1.4",
"duckdb>=0.10.0",
"duckdb-engine>=0.13.0",
]
[project.scripts]
agent-autolabel = "app:main"
data-miner = "data_miner.run_miner:main"
datasette-viewer = "visualizer.datasette_app:main"
download-matrix = "downloads.matrix.main:main"
download-fastdm-marker = "downloads.fastdm.main:main"
download-cyber = "downloads.cyber.main:main"
vue-pullover = "visualizer.pullover.cli:main"
sync-pd-labels = "scripts.postprocess.sync_pd_labels:main"
sync-prediction-protos = "scripts.postprocess.sync_prediction_protos:main"
sync-pickle-labels = "scripts.postprocess.sync_pickle_labels:main"
[project.urls]
Homepage = "https://github.com/huaibin/AgentAutolabel"
Documentation = "https://github.com/huaibin/AgentAutolabel#readme"
Repository = "https://github.com/huaibin/AgentAutolabel"
[tool.setuptools]
packages = [
"mcps", "mcps.examples", "mcps.agent_autolabel",
"mcps.agent_autolabel.perception_mcp_pool",
"mcps.agent_autolabel.planning_mcp_pool",
"mcps.agent_autolabel.selector",
"llm", "database", "database.data", "database.data_provider",
"database.data.agent_labeled_data",
"database.server",
"database.image_processor",
"dataset_manager",
"utils", "config", "prompt",
"visualizer", "visualizer.streamlit", "visualizer.pullover",
"data_miner", "data_miner.projects", "data_miner.match_functions",
"downloads", "downloads.matrix", "downloads.fastdm", "downloads.cyber",
"scripts", "scripts.postprocess"
]
include-package-data = true
[tool.setuptools.package-data]
"*" = ["*.yaml", "*.json", "*.jinja2", "*.j2"]
[tool.pytest.ini_options]
asyncio_mode = "auto"
testpaths = ["test"]
python_files = ["test_*.py"]
python_classes = ["Test*"]
python_functions = ["test_*"]
[tool.black]
line-length = 100
target-version = ['py39', 'py310', 'py311']
[tool.isort]
profile = "black"
line_length = 100
2. 一些安装
pip install -e .只装[project].dependencies里那一组(基础依赖)。pip install -e .[all]会装 基础依赖 + optional-dependencies 里 all 这一组。最终等价于安装:dependencies ∪ all(取并集,重复的不再装两次)。
# 只安装必要依赖
pip install -e .
# 安装必要依赖和all
pip install -e .[all]
# 安装必要依赖和其他的一些
pip install -e ".[all,dev]"

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)