大模型训练和推理阶段的内存消耗估计
本文以Mixtral-8x22B为例来介绍各个阶段的内存消耗以及推理和训练时的内存消耗。
文章目录
上一篇文章提到了llama 3 8b 全量微调需要占用 Fine-tuning内存占用128.87GB的内存,主要包括三方面,分别是:
- loading the model
- optimizer states
- activations
本文以Mixtral-8x22B为例来介绍各个阶段的内存消耗以及推理和训练时的内存消耗。
各阶段内存消耗
model 自身占用内存
要想知道模型有多少个参数,直接查看模型卡片即可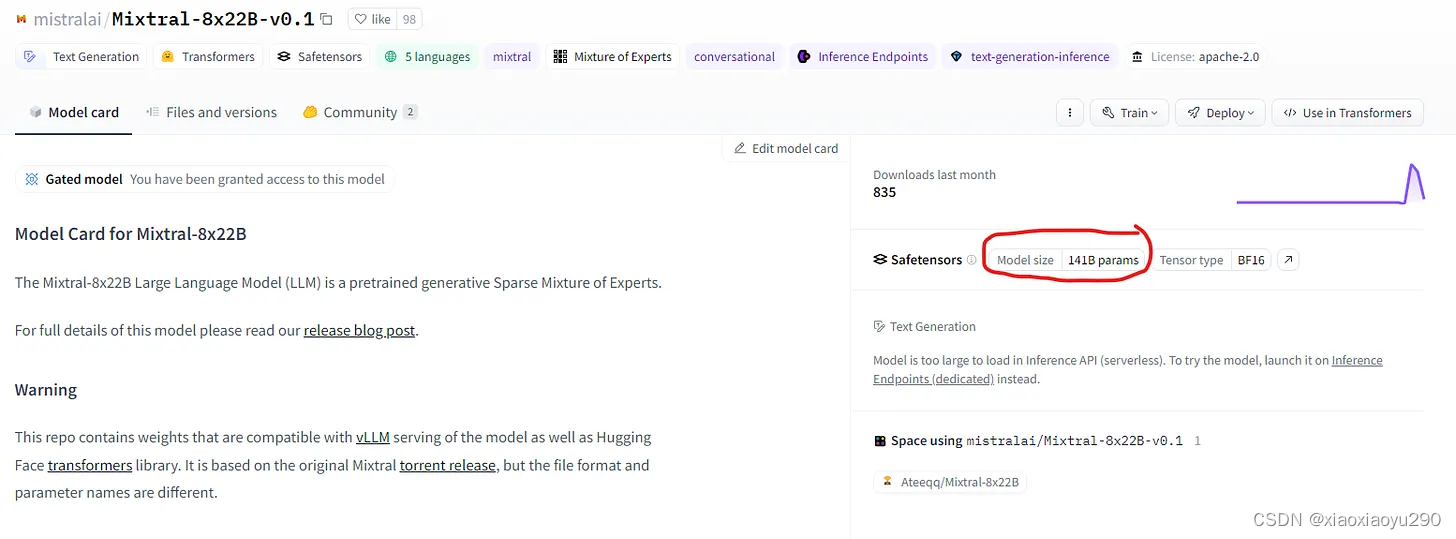
如果想在GPU上进行快速推理,就需要将模型完全加载到GPU内存中。对于“Command-R”需要193.72 GB的GPU显存;对于Mixtral-8x22B来说需要有262.63 GB的GPU内存;对于Llama 3 70B型号,其拥有131.5 GB的GPU内存(每个参数占用16 bit,即 2 bytes)
activations的内存消耗(重点)
首先需要知道以下信息:
- max_seq_len,记为s
- hidden_size,记为h
- attention head的数量,记为a
- layer number,记为l
标准的transformer block如下: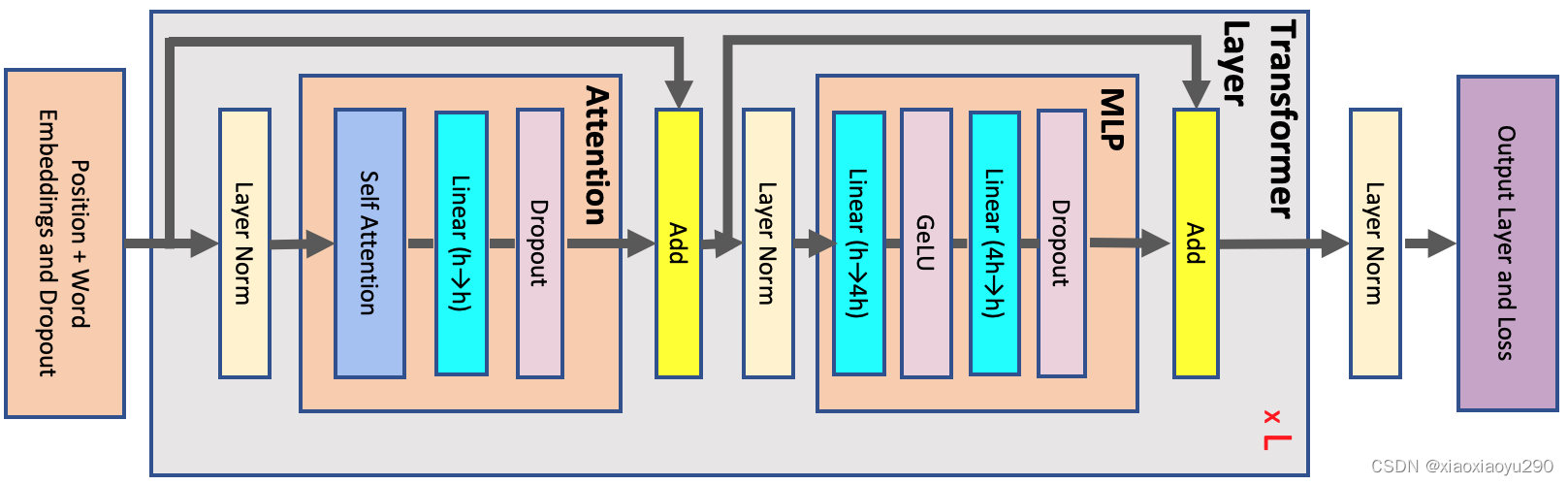
At the start of the network, the input tokens are fed into a word embedding table with sizev×h, and the token embeddings are combined with learned positional embeddings with sizes×h, where s is the sequence length, h is the hidden dimension, and v is the vocabulary size. The output of the embedding layer, which is the input to the transformer block, is a 3-D tensor of size b×s×h, where b is the microbatch size. Each transformer layer consists of a self-attention block with a attention heads followed by a multi-layer perceptron (MLP) with two layers which increase the hidden size to 4h and then reduce it back to h. Input to and output from each transformer layer have the same size b×s×h. The output from the last transformer layer is projected back into the vocabulary dimension to calculate the cross-entropy loss. We assume that word embedding and output layer weights are shared.
- 参考论文:https://ar5iv.labs.arxiv.org/html/2205.05198
- Note that “activations” in this paper refers to any tensor that is created in the forward pass and is necessary for gradient computation during back-propagation. As a result, this excludes the main parameters of the model and optimizer state, but, for example, includes the mask used by the dropout operation.
- In addition, we only consider the main contributors to the memory and ignore small buffers. For example, for a layer normalization block, the input to the layer as well as the input’s mean and variance are required to calculate the gradients. The input contains
sbhelements whereas mean and variance have onlysbelements each. Sincehis large (of order of thousands). As a result it is a good approximation to only consider the memory required to store the input, i.e., we only includesbh.- We also assume that the network and the activations are stored in a 16-bit floating point format and therefore each element requires 2 bytes for storage. The only exceptions are the dropout masks which only require a single byte per element. Note that all the reported sizes in this section are in bytes and not number of elements unless explicitly mentioned.
(1) Attention block
which includes self attention followed by a linear projection and an attention dropout
(2) MLP block

每层激活记忆消耗量 = 34sbh × 5as²b
Optimizer States的内存消耗
优化器是导致微调比推理消耗更多内存的主要原因:
- AdamW优化器是用于微调LLMs(大型语言模型)的最流行的优化器,它为模型中的每个参数创建并存储了2个新参数。如果我们有一个100B大小的模型,那么优化器将创建200B个新参数!
- 为了提高训练的稳定性,优化器的参数采用浮点数32位(float32)表示,即每个参数占用4字节的内存。
- 此外,它将模型的参数和梯度复制为float32类型。在混合精度训练中,梯度通常为16位参数。
例如,对于Mixtral-8x22B,优化器除了复制模型参数(141B float32)和梯度(141B float16)之外,还会创建282B float32参数。为此,我们需要额外占用1053.53 GB的内存,再加上模型本身占用的262.63 GB内存,总共需要1315.63 GB的GPU内存。这大致相当于17个80 GB的GPU!
推理时内存消耗
当 s = 512 (the sequence length),b = 8 (the batch size)时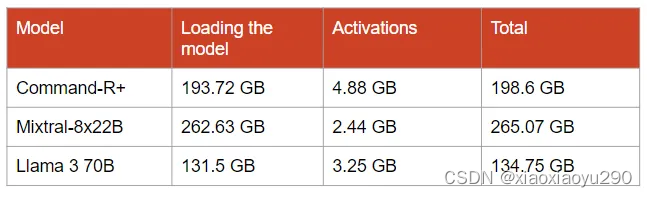
h和l需要参照huggingface中的值。Compared to the size of the model in memory, the size of the activations is negligible. However, their size rapidly increases as the batch size and the sequence length get larger.
训练时内存消耗
In contrast with inference for which we only need to store activations for a single layer before passing them to the next one, fine-tuning requires storing all the activations created during the forward pass. 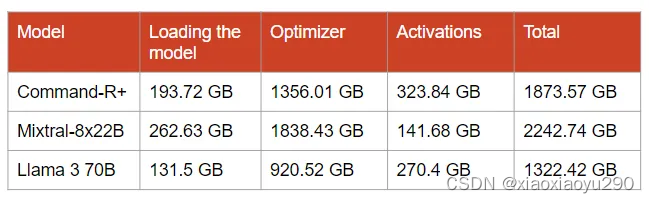
code
上述具体的计算代码详见github.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)