springboot整合ELK---分两种直接使用logstash,另外一种整合kafka
·
环境说明:springBoot2.1.3,logback,es6.8.2
当我们服务节点特别多的时候,我们就需要考虑将日志统一放到ELK中去高效查找定位日志,不用去服务器一个一个找。同时整合分布式链路追踪打印日志。这里提供两种springboot整合ELK的方式。
1.第一种springboot-logstash环境搭建
1.1 添加maven
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
1.2 logback-spring.xml添加日志打印
<!--LOGSTASH config -->
<appender name="LOGSTASH"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:5000</destination>
<!--<encoder charset="UTF-8"
class="net.logstash.logback.encoder.LogstashEncoder"> -->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS}
[service:${springAppName:-}]
[traceId:%X{X-B3-TraceId:-},spanId:%X{X-B3-SpanId:-},parentSpanId:%X{X-B3-ParentSpanId:-},exportable:%X{X-Span-Export:-}]
[%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
</appender>
1.3配置logstash
input {
tcp {
port => 5000
}
}
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:logTime} %{GREEDYDATA:service} %{GREEDYDATA:thread} %{LOGLEVEL:level} %{GREEDYDATA:loggerClass}-%{GREEDYDATA:logContent}"}
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "springboot-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
}
}
1.4 启动ES, kibana, logstash, springboot查看
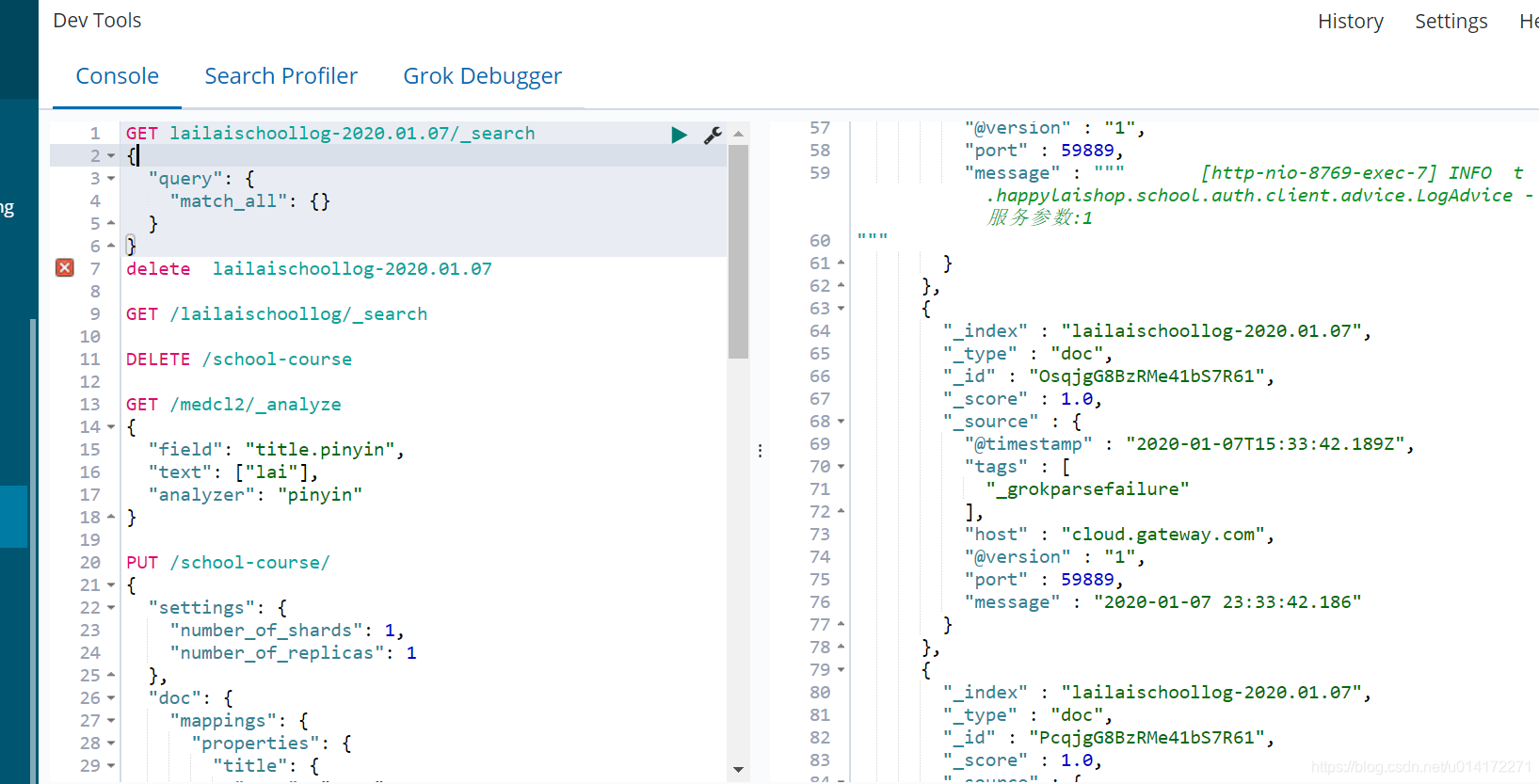
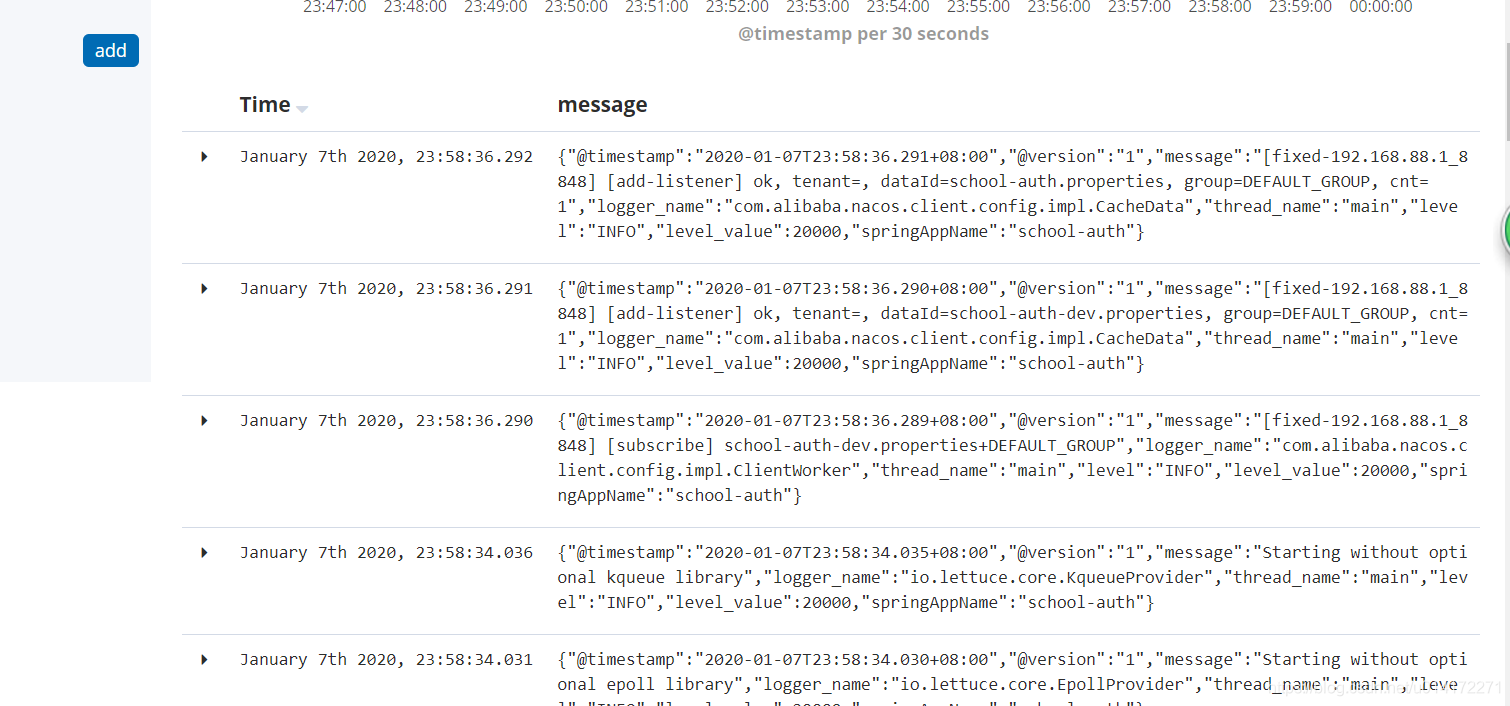
2.第二种springboot-kafka-logstash环境搭建
2.1 maven添加依赖
<dependency> <groupId>com.github.danielwegener</groupId> <artifactId>logback-kafka-appender</artifactId> <version>0.2.0-RC2</version> </dependency>
2.2 修改日志配置
<appender name="kafkaAppender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [service:${springAppName:-}]
[traceId:%X{X-B3-TraceId:-},spanId:%X{X-B3-SpanId:-},parentSpanId:%X{X-B3-ParentSpanId:-},exportable:%X{X-Span-Export:-}]
[%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
<topic>authLog</topic>
<!-- we don't care how the log messages will be partitioned -->
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy" />
<!-- use async delivery. the application threads are not blocked by logging -->
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<!-- each <producerConfig> translates to regular kafka-client config (format: key=value) -->
<!-- producer configs are documented here: https://kafka.apache.org/documentation.html#newproducerconfigs -->
<!-- bootstrap.servers is the only mandatory producerConfig -->
<producerConfig>bootstrap.servers=localhost:9092</producerConfig>
<!-- don't wait for a broker to ack the reception of a batch. -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the application but start to drop messages -->
<producerConfig>max.block.ms=0</producerConfig>
<!-- define a client-id that you use to identify yourself against the kafka broker -->
<producerConfig>client.id=${HOSTNAME}-${CONTEXT_NAME}-logback-relaxed</producerConfig>
</appender>
2.3 修改Logstash
input {
kafka {
id => "my_plugin_id"
bootstrap_servers => "127.0.0.1:9092"
topics => ["authLog"]
auto_offset_reset => "latest"
}
}
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:logTime} %{GREEDYDATA:service} %{GREEDYDATA:thread} %{LOGLEVEL:level} %{GREEDYDATA:loggerClass}-%{GREEDYDATA:logContent}"}
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "springboot-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
}
}
2.4启动zk,kafka,elk
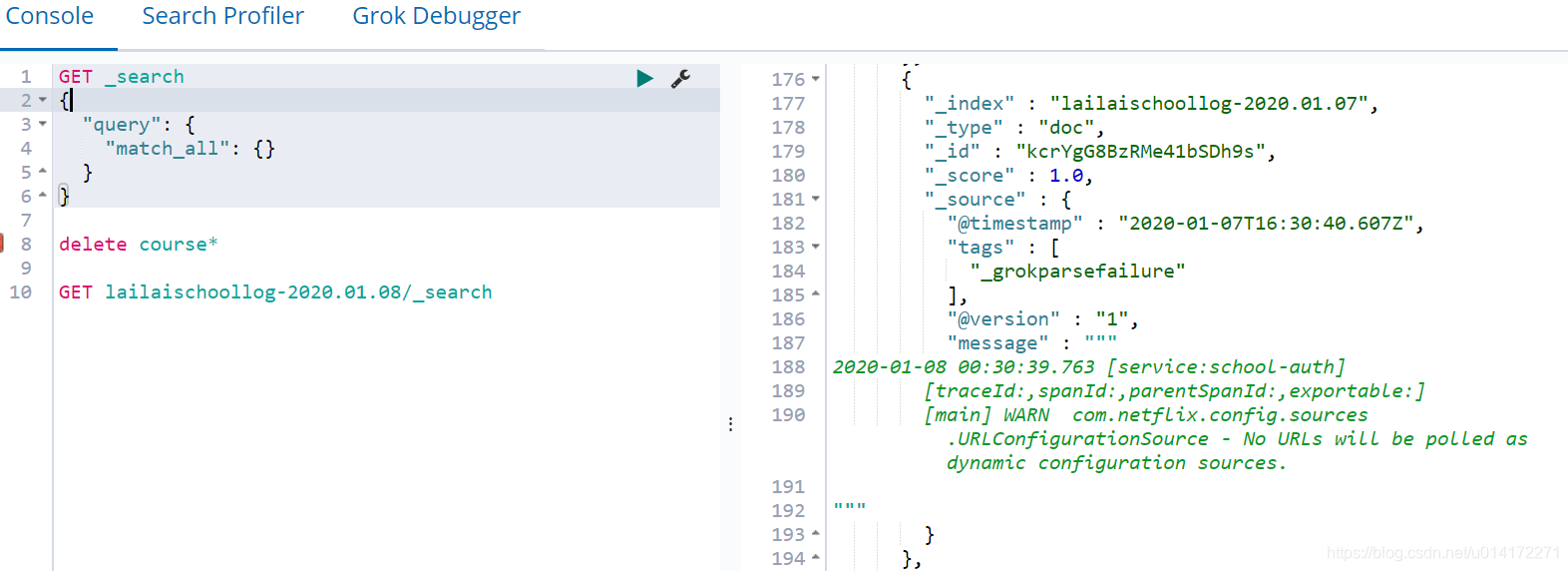

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)