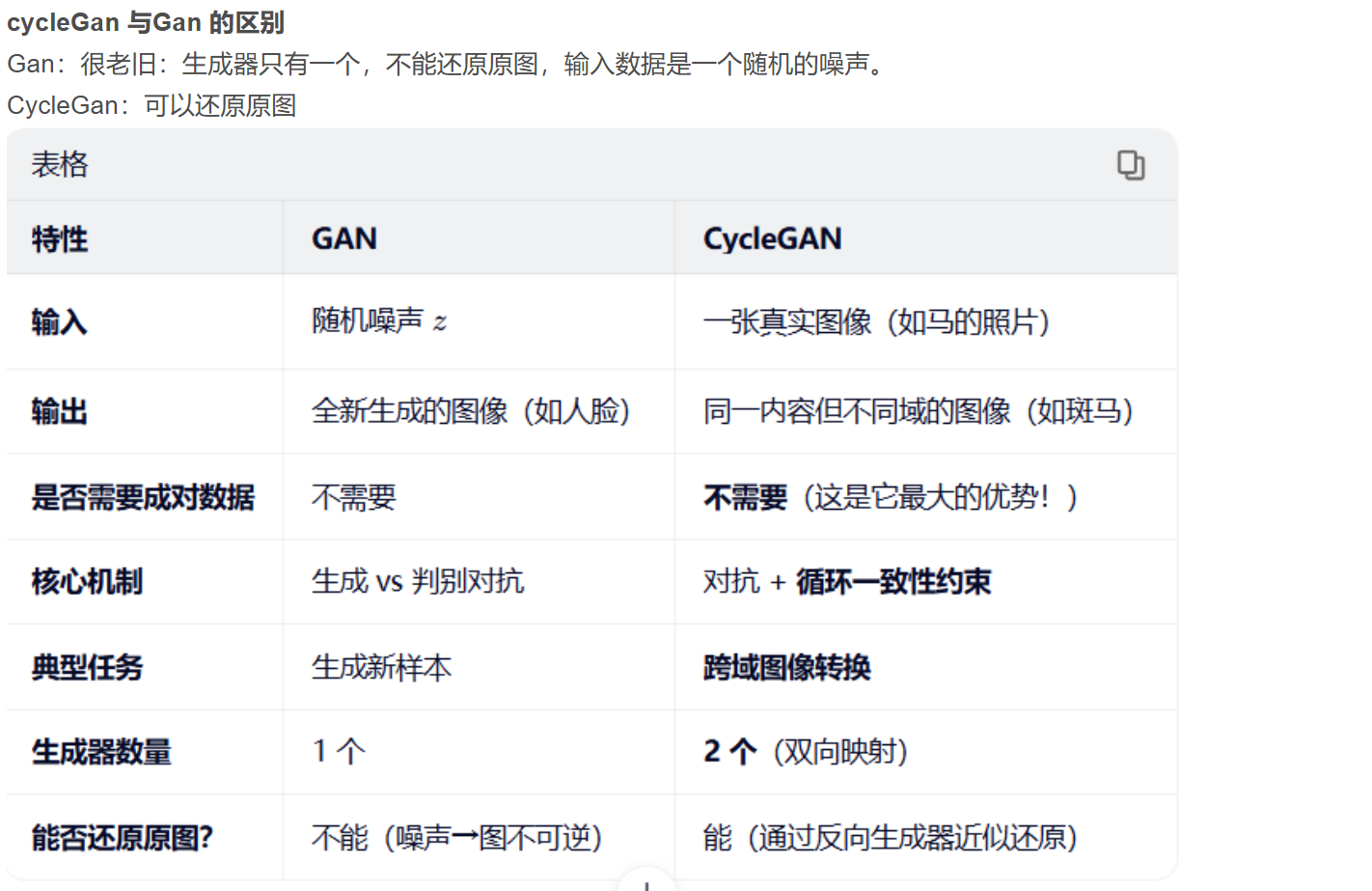
无监督学习、对比学习及生成式自监督学习
无监督学习是一种从无标签数据中发现内在结构和模式的方法。其核心任务包括聚类(如K-Means算法对客户细分)和降维(如PCA简化高维数据)。对比学习通过"相似性判断"训练AI的特征提取能力,如SimSiam算法利用图像增强进行自监督学习。GAN则通过生成器与判别器的对抗训练实现数据生成,CycleGAN能完成图像风格转换。生成式自监督学习(如BERT掩码预测、GPT自回归)是大
无监督学习
无监督学习,一般指我们只有数据,没有标签。
一句话概括
给你一堆“没有标准答案”的东西,让你自己去发现其中的结构、模式或分组。
类比:
想象你被扔进一个堆满了各种衣服的房间里,但没人告诉你这些衣服是T恤、裤子还是裙子。
你的任务是:
发现规律:哦,有些衣服是棉的,有些是丝绸的。
进行分组:把长袖的放一堆,短袖的放一堆;或者把红色的放一堆,蓝色的放一堆。
总结特点:这个房间的衣服大部分是运动款,颜色比较鲜艳。
你做的这一切,没有任何人给你标准答案,全靠自己观察和归纳。这就是无监督学习。
核心思想
无监督:数据没有标签,只有“特征”。算法不知道“正确答案”是什么,也没人教它。
目标:从这些“无答案”的数据中,探索其内在结构、模式或简化表达。它不是为了“预测”,而是为了“发现”。
主要任务类型
1. 聚类
目标:物以类聚。把相似的数据点自动归为一组(簇),不相似的分到不同组。
结果:你不知道每个组叫什么名字,但你知道哪些东西比较像,可以归在一起。
生活例子:
客户细分:电商有一百万用户,没有预先分类。通过分析购买记录、浏览行为,算法自动把用户分成几个不同的群体(比如“高消费家庭主妇”、“追求性价比的学生”、“数码发烧友”)。公司再针对不同群体制定营销策略。
新闻分组:搜索引擎抓取一天的海量新闻,自动把它们按主题分成“科技类”、“体育类”、“财经类”等不同的簇。
经典算法:K-Means, DBSCAN, 层次聚类。
2. 降维
目标:化繁为简。在保留最主要信息的前提下,把复杂的高维数据压缩到低维(比如二维或三维)。
为什么做:高维数据(比如有几百个特征)难以理解和可视化。降维后,可以画在图上,让人眼能看清数据的大致结构和分布。
生活例子:
你描述一个人,可以说“身高180cm,体重70kg,头发颜色,眼睛颜色,学历,收入……” 有几十个维度。
降维就像用一个“综合评分”或两个核心维度(比如“体型”和“社会属性”)来大致概括这个人,虽然丢失了细节,但能快速把握主要特点。
经典算法:主成分分析(PCA),t-SNE。
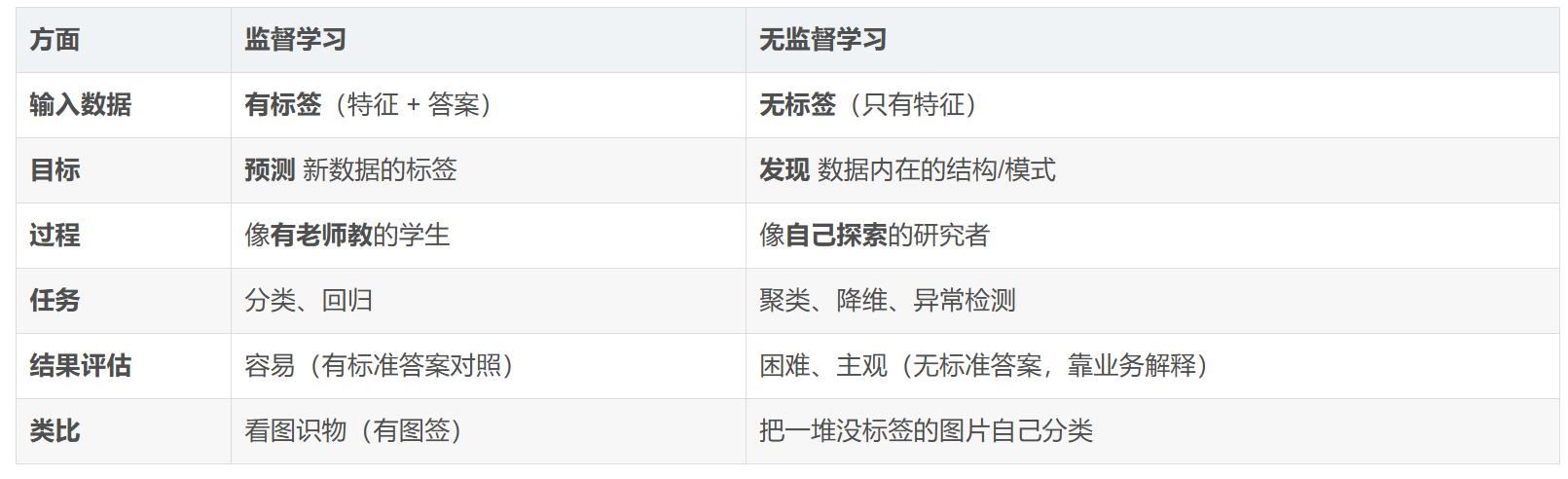
与监督学习的核心区别(一张表看懂)
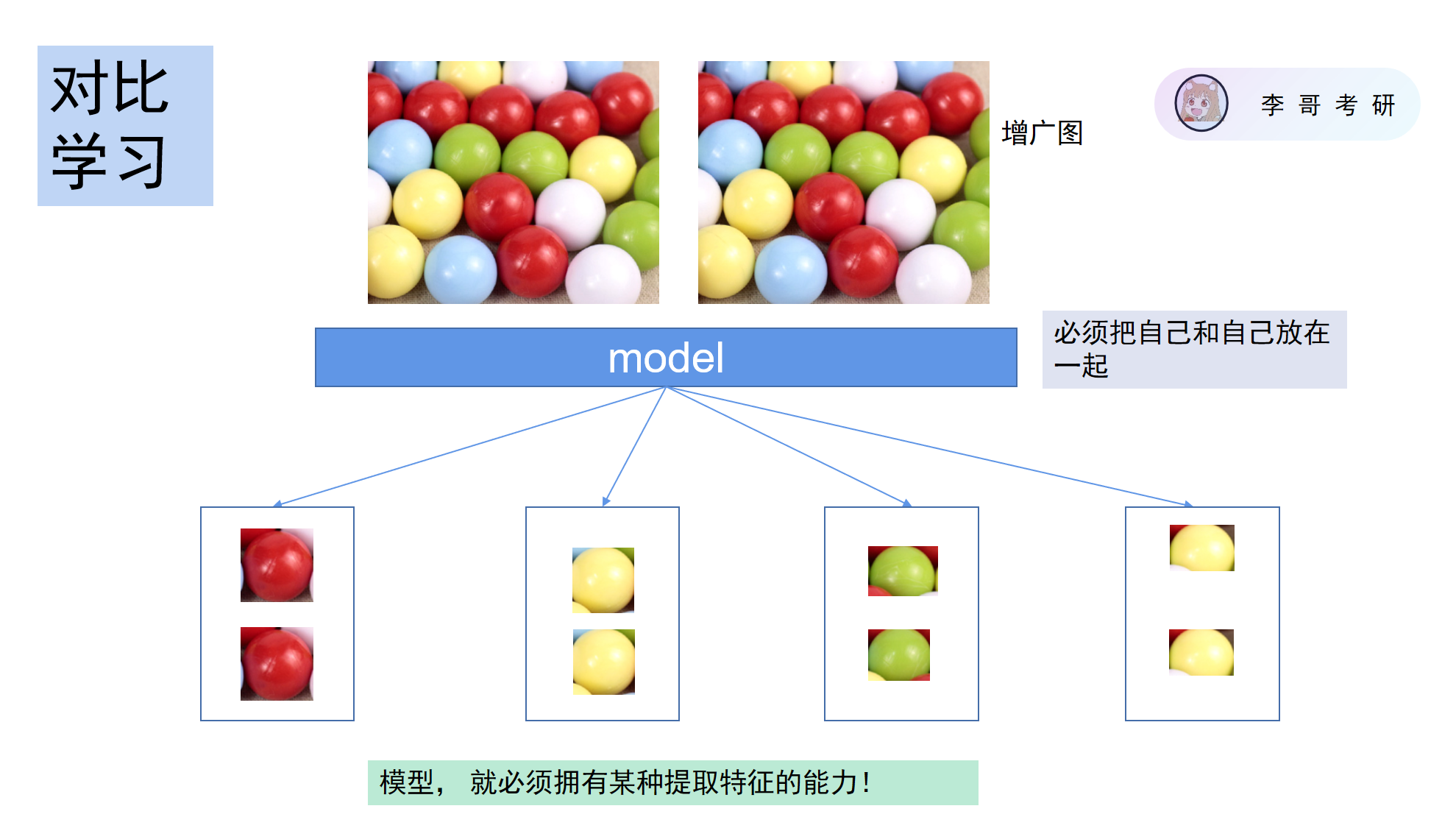
对比学习
让自己和自己靠的更近一些
把自己和自己的增广图像当作一对,把别人当作敌人。亲近自己,远离别人。
1.传统方法(监督学习):你指着图片一张张教他:“这是猫,这是狗,这是猫……”
2.对比学习方法:
你根本不提“猫狗”这两个词,只做三件事:
找相似:拿出同一只猫的两张不同照片(一张正面、一张睡觉),说:“这两张是‘同一种东西’。”
找不同:拿出猫的照片和狗的照片,说:“这两张‘不是同一种东西’。”
让他自己猜:就这样用几万张图片反复玩,最后问他:“你觉得这两张(一张新猫图、一张新狗图)是同一类吗?”他会回答:“不是,左边这个属于‘猫类’,右边这个属于‘狗类’。”
关键:他自己总结出了“猫类”和“狗类”的特征,尽管你从未说过“猫”和“狗”这两个词。
更本质的理解:AI的“感觉系统”训练法
1. 目标是什么?
让AI对事物产生“感觉”——不是知识,而是直觉。
就像你闭眼摸东西:一摸毛茸茸有爪子,感觉是猫;一摸湿漉漉有鳞片,感觉是鱼。
对比学习就是训练AI的这种“触觉”。
2. 怎么训练?
不是教它“这是什么”,而是告诉它:
“这两个东西给你的感觉应该很像”(比如猫的正面和侧面)
“这两个东西给你的感觉应该很不像”(比如猫和汽车)
通过成千上万次的“像vs不像”训练,AI逐渐建立起了自己对世界的“感觉体系”。
3. 为什么有效?
因为它迫使AI忽略表面差异,关注本质。
猫无论什么颜色、姿势,摸起来的感觉(特征)都差不多。
猫和汽车无论怎么摆拍,感觉都天差地别。
AI为了完成“找相似”任务,就必须抽象出最核心的特征。
终极比喻:给AI做“性格测试”
想象给AI做这样的测试:
问题1:你觉得“猫的正面照”和“猫的背面照”像吗?
AI应该答:像(它们本质都是猫)
问题2:你觉得“猫的照片”和“汽车照片”像吗?
AI应该答:不像(完全不同类)
做几百万道这种题后,AI就形成了自己的“价值观”(特征系统),能判断万事万物之间的相似度。以后看到新图片,它就能用这套价值观来理解了。
所以对比学习的核心就是:不说是什么,只说像不像;练够百万次,自通天下物。
SimSiam("Simple Siamese network" 的简称)
这是一个非常重要的对比学习算法,以简单、优雅、高效而闻名。
核心思想:一个人的左右手互搏
想象你在教一个AI认识世界,但只给它一堆没有标签的图片。
SimSiam 想出了一个绝妙的“单人游戏”:让AI的 “左手” 和 “右手” 看同一只猫的两张不同照片(比如一张正的,一张歪的),然后让它的“右手”去猜“左手”看到了什么。
神奇之处在于:这个游戏不需要任何“负样本”(不像的图片),也不需要复杂的内存库。它自己和自己玩,就能学到东西。
游戏规则详解(三步走)
假设我们有一张猫的图片 X。
第一步:制造“谜面”和“谜底”
对 X做两次不同的数据增强(比如裁剪、调色):
得到 版本一:X1(例如:猫的全身照)
得到 版本二:X2(例如:猫的特写大头照)
把它们分别送入同一个神经网络(编码器)。
这个网络有两个部分:
在线网络:像游戏里的“玩家”,需要不断学习和进步。
目标网络:像游戏里的“参考答案”,它只是缓慢地跟随在线网络,保持稳定。
第二步:开始“猜谜”
在线网络 处理 X1,输出一个特征向量 P1(可以理解为对这张图片的“描述”)。
目标网络 处理 X2,输出一个特征向量 Z2(这是“参考答案”)。
现在,游戏的目标是:让在线网络对 X1的“描述”P1,尽可能接近目标网络对 X2的“参考答案”Z2。
第三步:核心魔法——“停止梯度”
这是 SimSiam 最聪明的一点:
在计算“参考答案” Z2时,我们切断它的梯度回传路径(技术上叫 stop-gradient)。
这意味着:目标网络像一个“沉稳的老师”,它不会被学生(在线网络)的答案所影响而胡乱改变。它只是提供稳定、可靠的目标。
在线网络则像一个“勤奋的学生”,需要努力调整自己,使自己输出的描述 P1去匹配老师提供的参考答案 Z2。
这个过程可以概括为:拿版本一,去预测版本二的特征。
一个生动比喻:临摹大师的画作
准备:你(在线网络)和老师(目标网络)各拿到一幅梵高《星空》的高清复制品,但这两张复制品略有不同(比如亮度、裁剪不同)。
任务:你要临摹你手中的那幅,目标是让你临摹出来的画,和老师手中那幅画的“神韵”一模一样。
关键规则:老师手里的画是“标准答案”,它不会因为你临摹得好坏而改变。 你只能通过不断调整自己的笔法(更新在线网络),让自己的画越来越接近老师那幅画的神韵。
结果:经过无数次临摹不同画作(不同图片)的练习,你虽然从未被告知“这是星空,那是向日葵”,但你深刻地掌握了梵高笔触的精髓。以后看到一幅新的、从未见过的梵高画作,你也能立刻认出其风格。
在 SimSiam 中,“神韵”就是图片的特征向量。通过让两个增强视图的特征互相匹配,网络学会了抓取图片中最本质、不受增强干扰的信息。
它的优点
极其简单:不需要像 MoCo 那样维护一个队列作为负样本库,也不需要像 SimCLR 那样依赖巨大的批处理规模来获得足够的负样本。架构非常简洁。
没有负样本:它避免了“负样本”可能带来的问题(比如可能会把本应相似的困难样本错误地推开)。
效率高:训练更稳定,对计算资源的要求相对较低。
效果好:尽管简单,但在 ImageNet 等标准数据集上的性能与那些更复杂的对比学习方法相当。
GAN(生成对抗网络)
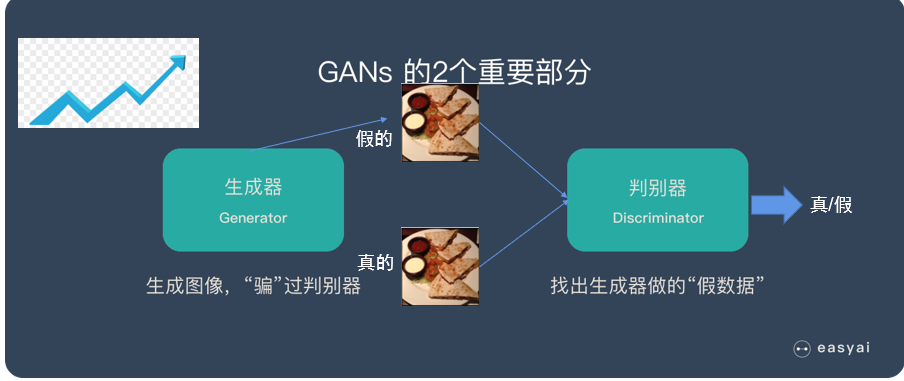
GAN(生成对抗网络)是人工智能领域最有趣、也最像“左右互搏”的神奇技术。
一句话概括
GAN是让两个AI相互对抗、共同进化:一个拼命造假,一个拼命鉴假,最终造假者造出以假乱真的东西。
完整故事:艺术伪造工厂
角色介绍
伪造者(Generator,生成器):
目标:伪造世界名画(比如梵高的《星空》)。
初始状态:技术很烂,画得像儿童涂鸦。
鉴定专家(Discriminator,判别器):
目标:鉴定画作是真迹还是赝品。
初始状态:水平一般,但比伪造者强一点。
训练过程(一场持续的军备竞赛)
第一轮:
伪造者画了一张很假的《星空》赝品。
鉴定专家一看就说:“垃圾!颜色不对,笔触粗糙,一眼假!”(判别器输出:0.01,几乎肯定是假的)
伪造者很受挫,但记住了这次失败的原因,回去改进技术。
第二轮:
伪造者画得稍微好了一点。
鉴定专家仔细看后说:“嗯…有点像了,但这里、那里还是有问题,70%可能是假的。”(判别器输出:0.3)
伪造者又学到了:“哦,原来要注意这些细节”。
第N轮(关键转折):
伪造者技术突飞猛进,造了一张高仿。
鉴定专家仔细研究后犹豫了:“这…太像真的了,但我感觉有点不对劲,51%可能是真的?”(判别器输出:0.49)
鉴定专家也开始慌了,意识到对手变强了,自己必须升级鉴伪技术。
最终轮(理想状态):
伪造者造出了一张完美赝品。
鉴定专家用尽所有手段,放大镜、光谱仪都上了,最后说:“我无法判断!这有50%的可能是真迹!”(判别器输出:0.5)
此时,伪造者已经成为了超级伪造大师,它画的《星空》连最顶级的专家都难辨真假!
GAN的核心机制
1. 生成器(G)的运作
输入:随机噪声(就像一堆随意的颜料和灵感碎片)。
输出:一张“伪造”的图片。
学习目标:骗过判别器,让判别器认为它生成的是“真的”。
2. 判别器(D)的运作
输入:一张图片(可能来自真实数据集,也可能是生成器造的假)。
输出:一个概率值(0到1之间),表示这张图是“真实”的概率。
学习目标:尽可能准确地区分真假。
3. 对抗过程(数学上的“二人极小极大博弈”)
生成器想最大化判别器对自己造假的误判率。
判别器想最大化自己的鉴别准确率(同时最小化生成器的成功率)。
它们就像在玩一个动态平衡的游戏:任何一方的进步都会迫使另一方进步。
GAN的独特魅力与挑战
魅力
无需标注数据:只需要真实的图片,不需要告诉AI“这是猫”“那是狗”。
能创造新内容:不仅仅是分析数据,而是创造新的数据。
自我驱动进步:两个网络互相逼迫,实现自动化升级。
挑战(为什么GAN难训练)
模式崩塌:生成器可能只学会画一种东西(比如只画某一种角度的猫),因为它发现这样就能骗过判别器。
训练不稳定:就像两个拳击手,一方突然太强,比赛就失去意义了。需要精心设计让它们保持“势均力敌”。
难以评估:怎么判断生成的质量好坏?没有绝对标准。
技术总结
GAN = 生成器(造假者) + 判别器(鉴定者) + 对抗训练框架
核心哲学:通过制造“内部竞争”,驱动系统达到外部无法直接指定的高性能。它不是被“教”会的,而是被“逼”出来的。
最终产物:一个能生成极其逼真数据的“生成器”,它捕捉并内化了真实数据的全部复杂分布。这不仅是技术,更像是一种艺术——让机器学会“无中生有”的创造艺术。
CycleGAN
输入一张真实的图像(比如抖音上一个很火的变二次元的特效就是这个),真人照片与训练图库进行对比,提取特征,最终输出一张二次元照片,还能够通过反向生成器近似还原真人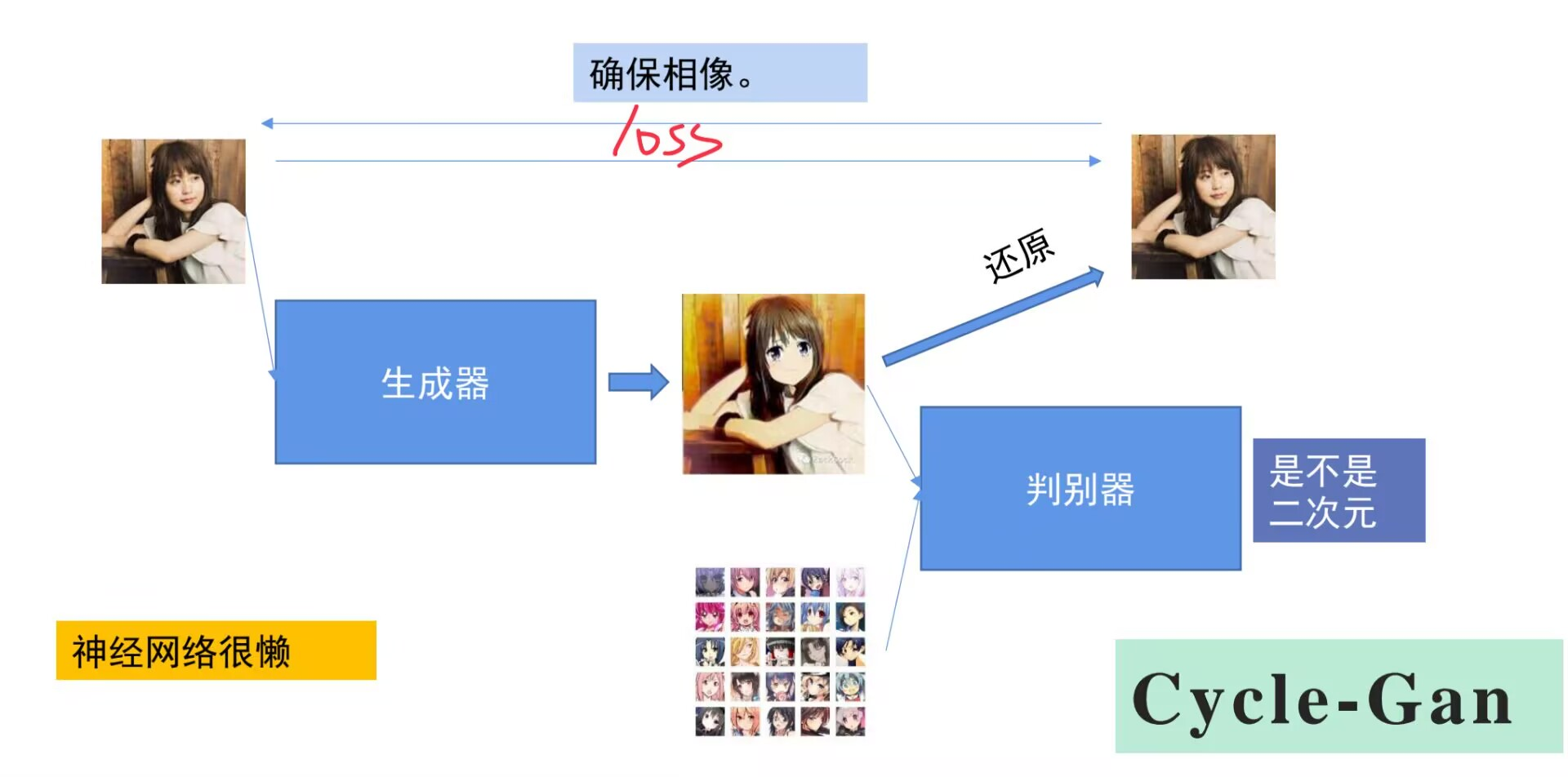
生成式自监督学习

一句话核心
生成式自监督学习:让AI通过“预测被遮住的部分”来学习,最终获得“无中生有”的创造能力。
它的核心是:把学习数据本身的结构,变成一个“猜谜游戏”。
从一个游戏讲起:超级完形填空
假设你想让AI学会写文章,但不想雇人一句句教它。
传统方法(监督学习):
你准备海量“问题-答案”对:
输入:“法国的首都是?” → 输出:“巴黎”
输入:“2+2=?” → 输出:“4”
… AI只能回答你教过的问题。
生成式自监督学习方法:
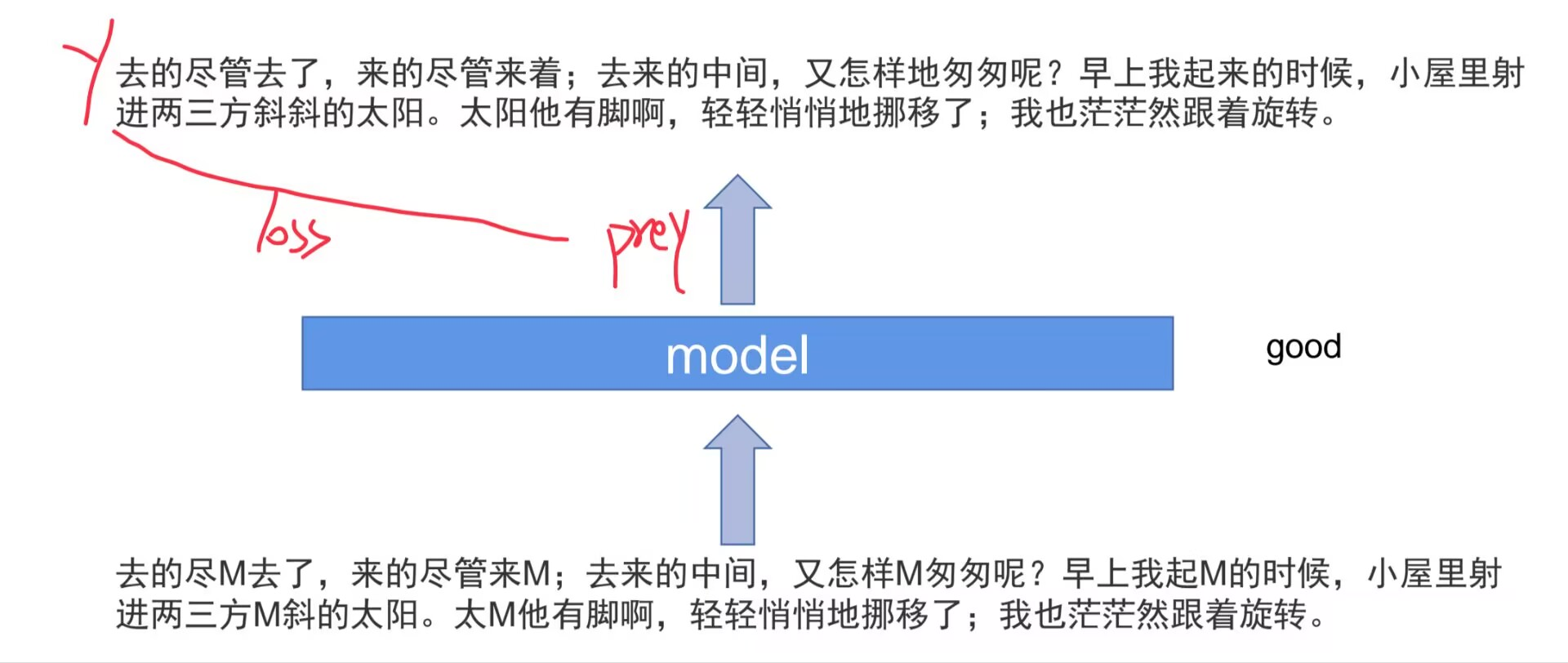
你扔给AI一本完整的《百科全书》,但把里面随机的字词遮掉,然后说:
“来,把这些空填上。”
例如:
“法国的首都是 ███。” → AI猜:“巴黎”
“████ 的首都是巴黎。” → AI猜:“法国”
“螳螂捕蝉,黄雀在 ██。” → AI猜:“在后”
“少壮不努力,老大徒 ███。” → AI猜:“伤悲”
关键:你从未提供“标准答案”,答案就在原文里。AI通过无数次“猜原文”的练习,自己学会了语法、事实、逻辑、甚至文学修辞。
这就是“自监督”——自己制造任务,自己提供监督信号。
技术核心:三种经典“游戏”
掩码语言模型(如BERT,但用于训练)
玩法:随机遮盖文章中15%的单词,让AI预测原词。
学的什么:词语的上下文语义、语法结构、事实关联。
好比:读一本用马克笔涂掉某些词的小说,边读边猜,词汇量和语感飞速提升。
自回归预测(如GPT系列)
玩法:只给前文,永远预测“下一个词是什么”。
学的什么:语言的逻辑流、叙事结构、长程依赖。
好比:总被要求接龙“从前有座山,山上有座庙,庙里有个…” ,最终学会自己编一个完整的故事。
图像生成式学习(如MAE,掩码自编码器)
玩法:随机遮盖图片75%的像素块,让AI根据可见的25%来 reconstruct(重建)全图。
学的什么:物体的结构、部件的组合关系、纹理与语义。
好比:只看一个人的左眼和嘴角,就要猜出他整张脸的样子,从而深刻理解人脸结构。
与大模型的关系(至关重要!)
GPT、Llama等大语言模型:本质上就是通过 “下一个词预测” 这种生成式自监督任务,在海量互联网文本上训练出来的。它们学会了语言的规律,因此能生成流畅文本。
DALL-E、Stable Diffusion等文生图模型:其核心也包含了生成式自监督学习。例如,在训练中,它们学习从带噪声的、不完整的图像数据中重建清晰图像,从而理解图像结构和文本-图像的对应关系。
简单说:没有生成式自监督学习,就没有今天的大模型浪潮。
特征分离
将图片的特征进行分割提取:风格和内容,随后可以将特征进行融合组建

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)