强化学习|lesson2:强化学习方法汇总
强化学习领域探讨了多种方法,包括模型自由和模型基于的策略。模型自由方法直接从反馈中学习,无需理解环境;而模型基于方法通过建立环境模型,增强预测能力。基于概率的方法聚焦于动作的概率,旨在最大化成功概率;相比之下,基于价值的方法侧重于选择具有最高价值的动作,追求最优策略。讨论还涉及了按回合更新与单步更新的策略,以及在线学习与离线学习的区别。以Q-learning、Policy Gradients、De
今天我们会来了解强化学习中常会用到的几种方法以及他们的区别,对我们根据特定问题选择方法是很有帮助。强化学习是一个大家族发展历史也不断具有很多种不同的方法。比如说比较知名的控制方法q learning policy gradients,还有基于对环境理解的model base的rl等等。接下来我们通过分类的方式来了解他们的区别。

(一)理不理解环境进行分类——model base OR model free
(1)该怎么理解什么是model base OR model free
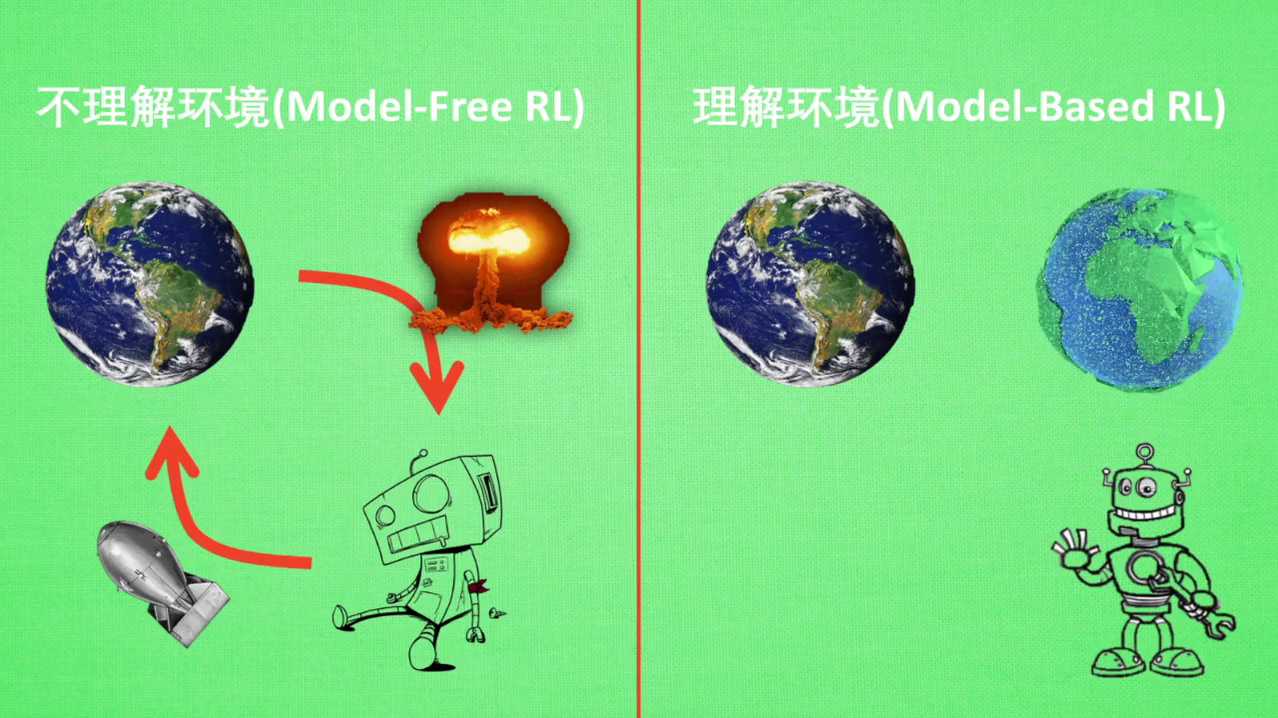
我们可以将所有的强化学习方法分为理不理解所处的环境。如果我们不尝试去理解环境,环境给了我们什么就是什么,我们就把这种方法叫做model free。这里的model就是用模型来表示环境,理解的环境也就是学会了一种模型来代表环境,所以这种叫做model base的方法。
我们想象现在环境就是我们所处的世界,我们的机器人正在这个世界玩耍,他不理解这个世界是怎样构成的,也不理解世界对于他们的行为会做出怎样的反馈。举个例子,他决定丢一颗原子弹去真实的世界,结果把自己也砸死了,所有结果都是那么现实。不过如果采取model based RL机器人就会通过过往的经验,先理解真实世界是怎样的,并建立一个模型来模拟现实世界的反馈。最后他不仅可以可以在现实世界中玩耍,也能在模拟世界中玩耍,这样就没有必要去炸真实的世界,连自己都炸死了,他可以像玩游戏一样站在游戏中的世界,也保住了自己的小命。
| 维度 | Model-Based(基于模型) | Model-Free(无模型) |
|---|---|---|
| 环境模型 | 显式学习环境模型(如状态转移矩阵 P(s′∣s,a) 和奖励函数 R(s,a,s′))。 | 不学习环境模型,直接通过与环境交互数据(状态、动作、奖励)学习策略或价值函数。 |
| 决策方式 | 利用模型进行规划(Planning):通过模拟环境动态预测未来状态,指导动作选择。 | 通过 试错(Trial-and-Error)直接优化策略或价值函数,依赖实时交互数据。 |
| 数据效率 | 通常更高,可利用模型生成 “虚拟经验”,减少真实环境交互次数。 | 依赖真实环境采样,数据效率较低(尤其是复杂环境)。 |
| 适用场景 | 环境可模拟(如游戏、机器人仿真)、需长期规划的场景。 | 环境难以建模(如真实世界)、实时性要求高的场景。 |
(2)model base OR model free方法各有那些
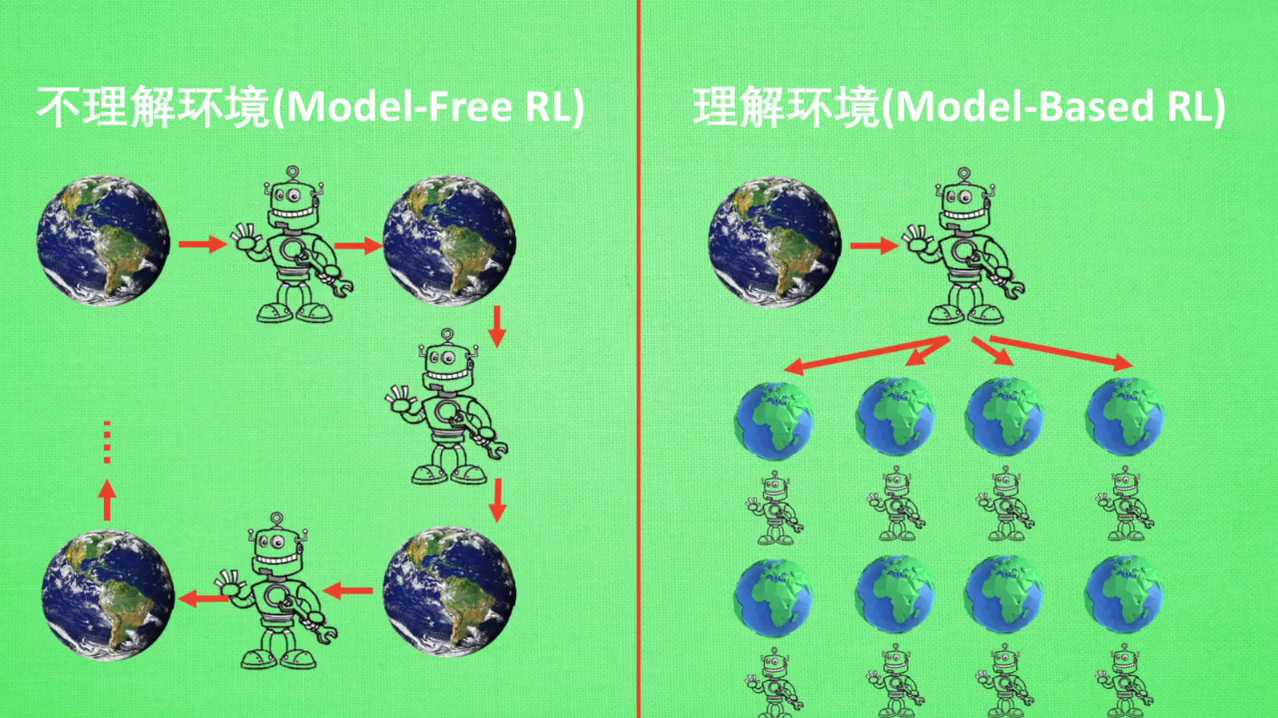
Model free的方法很多,像culinary science,都是从环境中得到反馈,从而学习。而model base style只是多了一道工序,为现实世界建模,也就是可以说他们都是model free的强化学习,只是model based做出了一个虚拟环境,我们不仅可以像model free那样在现实中玩耍的,也能在游戏中玩耍,而玩耍的方式都是model free中那些玩耍的方式,最终model base的还有一个杀手锏是model free超级羡慕的那就是想象力。Model free的方法中,机器人只能按部就班,一步一步的等待真实世界的反馈,再根据反馈采取下一步行动。而model base的方法它能通过想象来预判断接下来要发生的所有情况,然后根据这些想象中的情况选择最好的那种,并根据这种情况来采取下一步的策略。这也就是为其场上alphago能够超越人类的原因。

(二)是否依据概率进行划分——基于概率和基于价值
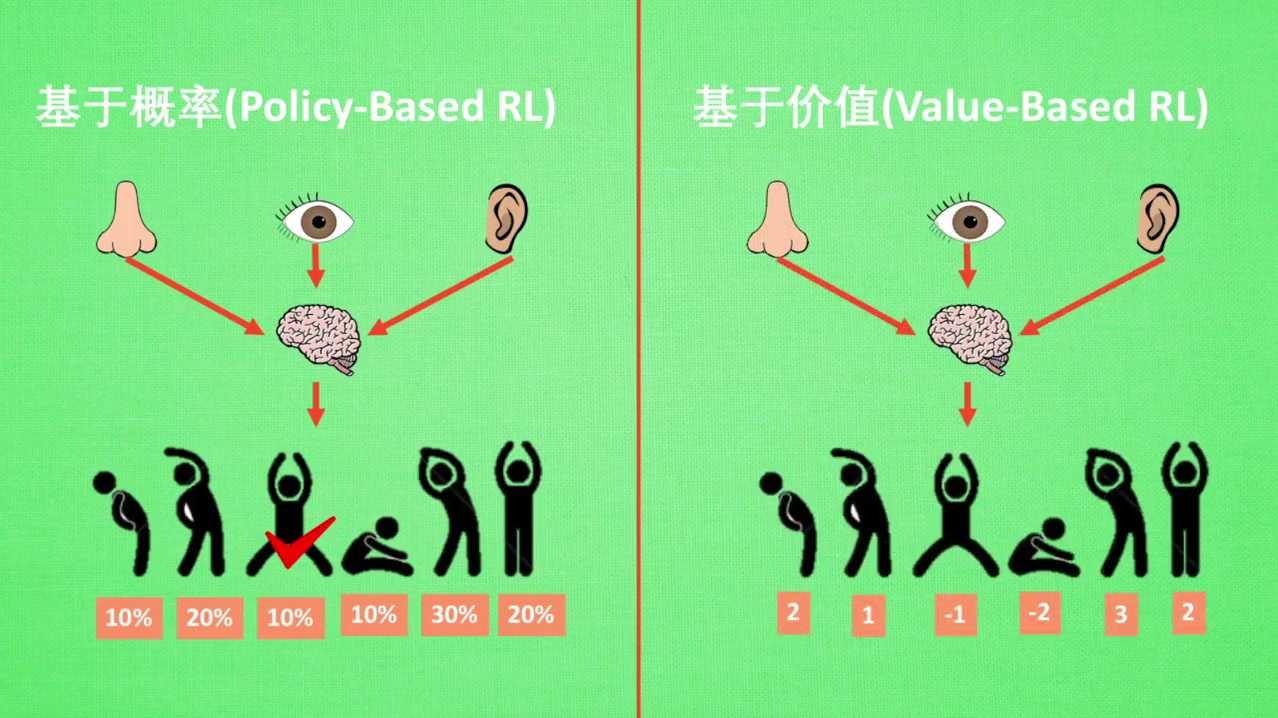
基于概率是强化学习中最直接的一种,他能通过感官分析所处的环境,直接输出下一步采取的各种行动的概率,然后根据概率采取行动。所以每一种动作都有可能被选中,只是可能性不同。而基于价值的方法说这是所有动作的价值,我们会根据最高价值来选择动作。相比基于概率的方法,基于价值的决策部分更为铁定,毫不留情就选价值最高的。而基于概率的基本,即使某个动作的概率最高,但还是不一定会选择到它。我们现在做的动作都是一个个不连续的动作,而连续的动作基于价值的方法是无能为力的。我们却能用一个概率分布在连续动作中选择特定的动作,这也就是基于概率的方法优点之一。
| 分类 | 核心思想 | 策略类型 | 代表算法 | 关键特点 | 典型应用场景 |
|---|---|---|---|---|---|
| 基于价值 | 学习价值函数(状态价值 V(s) 或动作价值 Q(s,a)),通过价值函数间接推导策略。 | 确定性策略(如 ε- 贪心、确定性动作选择) | 表格型:Q-Learning、Sarsa、Expected Sarsa 函数近似:DQN、DDQN、DDPG、C51、QR-DQN |
- 不直接参数化策略,策略由价值函数导出(如 “选择 Q 值最大的动作”) - 适用于离散动作空间(DQN)或连续动作空间(DDPG 通过确定性策略输出) |
游戏(Atari、围棋)、推荐系统、离散控制任务(如机械臂点位控制) |
| 基于概率 | 直接参数化策略函数 π(a∣s),学习动作的概率分布。 | 随机性策略(输出动作概率分布) | 策略梯度:REINFORCE、TRPO、PPO、CMA-ES 演员 - 评论家:A2C、A3C、PPO、SAC(软演员 - 评论家) |
- 直接优化策略的概率分布,可自然处理连续动作空间 - 适合需要探索随机性或高维动作空间的场景 - 常结合价值函数(如优势函数 A(s,a))提升稳定性 |
机器人控制(行走、抓取)、自动驾驶、连续动作优化(如机械臂扭矩控制) |

(1)关键区别解析
-
策略生成方式
- 基于价值:策略由价值函数间接决定(如 “贪心选择价值最大的动作”),本质是确定性策略(仅在探索时引入随机性,如 ε- 贪心)。
- 基于概率:策略直接输出动作概率分布(如 π(a∣s)=softmax(wTϕ(s,a))),天然支持随机性策略,适合需要探索不同动作分布的场景(如机器人避障的随机扰动)。
-
动作空间适应性
- 基于价值:离散动作空间(如 DQN 控制 Atari 游戏的 8 种按键)更易处理;连续动作需特殊设计(如 DDPG 通过确定性策略 + 探索噪声处理)。
- 基于概率:连续动作空间(如机械臂关节角度、车辆油门刹车)更自然,可直接输出连续概率分布(如高斯分布均值和方差)。
-
探索机制
- 基于价值:依赖外在探索策略(如 ε- 贪心、玻尔兹曼探索),与价值函数分离。
- 基于概率:探索由策略本身的随机性提供(如概率分布的熵正则化),探索与策略优化一体化。
-
收敛性与稳定性
- 基于价值:价值函数收敛性较好(如 Q-Learning 理论上收敛到最优 Q 值),但策略贪心选择可能导致局部最优(如 “悬崖行走” 问题中的短视行为)。
- 基于概率:策略梯度算法(如 PPO)通过信赖域优化提升稳定性,但需谨慎调整学习率和熵奖励,否则易发散。
(2)混合方法:演员 - 评论家(Actor-Critic)
部分算法结合两者优势(如 A2C、PPO、DDPG):
- 演员(Actor):基于概率的策略网络(随机性或确定性),负责生成动作。
- 评论家(Critic):基于价值的函数(如 Q 函数或状态价值 V (s)),评估动作质量并指导策略更新。
- 典型案例:
- DDPG:评论家为 Q 函数,演员为确定性策略(适合连续动作,如机器人控制)。
- PPO:评论家评估状态价值 V (s),演员输出动作概率分布(适合高维连续动作,如 OpenAI 的机器人体操)。
(三)是否会和更新——回合更新和单步更新
回合更新(Episodic Update)应该是指在一个完整的回合(episode)结束后才进行参数更新,而单步更新(Step-by-Step Update)则是在每一步(step)之后立即更新。这可能涉及到不同的学习方式,比如蒙特卡洛方法通常是回合更新,而时序差分(TD)方法可以是单步更新。
| 分类 | 核心思想 | 更新时机 | 代表算法 | 关键特点 | 典型应用场景 |
|---|---|---|---|---|---|
| 回合更新 | 等待完整回合结束后,基于整个轨迹的累积奖励更新策略或价值函数。 | 回合结束后一次性更新 | 蒙特卡洛方法:蒙特卡洛策略梯度(REINFORCE)、蒙特卡洛树搜索(MCTS) Actor-Critic:A3C(异步优势演员评论家) |
- 依赖完整轨迹,需存储整个回合的状态、动作、奖励 - 方差高但估计无偏(如蒙特卡洛) - 适合回合明确的任务(如棋类、导航) |
棋类游戏(围棋、象棋)、机器人路径规划、需长期回报评估的任务 |
| 单步更新 | 每一步交互后,利用当前奖励和下一状态的估计值即时更新策略或价值函数。 | 每个时间步实时更新 | 时序差分(TD):Q-Learning、Sarsa、Dyna-Q Actor-Critic:A2C(同步优势演员评论家)、DDPG(深度确定性策略梯度) |
- 无需等待回合结束,样本效率高 - 依赖当前估计值,可能引入偏差(如 TD (0)) - 适合连续任务或在线学习 |
自动驾驶、推荐系统、机器人实时控制、股票交易 |


| 维度 | 回合更新 | 单步更新 |
|---|---|---|
| 适用场景 | 回合明确、需长期回报评估(如棋类) | 连续任务、实时控制(如自动驾驶) |
| 数据效率 | 低(需完整回合) | 高(每步更新) |
| 收敛速度 | 慢(依赖回合长度) | 快(增量更新) |
| 代表算法 | REINFORCE、A3C、蒙特卡洛树搜索 | Q-Learning、Sarsa、A2C、DDPG |
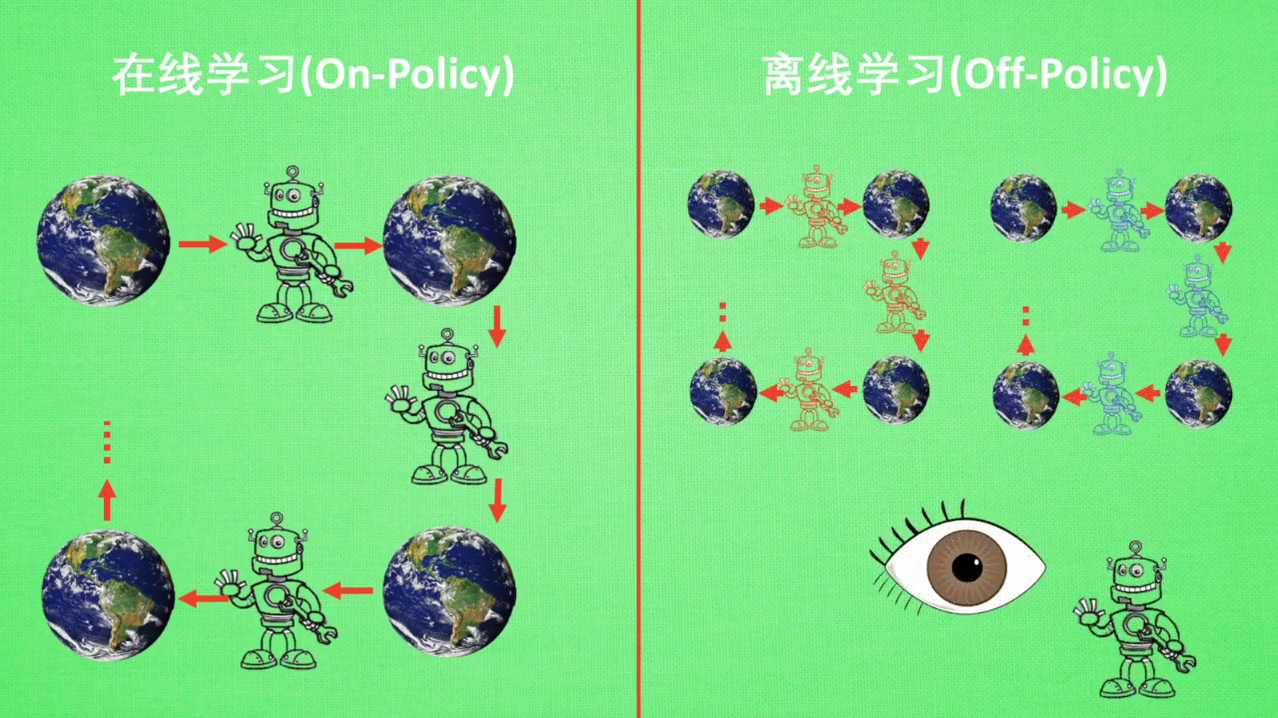
(四)分为在线学习和离线学习
所谓的在线学习就是指我必须本人在场,并且一定是本人在编学习。而离线学习就是你可以选择自己玩,也可以选择看着别人玩,通过看着别人玩来学习别人的行为准则。离线学习同样是从过往经验中学习,但是这些过往的经历没有必要是自己的经历,任何人的经历都能被学习,或者我也不必要天玩边学习,我可以白天先储存下来玩耍时的记忆,等到晚上再通过离线学习来学习白天的记忆。
| 分类 | 核心思想 | 数据来源 | 更新方式 | 代表算法 | 关键特点 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 在线学习 | 策略与环境实时交互,通过采样当前策略产生的数据更新自身,学习与决策同步进行。 | 实时采样当前策略与环境交互的数据 | 边采样边更新(在线更新) | 基于价值:Sarsa、SARSA(λ) 策略梯度:REINFORCE、A2C(同步演员评论家)、PPO(近端策略优化) 模仿学习:DAGGER(交互式专家查询) |
- 数据为当前策略产生,样本相关性高 - 需持续与环境交互,适合动态环境 - 策略更新直接影响后续采样分布 |
机器人实时控制、自动驾驶、动态博弈(如实时对战游戏) |
| 离线学习 | 利用历史固定数据集(无需与环境实时交互)学习策略,学习过程不影响环境采样。 | 预先收集的历史数据集(可来自任意策略) | 基于固定数据集迭代更新(离线更新) | 离线强化学习:BCQ(引导策略搜索)、CQL(保守 Q 学习)、TD3+BC(截断双 DQN + 行为克隆) 模仿学习:行为克隆(BC)、逆强化学习(IRL) 传统离线策略:Q-Learning(结合回放缓冲区)、DDPG(经验回放) |
- 无需实时交互,适合数据安全敏感场景 - 可重用旧数据,节省采样成本 - 需处理数据分布偏移(如策略差异导致的偏差) |
医疗决策(数据隐私)、自动驾驶仿真测试、游戏 AI 复盘优化、工业机器人预训练 |


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)